spark高可用集群搭建及运行测试
文中的所有操作都是在之前的文章spark集群的搭建基础上建立的,重复操作已经简写;
之前的配置中使用了master01、slave01、slave02、slave03;
本篇文章还要添加master02和CloudDeskTop两个节点,并配置好运行环境;
一、流程:
1、在搭建高可用集群之前需要先配置高可用,首先在master01上:
[hadoop@master01 ~]$ cd /software/spark-2.1.1/conf/
[hadoop@master01 conf]$ vi spark-env.sh
export JAVA_HOME=/software/jdk1.7.0_79
export SCALA_HOME=/software/scala-2.11.8
export HADOOP_HOME=/software/hadoop-2.7.3
export HADOOP_CONF_DIR=/software/hadoop-2.7.3/etc/hadoop
#Spark历史服务分配的内存尺寸
export SPARK_DAEMON_MEMORY=512m
#这面的这一项就是Spark的高可用配置,如果是配置master的高可用,master就必须有;如果是slave的高可用,slave就必须有;但是建议都配置。
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=slave01:2181,slave02:2181,slave03:2181 -Dspark.deploy.zookeeper.dir=/spark" #当启用了Spark的高可用之后,下面的这一项应该被注释掉(即不能再被启用,后面通过提交应用时使用--master参数指定高可用集群节点)
#export SPARK_MASTER_IP=master01
#export SPARK_WORKER_MEMORY=1500m
#export SPARK_EXECUTOR_MEMORY=100m
2、将master01节点上的Spark配置文件spark-env.sh同步拷贝到Spark集群上的每一个Worker节点
[hadoop@master01 software]$ scp -r spark-2.1.1/conf/spark-env.sh slave01:/software/spark-2.1.1/conf/
[hadoop@master01 software]$ scp -r spark-2.1.1/conf/spark-env.sh slave02:/software/spark-2.1.1/conf/
[hadoop@master01 software]$ scp -r spark-2.1.1/conf/spark-env.sh slave03:/software/spark-2.1.1/conf/
3、配置master02的高可用配置:
#拷贝Scala安装目录和Spark安装目录到master02节点
[hadoop@master01 software]$ scp -r scala-2.11.8 spark-2.1.1 master02:/software/
[hadoop@master02 software]$ su -lc "chown -R root:root /software/scala-2.11.8"
#拷贝环境配置/etc/profile到master02节点
[hadoop@master01 software]$ su -lc "scp -r /etc/profile master02:/etc/"
#让环境配置立即生效
[hadoop@master01 software]$ su -lc "source /etc/profile"
4、配置CloudDeskTop的高可用配置,方便在eclipse进行开发:
#拷贝Scala安装目录和Spark安装目录到CloudDeskTop节点
[hadoop@master01 software]$ scp -r scala-2.11.8 spark-2.1.1 CloudDeskTop:/software/
[hadoop@CloudDeskTop software]$ su -lc "chown -R root:root /software/scala-2.11.8"
#拷贝环境配置/etc/profile到CloudDeskTop节点
[hadoop@CloudDeskTop software]$ vi /etc/profile
JAVA_HOME=/software/jdk1.7.0_79
HADOOP_HOME=/software/hadoop-2.7.3
HBASE_HOME=/software/hbase-1.2.6
SQOOP_HOME=/software/sqoop-1.4.6
SCALA_HOME=/software/scala-2.11.8
SPARK_HOME=/software/spark-2.1.1
PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/lib:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$SQOOP_HOME/bin:$SCALA_HOME/bin::$SPARK_HOME/bin:
export PATH JAVA_HOME HADOOP_HOME HBASE_HOME SQOOP_HOME SCALA_HOME SPARK_HOME
#让环境配置立即生效:(大数据学习交流群:217770236 让我我们一起学习大数据)
[hadoop@CloudDeskTop software]$ source /etc/profile
二、启动spark集群
由于每次都要启动,比较麻烦,所以博主写了个简单的启动脚本:第一个同步时间的脚本在root用户下执行,后面的脚本在hadoop用户下执行;
[hadoop@master01 install]$ sh start-total.sh
三、高可用集群测试:
使用浏览器访问:
http://master01的IP地址:8080/ #显示Status:ALIVE
http://master02的IP地址:8080/ #显示Status: STANDBY
感谢李永富老师提供的资深总结:
注意:通过上面的访问测试发现以下结论:
0)、ZK保存的集群状态数据也称为元数据,保存的元数据包括:worker、driver、application;
1)、Spark启动时,ZK根据Spark配置文件slaves中的worker配置项使用排除法找到需要启动的master节点(除了在slaves文件中被定义为worker节点以外的节点都有可能被选举为master节点来启动)
2)、ZK集群将所有启动了master进程的节点纳入到高可用集群中的节点来进行管理;
3)、如果处于alive状态的master节点宕机,则ZK集群会自动将其alive状态切换到高可用集群中的另一个节点上继续提供服务;如果宕机的master恢复则alive状态并不会恢复回去而是继续使用当前的alive节点,这说明了ZK实现的是双主或多主模式的高可用集群;
4)、Spark集群中master节点的高可用可以设置的节点数多余两个(高可用集群节点数可以大于2);
5)、高可用集群中作为active节点的master则是由ZK集群来确定的,alive的master宕机之后同样由ZK来决定新的alive的master节点,当新的alive的master节点确定好之后由该新的alive的master节点去主动通知客户端(spark-shell、spark-submit)来连接它自己(这是服务端主动连接客户端并通知客户端去连接服务端自己的过程,这个过程与Hadoop的客户端连接高可用集群不同,Hadoop是通过hadoop客户端主动识别高可用集群中的active节点的master);
6)、Hadoop与Spark的高可用都是基于ZK的双主或多主模式,而不是类同于KP的主备模式,双主模式与主备模式的区别在于;
双主模式:充当master的主机是并列的,没有优先级之分,双主切换的条件是其中一台master宕掉之后切换到另一台master
主备模式:充当master的主机不是并列的,存在优先级(优先级:主>备),主备模式切换的条件有两种:
A、主master宕掉之后自动切换到备master
B、主master恢复之后自动切换回主master
四、运行测试:
#删除以前的老的输出目录
[hadoop@CloudDeskTop install]$ hdfs dfs -rm -r /spark/output
1、准备测试所需数据
[hadoop@CloudDeskTop install]$ hdfs dfs -ls /spark
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-01-05 15:14 /spark/input
[hadoop@CloudDeskTop install]$ hdfs dfs -ls /spark/input
Found 1 items
-rw-r--r-- 3 hadoop supergroup 66 2018-01-05 15:14 /spark/input/wordcount
[hadoop@CloudDeskTop install]$ hdfs dfs -cat /spark/input/wordcount
my name is ligang
my age is 35
my height is 1.67
my weight is 118
2、运行spark-shell和spark-submit时需要使用--master参数同时指定高可用集群的所有节点,节点之间使用英文逗号分割,如下:
1)、使用spark-shell
[hadoop@CloudDeskTop bin]$ pwd
/software/spark-2.1.1/bin
