mysql之视图,触发器,事务等。。。
一、视图
视图是一个虚拟表(非真实存在),其本质是【根据SQL语句获取动态的数据集,并为其命名】,用户使用时只需使用【名称】即可获取结果集,可以将该结果集当做表来使用。
使用视图我们可以把查询过程中的临时表摘出来,用视图去实现,这样以后再想操作该临时表的数据时就无需重写复杂的sql了,直接去视图中查找即可,但视图有明显地效率问题,并且视图是存放在数据库中的,如果我们程序中使用的sql过分依赖数据库中的视图,即强耦合,那就意味着扩展sql极为不便,因此并不推荐使用
-- 1.视图是一个虚拟表(非正式存在),其本质是其本质是
-- 【根据SQL语句获取动态的数据集,并为其命名】,
-- 用户使用时只需使用【名称】即可获取结果集,
-- 可以将该结果集当做表来使用。
-- 2.
-- 有了视图以后你是不是觉得写sql语句就很简单了,但是你尽量不要这样做
-- 因为mysql是DBA管着呢,那么你告诉DBA建一堆视图,你写程序的时候是方便了,
-- 但是你要是修改呢,那么你就得修改视图了,你就得找到DBA修改你的视图了,
-- 那么这样联系别人会很麻烦的。说不定人家还很忙呢。还是推荐自己去写sql语句。 -- #注意:
-- 如果是一个单表的就可以修改或者删除或者插入
-- 如果是几个表关联的时候是不可以修改或者删除或者插入的(这点也是不确定的,有的可以改,有的不可以改)
准备表
========================
创建部门表
create table dep(
id int primary key auto_increment,
name char(32)
);
创建用户表
create table user(
id int primary key auto_increment,
name char(32),
dep_id int,
foreign key(dep_id) references dep(id)
);
插数据
insert into dep(name) values('外交部'),('销售'),('财经部');
insert into user(name,dep_id) values ('egon',1),
('alex',2),
('haiyan',3);
1.创建视图
创建视图语法
CREATE VIEW 视图名称 AS SQL语句
create view teacher_view as select tid from teacher where tname='李平老师';
#连表
select * from dep left join user on dep.id = user.dep_id;
#创建一个视图
create view user_dep_view as select dep.id depid ,user.id uid ,user.name uname,dep.name depname from dep left join user
on dep.id = user.dep_id;
-- 这样创建一个视图以后就可以吧一个虚拟表保存下来,就可以查看了。
select uname from user_dep_view where depid = 3;
-- 我的电脑上不可以增删改,只可查看。但是有的电脑上又可以增删改,可能是跟版本有关吧
#测试
insert into user_dep_view VALUES (1,2,'egon','人文部'); #会报错
DELETE from user_dep_view where uid = 1; #会报错
update user_dep_view set uname = '海燕' where depid = 2; #会报错
-- 对于单表来说是可以修改的,并且原来表的也就更改了。
-- 但是一般还是不要这样改。视图大多数是用来查看的
#建表
CREATE TABLE t1(
id int PRIMARY KEY auto_increment,
name CHAR(10)
);
#插入数据
insert into t1 VALUES (1,'egon'),
(2,'daa'),
(3,'eef');
#创建视图
CREATE view t1_view as select * from t1;
#测试创建视图以后还能不能增删改查
select * from t1_view;
update t1_view set name = '海燕' where id = 2; #可以修改(而且原来表的记录也修改了)
INSERT into t1_view values(4,'aaa'); #可以插入(同上)
delete from t1_view where id=3;#同上
2.修改视图
语法:ALTER VIEW 视图名称 AS SQL语句
3.删除视图
语法:DROP VIEW 视图名称
二、触发器
使用触发器可以定制用户对表进行【增、删、改】操作时前后的行为,注意:没有查询
-- 触发器:某种程序触发了工具的运行
-- 触发器不能主动调用,只有触发了某种行为才会调用触发器的执行
-- 插入一条记录就触发一次
-- 还是建议不要用触发器,因为这是BDA管理的,还是不如你在程序里面直接写比较方便
1.创建触发器的语法
create
trigger trigger_name
trigger_time trigger_event
on tbl_name for each row
triggrr_body #主体,就是在触发器里干什么事
trigger_time:{before | after}
trigger_event:{insert | update |detele}
