MyBatis - 3.Mapper XML映射文件
SQL 映射文件有很少的几个顶级元素(按照它们应该被定义的顺序):
- cache – 给定命名空间的缓存配置。
- cache-ref – 其他命名空间缓存配置的引用。
- resultMap – 是最复杂也是最强大的元素,用来描述如何从数据库结果集中来加载对象。
parameterMap – 已废弃!老式风格的参数映射。内联参数是首选,这个元素可能在将来被移除,这里不会记录。- sql – 可被其他语句引用的可重用语句块。
- insert – 映射插入语句
- update – 映射更新语句
- delete – 映射删除语句
- select – 映射查询语句
1.基本增删改查
定义接口
public interface employeeMapper {
public employee getEmployeeById(int id);
public int addEmp(employee employee);
public boolean editEmp(employee employee);
public int delEmp(int id);
}
EmplyoeeMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
namespace:命名空间,指定为接口的全类名
-->
<!--<mapper namespace="com.tancom.tangge.Mapper.employeeMapperpper">-->
<mapper namespace="com.tangge.Mapper.employeeMapper">
<!--接口方式:
id:接口方法名 ,resultType:返回类型
-->
<select id="getEmployeeById" resultType="com.tangge.model.employee">
select `id`, `last_name` lastName, `gender`, `email` from tbl_employee where id = #{id}
</select>
<!--插入 parameterType:参数类型(可以省略 -->
<insert id="addEmp" parameterType="com.tangge.model.employee">
insert into `db_mybatis`.`tbl_employee` ( `last_name`, `gender`, `email`)
values (#{lastName}, #{gender}, #{email} );
</insert>
<!--更新-->
<update id="editEmp">
update tbl_employee set last_name = #{lastName},email=#{email},gender=#{gender}
where id =#{id}
</update>
<!--删除-->
<delete id="delEmp">
DELETE FROM tbl_employee where id =#{id}
</delete>
</mapper>
---->【测试】:
/**
* 1.mybatis 允许直接定义下列返回值
* Boolean/Long/Integer
* 2.手动提交数据
*/
//插入
public static void insertTest() {
SqlSessionFactory sqlSessionFactory = SqlSessionFactoryUtil.getSqlSessionFactory();
//获取 SqlSession,能直接执行已经映射的SQL语句
SqlSession session = sqlSessionFactory.openSession();
try {
employeeMapper mapper = session.getMapper(employeeMapper.class);
//employee employee = new employee("jerry","fne@xwf.com",'0');
employee employee = new employee("lily", "lily@xwf.com", '1');
//1.插入数据
int rows = mapper.addEmp(employee);
System.out.println("影响行数:" + rows);
//2.手动提交数据
session.commit();
} finally {
session.close();
}
}
//修改
public static void updateTest() {
SqlSessionFactory sqlSessionFactory = SqlSessionFactoryUtil.getSqlSessionFactory();
//获取 SqlSession,能直接执行已经映射的SQL语句
SqlSession session = sqlSessionFactory.openSession();
try {
employeeMapper mapper = session.getMapper(employeeMapper.class);
employee employee = new employee(4,"jerry","fne@xwf.com",'1');
//1.修改数据
boolean rows = mapper.editEmp(employee);
System.out.println("修改+是否成功:" + rows);
//2.手动提交数据
session.commit();
} finally {
session.close();
}
}
//删除
public static void delTest() {
SqlSessionFactory sqlSessionFactory = SqlSessionFactoryUtil.getSqlSessionFactory();
//获取 SqlSession,能直接执行已经映射的SQL语句
SqlSession session = sqlSessionFactory.openSession();
try {
employeeMapper mapper = session.getMapper(employeeMapper.class);
//1.删除数据
int rows = mapper.delEmp(4);
System.out.println("影响行数:" + rows);
//2.手动提交数据
session.commit();
} finally {
session.close();
}
}
2.获取自增主键值
2.1 有自增功能数据库(mysql,sqlserver)
Insert, Update, Delete 's Attributes
| 属性 | 描述 |
|---|---|
useGeneratedKeys |
(仅对 insert 和 update 有用)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键 (比如:像 MySQL 和 SQL Server 这样的关系数据库管理系统的自动递增字段),默认值:false。 |
keyProperty |
(仅对 insert 和 update 有用)唯一标记一个属性,MyBatis 会通过 getGeneratedKeys 的返回值或者通过 insert 语句的 selectKey 子元素设置它的键值, 默认:unset。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表。 |
<!--
mybatis获取自增主键,和JDBC一样,利用statement.getGeneratedKeys()
- useGeneratedKeys="true" 使用自增主键
- keyProperty:指定对应的主键属性,将这个值赋给 javabean 的哪个属性
-->
