爬虫之进阶 twisted
简介
Twisted是用Python实现的基于事件驱动的网络引擎框架。Twisted诞生于2000年初,在当时的网络游戏开发者看来,无论他们使用哪种语言,手中都鲜有可兼顾扩展性及跨平台的网络库。Twisted的作者试图在当时现有的环境下开发游戏,这一步走的非常艰难,他们迫切地需要一个可扩展性高、基于事件驱动、跨平台的网络开发框架,为此他们决定自己实现一个,并从那些之前的游戏和网络应用程序的开发者中学习,汲取他们的经验教训。
Twisted支持许多常见的传输及应用层协议,包括TCP、UDP、SSL/TLS、HTTP、IMAP、SSH、IRC以及FTP。就像Python一样,Twisted也具有“内置电池”(batteries-included)的特点。Twisted对于其支持的所有协议都带有客户端和服务器实现,同时附带有基于命令行的工具,使得配置和部署产品级的Twisted应用变得非常方便。
- 使用基于事件驱动的编程模型,而不是多线程模型。
- 跨平台:为主流操作系统平台暴露出的事件通知系统提供统一的接口。
- “内置电池”的能力:提供流行的应用层协议实现,因此Twisted马上就可为开发人员所用。
- 符合RFC规范,已经通过健壮的测试套件证明了其一致性。
- 能很容易的配合多个网络协议一起使用。
- 可扩展。
架构概念
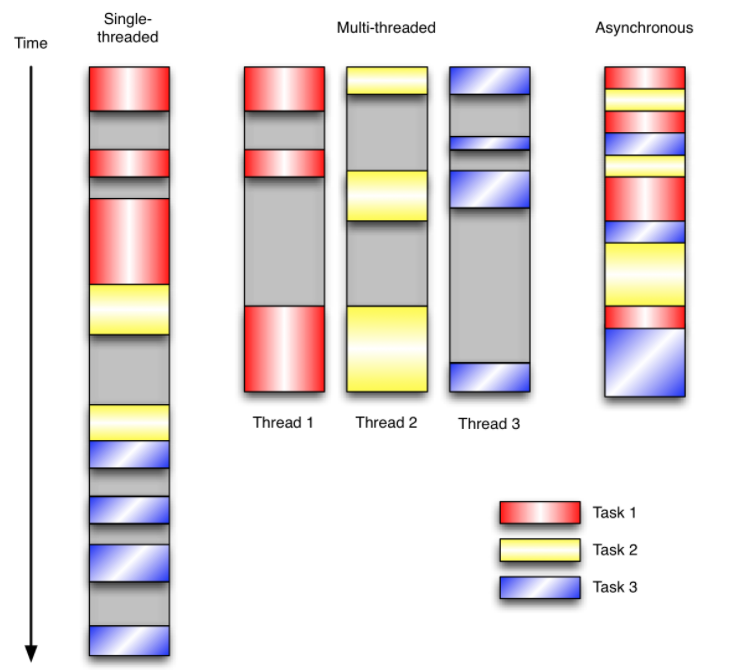
在单线程同步模型中,任务按照顺序执行。如果某个任务因为I/O而阻塞,其他所有的任务都必须等待,直到它完成之后它们才能依次执行。这种明确的执行顺序和串行化处理的行为是很容易推断得出的。如果任务之间并没有互相依赖的关系,但仍然需要互相等待的话这就使得程序不必要的降低了运行速度。
在多线程版本中,这3个任务分别在独立的线程中执行。这些线程由操作系统来管理,在多处理器系统上可以并行处理,或者在单处理器系统上交错执行。这使得当某个线程阻塞在某个资源的同时其他线程得以继续执行。与完成类似功能的同步程序相比,这种方式更有效率,但程序员必须写代码来保护共享资源,防止其被多个线程同时访问。多线程程序更加难以推断,因为这类程序不得不通过线程同步机制如锁、可重入函数、线程局部存储或者其他机制来处理线程安全问题,如果实现不当就会导致出现微妙且令人痛不欲生的bug。
