【新手向】使用nodejs抓取百度贴吧内容
参考教程:https://github.com/alsotang/node-lessons 1~5节
1. 通过superagent抓取页面内容
- superagent
- .get('http://www.cnblogs.com/wenruo/')
- .end(function(err, res) {
- if (err) {
- reject(err)
- } else {
- console.log(res.text)
- }
- })
OK 这样就获得了一份HTML代码。
因为获取HTML是异步的,所以我们封装一个函数,返回一个Promise。
- // 获取页面html
- function getHTML(url) {
- return new Promise(function(resolve, reject) {
- superagent.get(url)
- .end(function(err, res) {
- if (err) {
- reject(err)
- } else {
- resolve(res.text)
- }
- })
- })
- }
2. 通过cheerio筛选页面数据
总不能通过正则一点一点匹配出数据吧,有这样一个库: cheerio( https://github.com/cheeriojs/cheerio ),有了它,我们可以像jQuery一样轻松的从这个HTML代码中获取需要数据。
现在随便找了一个贴吧的帖子。
因为我们要获取一个帖子的全部内容,所以要首先要获取帖子的页数,然后分别爬取每一页的内容。通过检查元素找到数据对应的html中的位置,找到所对应的一个类 l_reply_num 然后发现其下有两个span,我们获取第二个的数据,就是总页数。

代码如下,这里通过 + 将字符串转为数字。
- function getPage(html) {
- let $ = cheerio.load(html)
- return +$('.l_reply_num span').eq(1).text()
- }
其他的数据,如标题,昵称,层数等,都可以通过同样的方法获取。
3. 控制并发数量
贴吧的高楼可以有几百上千页,我们能通过 pages.forEach(page => { getHTML(page) }) 同时发起多个异步请求获取数据,但是,网站有可能会因为你发出的并发连接数太多而当你是在恶意请求,把你的 IP 封掉。
这时我们可以通过 async ( https://github.com/caolan/async ) 来实现控制并发的数量,使用方法也很简单:
- var async = require("async")
- async.mapLimit(urls, 5, function(url, callback) {
- const response = fetch(url)
- callback(response.body)
- }, (err, results) => {
- if (err) throw err
- // results is now an array of the response bodies
- console.log(results)
- })
通过遍历数组,分别对其中的每一项发起请求,5为控制的并发数量。results是callback中返回数据的集合。
当然上面的代码假设fetch是同步函数了,否则callback应该放在回调函数里面。
4. 结果保存到文件
得到的数据很大,总不能在控制台看,一定要放到文件里。
- function writeFile(filename, content, cb) {
- fs.writeFile(filename, content, function(err) {
- if (err) {
- return console.error(err);
- }
- cb && cb()
- })
- }
包含三个参数,文件名,存储内容和回调函数。
整体代码如下:
- let superagent = require('superagent')
- let cheerio = require('cheerio')
- let async = require('async')
- let fs = require('fs')
- // 获取页面html
- function getHTML(url) {
- return new Promise(function(resolve, reject) {
- superagent.get(url)
- .end(function(err, res) {
- if (err) {
- reject(err)
- } else {
- resolve(res.text)
- }
- })
- })
- }
- // 获取帖子页数
- function getPage(html) {
- let $ = cheerio.load(html)
- return +$('.l_reply_num span').eq(1).text()
- }
- // 获取帖子标题
- function getTitle(html) {
- let $ = cheerio.load(html)
- return $('.core_title_txt').text()
- }
- // 获取帖子一页内容
- function getOnePage(url) {
- return getHTML(url).then(html => {
- let result = []
- let $ = cheerio.load(html)
- $('#j_p_postlist .l_post').each(function(idx, element) {
- let $element = $(element)
- let name = $element.find('.d_name a').text()
- let content = $element.find('.d_post_content').text()
- let floor = $element.find('.tail-info').eq($element.find('.tail-info').length-2).text()
- let time = $element.find('.tail-info').eq($element.find('.tail-info').length-1).text()
- name = name.replace(/[\s\r\t\n]/g, '')
- content = content.replace(/[\s\r\t\n]/g, '')
- if (floor) {
- result.push(`${floor}(${name}/${time})\n${content}\n\n`)
- }
- })
- return result.join('')
- }, err => {
- console.error(err)
- })
- }
- // 将内容写入到文件
- function writeFile(filename, content, cb) {
- fs.writeFile(filename, content, function(err) {
- if (err) {
- return console.error(err);
- }
- cb && cb()
- })
- }
- function getContent(url) {
- console.log('抓取中...')