<insert id="addEmp" parameterType="com.tangge.model.employee"
useGeneratedKeys="true" keyProperty="id">
insert into `db_mybatis`.`tbl_employee` ( `last_name`, `gender`, `email`)
values (#{lastName}, #{gender}, #{email} );
</insert>
---->【测试】:
//插入
public static void insertTest() {
SqlSessionFactory sqlSessionFactory = SqlSessionFactoryUtil.getSqlSessionFactory();
//获取 SqlSession,能直接执行已经映射的SQL语句
SqlSession session = sqlSessionFactory.openSession();
try {
employeeMapper mapper = session.getMapper(employeeMapper.class);
//employee employee = new employee("jerry","fne@xwf.com",'0');
employee employee = new employee("lily", "lily@xwf.com", '1');
//1.插入数据
int rows = mapper.addEmp(employee);
System.out.println("影响行数:" + rows);
System.out.println("添加的员工ID:" + employee.getId());
//2.手动提交数据
session.commit();
} finally {
session.close();
}
}
这里 employee.getId() 获取值
2.1 没有自增功能数据库(oracle)
oracle 不支持自增,使用序列
<!--oracle插入-->
<insert id="addEmpByOracle">
<!--
keyProperty:查出的主键值赋给 javabean 的哪个属性
order="BEFORE":当前SQL在插入SQL之前执行
resultType:返回值类型
-->
<selectKey keyProperty="id" order="BEFORE" resultType="Integer">
<!--查询主键的SQL-->
SELECT EMPLOYEES_SEQ.nextval FROM dual
</selectKey>
<!--oracle主键从序列中拿到-->
insert into employees ( employeeID, `last_name`, `gender`, `email`)
values (${id}, #{lastName}, #{gender}, #{email} );
</insert>
3.参数处理
3.1 单个参数
不做特殊处理。
#{参数}:取出参数值
3.2 多个参数(不推荐)
多个参数会被封装成一个 map。
#{} 就是从map中获取指定的key。
- key:param1...param2,或有参数的索引也可以
- value:传入的值
---->【测试】:
新定义一个接口,传入两个参数。
public employee getEmployeeParam(int id,String lastName);
以 paramN 传入key。
<select id="getEmployeeParam" resultType="com.tangge.model.employee">
select * from tbl_employee where id = #{param1} and last_name = #{param2}
</select>
3.3 命名参数(推荐)
明确指定封装参数时 map 的 key:@Param("id")
多个参数会被封装为一个 map。
key:使用 @Param 注解指定的值
value:参数值
---->【测试】:
public employee getEmployeeParam(@Param("id") int id,@Param("lastName") String lastName);
@Param 传入key
<select id="getEmployeeParam" resultType="com.tangge.model.employee">
<!--select * from tbl_employee where id = #{param1} and last_name = #{param2}-->
select * from tbl_employee where id = #{id} and last_name = #{lastName}
</select>
3.4 POJO
如果多个参数正好是我们业务逻辑的数据模型,我们可以直接传 POJO
#{属性名}:取出传入 pojo 的值
3.5 Map
如果多个参数不是我们业务逻辑的数据模型,没有对应的 POJO,我们也可以传入Map
#{key}: 取出 map 的值
---->【测试】:
<select id="getEmployeeMap" resultType="com.tangge.model.employee">
select * from tbl_employee where id = #{id} and last_name = #{lastName}
</select>
定义接口
public interface employeeMapper {
public employee getEmployeeMap(Map<String,Object> map);
...
}
测试方法:
public static void selectMapTest() {
SqlSessionFactory sqlSessionFactory = SqlSessionFactoryUtil.getSqlSessionFactory();
//获取 SqlSession,能直接执行已经映射的SQL语句我
SqlSession session = sqlSessionFactory.openSession();
try {
employeeMapper mapper = session.getMapper(employeeMapper.class);
Map<String, Object> map = new HashMap<String, Object>();
map.put("id", 1);
map.put("lastName", "tom");
employee employee = mapper.getEmployeeMap(map);
System.out.println(employee);
} finally {
session.close();
}
}
3.6 TO
如果多个参数不是我们业务逻辑的数据模型,又经常要使用,推荐写一个 TO(Transfer Object)数据传输对象
Page{
int size;
int index;
}
3.7 List/Collection/Array
把List或数组封装在Map中
Key:
- Collection ==> collection
- List ==> list
- 数组 ==> array
例子:
public void getEmpId(List<Integer> ids);
取值:第一个id的值:#{list[0]}
3.8 参数值的获取 (#{}与${}的区别)
#{}:可以获取map中的值或者pojo对象属性的值;
${}:可以获取map中的值或者pojo对象属性的值;
select * from tbl_employee where id=${id} and last_name=#{lastName}
Preparing: select * from tbl_employee where id=2 and last_name=?
