Oracle 数据库导入与出
Oracle 数据库导入与出
导出( EXPORT )是用 EXP 将数据库部分或全对象的结构和导出 。 导入( 导入( IMPORT )是用 )是用 IMP IMP将 OS 文件中的对象结构和数据装载到库过程。
EXP 和 IMP 用于实现逻辑备份和恢复,导入出的作如下:
1、使用导出和入可以重新组织表。
2、使用导出和入可以在户之前移动对象。
3、使用导出和入可以在数据库之间移动对象。典型事例:传输表空间
4、使用导出和入可以升级数据库到其它平台。
5、使用导出和入可以升级数据库到更高版本。
6、使用导出和入可以实现逻辑备份恢复。
一、 获取帮助 获取帮助 获取帮助
$ exp help=y
$ imp help=y
二、 三种工作方式
1.交互式
方[oracle@localhost ~]$ exp Export: Release 11.2.0.3.0 - Production on Sun Jul 15 16:41:02 2018 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. Username: system
Password: Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
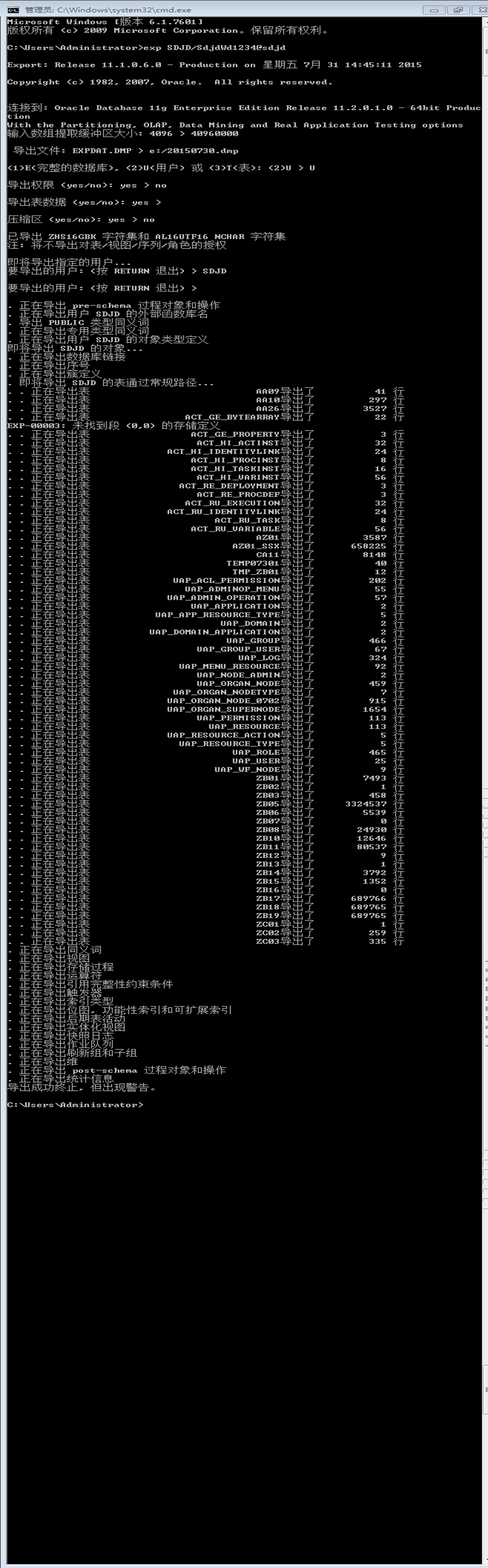
Enter array fetch buffer size: 4096 > 4096 Export file: expdat.dmp > a.dmp (1)E(ntire database), (2)U(sers), or (3)T(ables): (2)U > 3 Export table data (yes/no): yes > yes Compress extents (yes/no): yes > yes Export done in US7ASCII character set and AL16UTF16 NCHAR character set
server uses ZHS16GBK character set (possible charset conversion) About to export specified tables via Conventional Path ...
Table(T) or Partition(T:P) to be exported: (RETURN to quit) > scott.dept Current user changed to SCOTT
. . exporting table DEPT 10 rows exported
EXP-00091: Exporting questionable statistics.
EXP-00091: Exporting questionable statistics.
Table(T) or Partition(T:P) to be exported: (RETURN to quit) > Export terminated successfully with warnings.
[oracle@localhost ~]$交互式导出数据库
交互式导入数据库
实例:
1) 导出整个数据库
2) 导出数据库中某个用户的所有对象
3) 导出特定的表2.命令行方式
在命令行中输入所需的参数 即可,如下所示:
 [oracle@localhost ~]$ exp system/oracle tables=scott.dept file=b.dmp Export: Release 11.2.0.3.0 - Production on Sun Jul 15 17:02:57 2018 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - Production
[oracle@localhost ~]$ exp system/oracle tables=scott.dept file=b.dmp Export: Release 11.2.0.3.0 - Production on Sun Jul 15 17:02:57 2018 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
Export done in US7ASCII character set and AL16UTF16 NCHAR character set
server uses ZHS16GBK character set (possible charset conversion) About to export specified tables via Conventional Path ...
Current user changed to SCOTT
. . exporting table DEPT 10 rows exported
EXP-00091: Exporting questionable statistics.
EXP-00091: Exporting questionable statistics.
Export terminated successfully with warnings.
[oracle@localhost ~]$ ls
a.dmp database extertablefile h:1dept.sql h:1.lst h:emp.txt oyt.lst rlwrap-0.37.tar.gz
b.dmp Desktop grid h:1emp.txt h:1spooltest.txt oracle_system_files_back rlwrap-0.37
[oracle@localhost ~]$实例:1) 导出整个数据库
导出整个数据库,只需要 导出整个数据库,只需要 FULL 和 FILE 二个参数, FULLL 表示导出整 个文件, 包括所有的数据库对象FILE 表示备份后的数据文件名。
只导出数据库的结构,不要表即包含全备份。
实例:2) 导出数据库中某个用户的所有对象
导出当前数据库 中某个用户的所有对象,作为该备份,使用 备份,使用 owner 参数指定。 导出该用户所拥有的数据库对象定义,以及 导出该用户所拥有的数据库对象定义,以及 对象所拥有的数据。使用 system 用户登录数据库,该具有 DBA 权限, 所以它拥有访问 scott 用户的数据库对象权限,可以导出 用户的数据库对象权限,可以导出 scott 用户的所有
数据库对象,也可以使用 数据库对象,也可以使用 scott 用户登录数据库 ,导出它自已拥有的用户登录数据库 ,导出它自已拥有的对象。exp system/oracle owner=scott file= userback_scott .dmp或
exp scott /scott owner=scott file= back_user_scott .dmp或
exp scott /scott file= back_user_scott .dmp实例:3) 导出特定的表
导出特定用户的表需要 tables 参数, 该后可以有几个表名参数, 该后可以有几个表名如导出的表不是当前用 户,需要使如导出的表不是当前用 户,需要使schema_name.table_name 的形 式,告诉 式,告诉 exp 这个表属于哪用户。 System 具有对用户 scott 中表的访 问权,所以该用户可导出 scott 用 户的表,如果使用 户的表,如果使scott 用户登录 用户登录 数据库,在导出自已的表时可以直接写名不用加模式。
导出一张表exp userid=hr/hr tables=jobs file=hr_tables.dmp log=/home/oracle/jobs.log导出多张表
exp userid=system/oracle tables=scott.dept,tables=scott.emp file=tables.dmp或
exp userid=system /oracle tables= scott.dept ,scott.emp file= tables.dmp或
exp scott/scotttables=dept,emp file=backup_scott_tables.dmp导出表的部分数据 ,使用 query 参数
exp userid=hr/hr file= hr_tables_9000.dmp tables=jobs query= \'where MAX_SALARY \=9000 \'
注意:对字符采用 注意:对字符采用 注意:对字符采用 注意:对字符采用 \转义。 转义。
导出表结构导出触发器
exp userid=hr/hr tables=jobs file= hr_job.dmp triggers=n indexes=n grants=n constraints=n实例:4) 导出特定的表空间
exp system/oracle tablespaces=users file=backup_tablespaces_users.dmp或
或
exp userid=\'/ as sysdba '/ as sysdba '/ as sysdba \' tablespaces=TBS_SINGLE ' file=/tmp/ODU.dmp transport_tablespace=y3.参数文件方式 ,在参数 文件中输入所需的在参数



三、种模式
- 1、表方式,将指定的数据导出 /导入
- 2、用户方式,将指定的所有对象及数据导出 /导入
- 3、全库方式,将数据中的所有对象导出 /导入
EXP 的参数: 的参数: 的参数:
[oracle@localhost ~]$ exp help =y Export: Release 11.2.0.3.0 - Production on Sun Jul 15 14:38:38 2018 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. You can let Export prompt you for parameters by entering the EXP
command followed by your username/password: Example: EXP SCOTT/TIGER Or, you can control how Export runs by entering the EXP command followed
by various arguments. To specify parameters, you use keywords: Format: EXP KEYWORD=value or KEYWORD=(value1,value2,...,valueN)
Example: EXP SCOTT/TIGER GRANTS=Y TABLES=(EMP,DEPT,MGR)
or TABLES=(T1:P1,T1:P2), if T1 is partitioned table USERID must be the first parameter on the command line. Keyword Description (Default) Keyword Description (Default)
--------------------------------------------------------------------------
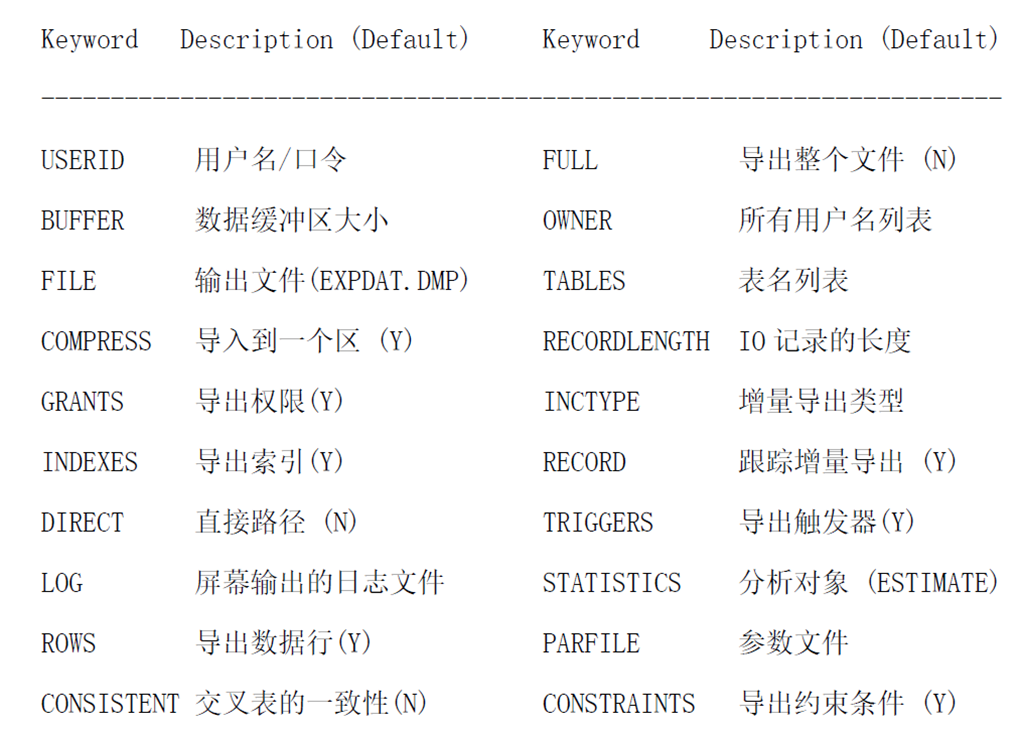
USERID username/password FULL export entire file (N)
BUFFER size of data buffer OWNER list of owner usernames
FILE output files (EXPDAT.DMP) TABLES list of table names
COMPRESS import into one extent (Y) RECORDLENGTH length of IO record
GRANTS export grants (Y) INCTYPE incremental export type
INDEXES export indexes (Y) RECORD track incr. export (Y)
DIRECT direct path (N) TRIGGERS export triggers (Y)
LOG log file of screen output STATISTICS analyze objects (ESTIMATE)
ROWS export data rows (Y) PARFILE parameter filename
CONSISTENT cross-table consistency(N) CONSTRAINTS export constraints (Y) OBJECT_CONSISTENT transaction set to read only during object export (N)
FEEDBACK display progress every x rows (0)
FILESIZE maximum size of each dump file
FLASHBACK_SCN SCN used to set session snapshot back to
FLASHBACK_TIME time used to get the SCN closest to the specified time
QUERY select clause used to export a subset of a tableRESUMABLE suspend
whena
spacerelated error
isencountered(N) RESUMABLE_NAME
textstring used
toidentify resumable statement RESUMABLE_TIMEOUT wait
timeforRESUMABLE
TTS_FULL_CHECK perform full or partial dependency check for TTS
VOLSIZE number of bytes to write to each tape volume
TABLESPACES list of tablespaces to export
TRANSPORT_TABLESPACE export transportable tablespace metadata (N)
TEMPLATE template name which invokes iAS mode export Export terminated successfully without warnings.