在事件驱动版本的程序中,3个任务交错执行,但仍然在一个单独的线程控制中。当处理I/O或者其他昂贵的操作时,注册一个回调到事件循环中,然后当I/O操作完成时继续执行。回调描述了该如何处理某个事件。事件循环轮询所有的事件,当事件到来时将它们分配给等待处理事件的回调函数。这种方式让程序尽可能的得以执行而不需要用到额外的线程。事件驱动型程序比多线程程序更容易推断出行为,因为程序员不需要关心线程安全问题。
当我们面对如下的环境时,事件驱动模型通常是一个好的选择:
- 程序中有许多任务,而且…
- 任务之间高度独立(因此它们不需要互相通信,或者等待彼此)而且…
- 在等待事件到来时,某些任务会阻塞。
当应用程序需要在任务间共享可变的数据时,这也是一个不错的选择,因为这里不需要采用同步处理。
网络应用程序通常都有上述这些特点,这使得它们能够很好的契合事件驱动编程模型。
Reactor模式
Twisted实现了设计模式中的反应堆(reactor)模式,这种模式在单线程环境中调度多个事件源产生的事件到它们各自的事件处理例程中去。
Twisted的核心就是reactor事件循环。Reactor可以感知网络、文件系统以及定时器事件。它等待然后处理这些事件,从特定于平台的行为中抽象出来,并提供统一的接口,使得在网络协议栈的任何位置对事件做出响应都变得简单。
while True:
timeout = time_until_next_timed_event()
events = wait_for_events(timeout)
events += timed_events_until(now())
for event in events:
event.process()
reactor
管理回调链
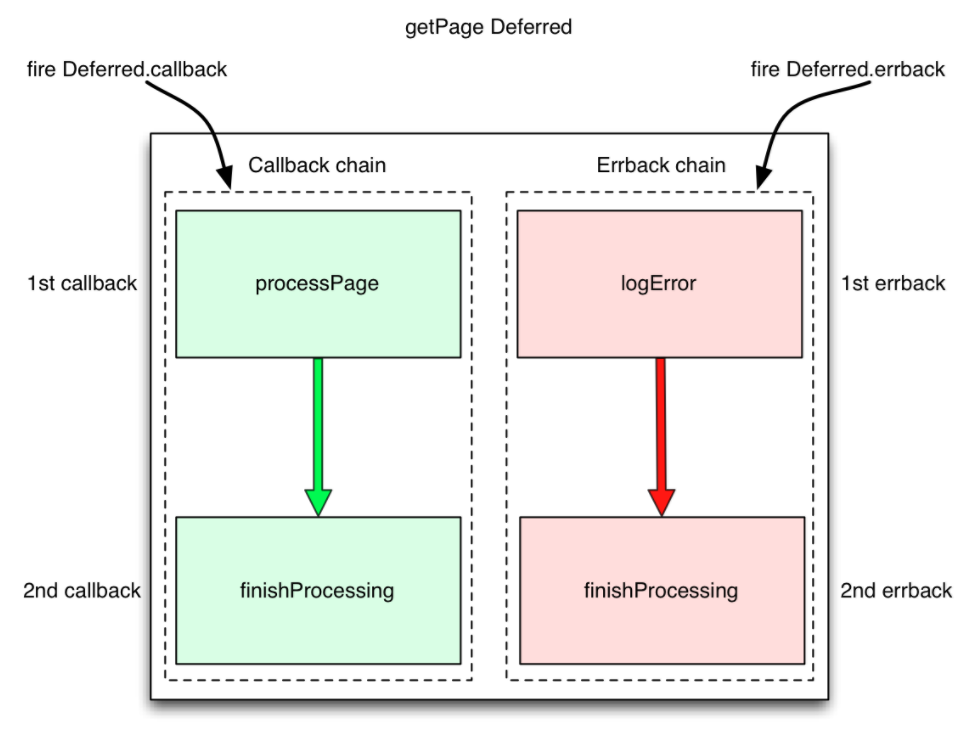
回调是事件驱动编程模型中的基础,也是reactor通知应用程序事件已经处理完成的方式。随着程序规模不断扩大,基于事件驱动的程序需要同时处理事件处理成功和出错的情况,这使得程序变得越来越复杂。若没有注册一个合适的回调,程序就会阻塞,因为这个事件处理的过程绝不会发生。出现错误时需要通过应用程序的不同层次从网络栈向上传递回调链。
import getPage def processPage(page):
print(page) def logError(error):
print(error) def finishProcessing(value):
print("Shutting down...")