区别:
#{}:是以预编译的形式,将参数设置到sql语句中;PreparedStatement;防止sql注入
${}:取出的值直接拼装在sql语句中;会有安全问题;
大多情况下,我们去参数的值都应该去使用#{};
原生jdbc不支持占位符的地方我们就可以使用${}进行取值
比如分表、排序。。。;按照年份分表拆分
select * from ${year}_salary where xxx;
select * from tbl_employee order by ${f_name} ${order}
---->【测试】:
这里${tableName}是预编译
<select id="getEmployeeMap" resultType="com.tangge.model.employee">
<!--select * from tbl_employee where id = ? and last_name =?-->
select * from ${tableName} where id = #{id} and last_name = #{lastName}
</select>
JAVA
Map<String, Object> map = new HashMap<String, Object>();
map.put("id", 1);
map.put("lastName", "tom");
map.put("tableName", "tbl_employee");
employee employee = mapper.getEmployeeMap(map);
3.9 #{}:更丰富的用法:
- 规定参数的一些规则:
javaType、 jdbcType、 mode(存储过程)、 numericScale、
resultMap、 typeHandler、 jdbcTypeName、 expression(未来准备支持的功能); jdbcType通常需要在某种特定的条件下被设置:在我们数据为null的时候,有些数据库可能不能识别mybatis对null的默认处理。比如Oracle(报错);
JdbcType OTHER:无效的类型;因为mybatis对所有的null都映射的是原生Jdbc的OTHER类型,oracle不能正确处理;由于全局配置中:jdbcTypeForNull=OTHER;oracle不支持;两种办法
1、#{email,jdbcType=OTHER};insert into employees ( employeeID, `last_name`, `gender`, `email`)
values (#{id}, #{lastName}, #{gender}, #{email,jdbcType=NULL} );
2、jdbcTypeForNull=NULL
<settings>
<setting name="jdbcTypeForNull" value="NULL"/>
</settings>
4.Select
4.1 返回 List
接口
public List<employee> getEmployeesByLastNameLike(String lastName);
resultType:如果返回一个集合,只要集合中元素的类型
配置
<!--返回List集合:
resultType:如果返回一个集合,只要集合中元素的类型
-->
<select id="getEmployeesByLastNameLike" resultType="com.tangge.model.employee">
select * from tbl_employee where last_name LIKE #{lastName}
</select>
---->【测试】:
public static void selectListTest() {
SqlSessionFactory sqlSessionFactory = SqlSessionFactoryUtil.getSqlSessionFactory();
SqlSession session = sqlSessionFactory.openSession();
try {
employeeMapper mapper = session.getMapper(employeeMapper.class);
List<employee> employees = mapper.getEmployeesByLastNameLike("%i%");
System.out.println(employees);
} finally {
session.close();
}
}
结果:
[com.tangge.model.employee{id=1, lastName='null', email='tom@guigu.com', gender=0}, com.tangge.model.employee{id=5, lastName='null', email='lily@xwf.com', gender=1}]
4.2 返回 Map
接口
//返回一条:记录的map,key 就是列名,value 就是对应的值
public Map<String,Object> getEmpByIdReturnMap(int id);
//返回多条:封装一个Map时,key 是这条记录的主键,value 是记录封装后的 javabean
//@MapKey("last_name") --> key可以得到 last_name 的 字段
@MapKey("id")
public Map<Integer,employee> getEmpByLastNameReturnMap(String lastName);
配置
resultType 的 Map 别名 map
<!--返回一条:Map集合:
resultType:如果返回一个集合,只要集合中元素的类型
-->
<select id="getEmpByIdReturnMap" resultType="map">
select * from tbl_employee where id = #{id}
</select>
<!--返回多条:Map集合:
resultType:如果返回一个集合,只要集合中元素的类型
-->
<select id="getEmpByLastNameReturnMap" resultType="map">
select * from tbl_employee where last_name LIKE #{lastName}
</select>
---->【测试】:
//返回多条 Map
public static void selectEmpByLastNameReturnMapTest() {
SqlSessionFactory sqlSessionFactory = SqlSessionFactoryUtil.getSqlSessionFactory();
SqlSession session = sqlSessionFactory.openSession();
try {
employeeMapper mapper = session.getMapper(employeeMapper.class);