[hadoop@CloudDeskTop bin]$ ./spark-shell --master spark://master01:7077,master02:7077
scala> sc.textFile("/spark/input").flatMap(_.split(" ")).map(word=>(word,1)).reduceByKey(_+_).map(entry=>(entry._2,entry._1)).sortByKey(false,1).map(entry=>(entry._2,entry._1)).saveAsTextFile("/spark/output")
scala> :q
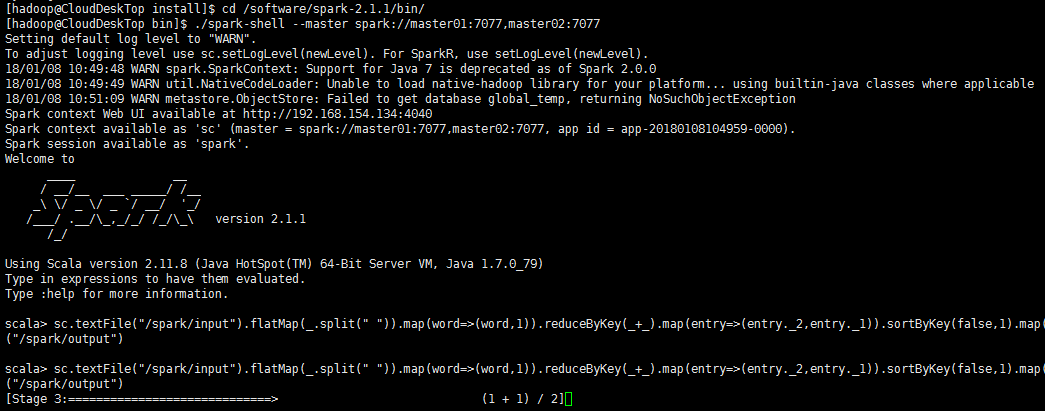
查看HDFS集群中的输出结果:
[hadoop@slave01 ~]$ hdfs dfs -ls /spark/
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2018-01-05 15:14 /spark/input
drwxr-xr-x - hadoop supergroup 0 2018-01-08 10:53 /spark/output
[hadoop@slave01 ~]$ hdfs dfs -ls /spark/output
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2018-01-08 10:53 /spark/output/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 88 2018-01-08 10:53 /spark/output/part-00000
[hadoop@slave01 ~]$ hdfs dfs -cat /spark/output/part-00000
(is,4)
(my,4)
(118,1)
(1.67,1)
(35,1)
(ligang,1)
(weight,1)
(name,1)
(height,1)
(age,1)
hdfs集群中的输出结果:
2)、使用spark-submit
[hadoop@CloudDeskTop bin]$ ./spark-submit --class org.apache.spark.examples.JavaSparkPi --master spark://master01:7077,master02:7077 ../examples/jars/spark-examples_2.11-2.1.1.jar 1
[hadoop@CloudDeskTop bin]$ ./spark-submit --class org.apache.spark.examples.JavaSparkPi --master spark://master01:7077,master02:7077 ../examples/jars/spark-examples_2.11-2.1.1.jar 1
18/01/08 10:55:13 INFO spark.SparkContext: Running Spark version 2.1.1
18/01/08 10:55:13 WARN spark.SparkContext: Support for Java 7 is deprecated as of Spark 2.0.0
18/01/08 10:55:14 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/01/08 10:55:14 INFO spark.SecurityManager: Changing view acls to: hadoop
18/01/08 10:55:14 INFO spark.SecurityManager: Changing modify acls to: hadoop
18/01/08 10:55:14 INFO spark.SecurityManager: Changing view acls groups to:
18/01/08 10:55:14 INFO spark.SecurityManager: Changing modify acls groups to:
18/01/08 10:55:14 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); groups with view permissions: Set(); users with modify permissions: Set(hadoop); groups with modify permissions: Set()
18/01/08 10:55:15 INFO util.Utils: Successfully started service 'sparkDriver' on port 51109.