准备表
-- # 2.准备表
-- #第一步:准备表
create table cmd_log(
id int primary key auto_increment,
cmd_name char(64), #命令的名字
sub_time datetime, #提交时间
user_name char(32), #是哪个用户过来执行这个命令
is_success enum('yes','no') #命令是否执行成功
); create table err_log(
id int primary key auto_increment,
cname char(64), #命令的名字
stime datetime #提交时间
);
创建触发器
-- #创建触发器(向err_log表里插入最新的记录)
delimiter //
create
trigger tri_after_inser_cmd_log
after insert
on cmd_log for each row
BEGIN
if new.is_success = 'no' then
insert into err_log(cname,stime) VALUES(new.cmd_name,new.sub_time);
end if; #记得加分号,mysql一加分号代表结束,那么就得声明一下
END //
delimiter ; #还原的最原始的状态 -- #创建触发器(向err_log表里插入最旧的记录)
delimiter //
create
trigger tri_after_inser_cmd_log1
after delete
on cmd_log for each row
BEGIN
if old.is_success = 'no' then
insert into err_log(cname,stime) VALUES(old.cmd_name,old.sub_time);
end if; #记得加分号,mysql一加分号代表结束,那么就得声明一下
END //
delimiter ; #还原的最原始的状态
DELETE from cmd_log where id=1;
-- 触发器的两个关键字:new ,old
-- new :表示新的记录
-- old:表示旧的那条记录
-- 什么情况下才往里面插记录
-- 当命令输入错误的时候就把错误的记录插入到err_log表中
测试
# 4.测试
insert into cmd_log(cmd_name,sub_time,user_name,is_success) values
('ls -l /etc | grep *.conf',now(),'root','no'), #NEW.id,NEW.cmd_name,NEW.sub_time
('ps aux |grep mysqld',now(),'root','yes'),
('cat /etc/passwd |grep root',now(),'root','yes'),
('netstat -tunalp |grep 3306',now(),'egon','no');
三、事务
-- 事务用于将某些操作的多个SQL作为原子性操作,一旦有某一个出现错误,
-- 即可回滚到原来的状态,从而保证数据库数据完整性。
-- 事务也就是要么都成功,要么都不成功
-- 事务就是由一堆sql语句组成的
create table user(
id int primary key auto_increment,
name char(32),
balance int #用户余额
); insert into user(name,balance) values('海燕',200),
('哪吒',200),
('小哈',200); -- 如果都成功就执行commit,,,如果不成功就执行rollback。
start transaction #开启事务
update user set balance = 100 where name = '海燕';
update user set balance = 210 where name = '哪吒';
update user set balance = 290 where name = '小哈'; #sql语句错误就会报错了
commit; #如果所有的sql语句都没有出现异常,应该执行commit start transaction
update user set balance = 100 where name = '海燕';
update user set balance = 210 where name = '哪吒';
updatezzzz user set balance = 290 where name = '小哈'; #sql语句错误就会报错了
rollback; #如果任意一条sql出现异常,都应该回归到初始状态
上面的两种情况我们可以用异常处理捕捉一下
delimiter //
create PROCEDURE p6(
OUT p_return_code tinyint
)
BEGIN
DECLARE exit handler for sqlexception
BEGIN
-- ERROR
set p_return_code = 1;
rollback;
END;
DECLARE exit handler for sqlwarning
BEGIN
-- WARNING
set p_return_code = 2;
rollback;
END;
START TRANSACTION;
update user set balance = 100 where name = '海燕';