[oracle@localhost ~]$注:关于 resumable resumable_name resumable_timeout 的信息 请从本文的 《管理可恢复的空间分配》部分了解

IMP 部分参数解释:
[oracle@localhost ~]$ imp help =y Import: Release 11.2.0.3.0 - Production on Sun Jul 15 15:37:17 2018 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. You can let Import prompt you for parameters by entering the IMP
command followed by your username/password: Example: IMP SCOTT/TIGER Or, you can control how Import runs by entering the IMP command followed
by various arguments. To specify parameters, you use keywords: Format: IMP KEYWORD=value or KEYWORD=(value1,value2,...,valueN)
Example: IMP SCOTT/TIGER IGNORE=Y TABLES=(EMP,DEPT) FULL=N
or TABLES=(T1:P1,T1:P2), if T1 is partitioned table USERID must be the first parameter on the command line. Keyword Description (Default) Keyword Description (Default)
--------------------------------------------------------------------------
USERID username/password FULL import entire file (N)
BUFFER size of data buffer FROMUSER list of owner usernames
FILE input files (EXPDAT.DMP) TOUSER list of usernames
SHOW just list file contents (N) TABLES list of table names
IGNORE ignore create errors (N) RECORDLENGTH length of IO record
GRANTS import grants (Y) INCTYPE incremental import type
INDEXES import indexes (Y) COMMIT commit array insert (N)
ROWS import data rows (Y) PARFILE parameter filename
LOG log file of screen output CONSTRAINTS import constraints (Y)
DESTROY overwrite tablespace data file (N)
INDEXFILE write table/index info to specified file
SKIP_UNUSABLE_INDEXES skip maintenance of unusable indexes (N)
FEEDBACK display progress every x rows(0)
TOID_NOVALIDATE skip validation of specified type ids
FILESIZE maximum size of each dump file
STATISTICS import precomputed statistics (always)
RESUMABLE suspend when a space related error is encountered(N)
RESUMABLE_NAME text string used to identify resumable statement
RESUMABLE_TIMEOUT wait time for RESUMABLE
COMPILE compile procedures, packages, and functions (Y)
STREAMS_CONFIGURATION import streams general metadata (Y)
STREAMS_INSTANTIATION import streams instantiation metadata (N)
DATA_ONLY import only data (N)
VOLSIZE number of bytes in file on each volume of a file on tape The following keywords only apply to transportable tablespaces
TRANSPORT_TABLESPACE import transportable tablespace metadata (N)
TABLESPACES tablespaces to be transported into database
DATAFILES datafiles to be transported into database
TTS_OWNERS users that own data in the transportable tablespace set Import terminated successfully without warnings.
[oracle@localhost ~]$
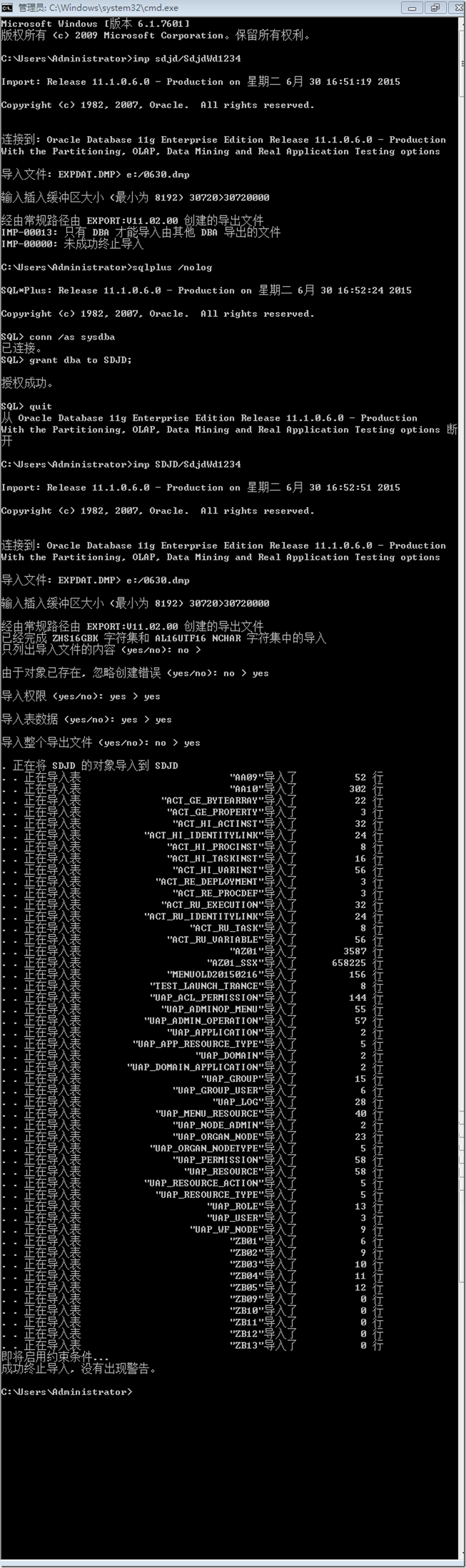
实例:1、 导入整个数据库
exp system/oracle full=y file=full.dmp
SQL> drop user scott cascade;
SQL> drop user hr cascade;
imp system/oracle full=y file=full.dmp ignore=Y实例:2、 导入 指定用户 的全部数据库对象,不建用户
exp scott /scott file=back_user_scott.dmp
exp system /orac le owner=scott file= back_user_scott1 .dmp
SQL> drop user scott cascade;
SQL> create user scott identified by scott DEFAULT TABLESPACE users TEMPORARY TABLESPACE temp QUOTA 10M ON users;
SQL> grant create session to scott;
imp scott/scott file= back_user_scott.dmp ignore=y或
或
imp system/oracle file=back_user_scott1.dmp ignore=y fromuser=scott touser=scott实例:3、 导入 特定的表
将特定的表导入指用户imp system/oracle tables=emp file=back_user_scott1.dmp fromuser=scott touser= system向用户 system 导入了 scott 用户的表 emp ,当导入 emp 表时其实就是在新用户 system 的用户表空间中创建一个并填充数据,最后基于该触发器。
导入一张表exp userid=hr/hr tables=jobs file= hr_tables.dmp log=/home/oracle/jobs.log
drop table jobs cascade constraints;
imp userid=hr/hr tables=jobs file= hr_tables.dmp log=/home/oracle/jobs.log
导入多张表exp userid=system/oracle tables=scott.dept ,scott.emp file=tables.dmp
SQL> drop table emp purge;
SQL> drop table dept purge;
imp userid=system/oracle tables=dept,emp file=tables.dmp fromuser=scott touser=scott
导入表的部分数据








四、传输表空间
理解:big /little andian
imp sys/oracle file=expdp.dmp datafile=expdp_trans.dmp transport_tablespace=y--- 查询各自数据库的环境的:字节序
SELECT des.PLATFORM_NAME, ENDIAN_FORMAT FROM V$TRANSPORTABLE_PLATFORM tp,V$DATABASE des WHERE tp.PLATFORM_NAME=des.PLATFORM_NAME;[oracle@localhost ~]$ rlwrap sqlplus / as sysdba; SQL*Plus: Release 11.2.0.3.0 Production on Sun Jul 15 19:53:09 2018 Copyright (c) 1982, 2011, Oracle. All rights reserved. Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options SYS@orcl> SELECT des.PLATFORM_NAME, ENDIAN_FORMAT FROM V$TRANSPORTABLE_PLATFORM tp,V$DATABASE des WHERE tp.PLATFORM_NAME=des.PLATFORM_NAME; PLATFORM_NAME
--------------------------------------------------------------------------------
ENDIAN_FORMAT
--------------
Linux IA (32-bit)
Little SYS@orcl>传输表空间的限制
传输表空间的自包含特性
实现 传输表空间的步骤
--在orcl库进行
create tablespace wl datafile '/u01/app/oracle/oradata/orcl/wl01.dbf' size 100M extent management local; create user u1 identified by oracle default tablespace wl; grant connect,resource to u1; create table u1.tab1 tablespace wl as select * from sys.dba_objects; --分别在orcl和prod库进行
SELECT des.PLATFORM_NAME, ENDIAN_FORMAT FROM V$TRANSPORTABLE_PLATFORM tp,V$DATABASE des WHERE tp.PLATFORM_NAME=des.PLATFORM_NAME; --在orcl库进行
EXECUTE DBMS_TTS.TRANSPORT_SET_CHECK('wl',true); SELECT * FROM TRANSPORT_SET_VIOLATIONS; alter tablespace wl read only; exp userid=\'/ as sysdba\' tablespaces=wl file=/tmp/wl.dmp transport_tablespace=y --将orcl库的wl表空间的数据文件和导出的DMP文件,传送到目标数据库平台上prod,通过拷贝导出的DMP文件到目标平台:拷贝表空间的数据文件到目标平台: --在prod库操作 --创建用户:
SQL> create user u1 identified by u1; --授予connect,resource角色授予给u1用户:
SQL> grant connect,resource to u1; imp userid=\'/ as sysdba\' tablespaces=wl file=/tmp/wl.dmp transport_tablespace=y datafiles=/tmp/wl01.dbf fromuser=u1 touser=u1 --在orcl库操作
--将被导入的表空间设置为可读可写:
SQL> alter tablespace wl read write; --在prod库操作
--以sys用户登录数据库,查看v$tablespace视图:
SQL> conn / as sysdba
SQL> select name from v$tablespace; --以u1用户连接到数据库,查看user_tables视图:
SQL> conn u1/oracle
SQL> select table_name from user_tables;











修改字符集:
---查看数据库的字符集
sqlplus system/manager
col parameter for a40
col value for a40
set lines 200
select * from nls_database_parameters where PARAMETER='NLS_CHARACTERSET';
ZHS16GBK --如不对可按以下方法修改(建议先备份)
1.SHUTDOWN IMMEDIATE; -- or NORMAL
2.<do a full backup>
3.STARTUP MOUNT;
ALTER SYSTEM ENABLE RESTRICTED SESSION;
ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
ALTER SYSTEM SET AQ_TM_PROCESSES=0;
ALTER DATABASE OPEN;
ALTER DATABASE CHARACTER SET ZHS16GBK;
ALTER DATABASE CHARACTER SET INTERNAL_USE ZHS16GBK;
4.SHUTDOWN IMMEDIATE; -- or NORMAL
5.STARTUP;
6.