18/01/08 10:55:15 INFO spark.SparkEnv: Registering MapOutputTracker
18/01/08 10:55:15 INFO spark.SparkEnv: Registering BlockManagerMaster
18/01/08 10:55:15 INFO storage.BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
18/01/08 10:55:15 INFO storage.BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
18/01/08 10:55:15 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-42661d7c-9089-4f97-9dea-661f59f366df
18/01/08 10:55:15 INFO memory.MemoryStore: MemoryStore started with capacity 366.3 MB
18/01/08 10:55:15 INFO spark.SparkEnv: Registering OutputCommitCoordinator
18/01/08 10:55:16 INFO util.log: Logging initialized @4168ms
18/01/08 10:55:16 INFO server.Server: jetty-9.2.z-SNAPSHOT
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@131e6b9c{/jobs,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@322ad892{/jobs/json,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1af072f9{/jobs/job,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@200c4740{/jobs/job/json,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@619cb30{/stages,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@76abf71{/stages/json,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@713e9784{/stages/stage,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@444d9531{/stages/stage/json,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@417de6ff{/stages/pool,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@30c890f0{/stages/pool/json,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3fa39595{/storage,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@cb189d7{/storage/json,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5bd088c3{/storage/rdd,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@57c2e94c{/storage/rdd/json,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3d62a997{/environment,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@186c17fd{/environment/json,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@609aef91{/executors,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5be64a23{/executors/json,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@6c0d6ef7{/executors/threadDump,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@65f0518c{/executors/threadDump/json,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@479f29d{/static,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@622723b6{/,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7799b411{/api,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@bfd056f{/jobs/job/kill,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@106fc08f{/stages/stage/kill,null,AVAILABLE,@Spark}
18/01/08 10:55:16 INFO server.ServerConnector: Started Spark@297cce3b{HTTP/1.1}{0.0.0.0:4040}
18/01/08 10:55:16 INFO server.Server: Started @4619ms
18/01/08 10:55:16 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
18/01/08 10:55:16 INFO ui.SparkUI: Bound SparkUI to 0.0.0.0, and started at http://192.168.154.134:4040
18/01/08 10:55:16 INFO spark.SparkContext: Added JAR file:/software/spark-2.1.1/bin/../examples/jars/spark-examples_2.11-2.1.1.jar at spark://192.168.154.134:51109/jars/spark-examples_2.11-2.1.1.jar with timestamp 1515380116738
18/01/08 10:55:16 INFO client.StandaloneAppClient$ClientEndpoint: Connecting to master spark://master01:7077...
18/01/08 10:55:16 INFO client.StandaloneAppClient$ClientEndpoint: Connecting to master spark://master02:7077...
18/01/08 10:55:17 INFO client.TransportClientFactory: Successfully created connection to master01/192.168.154.130:7077 after 70 ms (0 ms spent in bootstraps)
18/01/08 10:55:17 INFO client.TransportClientFactory: Successfully created connection to master02/192.168.154.140:7077 after 77 ms (0 ms spent in bootstraps)
18/01/08 10:55:17 INFO cluster.StandaloneSchedulerBackend: Connected to Spark cluster with app ID app-20180108105518-0001
18/01/08 10:55:17 INFO client.StandaloneAppClient$ClientEndpoint: Executor added: app-20180108105518-0001/0 on worker-20180108093501-192.168.154.131-55066 (192.168.154.131:55066) with 4 cores
18/01/08 10:55:17 INFO cluster.StandaloneSchedulerBackend: Granted executor ID app-20180108105518-0001/0 on hostPort 192.168.154.131:55066 with 4 cores, 1024.0 MB RAM
18/01/08 10:55:17 INFO client.StandaloneAppClient$ClientEndpoint: Executor added: app-20180108105518-0001/1 on worker-20180108093502-192.168.154.132-38226 (192.168.154.132:38226) with 4 cores
18/01/08 10:55:17 INFO cluster.StandaloneSchedulerBackend: Granted executor ID app-20180108105518-0001/1 on hostPort 192.168.154.132:38226 with 4 cores, 1024.0 MB RAM
18/01/08 10:55:17 INFO client.StandaloneAppClient$ClientEndpoint: Executor added: app-20180108105518-0001/2 on worker-20180504093452-192.168.154.133-37578 (192.168.154.133:37578) with 4 cores
18/01/08 10:55:17 INFO cluster.StandaloneSchedulerBackend: Granted executor ID app-20180108105518-0001/2 on hostPort 192.168.154.133:37578 with 4 cores, 1024.0 MB RAM
18/01/08 10:55:17 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 53551.