update user set balance = 210 where name = '哪吒';
update user11 set balance = 290 where name = '小哈';
COMMIT;
-- SUCCESS
set p_return_code = 0; #0代表执行成功
END //
delimiter ;
捕捉异常+事务1
============捕捉异常+事务==============
delimiter //
create PROCEDURE p6(
OUT p_return_code tinyint
)
BEGIN
DECLARE exit handler for sqlexception
BEGIN
-- ERROR
set p_return_code = 1;
rollback;
END;
DECLARE exit handler for sqlwarning
BEGIN
-- WARNING
set p_return_code = 2;
rollback;
END;
START TRANSACTION;
insert into test(username,dep_id) values('egon',1);
DELETE from tb1111111; #如果执行失败,就不会执行commit了
COMMIT;
-- SUCCESS
set p_return_code = 0; #0代表执行成功
END //
delimiter ;
#调用
set @res = 111 #相当于定义一个全局变量
call p6(@res)
select * from test;
select @res
捕捉异常+事务
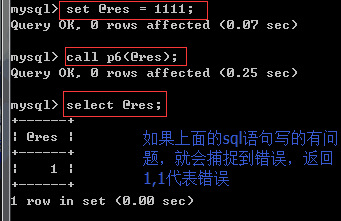
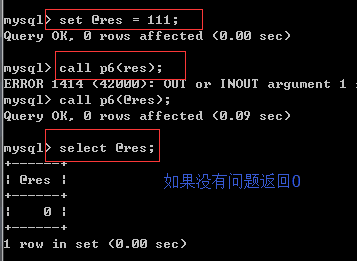
其实也就相当于python中的try.....except
#用python模拟
try:
START TRANSACTION;
DELETE from tb1; #执行失败
insert into blog(name,sub_time) values('yyy',now());
COMMIT;
set p_return_code = 0; #0代表执行成功
except sqlexception:
set p_return_code = 1;
rollback;
except sqlwaring:
set p_return_code = 2;
rollback;
用python模拟
四、存储过程
存储过程包含了一系列可执行的sql语句,存储过程存放于MySQL中,通过调用它的名字可以执行其内部的一堆sql
-- 存储过程的优点:
-- 1.程序与数据实现解耦
-- 2.减少网络传输的数据量
-- 但是看似很完美,还是不推荐你使用
===========创建无参的存储过程===============
delimiter //
create procedure p1()
begin
select * from test;
insert into test(username,dep_id) VALUES('egon',1);
end //
delimiter ; #调用存储过程
#在mysql中调用
call p1();
#在python程序中调用
cursor.callproc('p1')
创建无参的存储过程
对于存储过程,可以接收参数,其参数有三类:
#in 仅用于传入参数用
#out 仅用于返回值用
#inout 既可以传入又可以当作返回值
==========创建有参的存储过程(in)===============
delimiter //
create procedure p2(
in m int, #从外部传进来的值
in n int
)
begin
insert into test(username,dep_id) VALUES ('haha',2),('xixi',3),('sasa',1),('yanyan',2);
select * from test where id between m and n;
end //
delimiter ; #调用存储过程
call p2(3,7); #在mysql中执行
#在python程序中调用
cursor.callproc('p2',arg(3,7))
创建有参的存储过程(in)
===========创建有参的存储过程(out)===============
delimiter //
create procedure p3(
in m int, #从外部传进来的值
in n int,
out res int
)
begin
select * from test where id between m and n;
set res = 1;#如果不设置,则res返回null
end //
delimiter ; #调用存储过程
set @res = 11111;
call p3(3,7,@res);
select @res; #在mysql中执行 #在python中
res=cursor.callproc('p3',args=(3,7,123)) #@_p3_0=3,@_p3_1=7,@_p3_2=123
print(cursor.fetchall()) #只是拿到存储过程中select的查询结果
cursor.execute('select @_p3_0,@_p3_1,@_p3_2')
print(cursor.fetchall()) #可以拿到的是返回值
创建有参的存储过程(out)