col parameter for a40
col value for a40
set lines 200
select * from nls_database_parameters where PARAMETER='NLS_CHARACTERSET';
管理可恢复的空间分配
可恢复的空间分配功能挂起需要更多磁盘空间的数据库操作而不是将
其终止。挂起操作时,可以在目的地表空间上分配更多磁盘空间或增加用
户的配额。解决空间不足问题后,数据库操作将自动恢复。进行恢复的语句称为可恢复语句。如果挂起的语句是事务的一部分,则
也会挂起事务。当提供了磁盘空间而且挂起的语句恢复时,无论事务中是
否有挂起的语句,都可以提交或回滚事务。以下条件会触发可恢复的空间分配:
1、永久表空间或临时表空间中的磁盘空间不足
2、表空间达到是最大极限
3、超过了用户空间配额还可以控制挂起语句的时间,默认的时间间隔是二个小时,超过了 这段时间,语句将失败,并且给用户或应用程序返回一条错误消息,如 同完全未挂起语句的情况一样。
有四种可以恢复的命令:
1、可以恢复的select 语句:只有select 用户临时表空间中的空间 时,才可以恢复select 语句,主要指select 语句执行orader by、 distinct、union 等排序操作。
2、可以恢复的DML 命令:如insert、update、delete 的DML 命令 也会导致空间不足的情况。
3、可以恢复的SQL*LOADER 操作:SQL*LOADER 导入操作可 能导致空间不足的情形。
4、分配磁盘空间的DDL 命令:为新段或现有段分配磁盘空间的 所有DDL 命令均可以恢复。
create table ….. as select ..
create index….
一、配置可恢复的空间分配
启用和禁用可恢复的空间分配可以使用resumable_timeout 初始化参数,
如果将初始化参数resumable_timeout 设置为非零值,则将启用可恢复的
空间分配。为该初始化参数指定的值确定挂起操作等待分配更多资源的
时间,在超出此时限后将终止操作。SYS@orcl> show parameter resumable_timeout NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
resumable_timeout integer 0
SYS@orcl>注:resumable_timeout 值为0表示没有启用 可恢复的空间分配;如果把 0 改为 20 则表示 当表空间分配不足的时候,数据库会挂起20分钟的时间。如果在这 20分钟内给分配更多的表空间,则20分钟之后,就可以直接分配执行了
默认情况下,值0 表示禁用可恢复的空间分配。如果在系统级别启 用,则所有会话都可以利用可恢复的空间分配功能,如果控制哪些用户 可以启用可恢复的空间分配功能,则授予resumable 系统权限。
一旦拥有了resumable 系统权限,用户就可以使用alter session 命令启用
些功能。如果未将resumable_timeout 参数设置为非零或使用alter session 重写,
默认可恢复的时限值是7200 秒(二个小时)为了更方便地在数据字典视图dba_resumable 和user_resumable 中确定可
恢复语句,可以使用name 参数恢复启用可恢复的空间分配功能。查询dba_resumable 和user_resumable 时,可以看到启用了此功能的会话
的状态及当前执行的SQL 语句。可以使用alter session 禁用可恢复的空间分配功能。
实例:为scott 用户配置可恢复的空间分配功能
--1、为scott 授予resumable 系统权限
SYS@orcl> alter user scott identified by scott account unlock; -- 修改 scott用户的登录密码并解锁SYS@orcl>grantresumabletoscott; --分配权限
SYS@orcl>createtablespace test datafile '/u01/app/oracle/oradata/orcl/test.dbf'size90K autoextendoff; --创建一个表空间。该表空间大小只要90k且不能自动扩展SYS@orcl>selecttablespace_name,autoextensiblefromdba_data_fileswheretablespace_name ='TEST';
SYS@orcl> conn scott/scott -- 连接到 scott用户
-- 2、为scott 用户创建空间,并分配此表空间中的所有空间
SCOTT@orcl>createtablet1 tablespace testasselect*fromemp;
-- 3、表空间满后,再创建表,收到错语
SCOTT@orcl>createtablet2 tablespace testasselect*fromemp;
ERRORatline 1:
ORA-01658: unabletocreateINITIAL extentforsegmentintablespace TEST
--4、在scott 会话中启用可恢复的空间分配功能,时限是3600 秒(60分)
SCOTT@orcl>altersessionenable resumable timeout 3600;
-- 5、当用户scott 再创建表时,不会终止创建并发出错语消息,进入挂 起状态,查看警报日志显示了挂起些语句的信息
SCOTT@orcl>createtablet2 tablespace testasselect*fromemp;
--打开另一个会话,查看警告日志文件
[oracle@togogo ~]$ tail -f
/u01/app/oracle/diag/rdbms/orcl/orcl/trace/alert_orcl.log
-- 6、开启另一会话查询数据字典dba_resumable 了解挂起语句的其它信 息
SYS@orcl>selectuser_id,session_id,instance_id,status,name,sql_text,error_msgfromdba_resumable;
--7、DBA 为刚创建的表空间增加100M 的空间
SYS@orcl>alterdatabasedatafile '/u01/app/oracle/oradata/orcl/test.dbf' resize 300K;
-- 8、再次查询数据字典dba_resumable,确认可恢复操作是否已经完成
SYS@orcl>selectuser_id,session_id,instance_id,status,name,sql_text,error_msgfromdba_resumable;
--9、scott 用户的创建表语句成功完成
SCOTT@orcl>createtablet2 tablespace testasselect*fromemp;
--由于用户必须等待DBA 手动分配更多空间,所以响应速度不如用 户想的那么快。
另例:
--启用可恢复的空间分配功能
SYS@orcl> alter session enable resumable;
SYS@orcl> create tablespace test datafile
'/u01/app/oracle/oradata/orcl/test.dbf' size 100K autoextend off;
SYS@orcl> create table t1(id number) tablespace test;
--挂起
SYS@orcl> create table t2(id number) tablespace test;
--禁用可恢复的空间分配功能
SYS@orcl> alter session disable resumable;
--报错
SYS@orcl> create table t2(id number) tablespace test;
数据泵 方式数据的导入和导出
数据泵导入导出技术的结构
在数据泵导出导入技术中,涉及导出实用程序expdp和导入实用程序impdp,当启动数据泵导入或导出程序时,在数据库服务器端启动相应的服务器进程,完成数据的导入及导出任务,所以也称数据泵技术是基于oracle数据库服务器的,导入及导出的数据文件也保存在数据库服务器端。
expdp程序启动数据库服务器端的服务器进程,服务器进程完成数据的备份并将备份文件写入数据库服务器端磁盘中,导出的备份文件在导入时只能数据泵的导入实用程序impdp完成。
使用数据泵技术的优点:
1、可以只处理某些对象,或者不处理某些对象,或只处理某些对象下满足条件的数据
2、不实际导出的情况下,估计整个导出工作需要占用的磁盘空间
3、只导出元数据(如表结构),不导出实际数据。
4、可以进行并行操作
数据泵导入导出的目录对象
数据泵作业在数据库服务器上创建所有的备份文件,要求数据泵必须使用目录对象,以防止用户误操作数据库服务器上特定目录下的操作系统文件。目录对象对应于操作系统上的一个指定目录。
如果当前用户是DBA用户,可以使用默认的目录对象而不必再创建数据泵操作的工作目录。此时数据泵作业会将备份文件、日志文件以及SQL文件存储在该目录下,查看默认目录:SQL> col directory_name for a15
SQL> col owner for a23
SQL> col directory_path for a50
SQL> select * from dba_directories where directory_name='DATA_PUMP_DIR';不具备目录对象的数据泵作业错误
[oracle@oracle Desktop]$ expdp scott/scott
Export: Release 11.2.0.4.0 - Production on Fri Jan 17 17:04:18 2014
Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved.
Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
ORA-39002: invalid operation
ORA-39070: Unable to open the log file.
ORA-39145: directory object parameter must be specified and non-null
---如果需要自已创建目录对象,需要具有create any directory权限,首先向scott用户授权create any directory,然后创建属于scott用户的数据泵目录对象。
SQL> grant create any directory to scott;
SQL> conn scott/scott
SQL> create directory scott_dump_dir as '/home/oracle';
sys用户给 普通用户 scott 授权 创建文件目录和访问sys用户创建的文件目录的权限
---给scott用户 授权创建文件目录
SYS@orcl> grant create any directory to scott; Grant succeeded. SYS@orcl> ho ls /home/oracle
a.dmp database extertablefile h:1dept.sql h:1.lst h:emp.txt oyt.lst rlwrap-0.37.tar.gz
b.dmp Desktop grid h:1emp.txt h:1spooltest.txt oracle_system_files_back rlwrap-0.37 SYS@orcl> ho mkdir /home/oracle/dexp SYS@orcl> ho ls /home/oracle
a.dmp database dexp grid h:1emp.txt h:1spooltest.txt oracle_system_files_back rlwrap-0.37
b.dmp Desktop extertablefile h:1dept.sql h:1.lst h:emp.txt oyt.lst rlwrap-0.37.tar.gz
---sys用户创建 文件目录 dexpdirectory
SYS@orcl> create directory dexpdirectory as '/home/oracle/dexp'; Directory created.