18/01/08 10:55:17 INFO netty.NettyBlockTransferService: Server created on 192.168.154.134:53551
18/01/08 10:55:17 INFO storage.BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
18/01/08 10:55:17 INFO storage.BlockManagerMaster: Registering BlockManager BlockManagerId(driver, 192.168.154.134, 53551, None)
18/01/08 10:55:17 INFO client.StandaloneAppClient$ClientEndpoint: Executor updated: app-20180108105518-0001/1 is now RUNNING
18/01/08 10:55:17 INFO client.StandaloneAppClient$ClientEndpoint: Executor updated: app-20180108105518-0001/2 is now RUNNING
18/01/08 10:55:17 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.154.134:53551 with 366.3 MB RAM, BlockManagerId(driver, 192.168.154.134, 53551, None)
18/01/08 10:55:17 INFO storage.BlockManagerMaster: Registered BlockManager BlockManagerId(driver, 192.168.154.134, 53551, None)
18/01/08 10:55:17 INFO storage.BlockManager: Initialized BlockManager: BlockManagerId(driver, 192.168.154.134, 53551, None)
18/01/08 10:55:18 INFO client.StandaloneAppClient$ClientEndpoint: Executor updated: app-20180108105518-0001/0 is now RUNNING
18/01/08 10:55:18 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@280bc0db{/metrics/json,null,AVAILABLE,@Spark}
18/01/08 10:55:23 INFO scheduler.EventLoggingListener: Logging events to hdfs://ns1/sparkLog/app-20180108105518-0001
18/01/08 10:55:23 INFO cluster.StandaloneSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.0
18/01/08 10:55:23 INFO internal.SharedState: Warehouse path is 'file:/software/spark-2.1.1/bin/spark-warehouse/'.
18/01/08 10:55:23 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@77b3e297{/SQL,null,AVAILABLE,@Spark}
18/01/08 10:55:23 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5ba75a57{/SQL/json,null,AVAILABLE,@Spark}
18/01/08 10:55:23 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@440b92a3{/SQL/execution,null,AVAILABLE,@Spark}
18/01/08 10:55:23 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@7b534e75{/SQL/execution/json,null,AVAILABLE,@Spark}
18/01/08 10:55:23 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@fe55b47{/static/sql,null,AVAILABLE,@Spark}
18/01/08 10:55:25 INFO spark.SparkContext: Starting job: reduce at JavaSparkPi.java:52
18/01/08 10:55:26 INFO scheduler.DAGScheduler: Got job 0 (reduce at JavaSparkPi.java:52) with 1 output partitions
18/01/08 10:55:26 INFO scheduler.DAGScheduler: Final stage: ResultStage 0 (reduce at JavaSparkPi.java:52)
18/01/08 10:55:26 INFO scheduler.DAGScheduler: Parents of final stage: List()
18/01/08 10:55:26 INFO scheduler.DAGScheduler: Missing parents: List()
18/01/08 10:55:26 INFO scheduler.DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at JavaSparkPi.java:52), which has no missing parents
18/01/08 10:55:26 INFO memory.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 2.3 KB, free 366.3 MB)
18/01/08 10:55:27 INFO memory.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1405.0 B, free 366.3 MB)
18/01/08 10:55:27 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.154.134:53551 (size: 1405.0 B, free: 366.3 MB)
18/01/08 10:55:27 INFO spark.SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:996
18/01/08 10:55:27 INFO scheduler.DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at JavaSparkPi.java:52)
18/01/08 10:55:27 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
18/01/08 10:55:39 INFO cluster.CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(null) (192.168.154.131:53880) with ID 0
18/01/08 10:55:40 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.154.131:40573 with 366.3 MB RAM, BlockManagerId(0, 192.168.154.131, 40573, None)
18/01/08 10:55:41 WARN scheduler.TaskSetManager: Stage 0 contains a task of very large size (982 KB). The maximum recommended task size is 100 KB.