=============创建有参存储过程之inout的使用==========
delimiter //
create procedure p4(
inout m int
)
begin
select * from test where id > m;
set m=1;
end //
delimiter ; #在mysql中
set @x=2;
call p4(@x);
select @x; ===========================
delimiter //
create procedure p5(
inout m int
)
begin
select * from test11111 where id > m;
set m=1;
end //
delimiter ; #在mysql中
set @x=2;
call p5(@x);
select @x; #这时由于不存在那个表就会报错,查看的结果就成2了。
创建有参存储过程之inout的使用
-- 无参数
call proc_name() -- 有参数,全in
call proc_name(1,2) -- 有参数,有in,out,inout
set @t1=0;
set @t2=3;
call proc_name(1,2,@t1,@t2) 执行存储过程 在MySQL中执行存储过程
补充:程序与数据库结合使用的三种方式
#方式一:
MySQL:存储过程
程序:调用存储过程 #方式二:
MySQL:
程序:纯SQL语句 #方式三:
MySQL:
程序:类和对象,即ORM(本质还是纯SQL语句)
import pymysql
conn = pymysql.connect(host = 'localhost',user = 'root',password='',database = 'lianxi',charset = 'utf8')
cursor = conn.cursor(pymysql.cursors.DictCursor) #以字典的形式输出
# rows = cursor.callproc('p1') #1.调用存储过程的方法 ,没参数时
# rows = cursor.callproc('p2',args=(3,7)) #有参数时
rows = cursor.callproc('p3', args=(3,7,123)) #@_p3_0=3,@_p3_1=7 ,@_p3_2=123 #有参数时
conn.commit() #执行
print(cursor.fetchall())
cursor.execute('select @_p3_0,@_p3_1,@_p3_2')
print(cursor.fetchall())
cursor.close()
conn.close()
删除存储过程
drop procedure proc_name;
五、函数
MySQL中提供了许多内置函数,例如:
CHAR_LENGTH(str)
返回值为字符串str 的长度,长度的单位为字符。一个多字节字符算作一个单字符。
对于一个包含五个二字节字符集, LENGTH()返回值为 10, 而CHAR_LENGTH()的返回值为5。 CONCAT(str1,str2,...)
字符串拼接
如有任何一个参数为NULL ,则返回值为 NULL。
CONCAT_WS(separator,str1,str2,...)
字符串拼接(自定义连接符)
CONCAT_WS()不会忽略任何空字符串。 (然而会忽略所有的 NULL)。 CONV(N,from_base,to_base)
进制转换
例如:
SELECT CONV('a',16,2); 表示将 a 由16进制转换为2进制字符串表示 FORMAT(X,D)
将数字X 的格式写为'#,###,###.##',以四舍五入的方式保留小数点后 D 位, 并将结果以字符串的形式返回。若 D 为 0, 则返回结果不带有小数点,或不含小数部分。
例如:
SELECT FORMAT(12332.1,4); 结果为: '12,332.1000'
INSERT(str,pos,len,newstr)
在str的指定位置插入字符串
pos:要替换位置其实位置
len:替换的长度
newstr:新字符串
特别的:
如果pos超过原字符串长度,则返回原字符串
如果len超过原字符串长度,则由新字符串完全替换
INSTR(str,substr)
返回字符串 str 中子字符串的第一个出现位置。 LEFT(str,len)
返回字符串str 从开始的len位置的子序列字符。 LOWER(str)
变小写 UPPER(str)
变大写 LTRIM(str)
返回字符串 str ,其引导空格字符被删除。
RTRIM(str)
返回字符串 str ,结尾空格字符被删去。
SUBSTRING(str,pos,len)
获取字符串子序列 LOCATE(substr,str,pos)
获取子序列索引位置 REPEAT(str,count)
返回一个由重复的字符串str 组成的字符串,字符串str的数目等于count 。
若 count <= 0,则返回一个空字符串。
若str 或 count 为 NULL,则返回 NULL 。
REPLACE(str,from_str,to_str)
返回字符串str 以及所有被字符串to_str替代的字符串from_str 。
REVERSE(str)
返回字符串 str ,顺序和字符顺序相反。
RIGHT(str,len)
从字符串str 开始,返回从后边开始len个字符组成的子序列 SPACE(N)
返回一个由N空格组成的字符串。 SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len)