---把sys用户创建的 文件目录 dexpdirectory 给普通用户scott 读写的权限
SYS@orcl> grant read ,write on directory dexpdirectory to scott; Grant succeeded. SYS@orcl>
使用如下SQL查询具有READ和WRITE权限的目录
expdp参数
[oracle@localhost ~]$ expdp help =y Export: Release 11.2.0.3.0 - Production on Sun Jul 15 21:55:23 2018 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. The Data Pump export utility provides a mechanism for transferring data objects
between Oracle databases. The utility is invoked with the following command: Example: expdp scott/tiger DIRECTORY=dmpdir DUMPFILE=scott.dmp You can control how Export runs by entering the 'expdp' command followed
by various parameters. To specify parameters, you use keywords: Format: expdp KEYWORD=value or KEYWORD=(value1,value2,...,valueN)
Example: expdp scott/tiger DUMPFILE=scott.dmp DIRECTORY=dmpdir SCHEMAS=scott
or TABLES=(T1:P1,T1:P2), if T1 is partitioned table USERID must be the first parameter on the command line. ------------------------------------------------------------------------------ The available keywords and their descriptions follow. Default values are listed within square brackets. ATTACH
Attach to an existing job.
For example, ATTACH=job_name. CLUSTER
Utilize cluster resources and distribute workers across the Oracle RAC.
Valid keyword values are: [Y] and N. COMPRESSION
Reduce the size of a dump file. --对导出的文件dump 进行压缩
Valid keyword values are(压缩方式): ALL(所有压缩), DATA_ONLY(数据压缩,可以理解为:表数据的压缩), [METADATA_ONLY](默认压缩:元数据压缩,可以理解为表结构的压缩) and NONE(不压缩). CONTENT
Specifies data to unload.(指定要导出的数据。)
Valid keyword values are: [ALL](导出所有数据), DATA_ONLY(数据) and METADATA_ONLY(元数据). DATA_OPTIONS
Data layer option flags.(指定一个选项)
Valid keyword values are: XML_CLOBS. DIRECTORY
Directory object to be used for dump and log files.(必须要指定的目录对象) DUMPFILE
Specify list of destination dump file names [expdat.dmp].(导出文件)
For example, DUMPFILE=scott1.dmp(文件名称), scott2.dmp(文件名称), dmpdir(文件目录名称):scott3.dmp(文件名称).
ENCRYPTION
Encrypt part or all of a dump file.(对导出的dump文件进行加密)
Valid keyword values are: ALL(全部加密), DATA_ONLY(对数据加密), ENCRYPTED_COLUMNS_ONLY(对数据列加密), METADATA_ONLY(对元数据加密) and NONE(不加密). ENCRYPTION_ALGORITHM (加密算法)
Specify how encryption should be done.
Valid keyword values are: [AES128](默认128位加密), AES192 and AES256. ENCRYPTION_MODE (加密模式)
Method of generating encryption key.
Valid keyword values are: DUAL, PASSWORD and [TRANSPARENT]. ENCRYPTION_PASSWORD (对加密文件创建一个数据口令)
Password key for creating encrypted data within a dump file. ESTIMATE
Calculate job estimates.(分析)
Valid keyword values are: [BLOCKS](默认为:数据库分析) and STATISTICS(统计分析). ESTIMATE_ONLY (仅仅分析大小不导出数据文件)
Calculate job estimates without performing the export. EXCLUDE (排除)
Exclude specific object types.
For example, EXCLUDE=SCHEMA:"='HR'".(要导出除了HR对象以外的对象的整个数据库数据信息)1)"EXCLUDE=SCHEMA:\"='HR'\"" 2)将EXCLUDE=SCHEMA:"='HR'"加入到参数文件中
vi togogo
加入EXCLUDE=SCHEMA:"='HR'"
parfile=togogo
FILESIZE
Specify the size of each dump file in units of bytes. (指定最大的dump文件的大小) FLASHBACK_SCN (用于指定导出特定scn时刻的表数据)
SCN used to reset session snapshot. FLASHBACK_TIME (指定导出特定时间点的表数据)
Time used to find the closest corresponding SCN value. FULL (整库导出)
Export entire database [N]. HELP (显示出帮助信息)
Display Help messages [N]. INCLUDE (包含:指定导出时要包含的对象类型及相关对象)
Include specific object types.
For example, INCLUDE=TABLE_DATA. JOB_NAME (数据泵是以作业的方式来运行的:指定一个作业的名称 ,也可不指定则系统默认指定一个名称)
Name of export job to create. LOGFILE
Specify log file name [export.log]. (指定一个日志文件的名称) NETWORK_LINK (当要导出远程的数据库的时候可以指定一个databaselike的标识)
Name of remote database link to the source system. NOLOGFILE
Do not write log file [N]. (不写日志文件) PARALLEL
Change the number of active workers for current job. (指定几个并行的工作任务) PARFILE
Specify parameter file name. (参数文件) QUERY (导出表的部分数据 ,使用 query 参数)
Predicate clause used to export a subset of a table.
For example, QUERY=employees:"WHERE department_id > 10". REMAP_DATA
Specify a data conversion function. (指定一个转换的函数,重新映射数据。作用:把敏感的数据通过一个转行方法给转换掉)
For example, REMAP_DATA=EMP.EMPNO:REMAPPKG.EMPNO. REUSE_DUMPFILES (同名文件时 是否需要自动覆盖)
Overwrite destination dump file if it exists [N]. SAMPLE (导出多少)
Percentage of data to be exported. SCHEMAS (导出什么模式:即:导出哪个数据库用户的数据)
List of schemas to export [login schema]. SERVICE_NAME
Name of an active Service and associated resource group to constrain Oracle RAC resources. SOURCE_EDITION
Edition to be used for extracting metadata. STATUS (显示状态信息)
Frequency (secs) job status is to be monitored where
the default [0] will show new status when available. TABLES (导出表)
Identifies a list of tables to export.
For example, TABLES=HR.EMPLOYEES,SH.SALES:SALES_1995. TABLESPACES (导出表空间)
Identifies a list of tablespaces to export.
TRANSPORTABLE (传输表)
Specify whether transportable method can be used.
Valid keyword values are: ALWAYS and [NEVER]. TRANSPORT_FULL_CHECK
Verify storage segments of all tables [N]. TRANSPORT_TABLESPACES (传输表空间)
List of tablespaces from which metadata will be unloaded. VERSION (版本:高版本的数据导入到低版本数据库的时候:需要制定版本信息)
Version of objects to export.
Valid keyword values are: [COMPATIBLE], LATEST or any valid database version. ------------------------------------------------------------------------------ The following commands are valid while in interactive mode.(交互式命令,中途是可以暂停的。)
Note: abbreviations are allowed. ADD_FILE (增加文件)
Add dumpfile to dumpfile set. CONTINUE_CLIENT
Return to logging mode. Job will be restarted if idle. EXIT_CLIENT (退出客户端执行)
Quit client session and leave job running. FILESIZE (文件大小)
Default filesize (bytes) for subsequent ADD_FILE commands. HELP
Summarize interactive commands. KILL_JOB (结束当前作业)
Detach and delete job. PARALLEL (平行度)
Change the number of active workers for current job. REUSE_DUMPFILES (覆盖)
Overwrite destination dump file if it exists [N]. START_JOB (开始作业)
Start or resume current job.
Valid keyword values are: SKIP_CURRENT. STATUS (查看作业状态)
Frequency (secs) job status is to be monitored where
the default [0] will show new status when available. STOP_JOB (停止作业)
Orderly shutdown of job execution and exits the client.