- // 帖子后面可能会加 只看楼主 和 页码 选项 这里只添加只看楼主选项 将页码项删除
- let hasSeeLZ = false
- if (url.includes('?')) {
- let search = url.split('?')[1].split('&')
- url = url.split('?')[0]
- for (let query of search) {
- if (query.includes('see_lz')) {
- hasSeeLZ = true
- url = url + '?' + query
- break
- }
- }
- }
- // 开始抓取数据
- getHTML(url).then(html => {
- let page = getPage(html)
- let title = getTitle(html) + (hasSeeLZ ? ' -- [只看楼主]' : '')
- // 控制最大并发为 5
- async.mapLimit([...new Array(page).keys()], 5, function(idx, callback) {
- let pageUrl = url + (hasSeeLZ ? '&' : '?') + 'pn=' + (idx+1)
- getOnePage(pageUrl).then(res => {
- callback(null, res)
- })
- }, function(err, res) {
- if (err) {
- return console.error(err)
- }
- writeFile('result.txt', title + '\n\n' + res.join(''), () => { console.log('抓取完成!') })
- })
- })
- }
- let queryUrl = 'https://tieba.baidu.com/p/3905448690?see_lz=1'
- getContent(queryUrl)
效果展示(真的是随便找的贴 内容没看过……):
原贴内容:

抓取结果:
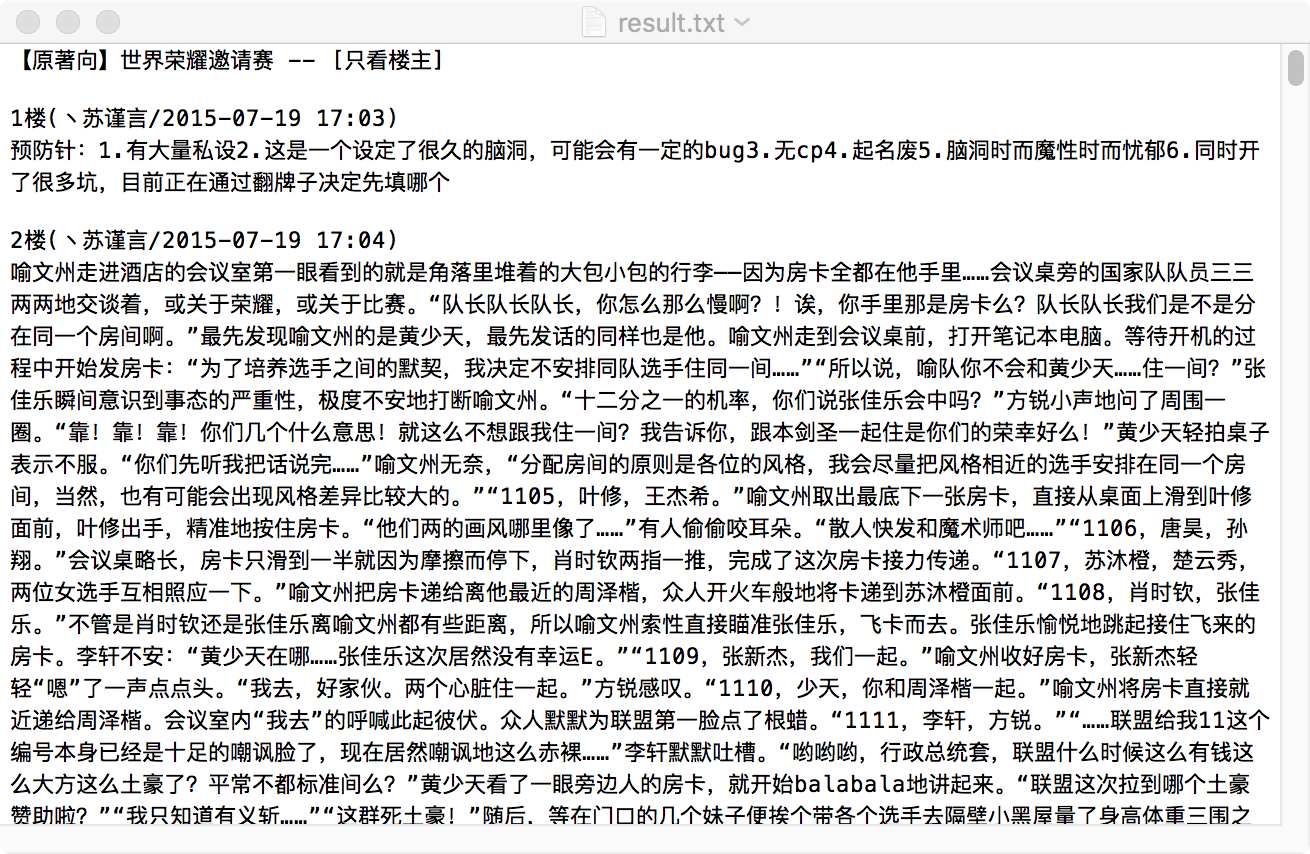
【新手向】使用nodejs抓取百度贴吧内容的更多相关文章
- Python3---爬虫---抓取百度贴吧
前言 该文章主要描述如何抓取百度贴吧内容.当然是简单爬虫实现功能,没有实现输入参数过滤等辅助功能,仅供小白学习. 修改时间:20191219 天象独行 import os,urllib.request ...