exit(0) url = "http://google.com"
try:
page = getPage(url)
processPage(page)
except Error, e:
logError(error)
finally:
finishProcessing()
同步
from twisted.internet import reactor
import getPage def processPage(page):
print (page)
finishProcessing() def logError(error):
print (error)
finishProcessing() def finishProcessing(value):
print ("Shutting down...")
reactor.stop() url = "http://google.com"
getPage(url, processPage, logError) reactor.run()
异步
Deferreds
Deferred对象以抽象化的方式表达了一种思想,即结果还尚不存在。它同样能够帮助管理产生这个结果所需要的回调链。当从函数中返回时,Deferred对象承诺在某个时刻函数将产生一个结果。返回的Deferred对象中包含所有注册到事件上的回调引用,因此在函数间只需要传递这一个对象即可,跟踪这个对象比单独管理所有的回调要简单的多。
Deferred对象包含一对回调链,一个是针对操作成功的回调,一个是针对操作失败的回调。初始状态下Deferred对象的两条链都为空。在事件处理的过程中,每个阶段都为其添加处理成功的回调和处理失败的回调。当一个异步结果到来时,Deferred对象就被“激活”,那么处理成功的回调和处理失败的回调就可以以合适的方式按照它们添加进来的顺序依次得到调用。
Transports
Transports代表网络中两个通信结点之间的连接。Transports负责描述连接的细节,比如连接是面向流式的还是面向数据报的,流控以及可靠性。TCP、UDP和Unix套接字可作为transports的例子。它们被设计为“满足最小功能单元,同时具有最大程度的可复用性”,而且从协议实现中分离出来,这让许多协议可以采用相同类型的传输。Transports实现了ITransports接口.
Protocols
Protocols描述了如何以异步的方式处理网络中的事件。HTTP、DNS以及IMAP是应用层协议中的例子。Protocols实现了IProtocol接口。
Applications
Twisted是用来创建具有可扩展性、跨平台的网络服务器和客户端的引擎。在生产环境中,以标准化的方式简化部署这些应用的过程对于Twisted这种被广泛采用的平台来说是非常重要的一环。为此,Twisted开发了一套应用程序基础组件,采用可重用、可配置的方式来部署Twisted应用。这种方式使程序员避免堆砌千篇一律的代码来将应用程序同已有的工具整合在一起,这包括精灵化进程(daemonization)、日志处理、使用自定义的reactor循环、对代码做性能剖析等。
应用程序基础组件包含4个主要部分:服务(Service)、应用(Application)、配置管理(通过TAC文件和插件)以及twistd命令行程序。
Service
Service就是IService接口下实现的可以启动和停止的组件。Twisted自带有TCP、FTP、HTTP、SSH、DNS等服务以及其他协议的实现。
爬虫之进阶 twisted的更多相关文章
- 爬虫之进阶 基于twisted实现自制简易scrapy框架(便于对scrapy源码的理解)
1.调度器 class Scheduler(object): """调度器""" def __init__(self, engine): & ...
- 网页爬虫--scrapy进阶
本篇将谈一些scrapy的进阶内容,帮助大家能更熟悉这个框架. 1. 站点选取 现在的大网站基本除了pc端都会有移动端,所以需要先确定爬哪个. 比如爬新浪微博,有以下几个选择: www.weibo.c ...
- Node.js 网页爬虫再进阶,cheerio助力
任务还是读取博文标题. 读取app2.js // 内置http模块,提供了http服务器和客户端功能 var http=require("http"); // cheerio模块, ...