Valid keyword values are: IMMEDIATE.attach
用于在客户会话与已存在导出作业之间建立关联,
语法如下:attach=[schema_name.]job_name,schema_name
用于指定方案名,job_name指定导出作业名,如果使用attach选项,在命令行除了连接字符串和attach选项外,不能指定任何其它选项。expdp scott/tiger attach=scott.export_jobcontent
用于指定要导出的内容,默认是all,
语法如下:
CONTENT={ALL | DATA_ONLY | METADATA_ONLY},
当设置content选项为all时,将导出对象定义及其所有数据,当设置该选项为data_only时,只能导出对象数据;当设置该选项为metadata_only时,只导出对象定义。expdp scott/tiger directory=dump dumpfile=a.dmp content=metadata_onlydirectory
用于指定转储文件和日志文件所在位置。
语法如下:directory=directory_object,
directory_object用于指定目录对象名称。目录对象是使用create directory语句建立的对象,而不是os目录。
expdp scott/tiger directory=dump dumpfile=a.dmpdumpfile
指定转储文件的名称,默认名称为expda.dmp,
语法如下:dumpfile=[directory_object:]file_name[,...],
directory_object指定目录对象名
file_name指定转储文件名。
expdp scott/tiger directory=dump1 dumpfile=dump2:a.dmpestimate
用于指定估算被导出表所占用磁盘空间的方法,默认值为blocks,
语法如下:
Estimate={blocks|statistics},设置blocks时,oracle会按照目标对象占用的数据块个数乘以数据块尺寸估算对象占用的空间,
设置statistics时,oracle会根据最近的统计值估算对象占用的空间。
expdp scott/tiger tables=emp estimate=statistics directory=dump dumpfile=a.dmpestimate_only
用于指定是否估算出作业所占用的磁盘空间,默认n,
语法如下:estimate_only={y|n},
设置为y时,导出作业只估算对象所占用的磁盘空间,而不会执行导出操作,
设置为n时,导出作业不仅估算对象所占用的磁盘空间,且会执行导出操作。
expdp scott/tiger estimate_only=y nologfile=yexclude
用于指定执行导出操作时要排除的对象类型或相关对象,
语法如下:exclude=object_type[:name_clause][,...],
object_type指定要排除的对象类型,
name_clause指定要排除的具体对象,
exclude和include不能同时使用。
expdp scott/tiger directory=dump dumpfile=a.dmp exclude=viewfilesize
用于指定导出文件的最大尺寸,默认值是0(表示文件尺寸无限制)
语法如下:filesize=integer[B|K|M|G]
expdp scott/tiger directory=dump dumpfile=hr_3M.dmp filesize=3Mflashback_time
指定导出特定时间点的表数据。
语法如下:flashback_time=”to_timestamp(time_value)”
time_value用于指定日期时间值,
flashback_time和flashback_scn不能同时用。
expdp scott/tiger directory=dump dumpfile=a.dmp flashback_time=”to_teimstamp(’25-08-2009 14:34:00’,’dd-mm-yyyy hh24:mi:ss’)”flashback_scn
用于指定导出特定scn时刻的表数据。
语法如下:flashback_scn=scn_value
expdp scott/tiger directory=dump dumpfile=a.dmp flashback_scn=385823full
指定数据库模式导出,默认主n,
语法如下:full={y|n},
设置为y时,表示执行数据库导出。
expdp scott/tiger directory=dump dumpfile=full.dmp full=yinclude
指定导出时要包含的对象类型及相关对象。
语法如下:include=object_type[:name_clause][,...],
object_type指定要导出的对象类型,
name_clause指定要导出的对象名。
expdp scott/tiger directory=dump dumpfile=a.dmp include=tablejob_name
指定导出作业的名称,
语法如下:job_name=jobname_string,
jobname_string用于指定导出作业的名称。
expdp scott/tiger directory=dump dumpfile=a.dmp job_name=wanglilogfile
指定导出日志文件的名称,默认名称为export.log,
语法如下:LOGFILE=[directory_object:]file_name。
directory_object用于指定目录对象名称,
file_name用于指定导出日志文件名。
expdp scott/tiger directory=dump dumpfile=a.dmp logfile=a.lognetwork_link
指定数据库链名,如果要将远程数据库对象导出到本地例程的转储文件中,必须设置些选项。
语法如下:NETWORK_LINK=source_database_link 。
source_database_link 用于指定数据库链名。
expdp scott/tiger directory=dump dumpfile=a.dmp network_like=orclnologfile
用于指定禁止发生导出日志文件,默认值n,
语法如下:nologfile={y|n}
设置为y时,导出操作不会生成日志文件 。
expdp scott/tiger dumpfile=dump:a.dmp nologfile=yparallel
用于指定执行导出操作的并行进程个数,默认是1,
语法如下:parallel=integer
Integer用于指定并行进程个数。通过执行并行导出操作,可以加快导出速度。Expdp scott/tiger directory=dump dumpfile=a.dmp parallel=3parfile
指定导出参数文件的名称,
语法如下:PARFILE=[directory_path]file_name。
directory_path指定参数文件所在目录,
file_name指定参数文件名。
参数文件a.txt示例如下:
tables=dept,emp
Directory=dump
Dumpfile=tab.dmp
参数文件不能包含parfile选项。参数文件里不指定directory_pathExpdp scott/tiger parfile=a.txtQuery
指定过滤导出数据的where条件,
语法如下;query=[schema.][table_name:]query_lause
Schema用于指定方案名,table_name指定表名,
query_lause指定条件限制子句,
query选项不能与connect=metadata_only、estimate_only、transport_tablespaces等选项同时使用。
expdp scott/tiger directory=dump dumpfile=a.dmp tables=emp query=’”where deptno=20”’schemas
指定执行方案模式导出,默认为当前用户方案,
语法如下:SCHEMAS=方案名称[,…]
方案名称:用于指定方案名,用户可以导出自身方案,但如果要导出其它方案,须具有exp_full_daabase角色或DBA角色。Expdp system/manager directory=dump dumpfile=a.dmp schemas=scott,systemstatus
指定显示导出作业进程的详细状态,默认为0,
语法如下:STATUS=[整数],
整数用于指定显示导出作业状态的时间间隔(秒),指定了该选项后,每隔特定时间会显示作业完成的百分比。
expdp system/manager directory=dump dumpfile=a.dmp full=y status=30tables
用于指定表模式导出。
语法如下:TABLES=[schema_name.]table_name[:partition_name][,…]
schema_name指定方案名,table_name指定要导出的表名,
partition_name用于指定要导出的分区名。用户可以直接导出其自身方案的表,但要导出其它方案的表,须具有exp_full_daabase角色或DBA角色。
expdpd system/manager directory=dump dumpfile=a.dmp tables=scott.dept,scott.emptablespaces
指定要导出的表空间列表,
语法如下:TABLESPACE=tablespace_name[,…]
tablespace_name用于指定要导出的表空间。指定选项时,会导出该表空间上的所有表。Expdp system/manager directory=dump dumpfile=a.dmp tablespaces=user01transport_full_check
用于指定被搬移表空间和末搬移表演关联关系的检查方式,默认值是n,
语法如下:TRANSPORT_FULL_CHECK={Y|N}
设置为y时,导出作业会检查表空间之间的完整关联关系,如果表所在表空间或其索引所在表空间只有一个表空间被搬移,将显示错误信息,
当设置该选项为n时,导出作业只检查单端依赖,如果搬移索引所在的表空间但末搬移表所在表空间,将显示错误信息,如果搬移表所在表空间,末搬移索引所在表空间,则不会显示错误信息
expdp system/manager directory=dump dumpfile=b.dmp transport_tablespaces=user01 transport_full_check=ytransport_tablespaces
指定执行表空间模式导出,
语法如下:TRANSPORT_TABLESPACES=Tablespace_name[,…]
Tablespace_name用于指定要导出的表空间名称,导出表空间时,要求数据库用户必须有exp_full_database角色或DBA角色。expdp system/manager directory=dump dumpfile=b.dmp transport_tablespaces=user01

数据泵导出实例
使用empd可以导出整个数据库、单个模式、特定的表或特定的表空间。
1、导出整个数据库
我们使用system用户登录数据库,限制备份的数据文件大小为230M,一旦备份数据文件满,则自动创建一个新的备份文件,使用%U来实现备份文件的自动创建,nologfile=y即不记录备份过程。
[oracle@oracle Desktop]$ expdp system/oracle dumpfile=pump_dir:mydb_%U.dat filesize=230M nologfile=y job_name=tom full=y
2、导出一个模式;
导出scott模式,在例子中没有schema参数,但是默认导出登录数据库时的模式对象。
[oracle@oracle Desktop]$ expdp scott/scott dumpfile=scott_dump_dir:scottschema.dmp logfile=scott_dump_dir:scottschema.log或
[oracle@oracle Desktop]$ expdp scott/scott directory= scott_dump_dir dumpfile=scottschema.dmp logfile=scott_dump_dir:scottschema.log schemas=scott3、导出特定的表
使用tables参数指定导入的表的列表,如果该表不属于登录的用户,但是登录用户有访问这些表的权限,则tables参数的表必须使用schema.tablename的方式。
[oracle@oracle Desktop]$ expdp system/oracle dumpfile=pump_dir:scott_tables_%U.dat tables=scott.emp,scott.dept nologfile=y job_name=only_scott4、导出表空间
导出表空间使用tablespaces参数,如果有多个表空间需要导出,表空间名使用逗号隔开,使用parallel参数指定数据导出并行线程数量,与之对应使用替换变量%U来创建相应数量的备份数据文件,这样每个线程可以独立写一个备份数据文件,提高导出速度。[oracle@oracle Desktop]$ expdp system/oracle dumpfile=pump_dir:users_tbs_%U.dmp tablespaces=users filesize=230M parallel=2 logfile=users_tbs.log job_name=exp_users_tbs5、导出数据;
使用content参数,可以指定导出表数据和元数据(应用参数all),导出表行数据(对应参数data_only)或只导出元数据即表以及其他数据库对象的定义(对应参数metadata_only)
[oracle@oracle Desktop]$ expdp system/oracle dumpfile=pump_dir:mydb_dataony_%U.dat filesize=230M job_name=larry full=y content=data_only logfile=pump_dir:mydb_exp_dataonly.log6、使用参数文件
在使用expdp导出数据时,由于参数很多导致每次执行备份都输入一大串指令,这样不但繁琐且不易修改,数据泵技术允许使用参数文件,用户在参数文件中创建各种参数,保存该文件paraname.par文件,然后再执行导出时使用parfile指定参数文件的位置执行导出备份。[oracle@oracle ~]$ vi paraname.par
directory=pump_dir
dumpfile=para_data_only_%U.dmp
content=data_only
exclude=table:"in('salgrade','bonus')"
logfile=para_data_only.log
filesize=50M
parallel=2
job_name=para_data_only
[oracle@oracle ~]$ expdp scott/scott parfile=/home/oracle/paraname.par7、估计空间导出文件的空间大小
estimate_only计算导出数据所需要的存储空间,在导出的数据大小不清楚时,事先知道备份文件的大小,可以提前分配磁盘空间,防止由于磁盘空间不足引起的expdp导出作业停止。[oracle@oracle ~]$ expdp system/oracle full=y estimate_only=y estimate=statistics nologfile=y使用STATISTICS方法计算system用户所有数据库对象的大小。最后给出一个总的估计结果。
8:交互式导出整个库
[oracle@localhost ~]$ expdp system/oracle directory=DEXPDIRECTORY dumpfile=full.dmp full=y Export: Release 11.2.0.3.0 - Production on Tue Jul 17 22:41:02 2018 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. Connected to: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
Starting "SYSTEM"."SYS_EXPORT_FULL_02": system/******** directory=DEXPDIRECTORY dumpfile=full.dmp full=y
Estimate in progress using BLOCKS method...
