Elasticsearch 分片路由原理指定分片存储查询
Elasticsearch 项目中使用到Es的父子结构、在数据填充之后,查看每个节点的数据分布情况,发现有的节点数据多,有的节点少的情况,在未使用Es父级结构之前,每个节点的数据分布还算平均,如下图:
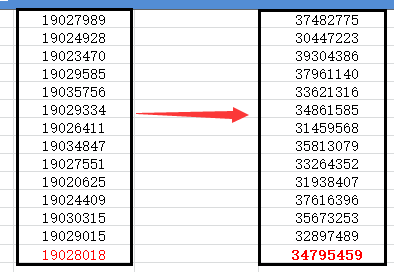
左边的数据是未使用父子结构之前每个节点的数据分布数量,右边的是使用了父子结构之后的数据节点分布数量,最下面一行红色的数字是节点平均数量,可以看出,左边的数据与平均值相差不大,右边的数据与平均值最大相差400万,这个差距还是蛮大的,为什么会有这么大的差距呢?围绕着这个问题,进行了一番研究,今天就来学习学习下Elasticsearch 的路由机制。
首先,Es的路由机制与其分片机制有着直接的关系,Es的路由机制是通过哈希算法,将具有相同哈希值的文档放置在同一分片中的,通过这个哈希算法来进行负载均衡的效果,这个就是为什么左侧图中的每个节点的数据都与平均值相差不大的原因。
计算公式是:
shard = hash(routing) % number_of_primary_shards
routing 值是一个任意字符串,它默认是_id但也可以自定义。这个routing 字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远是0到number_of_primary_shards - 1,这个数字就是特定文档所在的分片。
所以,每一条数据在写入的时候,是放在分片1上,还是分片2上,不是瞎蒙的,是通过计算得来的。这也解释了为什么主分片的数量只能在创建索引时定义且不能修改:如果主分片的数量在未来改变了,所有先前的路由值就失效了,文档也就永远找不到了。
上面解释清楚了,在来解释下,为什么我使用了Es父子结构之后,每个节点的数据发生了那么大的差距呢?
解释这个之前,先来看下Es父子结构情况下,写入子数据的写法(怎么创建父子结构这里就不赘述了):
PUT /company/employee/?parent=london
{
"name": "Alice Smith",
"dob": "1970-10-24",
"hobby": "hiking"
}
在创建子文档的时候你必须指出他们的父文档的id,为什么要指定父文档的ID呢?这是因为Es在存储子数据的时候,会用父文档的ID去计算存放在那个分片,它会把父文档相同的数据都存放在同一个分片上面;
举个例子,如果父文档1,下面子文档有10个,存储在A分片;
分文档2,下面子文档有500个,存储在B分片上;
这样,随着每个父文档对应的子文档数据分布不均,节点的数据量就会越来越不均衡,这就说明了为什么使用了Es父子结构之后,节点数据差距较大的情况了。
问题来了,那么怎么解决分布不均的问题呢?
可以通过指定个性化路由来处理,所有的文档API(get,index,delete,update和mget)都能接收一个routing参数,可以用来形成个性化文档分片映射。
写入数据时怎么指定存储的分片,可以参考这篇:https://www.cnblogs.com/bonelee/p/6055340.html ,别人已经写好,我就不重新去写了。
来说一说设置分片的好处,我画了个图,举个例子,现在你去找一本计算机相关的图书,现在有四个节点,在没有指定分片存储之前,所有的书是平均放的,每一个节点上面都会有计算机相关的图书,
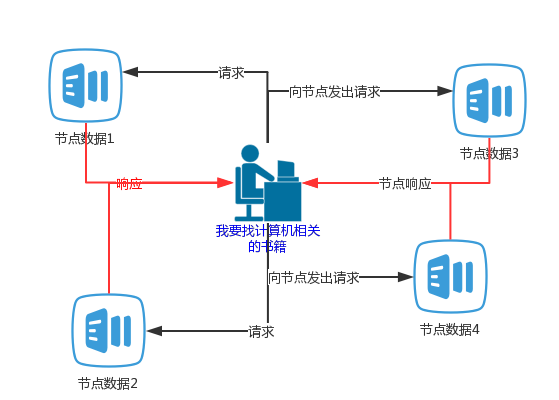
然后,Es就会去四个节点上面分别去找,黑色的线,ES会向每个节点都发送一个请求,然后节点就开始找找,找呀找,然后,找到了,节点开始返回数据了,就是红色的线;
ES把所有的节点的响应数据都汇总之后,然后在按照评分去做下排序,把评分最高,相关性比较高的数据在返回给你。
那么,如果在存储的时候,就告诉ES,把所有计算机相关的书籍都给我放置到节点3上面,然后在查询的时候,告诉ES,在节点3上面给我找计算机相关的书籍。如下图:
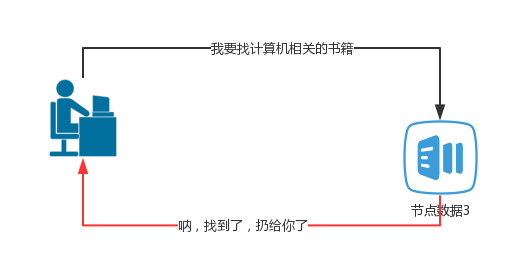
很明显,这样的查询,就不会去向所有的节点都广播,定位很精准,在某一程度上,效率可能会高一点,但是,这样做的话,就会增加ES节点分片的维护成本,就违背了Es高可用性,拓展性的设计理念了
所以,要根据具体业务具体需求去定响应的方案。
Elasticsearch 分片路由原理指定分片存储查询的更多相关文章
- Mysql系列六:(Mycat分片路由原理、Mycat常用分片规则及对应源码介绍)
一.Mycat分片路由原理 我们先来看下面的一个SQL在Mycat里面是如何执行的: , ); 有3个分片dn1,dn2,dn3, id=5000001这条数据在dn2上,id=10000001这条数 ...