- 爬虫技术 -- 进阶学习(十)网易新闻页面信息抓取(htmlagilitypack搭配scrapysharp)
最近在弄网页爬虫这方面的,上网看到关于htmlagilitypack搭配scrapysharp的文章,于是决定试一试~ 于是到https://www.nuget.org/packages/Scrapy ...
- 爬虫技术 -- 进阶学习(七)简单爬虫抓取示例(附c#代码)
这是我的第一个爬虫代码...算是一份测试版的代码.大牛大神别喷... 通过给定一个初始的地址startPiont然后对网页进行捕捉,然后通过正则表达式对网址进行匹配. List<string&g ...
- 【转】零基础写Java知乎爬虫之进阶篇
转自:脚本之家 说到爬虫,使用Java本身自带的URLConnection可以实现一些基本的抓取页面的功能,但是对于一些比较高级的功能,比如重定向的处理,HTML标记的去除,仅仅使用URLConnec ...
- scrapy中运行爬虫时出现twisted critical unhandled error错误
1. 试试这条命令: twisted critical unhandled error on scrapy tutorial python python27\scripts\pywin32_posti ...
- 爬虫写法进阶:普通函数--->函数类--->Scrapy框架
本文转载自以下网站: 从 Class 类到 Scrapy https://www.makcyun.top/web_scraping_withpython12.html 普通函数爬虫: https:// ...
- 爬虫技术 -- 进阶学习(十一)【补充】获取html中meta标签中的content的内容
上一篇网易新闻页面信息抓取 -- htmlagilitypack搭配scrapysharp中提及了很多如何快速抓取html中的文本的语句, 但是meta标签中的content内容的抓取,没有提及到! ...
随机推荐
- Unity 3D中的阴影设置
在Unity 3D中,经常需要用到光照阴影,即Directional Light的Shadow,Shadow分为Hard Shadow和Soft Shadow.区别是Soft Shadow的阴影边缘比 ...
- Deviceiocontrol操作异常时,关于getlasterror的错误代码解析
[0]-操作成功完成. [1]-功能错误. [2]-系统找不到指定的文件. [3]-系统找不到指定的路径. [4]-系统无法打开文件. [5]-拒绝访问. [6]-句柄无效. [7]-存储控制块被损坏 ...
- docker创建image
=========================================================================在已有image基础上创建一个image======= ...
- Struts2多文件上传原理和示例
一.创建上传文件的页面,代码如下所示 1.Struts2也可以很方便地实现多文件上传. 在输入表单域增加多个文件域:multifileupload.jsp <%@ page lan ...
- 浏览器F12(开发者调试工具) 功能介绍
调试时使用最多的功能页面是:元素(ELements).控制台(Console).源代码(Sources).网络(Network)等. 元素(Elements):用于查看或修改HTML元素的属性.CSS ...
- listview-android:打造万能通用适配器(转)
转载:https://blog.csdn.net/q649381130/article/details/51781921: 1.前言 listview作为安卓项目中一个的明星控件,它的适配器的写法是广 ...
- RabbitMQ tutorial
一.安装RabbitMQ RabbitMQ是一套开源(MPL)的消息队列服务软件,是由 LShift 提供的一个 Advanced Message Queuing Protocol (AMQP) 的开 ...
- day3-三级目录
date = {"guangdong":{"guangzhou":{"tianhe":["tyx","zjxc ...
- robotframework在3.7下的搭建
网上看了大多安装RIDE都是在python2的环境下,今天试了下python3的安装,成功了,步骤如下: 1.首先是python3的安装,以及pip这些工具,具体的网上一堆,不再啰嗦 2.安装robo ...
- 【吴恩达课后编程作业】第二周作业 - Logistic回归-识别猫的图片
1.问题描述 有209张图片作为训练集,50张图片作为测试集,图片中有的是猫的图片,有的不是.每张图片的像素大小为64*64 吴恩达并没有把原始的图片提供给我们 而是把这两个图片集转换成两个.h5文件 ...