Processing object type DATABASE_EXPORT/SCHEMA/TABLE/TABLE_DATA
Total estimation using BLOCKS method: 436.6 MB
Processing object type DATABASE_EXPORT/TABLESPACE
Processing object type DATABASE_EXPORT/PROFILE
Processing object type DATABASE_EXPORT/SYS_USER/USER
Processing object type DATABASE_EXPORT/SCHEMA/USER
Processing object type DATABASE_EXPORT/ROLE
Processing object type DATABASE_EXPORT/GRANT/SYSTEM_GRANT/PROC_SYSTEM_GRANT
Processing object type DATABASE_EXPORT/SCHEMA/GRANT/SYSTEM_GRANT
Processing object type DATABASE_EXPORT/SCHEMA/ROLE_GRANT
Processing object type DATABASE_EXPORT/SCHEMA/DEFAULT_ROLE
Processing object type DATABASE_EXPORT/SCHEMA/TABLESPACE_QUOTA
Processing object type DATABASE_EXPORT/RESOURCE_COST
Processing object type DATABASE_EXPORT/TRUSTED_DB_LINK
Processing object type DATABASE_EXPORT/SCHEMA/SEQUENCE/SEQUENCE
Processing object type DATABASE_EXPORT/SCHEMA/SEQUENCE/GRANT/OWNER_GRANT/OBJECT_GRANT
Processing object type DATABASE_EXPORT/DIRECTORY/DIRECTORY
Processing object type DATABASE_EXPORT/DIRECTORY/GRANT/OWNER_GRANT/OBJECT_GRANT
Processing object type DATABASE_EXPORT/CONTEXT
Processing object type DATABASE_EXPORT/SCHEMA/PUBLIC_SYNONYM/SYNONYM
Processing object type DATABASE_EXPORT/SCHEMA/SYNONYM
Processing object type DATABASE_EXPORT/SCHEMA/TYPE/INC_TYPE
Processing object type DATABASE_EXPORT/SCHEMA/TYPE/TYPE_SPEC
Processing object type DATABASE_EXPORT/SCHEMA/TYPE/GRANT/OWNER_GRANT/OBJECT_GRANT
Processing object type DATABASE_EXPORT/SYSTEM_PROCOBJACT/PRE_SYSTEM_ACTIONS/PROCACT_SYSTEM
Processing object type DATABASE_EXPORT/SYSTEM_PROCOBJACT/PROCOBJ
Processing object type DATABASE_EXPORT/SYSTEM_PROCOBJACT/POST_SYSTEM_ACTIONS/PROCACT_SYSTEM
Processing object type DATABASE_EXPORT/SCHEMA/PROCACT_SCHEMA
Processing object type DATABASE_EXPORT/SCHEMA/XMLSCHEMA/XMLSCHEMA
Processing object type DATABASE_EXPORT/SCHEMA/TABLE/TABLE
Processing object type DATABASE_EXPORT/SCHEMA/TABLE/PRE_TABLE_ACTION
Processing object type DATABASE_EXPORT/SCHEMA/TABLE/GRANT/OWNER_GRANT/OBJECT_GRANT
Processing object type DATABASE_EXPORT/SCHEMA/TABLE/COMMENT
ORA-39171: Job is experiencing a resumable wait.
ORA-01652: unable to extend temp segment by 128 in tablespace TBS_20_GROUP
ORA-39171: Job is experiencing a resumable wait.
ORA-01652: unable to extend temp segment by 128 in tablespace TBS_20_GROUP
ORA-39171: Job is experiencing a resumable wait.
ORA-01652: unable to extend temp segment by 128 in tablespace TBS_20_GROUP
ORA-39171: Job is experiencing a resumable wait.
ORA-01652: unable to extend temp segment by 128 in tablespace TBS_20_GROUP Export> status Job: SYS_EXPORT_FULL_02
Operation: EXPORT
Mode: FULL
State: EXECUTING
Bytes Processed: 0
Current Parallelism: 1
Job Error Count: 0
Dump File: /home/oracle/dexp/full.dmp
bytes written: 4,096 Worker 1 Status:
Process Name: DW01
State: EXECUTING
Object Type: DATABASE_EXPORT/SCHEMA/TABLE/COMMENT
Completed Objects: 720
Worker Parallelism: 1 Export> stop_job
Are you sure you wish to stop this job ([yes]/no): yes [oracle@localhost ~]$ ls /home/oracle/dexp/
export.log full.dmp
[oracle@localhost ~]$
impdp参数
[oracle@localhost ~]$ impdp help=y Import: Release 11.2.0.3.0 - Production on Mon Jul 16 00:31:14 2018 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. The Data Pump Import utility provides a mechanism for transferring data objects
between Oracle databases. The utility is invoked with the following command: Example: impdp scott/tiger DIRECTORY=dmpdir DUMPFILE=scott.dmp You can control how Import runs by entering the 'impdp' command followed
by various parameters. To specify parameters, you use keywords: Format: impdp KEYWORD=value or KEYWORD=(value1,value2,...,valueN)
Example: impdp scott/tiger DIRECTORY=dmpdir DUMPFILE=scott.dmp USERID must be the first parameter on the command line. ------------------------------------------------------------------------------ The available keywords and their descriptions follow. Default values are listed within square brackets. ATTACHAttach to an existing job. (用于在客户会话与已存在导出作业之间建立关联)
For example, ATTACH=job_name. CLUSTER
Utilize cluster resources and distribute workers across the Oracle RAC.
Valid keyword values are: [Y] and N. CONTENT
Specifies data to load.
Valid keywords are: [ALL], DATA_ONLY and METADATA_ONLY. DATA_OPTIONS
Data layer option flags.
Valid keywords are: SKIP_CONSTRAINT_ERRORS. DIRECTORY
Directory object to be used for dump, log and SQL files. DUMPFILE
List of dump files to import from [expdat.dmp].
For example, DUMPFILE=scott1.dmp, scott2.dmp, dmpdir:scott3.dmp. ENCRYPTION_PASSWORD
Password key for accessing encrypted data within a dump file.
Not valid for network import jobs. ESTIMATE
Calculate job estimates.
Valid keywords are: [BLOCKS] and STATISTICS. EXCLUDE
Exclude specific object types.
For example, EXCLUDE=SCHEMA:"='HR'". FLASHBACK_SCN
SCN used to reset session snapshot. FLASHBACK_TIME
Time used to find the closest corresponding SCN value. FULL
Import everything from source [Y]. HELP
Display help messages [N]. INCLUDE
Include specific object types.
For example, INCLUDE=TABLE_DATA. JOB_NAME
Name of import job to create. LOGFILE
Log file name [import.log]. NETWORK_LINK
Name of remote database link to the source system. NOLOGFILE
Do not write log file [N]. PARALLEL
Change the number of active workers for current job. PARFILE
Specify parameter file. PARTITION_OPTIONS
Specify how partitions should be transformed.
Valid keywords are: DEPARTITION, MERGE and [NONE]. QUERY
Predicate clause used to import a subset of a table.
For example, QUERY=employees:"WHERE department_id > 10". REMAP_DATA
Specify a data conversion function.
For example, REMAP_DATA=EMP.EMPNO:REMAPPKG.EMPNO. REMAP_DATAFILE (将源数据文件名转变为目标数据文件名)
Redefine data file references in all DDL statements.
REMAP_SCHEMA (用于将源方案的所有对象装载到目标方案中 fromuser touser )
Objects from one schema are loaded into another schema. REMAP_TABLE
Table names are remapped to another table.
For example, REMAP_TABLE=HR.EMPLOYEES:EMPS. REMAP_TABLESPACE
Tablespace objects are remapped to another tablespace. REUSE_DATAFILES
Tablespace will be initialized if it already exists [N]. SCHEMAS
List of schemas to import. SERVICE_NAME
Name of an active Service and associated resource group to constrain Oracle RAC resources. SKIP_UNUSABLE_INDEXES
Skip indexes that were set to the Index Unusable state. SOURCE_EDITION
Edition to be used for extracting metadata. SQLFILE
Write all the SQL DDL to a specified file. STATUS
Frequency (secs) job status is to be monitored where
the default [0] will show new status when available. STREAMS_CONFIGURATION
Enable the loading of Streams metadata TABLE_EXISTS_ACTION
Action to take if imported object already exists.
Valid keywords are: APPEND, REPLACE, [SKIP] and TRUNCATE. TABLES
Identifies a list of tables to import.
For example, TABLES=HR.EMPLOYEES,SH.SALES:SALES_1995. TABLESPACES
Identifies a list of tablespaces to import. TARGET_EDITION
Edition to be used for loading metadata. TRANSFORM
Metadata transform to apply to applicable objects.
Valid keywords are: OID, PCTSPACE, SEGMENT_ATTRIBUTES and STORAGE. TRANSPORTABLE
Options for choosing transportable data movement.
Valid keywords are: ALWAYS and [NEVER].
Only valid in NETWORK_LINK mode import operations. TRANSPORT_DATAFILES
List of data files to be imported by transportable mode. TRANSPORT_FULL_CHECK
Verify storage segments of all tables [N]. TRANSPORT_TABLESPACES
List of tablespaces from which metadata will be loaded.
Only valid in NETWORK_LINK mode import operations. VERSION
Version of objects to import.
Valid keywords are: [COMPATIBLE], LATEST or any valid database version.
Only valid for NETWORK_LINK and SQLFILE. ------------------------------------------------------------------------------ The following commands are valid while in interactive mode.
Note: abbreviations are allowed. CONTINUE_CLIENT
Return to logging mode. Job will be restarted if idle. EXIT_CLIENT
Quit client session and leave job running. HELP
Summarize interactive commands. KILL_JOB
Detach and delete job. PARALLEL
Change the number of active workers for current job. START_JOB
Start or resume current job.
Valid keywords are: SKIP_CURRENT. STATUS
Frequency (secs) job status is to be monitored where
the default [0] will show new status when available. STOP_JOB
Orderly shutdown of job execution and exits the client.