Map<Integer ,employee> employees = mapper.getEmpByLastNameReturnMap("%i%");
System.out.println(employees);
//结果:
// {1={gender=0, last_name=tomi, id=1, email=tom@guigu.com}, 5={gender=1, last_name=lily, id=5, email=lily@xwf.com}}
} finally {
session.close();
}
}
//返回一条Map
public static void selectEmpByIdReturnMapTest() {
SqlSessionFactory sqlSessionFactory = SqlSessionFactoryUtil.getSqlSessionFactory();
SqlSession session = sqlSessionFactory.openSession();
try {
employeeMapper mapper = session.getMapper(employeeMapper.class);
Map<String ,Object> employees = mapper.getEmpByIdReturnMap(1);
System.out.println(employees);
//结果:
//{gender=0, last_name=tomi, id=1, email=tom@guigu.com}
} finally {
session.close();
}
}
5.resultMap 结果集
resultMap 元素是 MyBatis 中最重要最强大的元素。它可以让你从 90% 的 JDBC ResultSets 数据提取代码中解放出来, 并在一些情形下允许你做一些 JDBC 不支持的事情。 实际上,在对复杂语句进行联合映射的时候,它很可能可以代替数千行的同等功能的代码。 ResultMap 的设计思想是,简单的语句不需要明确的结果映射,而复杂一点的语句只需要描述它们的关系就行了。
属性:
- id 当前命名空间中的一个唯一标识,用于标识一个result map.
- type 类的完全限定名, 或者一个类型别名 (内置的别名可以参考上面的表格).
- autoMapping 如果设置这个属性,MyBatis将会为这个ResultMap开启或者关闭自动映射。这个属性会覆盖全局的属性 autoMappingBehavior。默认值为:unset。
子属性:
- constructor - 用于在实例化类时,注入结果到构造方法中
- idArg - ID 参数;标记出作为 ID 的结果可以帮助提高整体性能
- arg - 将被注入到构造方法的一个普通结果
- id – 一个 ID 结果;标记出作为 ID 的结果可以帮助提高整体性能
- result – 注入到字段或 JavaBean 属性的普通结果
- association – 一个复杂类型的关联;许多结果将包装成这种类型
- 嵌套结果映射 – 关联可以指定为一个 resultMap 元素,或者引用一个
- collection – 一个复杂类型的集合
- 嵌套结果映射 – 集合可以指定为一个 resultMap 元素,或者引用一个
- discriminator – 使用结果值来决定使用哪个 resultMap
- case – 基于某些值的结果映射
- 嵌套结果映射 – 一个 case 也是一个映射它本身的结果,因此可以包含很多相 同的元素,或者它可以参照一个外部的 resultMap。
- case – 基于某些值的结果映射
5.1 自定义结果映射规则
定义接口
public interface employeeMapperResultMap {
public employee getEmployeeById(int id);
}
XML配置
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.tangge.Mapper.employeeMapperResultMap">
<!--
resultMap:
自定义javabean规则,外部 resultMap 的命名引用。结果集的映射是 MyBatis 最强大的特性,对其有一个很好的理解的话,许多复杂映射的情形都能迎刃而解。
使用 resultMap 或 resultType,但不能同时使用。
- id:唯一id
- type:自定义java规则
-->
<resultMap id="MyEmp" type="com.tangge.model.employee">
<!--
id:指定主键封装规则
column:指定哪一列,
property:对应javabean属性
-->
<id column="id" property="id"></id>
<!--result:其他列的规则-->
<result column="last_name" property="lastName"></result>
<result column="email" property="email"></result>
</resultMap>
<select id="getEmployeeById" resultMap="MyEmp">
select * from tbl_employee where id = #{id}
</select>
</mapper>
---->【测试】:
public static void selectListTest() {
SqlSessionFactory sqlSessionFactory = SqlSessionFactoryUtil.getSqlSessionFactory();
SqlSession session = sqlSessionFactory.openSession();
try {
employeeMapperResultMap mapper = session.getMapper(employeeMapperResultMap.class);
employee employees = mapper.getEmployeeById(1);
System.out.println(employees);
} finally {
session.close();
}
}
结果:
com.tangge.model.employee{id=1, lastName='tomi', email='tom@guigu.com', gender=0}
5.2 关联查询
5.2.1 级联属性封装
tbl_employee 员工表,增加一个字段 dept_id
再增加一个部门表 tbl_dept
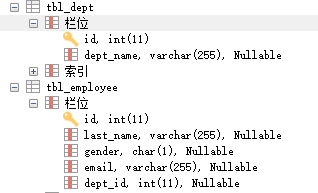
public class employee {
private int id;
private String lastName;
private String email;
private char gender;
private deptment dept; //部门
...