- mongodb系列之--分片的原理与配置
1.分片的原理概述 分片就是把数据分成块,再把块存储到不同的服务器上,mongodb的分片是自动分片的,当用户发送读写数据请求的时候,先经过mongos这个路由层,mongos路由层去配置服务器请求分 ...
- Elasticsearch由浅入深(六)批量操作:mget批量查询、bulk批量增删改、路由原理、增删改内部原理、document查询内部原理、bulk api的奇特json格式
mget批量查询 批量查询的好处就是一条一条的查询,比如说要查询100条数据,那么就要发送100次网络请求,这个开销还是很大的如果进行批量查询的话,查询100条数据,就只要发送1次网络请求,网络请求的 ...
- ElasticSearch 学习记录之集群分片内部原理
分片内部原理 分片是如何工作的 为什么ES搜索是近实时性的 为什么CRUD 操作也是实时性 ES 是怎么保证更新被持久化时断电也不丢失数据 为什么删除文档不会立即释放空间 refresh, flush ...
- Es官方文档整理-2.分片内部原理
Es官方文档整理-2.分片内部原理 1.集群 一个运行的Elasticsearch实例被称为一个节点,而集群是有一个或多个拥有相同claster.name配置的节点组成,他们共同承担数据和负 ...
- MongoDB 分片的原理、搭建、应用
一.概念: 分片(sharding)是指将数据库拆分,将其分散在不同的机器上的过程.将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载.基本思想就是将集合切成小块,这 ...
- ES学习之分片路由
本文主要内容: 1.路由一个文档到一个分片 2.新建.索引和删除请求 3.取回单个文档 4.局部单个文档 5.多文档模式 6.理解一下ES深度分页(from-size)的劣势 路由一个文档到一个分片 ...
- MongoDB 分片的原理、搭建、应用 !
MongoDB 分片的原理.搭建.应用 一.概念: 分片(sharding)是指将数据库拆分,将其分散在不同的机器上的过程.将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处 ...
- Elasticsearch 之 慘痛部署(分片移位)
部署说明 硬件 server两台: 机器A:64G内存 机器B:32G内存 分片 共12个节点 2个查询节点.10个存储节点 8个主分片 1个复制分片(每一个分片都有一个副本分布在不同的节点上面) 每 ...
随机推荐
- Intellij IDEA创建的Web项目配置Tomcat并启动Maven项目
本篇博客讲解IDEA如何配置Tomcat. 大部分是直接上图哦. 点击如图所示的地方,进行添加Tomcat配置页面 弹出页面后,按照如图顺序找到,点击+号 tomcat Service -> L ...
- 八、xadmin自定义菜单栏顺序
xadmin默认是读取注册的app和所有注册到xadmin的mode来生成对应的菜单. nav_menu[app_key] = { 'title': app_title, 'menus': [mode ...
- Dockerfile centos7_tomcat7.0.64_jdk7u80
FROM centos:7 MAINTAINER jiangzhehao WORKDIR /tmp RUN yum -y install net-tools ADD jdk-7u80-linux-x6 ...
- 小程序wxRequest封装
//const host = 'http://114.215.00.00:8005';// 测试地址 const host = 'https://xx.xxxxxxxx.net'; // 正式地址 c ...
- Volterra方程的不动点
- IdentityServer4【Topic】之定义资源
Defining Resources 定义资源 你在系统中通常定义的第一件事是你想要保护的资源.这可能是你的用户的身份信息,比如个人资料数据或电子邮件地址,或者访问api. 你可以通过C#对象模型(内 ...
- 对B+树,B树,红黑树的理解
出处:https://www.jianshu.com/p/86a1fd2d7406 写在前面,好像不同的教材对b树,b-树的定义不一样.我就不纠结这个到底是叫b-树还是b-树了. 如图所示,区别有以下 ...
- [转帖]国产紫光SSD不再只是实验室展品 开始批量出货
国产紫光SSD不再只是实验室展品 开始批量出货 https://www.cnbeta.com/articles/tech/825865.htm 没听说有做HDD的 现做了SSD 弯道超车吗 可以实现全 ...
- [转帖]oracle改版sql server问题点汇总
https://www.cnblogs.com/zhangdk/p/oracle_sqlserver.html 只记得 最开始的时候看过 没有具体的了解里面的特点 原作者总结的很好 留下来 以后说不定 ...
- day 7-15 表与表之间的关系
一. 前言 表与 表之间有3种对应关系,分别是: 多对一:一张表中的一个字段中的多个值对应另外一张表中的一个字段值.(多个学生,可以学习同一门课程) 多对多;一张表中的一个字段值对应另外一张表中的多个 ...