- PHP网络爬虫实践:抓取百度搜索结果,并分析数据结构
百度的搜索引擎有反爬虫机制,我先直接用guzzle试试水.代码如下: <?php /** * Created by Benjiemin * Date: 2020/3/5 * Time: 14:5 ...
- Python抓取百度百科数据
前言 本文整理自慕课网<Python开发简单爬虫>,将会记录爬取百度百科"python"词条相关页面的整个过程. 抓取策略 确定目标:确定抓取哪个网站的哪些页面的哪部分 ...
- python3 - 通过BeautifulSoup 4抓取百度百科人物相关链接
导入需要的模块 需要安装BeautifulSoup from urllib.request import urlopen, HTTPError, URLError from bs4 import Be ...
- selenium-java web自动化测试工具抓取百度搜索结果实例
selenium-java web自动化测试工具抓取百度搜索结果实例 这种方式抓百度的搜索关键字结果非常容易抓长尾关键词,根据热门关键词去抓更多内容可以用抓google,百度的这种内容容易给屏蔽,用这 ...
- C#.Net使用正则表达式抓取百度百家文章列表
工作之余,学习了一下正则表达式,鉴于实践是检验真理的唯一标准,于是便写了一个利用正则表达式抓取百度百家文章的例子,具体过程请看下面源码: 一:获取百度百家网页内容 public List<str ...
- 用PHP抓取百度贴吧邮箱数据
注:本程序可能非常适合那些做百度贴吧营销的朋友. 去逛百度贴吧的时候,经常会看到楼主分享一些资源,要求留下邮箱,楼主才给发. 对于一个热门的帖子,留下的邮箱数量是非常多的,楼主需要一个一个的去复制那些 ...
- Python爬虫之小试牛刀——使用Python抓取百度街景图像
之前用.Net做过一些自动化爬虫程序,听大牛们说使用python来写爬虫更便捷,按捺不住抽空试了一把,使用Python抓取百度街景影像. 这两天,武汉迎来了一个德国总理默克尔这位大人物,又刷了一把武汉 ...
- python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息,抓取政府网新闻内容
python3.4学习笔记(十三) 网络爬虫实例代码,使用pyspider抓取多牛投资吧里面的文章信息PySpider:一个国人编写的强大的网络爬虫系统并带有强大的WebUI,采用Python语言编写 ...
随机推荐
- Dockerfile制作自定义镜像
本文介绍最精简的Dockerfile文件构建镜像,Docker启动的时候可以启动一个shell脚本 1.首先编写Dockerfile文件 说明 1.启动的这个shell脚本一定是不退出的,比如服务器的 ...
- java将图片传为设定编码值显示(可做刺绣)
import java.awt.Color; import java.awt.image.BufferedImage;import java.io.File;import java.io.IOExce ...
- Java使用quartz实现作业调度
在spring boot中使用quartz实现作业调度的功能,简单易用. 什么是Quartz? Quartz是Java领域最著名的.功能丰富的.开放源码的作业调度工具,几乎可以在所有的Java应用程序 ...
- java39
String a= "hello.a.java;b.java;hello.java;hello.toha;"; //将每个分号的内容取出来 String[] res=a.split ...
- linux shell数组赋值方法(常用)
http://blog.csdn.net/shaobingj126/article/details/7395161 Bash中,数组变量的赋值有两种方法: (1) name = (value1 ... ...
- windows kafka 环境搭建踩坑记
版本介绍(64位): Windows 10 JDK1.8.0_171 zookeeper-3.4.8/ kafka_2.11-0.10.0.1.tgz 点击链接进行下载 1. JDK安装和环境搭建 自 ...
- day 35 线程
内容回顾 # 互斥锁 #在同一个进程中连续锁多次 #进程的数据共享 #进程之间可以共享数据 #提供共享数据的类是Manager #但是它提供的list|dict 这些数据类型 #针对+= -= *= ...
- 通过PRINT过程制作报表
通过PRINT过程制作报表 PRINT过程是SAS中用于输出数据集内容的最简单常用的过程,它可将选择的观测和字段以简单的矩形表格形式输出. 1.1 制作简单报表 使用PRINT过程最简单的语法形式如下 ...
- 关于String类学习的一些笔记(本文参考来自程序员考拉的文章)
String 类继承自 Object 超类,实现的接口有:Serializable.CharSequence.Comparable<String> 接口,具体如下图: 一.常用的Strin ...
- nginx server
配置nginx 首先apt install nginx 然后安装php apt-get install php7.0-fpm php7.0-mysql php7.0-common php7.0-mbs ...