}
部门类
public class deptment {
private int departmentId;
private String departmentName;
...
}
配置 Mapper
<!--1.级联属性-->
<resultMap id="EmpAndDept" type="com.tangge.model.employee">
<id column="id" property="id"></id>
<result column="last_name" property="lastName"></result>
<!--级联属性
deptment:在employee类中定义 privdeptment dept;
-->
<result column="dept_id" property="dept.departmentId"></result>
<result column="dept_name" property="dept.departmentName"></result>
</resultMap>
<!--
查询结果:
id last_name gender email dept_id dept_name
-->
<select id="getEmpAndDept" resultMap="EmpAndDept">
SELECT a.*,b.`dept_name` FROM tbl_employee a
JOIN tbl_dept b
ON a.dept_id=b.id
WHERE a.`id`=#{id}
</select>
---->【测试】:
public static void selectEmpAndDept() {
SqlSessionFactory sqlSessionFactory = SqlSessionFactoryUtil.getSqlSessionFactory();
SqlSession session = sqlSessionFactory.openSession();
try {
employeeMapperResultMap mapper = session.getMapper(employeeMapperResultMap.class);
employee employees = mapper.getEmpAndDept(1);
System.out.println(employees);
/**
* 结果:
* employee{id=1, lastName='tomi', email='tom@guigu.com', gender=0,
* deptment=deptment{departmentId=1, departmentName='技术部'}}
*/
} finally {
session.close();
}
}
5.2.2 association 嵌套查询
association + property + javaType
association – 一个复杂类型的关联;许多结果将包装成这种类型
Mapper配置
<!--2.association定义联合对象-->
<resultMap id="EmpAndDept2" type="com.tangge.model.employee">
<id column="id" property="id"></id>
<result column="last_name" property="lastName"></result>
<!--
association:指定联合的对象
- property="dept":指定哪个属性是联合对象
- javaType:指定类型
-->
<association property="dept" javaType="com.tangge.model.deptment">
<id column="dept_id" property="departmentId"></id>
<result column="dept_name" property="departmentName"></result>
</association>
</resultMap>
<!--
查询结果:
id last_name gender email dept_id dept_name
-->
<select id="getEmpAndDept" resultMap="EmpAndDept2">
SELECT a.*,b.`dept_name` FROM tbl_employee a
JOIN tbl_dept b
ON a.dept_id=b.id
WHERE a.`id`=#{id}
</select>
结果:
employee{id=1, lastName='tomi', email='null', gender= , dept=deptment{departmentId=1, departmentName='技术部'}}
5.2.3 association 分步查询
association + select + column
定义部门接口, 获取部门的方法getDeptbyId
package com.tangge.Mapper;
import com.tangge.model.deptment;
public interface IdeptmentMapper {
public deptment getDeptbyId(int id);
}
创建XML
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.tangge.Mapper.IdeptmentMapper">
<select id="getDeptbyId" resultType="com.tangge.model.deptment">
select id,dept_name departmentName from tbl_dept where id = #{id}
</select>
</mapper>
使用分步查询
<!--
3.使用association分步查询:
3.1 按照员工id查询员工信息
3.2 根据员工的dept_id查询tbl_dept
3.3 把部门设置到员工中
-->
<resultMap id="MyEmpbyStep" type="com.tangge.model.employee">
<id column="id" property="id"></id>
<result column="last_name" property="lastName"></result>
<result column="email" property="email"></result>
<!--
association:定义关联对象的封装规则
- select:表名当前属性调用select指定的方法
- column:指定讲哪一列值传给方法
-->
<association property="dept"
select="com.tangge.Mapper.IdeptmentMapper.getDeptbyId"
column="dept_id">
</association>
</resultMap>
<!--getEmpAndDeptByStep-->
<select id="getEmpAndDeptByStep" resultMap="MyEmpbyStep">
select * from tbl_employee where id = #{id}
</select>
---->【测试】:
public static void selectEmpAndDeptStep() {
SqlSessionFactory sqlSessionFactory = SqlSessionFactoryUtil.getSqlSessionFactory();
SqlSession session = sqlSessionFactory.openSession();
try {
employeeMapperResultMap mapper = session.getMapper(employeeMapperResultMap.class);
employee employees = mapper.getEmpAndDeptByStep(1);
System.out.println(employees);
} finally {
session.close();
}
}
这里有个错误:蛋疼了1小时
---->【报错】:
Caused by: java.lang.IllegalArgumentException:
Mapped Statements collection does not contain value for com.tangge.Mapper.IdeptmentMapper.getDeptbyId
为什么TM没定义。查百度都没用
后来想起貌似没有给IdeptmentMapper.xml注册?????