Valid keywords are: IMMEDIATE. [oracle@localhost ~]$attach
用于在客户会话与已存在导入作业之间建立关联,
语法如下:attach=[schema_name.]job_name,schema_name
用于指定方案名,job_name指定导出作业名,如果使用attach选项,在命令行除了连接字符串和attach选项外,不能指定任何其它选项。impdp scott/tiger attach=import_jobcontent
用于指定要导入的内容,默认是all,语法如下:
CONTENT={ALL | DATA_ONLY | METADATA_ONLY},
专业 专注 超越 数据泵
当设置content选项为all时,将导入对象定义及其所有数据,当设置该选项为data_only时,只能导入对象数据;当设置该选项为metadata_only时,只导入对象定义。impdp scott/tiger directory=dump dumpfile=a.dmp content=data_only tables=dept,empdirectory
用于指定转储文件所在位置。
语法如下:directory=directory_object,
directory_object用于指定目录对象名称。目录对象是使用create directory语句建立的对象,而不是os目录。
impdp scott/tiger directory=dump dumpfile=a.dmp tables=empdumpfile
指定转储文件的名称,默认名称为expda.dmp,
语法如下:dumpfile=[directory_object:]file_name[,...],directory_object指定目录对象名,file_name指定转储文件名。
impdp scott/tiger directory=dump dumpfile=a.dmp tables=empestimate
用于指定估算执行网络导入操作时要生成的数据量,默认值为blocks,
语法如下:Estimate={blocks|statistics},设置blocks时,oracle会根据数据块个数乘以数据块尺寸估算要生成的数据量,设置statistics时,oracle会根据统计值估算对要生成的数据量。
impdp scott/tiger tables=emp estimate=statistics directory=dump dumpfile=a.dmpexclude
用于指定执行导入操作时要过滤的对象类型或特定对象,
语法如下:exclude=object_type[:name_clause][,...],
object_type指定对象类型,
name_clause指定对象名。
impdp scott/tiger directory=dump dumpfile=a.dmp exclude=clusterflashback_time
指定导入特定时间点的表数据。
语法如下:flashback_time=”to_timestamp(time_value)”
time_value用于指定日期时间值,
flashback_time和flashback_scn不能同时用。
impdp scott/tiger directory=dump flashback_time=”to_teimstamp(’25-08-2009 14:34:00’,’dd-mm-yyyy hh24:mi:ss’)”flashback_scn
用于指定导入特定scn时刻的表数据。
语法如下:flashback_scn=scn_value
impdp scott/tiger directory=dump flashback_scn=385823full
指定是否要导入转储文件的全部内容,默认y
,语法如下:full={y|n},
设置为y时,表示所有内容。
include
指定导入时要包含的对象类型及相关对象。
语法如下:include=object_type[:name_clause][,...],
object_type指定要导入的对象类型,
name_clause指定要导入的对象名。
job_name
指定导入操作的作业名称,
语法如下:job_name=jobname_string,
jobname_string用于指定导出作业的名称。
impdp scott/tiger directory=dump dumpfile=a.dmp job_name=wanglilogfile
指定导入日志文件的名称,默认名称为export.log,
语法如下:LOGFILE=[directory_object:]file_name。
directory_object用于指定目录对象名称,
file_name用于指定导出日志文件名。
impdp scott/tiger directory=dump dumpfile=a.dmp logfile=a.lognetwork_link
指定数据库链名,如果要将远程数据库对象导入到本地例程的转储文件中,必须设置些选项。
语法如下:NETWORK_LINK=source_database_link 。
source_database_link用于指定数据库链名。
impdp scott/tiger directory=dump tables=emp network_like=orclnologfile
用于指定禁止生成入日志文件,默认值n,
语法如下:nologfile={y|n}设置为y时。
impdp scott/tiger dumpfile=a.dmp nologfile=yparallel
用于指定执行并行导入操作,默认是1,
语法如下:parallel=integer
Integer用于指定并行进程个数。通过执行并行导出操作,可以加快导出速度。
impdp scott/tiger directory=dump dumpfile=a.dmp parallel=3parfile
指定导入参数文件的名称,
语法如下:PARFILE=[directory_path]file_name。
directory_path指定参数文件所在目录,
file_name指定参数文件名。
参数文件a.txt示例如下: tables=dept,emp
Directory=dump
Dumpfile=tab.dmp
参数文件不能包含parfile选项。参数文件里不指定directory_pathimpdp scott/tiger parfile=a.txtquery
指定过滤导入数据的where条件,
语法如下;query=[schema.][table_name:]query_lause
Schema用于指定方案名,table_name指定表名,
query_lause指定条件限制子句,
query选项不能与connect=metadata_only、estimate_only、transport_tablespaces等选项同时使用。
schemas
指定执行方案模式导入,默认为当前用户方案,
语法如下:SCHEMAS=方案名称[,…]
方案名称:用于指定方案名,用户可以导入自身方案,但如果要导入其它方案,须具有exp_full_daabase角色或DBA角色。
impdp system/manager directory=dump dumpfile=tab.dmp schemas=scottstatus
指定显示导入作业的详细状态,默认为0,
语法如下:STATUS=[整数],
整数用于指定显示导出作业状态的时间间隔(秒),指定了该选项后,每隔特定时间会显示作业完成的百分比。
tables
用于指定表模式导入。语法如下:TABLES=[schema_name.]table_name[:partition_name][,…]
schema_name指定方案名,table_name指定要导入的表名,partition_name用于指定要导入的分区名。
impdpd system/manager directory=dump dumpfile=tab.dmp tables=emptablespaces
指定执行表空间模式导入,语法如下:TABLESPACE=tablespace_name[,…]
tablespace_name用于指定要导入的表空间。
impdp system/manager directory=dump dumpfile=a.dmp tablespaces=user01transport_full_check
用于指定被搬移表空间和末搬移表演关联关系的检查方式,默认值是n,语法如下:TRANSPORT_FULL_CHECK={Y|N}设置为y时,导入作业会检查表空间之间的完整关联关系,如果表所在表空间或其索引所在表空间只有一个表空间被搬移,将显示错误信息,当设置该选项为n时,导入作业只检查单端依赖,如果搬移索引所在的表空间,但末搬移表所在表空间,将显示错误信息,如果搬移表所在表空间,末搬移索引所在表空间,则不会显示错误信息
impdp system/manager directory=dump dumpfile=b.dmp transport_tablespaces=user01 transport_full_check=y transport_datafiles=’/u01/app/oracle/tbs6.dbf’transport_tablespaces
指定执行表空间模式导入,语法如下:TRANSPORT_TABLESPACES=Tablespace_name[,…]
Tablespace_name用于指定表空间名称,导入表空间时,要求数据库用户必须有imp_full_database角色或DBA角色。
impdp system/manager directory=dump dumpfile=b.dmp transport_tablespaces=user01transport_datafiles
指定搬移表空间时要被导入到目标数据库的数据文件
Table_exists_action
指定当表存在时,导入作业要执行的操作。默认是skip,语法如下:
table_exists_action={skip|append|truncate|replace}skip_unusable_indexes
指定导入时是否跳过不可使用的索引,默认是n,语法如下:skip_unusable_indexes={y|n}
reuse_datafiles
指定建立表空间时是否覆盖已存在的数据文件,默认n,语法如下:Reuse_datafiles={y|n}
remap_tablespace
用于将源表空间的所有对象导入到目标表空间中,语法如下:remap_tablespace=source_tablespace:target_tablespace。source_tablespace指定源表间名称, target_tablespace指定目标表空间名称。
remap_schema
用于将源方案的所有对象装载到目标方案中,语法如下:
remap_schema= source_schema:target_ schemaremap_datafile
将源数据文件名转变为目标数据文件名,语法如下:
remap_ datafile = source_ datafile:target_ datafile
数据泵导入实例
使用数据泵导入impdp可以导入基于使用数据泵导出的备份文件,可以导入整个数据库,指定的表空间,指定的表或指定的数据库对象类型,如索引、函数、存储过程和触发器等。
1、 导入整个数据库
导入整个数据库至少需要二个参数,一个是full,设置full=y说明是导入全库,一个是dumpfile,说明要导入的备份文件的目录和名称,job_name参数,允许切换到交换模式,允许终止或重启导入会话
[oracle@oracle oracle]$ mkdir /u01/app/oracle/wl/
[oracle@oracle ~]$ sqlplus / as sysdba
SQL> startup
SQL> create directory pump_dir as '/u01/app/oracle/wl';
SQL> select * from dba_directories where directory_name='PUMP_DIR';导出:
[oracle@oracle Desktop]$ expdp system/oracle dumpfile=pump_dir:full_db_%U.dat filesize=230M nologfile=y job_name=tom full=y
SQL> drop user scott cascade;导入:
[oracle@oracle Desktop]$ impdp system/oracle dumpfile=pump_dir:full_db_%U.dat logfile= pump_dir:myfulldb.log parallel=3 job_name=my_fulldb_impdp full=y2、 导入表空间
使用impdp导入特定的表空间时,需要有备份表空间文件,需要使用tablespaces参数说明要导入的表空间名,此时实际上是导入表空间中的所有数据库对象,由于表空间中有表对象,需要使用table_exits_action来告诉impdp怎么做,可以使用replace重建表,truncate删除当前表中的数据,然后使用备份文件中的表数据进行加载,但会跳过所有相关元数据。
[oracle@oracle Desktop]$ expdp system/oracle dumpfile=pump_dir:users_tbs_%U.dmp tablespaces=users filesize=230M parallel=2 logfile=users_tbs.log job_name=exp_users_tbs
SQL> drop table scott.emp;
SQL> drop table scott.dept;
[oracle@oracle Desktop]$ impdp system/oracle dumpfile=pump_dir:users_tbs_%U.dmp logfile= pump_dir:users.log tablespaces=users table_exists_action=replace3、 导入指定的表
使用impdp导入特定的表使用tables参数,该参数的后,是要导入表的对象列表,如果有多个表,使用逗号分隔。
[oracle@oracle Desktop]$ expdp system/oracle dumpfile=pump_dir:scott_tables_%U.dat tables=scott.emp,scott.dept nologfile=y job_name=only_scott
SQL> drop table scott.emp;
SQL> grant read,write on directory pump_dir to scott;
[oracle@oracle Desktop]$ impdp scott/scott dumpfile=pump_dir:scott_tables_%U.dat nologfile=y tables=emp table_exists_action=replace如将表dept,emp 导入到scott 方案中
impdp scott/tiger directory=dump_scott dumpfile=tab.dmp tables=dept,emp如将表dept 和emp 从scott 方案导入到system 方案中,对于方案的转移,必须使
用remap_shcema 参数impdp system/manage directory=dump_scott dumpfile=tab.dmp
tables=scott.dept,scott.emp remap_schema=scott:system4、 导入指定的数据库对象
导入指定的数据库对象使用include参数,恢复scott用户的所有表和触发器对象,对于已存在的表则重新加载数据
[oracle@oracle wl]$ expdp system/oracle dumpfile=pump_dir:full_db_%U.dat filesize=230M nologfile=y job_name=tom full=y
[oracle@oracle wl]$ impdp scott/scott dumpfile=pump_dir:full_db_%U.dat nologfile=y include=table,trigger table_exists_action=replace导入方案
如将dump_scott 目录下的schema.dmp 导入到scott 方案中impdp scott/tiger directory=dump_scott dumpfile=schema.dmp schemas=scott如将scott 方案中的所有对象转移到system 方案中
impdp system/redhat directory=dump_scott dumpfile=schema.dmp schemas=scott remap_schema=scott:system表空间迁移
参考传输表空间的方式来实现数据泵的传输表空间
Oracle 11g expdp中COMPRESSION参数
--Oracle 11g expdp中COMPRESSION参数:ALL, DATA_ONLY, [METADATA_ONLY] and NONE