18/01/08 10:55:41 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, 192.168.154.131, executor 0, partition 0, PROCESS_LOCAL, 1006028 bytes)
18/01/08 10:55:41 INFO cluster.CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(null) (192.168.154.132:39480) with ID 1
18/01/08 10:55:41 INFO cluster.CoarseGrainedSchedulerBackend$DriverEndpoint: Registered executor NettyRpcEndpointRef(null) (192.168.154.133:54919) with ID 2
18/01/08 10:55:43 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.154.132:46053 with 366.3 MB RAM, BlockManagerId(1, 192.168.154.132, 46053, None)
18/01/08 10:55:43 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.154.133:52023 with 366.3 MB RAM, BlockManagerId(2, 192.168.154.133, 52023, None)
18/01/08 10:55:48 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.154.131:40573 (size: 1405.0 B, free: 366.3 MB)
18/01/08 10:55:48 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 8946 ms on 192.168.154.131 (executor 0) (1/1)
18/01/08 10:55:48 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
18/01/08 10:55:48 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at JavaSparkPi.java:52) finished in 21.481 s
18/01/08 10:55:48 INFO scheduler.DAGScheduler: Job 0 finished: reduce at JavaSparkPi.java:52, took 22.791278 s
Pi is roughly 3.13876
18/01/08 10:55:48 INFO server.ServerConnector: Stopped Spark@297cce3b{HTTP/1.1}{0.0.0.0:4040}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@106fc08f{/stages/stage/kill,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@bfd056f{/jobs/job/kill,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@7799b411{/api,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@622723b6{/,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@479f29d{/static,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@65f0518c{/executors/threadDump/json,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@6c0d6ef7{/executors/threadDump,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@5be64a23{/executors/json,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@609aef91{/executors,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@186c17fd{/environment/json,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@3d62a997{/environment,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@57c2e94c{/storage/rdd/json,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@5bd088c3{/storage/rdd,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@cb189d7{/storage/json,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@3fa39595{/storage,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@30c890f0{/stages/pool/json,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@417de6ff{/stages/pool,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@444d9531{/stages/stage/json,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@713e9784{/stages/stage,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@76abf71{/stages/json,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@619cb30{/stages,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@200c4740{/jobs/job/json,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@1af072f9{/jobs/job,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@322ad892{/jobs/json,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO handler.ContextHandler: Stopped o.s.j.s.ServletContextHandler@131e6b9c{/jobs,null,UNAVAILABLE,@Spark}
18/01/08 10:55:48 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.154.134:4040
18/01/08 10:55:49 INFO cluster.StandaloneSchedulerBackend: Shutting down all executors
18/01/08 10:55:49 INFO cluster.CoarseGrainedSchedulerBackend$DriverEndpoint: Asking each executor to shut down
18/01/08 10:55:49 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
18/01/08 10:55:49 INFO memory.MemoryStore: MemoryStore cleared
18/01/08 10:55:49 INFO storage.BlockManager: BlockManager stopped
18/01/08 10:55:49 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
18/01/08 10:55:49 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
18/01/08 10:55:49 INFO spark.SparkContext: Successfully stopped SparkContext
18/01/08 10:55:49 INFO util.ShutdownHookManager: Shutdown hook called
18/01/08 10:55:49 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-504e3164-fcd6-4eac-8ae5-fc6744b0298f
Pi的计算结果:
3)、测试Spark的高可用是否可以做到Job的运行时高可用
在运行Job的过程中将主Master进程宕掉,观察Spark在高可用集群下是否可以正常跑完Job;
经过实践测试得出结论:Spark的高可用比Yarn的高可用更智能化,可以做到Job的运行时高可用,这与HDFS的高可用能力是相同的;Spark之所以可以做到运行时高可用应该是因为在Job的运行时其Worker节点对Master节点的依赖不及Yarn集群下NM节点对RM节点的依赖那么多。
4)、停止集群
[hadoop@master01 install]$ sh stop-total.sh
注意:
1、如果需要在Spark的高可用配置下仅开启其中一个Master节点,你只需要直接将另一个节点关掉即可,不需要修改任何配置,以后需要多节点高可用时直接启动那些节点上的Master进程即可,ZK会在这些节点启动Master进程时自动感知并将其加入高可用集群组中去,同时为他们分配相应的高可用角色;
2、如果在Spark的高可用配置下仅开启其中一个Master节点,则该唯一节点必须是Alive角色,提交Job时spark-submit的--master参数应该只写Alive角色的唯一Master节点即可,如果你还是把那些没有启动Master进程的节点加入到--master参数列表中去则会引发IOException,但是整个Job仍然会运行成功,因为毕竟运行Job需要的仅仅是Alive角色的Master节点。
spark高可用集群搭建及运行测试的更多相关文章
- Spark高可用集群搭建
Spark高可用集群搭建 node1 node2 node3 1.node1修改spark-env.sh,注释掉hadoop(就不用开启Hadoop集群了),添加如下语句 export ...