<mapper resource="com/tangge/Mapper/IdeptmentMapper.xml"/>
ok了。
5.2.4 分步查询&延迟加载
lazyLoadingEnabled (默认false):延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置 fetchType属性来覆盖该项的开关状态。
aggressiveLazyLoading (默认true):当开启时,任何方法的调用都会加载该对象的所有属性。否则,每个属性会按需加载(参考 lazyLoadTriggerMethods).
lazyLoadTriggerMethods :指定哪个对象的方法触发一次延迟加载。
https://www.cnblogs.com/tangge/p/9518532.html#t1
<settings>
<!--显示指定每个我们需要更改的值,即使他是默认的。防止版本更迭带来的问题-->
<setting name="lazyLoadingEnabled" value="true" />
<setting name="aggressiveLazyLoading" value="false" />
<!--<setting name="mapUnderscoreToCamelCase" value="true"></setting>-->
</settings>
---->【报错】:
IDEA Cannot enable lazy loading because CGLIB is not available
原因是因为少了cglib.jar,而cglib.jar有引入了asm.jar,所以,这两个jar包都需要导入。然后再次编译测试就可以了。
public static void selectEmpAndDeptStep() {
SqlSessionFactory sqlSessionFactory = SqlSessionFactoryUtil.getSqlSessionFactory();
SqlSession session = sqlSessionFactory.openSession();
try {
employeeMapperResultMap mapper = session.getMapper(employeeMapperResultMap.class);
employee employees = mapper.getEmpAndDeptByStep(1);
// System.out.println(employees.getEmail());
System.out.println(employees);
/**
* (1)System.out.println(employees.getEmail());
* 只运行:select * from tbl_employee where id = 1
*
* (2)System.out.println(employees);
* 同时运行:
* 1.select * from tbl_employee where id = 1
* 2.select id,dept_name departmentName from tbl_dept where id = 1
*/
} finally {
session.close();
}
}
5.2.5 collection定义关联集合封装规则
collection – 一个复杂类型的集合
嵌套结果映射 – 集合可以指定为一个 resultMap 元素,或者引用一个
先新增字段,查询部门下的所有员工。private List<employee> employees;
public class deptment {
private int departmentId;
private String departmentName;
private List<employee> employees; //新增:部门下的所有员工
@Override
public String toString() {
return "deptment{" +
"departmentId=" + departmentId +
", departmentName='" + departmentName + '\'' +
", employees=" + employees +
'}';
}
}
接口
public interface IdeptmentMapper {
public deptment getDeptbyId(int id);
//这个,deptment下定义List<employee> 定义collection,
public deptment getDeptbyIdCollection(int id);
}
定义XML
<resultMap id="deptCollection" type="com.tangge.model.deptment">
<id column="dept_id" property="departmentId"></id>
<result column="dept_name" property="departmentName"></result>
<!--
collection定义关联的集合属性.