--Oracle 10g expdp中COMPRESSION参数: (METADATA_ONLY) and NONE --一、创建目录对象
create directory wl as '/home/oracle';
grant read,write on directory wl to scott; --二、使用compression参数导出
--1)使用ALL参数,数据泵会对导出的源数据和表数据都进行压缩,这种方式导出的文件是最小的,不过用时相对也会比较长expdp scott/scott dumpfile=scott_ALL.dmp logfile=scott_ALL.log tables=emp directory=wl compression=ALL --2)使用DATA_ONLY参数,数据泵对表数据进行压缩,这种压缩方式对于大数据量的导出效果明显 expdp scott/scott dumpfile=scott_DATA_ONLY.dmp logfile=scott_DATA_ONLY.log tables=emp directory=wl compression=DATA_ONLY --3)使用METADATA_ONLY参数,数据泵只对源数据进行压缩,这种压缩执行后效果一般不是很明显,不过速度比较快
expdp scott/scott dumpfile=scott_METADATA_ONLY.dmp logfile=scott_METADATA_ONLY.log tables=emp directory=wl compression=METADATA_ONLY --4)使用NONE参数,不进行任何的压缩,导出后数据文件也是最大的
expdp scott/scott dumpfile=scott_NONE.dmp logfile=scott_NONE.log tables=emp directory=wl compression=NONE --比较生成的四个dump文件大小
du -sm scott*.dmp
--使用ALL参数和DATA_ONLY参数生成的备份文件基本一样大;使用METADATA_ONLY参数与NONE参数效果一样。 --对于默认方式,即不指定COMPRESSION参数,会采用默认的压缩方式METADATA_ONLYexpdp flashback_scn&flashback_time
conn / as sysdba
drop user wl cascade;
create user wl identified by wl;
grant connect,resource to wl;
GRANT execute ON dbms_flashback TO wl;
grant read,write on directory wl to wl;
conn wl/wl
create table test(id number);
insert into test values(1);
commit;
conn / as sysdba
select dbms_flashback.get_system_change_number from dual;
select current_scn from v$database;
2286919
select * from wl.test;
ID
---
1
insert into wl.test values(2);
commit;
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual;
2013-10-05 17:39:11
select * from wl.test; ID
----
1
2
insert into wl.test values(3);
commit;
select * from wl.test; ID
---
1
2
3 expdp wl/wl directory=wl dumpfile=scn.dmp logfile=scn.log flashback_scn=2286919
--导出1条数据
expdp wl/wl directory=wl dumpfile=scn1.dmp logfile=scn1.log
--导出3条数据
expdp wl/wl directory=wl dumpfile=scntime.dmp logfile=scntime.log flashback_time="'2013-10-05 17:39:11'"
--导出2条数据EXPDP IMPDP 中的并行度PARALLEL
-------PARALLEL工作原理:控制执行任务的最大线程数。当指定参数值为1 时,表示最多只启动一个线程处理数据,设置为 3 时,表示最多启动三个线程并行处理数据,由于同一时间一个DUMP文件只允许一个线程处理,所以输出的文件若只有一个,即使PARALLEL=10,也只有1 个线程进行数据输出,其他9 个空闲。所以PARALLEL需要与FILESIZE参数一起使用,指定每个DUMP文件的大小。
--如:
expdp system/oracle DIRECTORY=wl DUMPFILE=full_parallel_%U full=y LOGFILE=full_parallel PARALLEL=4 FILESIZE=200M status=1 --EXPDP在数据量较大并且配置合理的情况下,可以极大地提高我们的备份效率,但要经过测试,否则会出错expdp reuse_dumpfiles
--使用reuse_dumpfiles选项,用户可以指定是否覆盖原文件 expdp scott/scott directory=my_dir dumpfile=wl.dmp tables=emp expdp scott/scott directory=my_dir dumpfile=wl.dmp tables=emp --错误如下:
ORA-39001: invalid argument value
ORA-39000: bad dump file specification
ORA-31641: unable to create dump file "/home/oracle/wl.dmp"
ORA-27038: created file already exists --加reuse_dumpfiles=y选项
expdp scott/scott directory=my_dir dumpfile=wl.dmp tables=emp reuse_dumpfiles=yexpdp transportable
---TRANSPORTABLE用于指定表的迁移,TRANSPORTABLE方式不会导出真正的数据,而是采用将包含指定表的目标表空间迁移到目标数据库中,唯一不同的是TRANSPORTABLE的对象是个别表,而不是整个表空间。 ---一、在源数据库的tt1表空间上建立3张表
create directory my_dir as '/home/oracle';
grant read,write on directory my_dir to scott;
grant exp_full_database to scott;
create tablespace tt1 datafile '/u01/app/oracle/oradata/orcl/tt1.dbf' size 20M;
conn scott/scott
create table test1 (id number) tablespace tt1;
create table test2 (id number) tablespace tt1;
create table test3 (id number) tablespace tt1;
insert into test2 values(2);
insert into test3 values(3);
commit; --二、源数据库设置只读,并检查源数据库的DB_BLOCK_SIZE大小
select table_name,tablespace_name from user_tables where tablespace_name='TT1';
conn / as sysdba
alter tablespace tt1 read only;
show parameter db_block_size ---三、在源数据库使用TRANSPORTABLE方式导出test2和test3两张表,在源数据库导出的时候,Oracle并没有导出表的数据,而是采用了迁移表空间的方式,且导出之后提示需要传输数据文件信息。 host expdp scott/scott directory=my_dir dumpfile=tt.dmp tables=test2,test3 transportable=always ---四、将dump文件和数据文件发送到目标数据库站点
scp /u01/app/oracle/oradata/orcl/tt1.dbf oracle@192.168.0.11:/u01/app/oracle/oradata/orcl/
scp /home/oracle/tt.dmp oracle@192.168.0.11:/home/oracle/ ---五、将源数据库的tt1表空间置于READ WRITE状态:
alter tablespace tt1 read write; ---六、源数据库的操作结束,下面检查目标数据库指定表空间和对象是否存在
select tablespace_name from dba_tablespaces;
select object_name from user_objects where object_name like 'TEST%'; ---七、检查目标数据库的DB_BLOCK_SIZE和源数据库是否一致,如果不一致需要设置DB_nK_CACHE_SIZE的值
show parameter db_block_size
如不一致使用alter system进行设置,如下:
alter system set db_32K_cache_size= 64M; ---八、执行导入
create directory my_dd as '/home/oracle';
grant read,write on directory my_dd to scott;
grant imp_full_database to scott;
host impdp scott/scott directory=my_dd dumpfile=tt.dmp transport_datafiles='/u01/app/oracle/oradata/orcl/tt1.dbf' ---九、检查目标数据库指定表空间和对象是否存在
conn scott/scott
select object_name from user_objects where object_name like 'TEST%';
select table_name,tablespace_name from user_tables where tablespace_name='TT1';
select * from test2;
select * from test3; ---------需要注意,在拷贝本地的数据文件到远端站点之前,不要将表空间置于READ WRITE状态,否则会导致IMPDP过程出错。只要表空间在拷贝之前至于READ WRITE状态,即使在拷贝的时候再次置于READ ONLY状态也不行,这时导入过程也会出现错误。
=================================================================================================
Oracle 数据库导入与出的更多相关文章
- Oracle数据库导入csv文件(sqlldr命令行)
1.说明 Oracle数据库导入csv文件, 当csv文件较小时, 可以使用数据库管理工具, 比如DBevaer导入到数据库, 当csv文件很大时, 可以使用Oracle提供的sqlldr命令行工具, ...
- oracle数据库导入导出命令!(转)
oracle数据库导入导出命令! Oracle数据导入导出imp/exp 功能:Oracle数据导入导出imp/exp就相当与oracle数据还原与备份. 大多情况都可以用Oracle数据导入导出完成 ...
- Oracle数据库导入imp命令导入时1659错误处理
今天在自己的电脑上在给数据库导入表结构及数据时报1659错误,错误如下: IMP-00017:由于oracle错误1659,以下语句失败: “create table “T_TELETE” ..... ...
- Oracle 数据库导入导出 dmp文件
转自: http://hi.baidu.com/ooofcu/blog/item/ec5d1f9580d41f007af48077.html 首先询问对方数据库的表空间名称和大小,然后在你的oracl ...
- Oracle数据库导入导出命令总结
Oracle数据导入导出imp/exp就相当于oracle数据还原与备份.exp命令可以把数据从远程数据库服务器导出到本地的dmp文件,imp命令可以把dmp文件从本地导入到远处的数据库服务器中.利用 ...
- Oracle数据库导入导出命令总结 (详询请加qq:2085920154)
分类: Linux Oracle数据导入导出imp/exp就相当于oracle数据还原与备份.exp命令可以把数据从远程数据库服务器导出到本地的dmp文件,imp命令可以把dmp文件从本地导入到远处的 ...
- Oracle数据库导入导出总结(dmp文件)
Oracle 10G 管理页面(Oracle Enterprise Manager 10g): http://localhost:1158/em http://localhost:1158/em/co ...
- oracle数据库导入导出命令!
Oracle数据导入导出imp/exp 功能:Oracle数据导入导出imp/exp就相当与oracle数据还原与备份. 大多情况都可以用Oracle数据导入导出完成数据的备份和还原(不会造成数据的丢 ...
- oracle 数据库导入导出
要把公司的数据库导入到自己的电脑上(都需要再命令窗口下输入指令) 导出数据库的基本代码: exp zj_user_kf/oracle@tzsw_4 file=d:\test3.dmp full=y 导 ...
随机推荐
- nginx默认80端口被System占用,造成nginx启动报错的解决方案
今天启动window上的nginx总是报错 错误信息是bind() to 0.0.0.0:80 failed (10013: An attempt was made to access a socke ...
- oracle 远程连接不到dba用户
如果要远程连接192.168.10.44上的oracle,那么192.168.10.44服务器必须启动TNSListener.(配置文件 listener.ora) http://www.111cn. ...
- Python之线程 3 - 信号量、事件、线程队列与concurrent.futures模块
一 信号量 二 事件 三 条件Condition 四 定时器(了解) 五 线程队列 六 标准模块-concurrent.futures 基本方法 ThreadPoolExecutor的简单使用 Pro ...
- luogu P3250 [HNOI2016]网络
传送门 考虑只有一个询问,怎么使用暴力枚举最快的得到答案.因为要求最大的,所以可以把链按权值从大往小排序,然后往后扫,找到一个没有交的就是答案,直接退出 一堆询问,可以考虑整体二分,先二分一个值\(m ...
- linux下socket的连接队列的 backlog的分析
建立socket连接的过程 1:client发syn请求给server 2:server收到后把请求放在syn queue中,这个半连接队列的最大值是系统参数tcp_max_syn_backlog定义 ...
- linux sqlite replace into
sqlite replace into 文档详细说明: http://blog.sina.com.cn/s/blog_590be5290102vulh.html 这点很重要: 一般用replace语句 ...
- 移动端300ms延迟解决方法在vue 里面的一些小坑
话不多说上图: 至于import为什么会报错,瞅下面这个图: 总结:要搞懂个必须了解下es6的解构赋值才能在这方面装逼,网上资料一大堆自行百度.
- Shiro入门 - 通过自定义Realm连数数据库进行认证
添加shiro-realm.ini文件 [main] #自定义Realm myRealm=test.shiro.MyRealm #将myRealm设置到securityManager,相当于Sprin ...
- shiro-5基于url的权限管理
1.1 搭建环境 1.1.1 数据库 mysql5.1数据库中创建表:用户表.角色表.权限表(实质上是权限和资源的结合 ).用户角色表.角色权限表. 完成权限管理的数据模型创建. 1.1.2 开发环境 ...
- 转:MVC,MVP 和 MVVM 的图示
MVC,MVP 和 MVVM 的图示 - 阮一峰的网络日志http://www.ruanyifeng.com/blog/2015/02/mvcmvp_mvvm.html 作者: 阮一峰 日期: 201 ...