- Spark —— 高可用集群搭建
一.集群规划 这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop00 ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- MongoDB高可用集群搭建(主从、分片、路由、安全验证)
目录 一.环境准备 1.部署图 2.模块介绍 3.服务器准备 二.环境变量 1.准备三台集群 2.安装解压 3.配置环境变量 三.集群搭建 1.新建配置目录 2.修改配置文件 3.分发其他节点 4.批 ...
- RabbitMQ高级指南:从配置、使用到高可用集群搭建
本文大纲: 1. RabbitMQ简介 2. RabbitMQ安装与配置 3. C# 如何使用RabbitMQ 4. 几种Exchange模式 5. RPC 远程过程调用 6. RabbitMQ高可用 ...
- spring cloud 服务注册中心eureka高可用集群搭建
spring cloud 服务注册中心eureka高可用集群搭建 一,准备工作 eureka可以类比zookeeper,本文用三台机器搭建集群,也就是说要启动三个eureka注册中心 1 本文三台eu ...
- MongoDB 3.4 高可用集群搭建(二)replica set 副本集
转自:http://www.lanceyan.com/tech/mongodb/mongodb_repset1.html 在上一篇文章<MongoDB 3.4 高可用集群搭建(一):主从模式&g ...
随机推荐
- ora 01795 in 1000 limit
https://docs.oracle.com/cd/B19306_01/server.102/b14200/conditions013.htm https://docs.oracle.com/cd/ ...
- 生成图形化html报告
生成图形化html报告: 1.从cmd 进入执行测试文件 2.执行该命令:jmeter -n -t <test JMX file> -l <test log file> -e ...
- Postgresql 数据库错误修复v0.1
PS. 查询\nebula_boh\logs\BOHInterfaceLog.log 日志, 一般数据库文件损坏的日志 有 “UncategorizedSQLException” 或 “zero pa ...
- 【.NET Core项目实战-统一认证平台】第一章 功能及架构分析
[.NET Core项目实战-统一认证平台]开篇及目录索引 从本文开始,我们正式进入项目研发阶段,首先我们分析下统一认证平台应该具备哪些功能性需求和非功能性需求,在梳理完这些需求后,设计好系统采用的架 ...
- 剑指offer面试题26:复杂链表的复制
题目:请实现一个函数,复制一个复杂链表. 在复杂链表中,每个结点除了有一个next指针指向下一个结点外,还有一个sibling指针指向链表中的任意结点或者nulL 直观解法: 1.遍历链表,复制链表节 ...
- C#通过COM组件操作IE浏览器(一):打开浏览器跳转到指定网站
简介Internet Explorer对象模型 1.属性 属性 类型 描述 Application Object 返回对Internet Explorer对象的引用. Busy Boolean 返回一 ...
- vue组件推荐
Vue 是一个轻巧.高性能.可组件化的MVVM库,API简洁明了,上手快.从Vue推出以来,得到众多Web开发者的认可.在公司的Web前端项目开发中,多个项目采用基于Vue的UI组件框架开发,并投入正 ...
- 第69节:Java中数据库的多表操作
第69节:Java中数据库的多表操作 前言 学习数据库的多表操作,去电商行业做项目吧!!! 达叔,理工男,简书作者&全栈工程师,感性理性兼备的写作者,个人独立开发者,我相信你也可以!阅读他的文 ...
- SpringMVC项目容易出现的BUG
1.400错误:1.语义有误,当前请求无法被服务器理解.除非进行修改,否则客户端不应该重复提交这个请求. 2.请求参数有误. 你发送的请求有误,这个问题去页面提交的地方看. 如:你想删除一条数据,id ...
- Ubuntu 18.04基本配置
允许WinSCP使用root连接 默认是不允许的,具体方法出自这里(传送门),修改ssh配置,在/etc/ssh下,修改sshd_config文件 PermitRootLogin yes 即可.默认不 ...