property:指定变量,这里List<employee> employees
ofType:指定集合类型
-->
<collection property="employees" ofType="com.tangge.model.employee">
<id column="id" property="id"></id>
<result column="last_name" property="lastName"></result>
<result column="email" property="email"></result>
</collection>
</resultMap>
<select id="getDeptbyIdCollection" resultMap="deptCollection">
SELECT a.*,b.`dept_name` FROM tbl_employee a
JOIN tbl_dept b
ON a.dept_id=b.id
WHERE b.`id`=#{id}
</select>
---->【测试】:
public static void selectDeptbyIdCollection() {
SqlSessionFactory sqlSessionFactory = SqlSessionFactoryUtil.getSqlSessionFactory();
SqlSession session = sqlSessionFactory.openSession();
try {
IdeptmentMapper mapper = session.getMapper(IdeptmentMapper.class);
deptment deptment = mapper.getDeptbyIdCollection(1);
System.out.println(deptment);
} finally {
session.close();
}
}
/**
* 结果:
* deptment{departmentId=1, departmentName='技术部',
* employees=[employee{id=1, lastName='tomi', email='tom@guigu.com', gender= , dept=null},
* employee{id=6, lastName='wew', email='wewe@qq.com', gender= , dept=null}]}
*/
5.2.6 collection分步查询
1.先查部门
2.再查部门下员工
定义部门接口 deptment getDeptbyIdCollectionByStep(int id);
public interface IdeptmentMapper {
public deptment getDeptbyId(int id);
//deptment下定义List<employee> 定义collection,
public deptment getDeptbyIdCollection(int id);
//分步collection定义:1.先查部门
public deptment getDeptbyIdCollectionByStep(int id);
}
查询部门Mapper映射
<resultMap id="deptCollectionByStep" type="com.tangge.model.deptment">
<id column="id" property="departmentId"></id>
<result column="dept_name" property="departmentName"></result>
<collection property="employees"
select="com.tangge.Mapper.employeeMapperResultMap.getEmployeesBydeptId"
column="id">
</collection>
</resultMap>
<!--public deptment getDeptbyIdCollectionByStep(int id);-->
<select id="getDeptbyIdCollectionByStep" resultMap="deptCollectionByStep">
select id,dept_name departmentName from tbl_dept where id = #{id}
</select>
collection.select 需要员工新增接口List<employee> getEmployeesBydeptId(int id)
public interface employeeMapperResultMap {
public employee getEmployeeById(int id);
//联合查询
public employee getEmpAndDept(int id);
//分步查询
public employee getEmpAndDeptByStep(int id);
//collection:分步查询2
public List<employee> getEmployeesBydeptId(int id);
}
员工的Mapper映射
<!--collection:分步2:再查询部门下的所有员工-->
<select id="getEmployeesBydeptId" resultType="com.tangge.model.employee">
select * from tbl_employee where dept_id = #{id}
</select>
---->【测试】:
public static void selectDeptbyIdCollectionByStep() {
SqlSessionFactory sqlSessionFactory = SqlSessionFactoryUtil.getSqlSessionFactory();
SqlSession session = sqlSessionFactory.openSession();
try {
IdeptmentMapper mapper = session.getMapper(IdeptmentMapper.class);
deptment deptment = mapper.getDeptbyIdCollectionByStep(1);
System.out.println(deptment);
} finally {
session.close();
}
}
5.2.7 collection扩展:多列值&fetchType
fetchType:有效值为 lazy(延迟)和eager(立即)。
<resultMap id="deptCollectionByStep" type="com.tangge.model.deptment">
<id column="id" property="departmentId"></id>
<result column="dept_name" property="departmentName"></result>
<!--collection
- select:表名当前属性调用select指定的方法
- column:传入的值,多值传输封装为Map传递:
{key1=column1,key2=column2,..}
- fetchType:有效值为 lazy和eager。 如果使用了,它将取代全局配置参数lazyLoadingEnabled。
-->
<collection property="employees"
select="com.tangge.Mapper.employeeMapperResultMap.getEmployeesBydeptId"
column="{x_deptid=id}" fetchType="lazy">
</collection>
</resultMap>
5.2.8 discriminator 鉴别器
(场景需求):
判断性别:
女生:查部门
男生:lastName 赋值给 email
<!--
(场景需求):
判断性别:
女生:查部门
男生:lastName 赋值给 email
-->
<resultMap id="MyEmpDis" type="com.tangge.model.employee">
<id column="id" property="id"></id>
<result column="last_name" property="lastName"></result>
<result column="gender" property="gender"></result>
<!--
discriminator:
- column:指定判定的列
- javaType:列值对应javabean的类型
-->
<discriminator javaType="string" column="gender">
<!--男生 resultType:指定封装结果类型,不能缺少。 -->
<case value="0" resultType="com.tangge.model.employee">
<result column="last_name" property="email"></result>
</case>
<!--女生-->
<case value="1" resultType="com.tangge.model.employee">
<association property="dept" javaType="com.tangge.model.deptment">
<id column="dept_id" property="departmentId"></id>
<result column="dept_name" property="departmentName"></result>
</association>
</case>
</discriminator>
</resultMap>
<!--getEmpAndDeptByStep-->
<select id="getEmpAndDeptByStep" resultMap="MyEmpDis">
select * from tbl_employee where id = #{id}
</select>
---->【测试】:
如果是女生(id = 5):
employee{id=5, lastName='lily', email='null', gender=1, dept=deptment{departmentId=2, departmentName='null', employees=null}}
如果是男生(id = 1):
employee{id=1, lastName='tomi', email='tomi', gender=0, dept=null}
MyBatis - 3.Mapper XML映射文件的更多相关文章
- Mybatis学习--Mapper.xml映射文件
简介 Mapper.xml映射文件中定义了操作数据库的sql,每个sql是一个statement,映射文件是mybatis的核心. 映射文件中有很多属性,常用的就是parameterType(输入类型 ...
- Mybatis中的Mapper.xml映射文件sql查询接收多个参数
我们都知道,在Mybatis中的Mapper.xml映射文件可以定制动态SQL,在dao层定义的接口中定义的参数传到xml文件中之后,在查询之前mybatis会对其进行动态解析,通常使用#{}接收 ...
- Mapper.xml映射文件
查询订单关联查询用户: 使用resultType,ordersCustom可以通过继承orders获得其属性,再添加我们需要的用户字段. 使用resultMap,orders表中通过封装user对象来 ...
- mybatis学习------打包xml映射文件
编译mybatis时,idea不会将mybatis的xml映射文件一起打包进jar,即在编译好的jar包里缺少mybatis映射文件,导致网站加载失败 为解决这个问题,可在mybatis对应modul ...
- mybatis Mapper XML 映射文件
传送门:mybatis官方文档 Mapper XML 文件详解 一. 数据查询语句 1. select <select id="selectPerson" parameter ...
- MyBatis学习存档(3)——mapper.xml映射文件
MyBatis 真正的强大在于映射语句,专注于SQL,功能强大,SQL映射的配置却是相当简单 所以我们来看看映射文件的具体结构 一.xml节点结构 mapper为根节点 - namespace命名空间 ...
- 在mapper.xml映射文件中添加中文注释报错
问题描述: 在写mapper.xml文件时,想给操作数据库语句添加一些中文注释,添加后运行报如下错误: 思考 可能是写了中文注释,编译器在解析xml文件时,未能成功转码,从而导致乱码.但是文件开头也采 ...
- SSM_CRUD新手练习(4)修改生成的mapper.xml映射文件
我们为什么要修改呢,这是因为我们查询的时候,我们有时候需要连表查询,例如我们需要查询出员工表的信息(emp_id,emp_name...)与此同时,我们还想查询出该员工所在的部门(dept_name) ...
- springboot整合mybatis。mapper.xml资源文件放置到resources文件夹下的配置&别名使用配置
随机推荐
- ES6学习笔记七Generator、Decorators
Generator异步处理 { // genertaor基本定义,next()一步步执行 let tell=function* (){ yield 'a'; yield 'b'; return 'c' ...
- LSH(Locality Sensitive Hashing)原理与实现
原文地址:https://blog.csdn.net/guoziqing506/article/details/53019049 LSH(Locality Sensitive Hashing)翻译成中 ...
- git与eclipse集成之添加.gitignore文件
1.1. 添加.gitignore文件 .gitignore 配置文件用于配置不需要加入版本管理的文件 1.以斜杠/开头表示目录: 2.以星号*通配多个字符: 3.以问号?通配单个字符 4.以方括号[ ...
- xshell访问内网虚拟机
1 关闭虚拟机防火墙 chkconfig iptables off 2 查看VMware Network Adapter VMnet8的ip地址 3 虚拟机nat中设置端口转发,抓发至虚拟机内Linu ...
- openwrt页面显示问题修改
页面显示错误如下: 在不应该的位置显示了这个,查看配置文件: config igmpproxy option quickleave '1' config phyint o ...
- 前端跨域问题的总结&&nodejs 中间层的路由转发
前后端交互的时候,跨域是避不开的问题. 总结就是如下: 1.Cors 我在做前后端分离的时候,会采用cors 的方法:便于其他源的调用接口,这个可以设置成任意的源头,也可以允许指定的源头. 下面的是n ...
- how to avoid inheritance abuse
Liskov Principle: if S is a subtype of Type T, then any objects of type T may be repalced by objects ...
- Android apk互调
1.启动另外一个应用程序的主Activity. //这些代码是启动另外的一个应用程序的主Activity,当然也可以启动任意一个Activity ComponentName componetName ...
- 33)django-原生ajax,伪ajax
一:概述 对于WEB应用程序:用户浏览器发送请求,服务器接收并处理请求,然后返回结果,往往返回就是字符串(HTML),浏览器将字符串(HTML)渲染并显示浏览器上. 1.传统的Web应用 一个简单操作 ...
- 玩转 lua in Redis
一.引言 Redis学了一段时间了,基本的东西都没问题了.从今天开始讲写一些redis和lua脚本的相关的东西,lua这个脚本是一个好东西,可以运行在任何平台上,也可以嵌入到大多数语言当中,来扩展其功 ...