不带有len 参数的格式从字符串str返回一个子字符串,起始于位置 pos。带有len参数的格式从字符串str返回一个长度同len字符相同的子字符串,起始于位置 pos。 使用 FROM的格式为标准 SQL 语法。也可能对pos使用一个负值。假若这样,则子字符串的位置起始于字符串结尾的pos 字符,而不是字符串的开头位置。在以下格式的函数中可以对pos 使用一个负值。 mysql> SELECT SUBSTRING('Quadratically',5);
-> 'ratically' mysql> SELECT SUBSTRING('foobarbar' FROM 4);
-> 'barbar' mysql> SELECT SUBSTRING('Quadratically',5,6);
-> 'ratica' mysql> SELECT SUBSTRING('Sakila', -3);
-> 'ila' mysql> SELECT SUBSTRING('Sakila', -5, 3);
-> 'aki' mysql> SELECT SUBSTRING('Sakila' FROM -4 FOR 2);
-> 'ki' TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str) TRIM(remstr FROM] str)
返回字符串 str , 其中所有remstr 前缀和/或后缀都已被删除。若分类符BOTH、LEADIN或TRAILING中没有一个是给定的,则假设为BOTH 。 remstr 为可选项,在未指定情况下,可删除空格。 mysql> SELECT TRIM(' bar ');
-> 'bar' mysql> SELECT TRIM(LEADING 'x' FROM 'xxxbarxxx');
-> 'barxxx' mysql> SELECT TRIM(BOTH 'x' FROM 'xxxbarxxx');
-> 'bar' mysql> SELECT TRIM(TRAILING 'xyz' FROM 'barxxyz');
-> 'barx' 部分内置函数
部分内置函数
1.自定义函数
#!!!注意!!!
#函数中不要写sql语句(否则会报错),函数仅仅只是一个功能,是一个在sql中被应用的功能
#若要想在begin...end...中写sql,请用存储过程
delimiter //
create function f1(
i1 int,
i2 int)
returns int
BEGIN
declare num int; #声明
set num = i1 + i2;
return(num);
END //
delimiter ;
delimiter //
create function f5(
i int
)
returns int
begin
declare res int default 0;
if i = 10 then
set res=100;
elseif i = 20 then
set res=200;
elseif i = 30 then
set res=300;
else
set res=400;
end if;
return res;
end //
delimiter ;
2.删除函数
drop function func_name;
3.执行函数
# 获取返回值
select UPPER('egon') into @res;
SELECT @res;
select f1(1,2) into @res;
select @res
# 在查询中使用 select f1(11,nid) ,name from tb2;
#1 基本使用
mysql> SELECT DATE_FORMAT('2009-10-04 22:23:00', '%W %M %Y');
-> 'Sunday October 2009'
mysql> SELECT DATE_FORMAT('2007-10-04 22:23:00', '%H:%i:%s');
-> '22:23:00'
mysql> SELECT DATE_FORMAT('1900-10-04 22:23:00',
-> '%D %y %a %d %m %b %j');
-> '4th 00 Thu 04 10 Oct 277'
mysql> SELECT DATE_FORMAT('1997-10-04 22:23:00',
-> '%H %k %I %r %T %S %w');
-> '22 22 10 10:23:00 PM 22:23:00 00 6'
mysql> SELECT DATE_FORMAT('1999-01-01', '%X %V');
-> '1998 52'
mysql> SELECT DATE_FORMAT('2006-06-00', '%d');
-> '' #2 准备表和记录
CREATE TABLE blog (
id INT PRIMARY KEY auto_increment,
NAME CHAR (32),
sub_time datetime
); INSERT INTO blog (NAME, sub_time)
VALUES
('第1篇','2015-03-01 11:31:21'),
('第2篇','2015-03-11 16:31:21'),
('第3篇','2016-07-01 10:21:31'),
('第4篇','2016-07-22 09:23:21'),
('第5篇','2016-07-23 10:11:11'),
('第6篇','2016-07-25 11:21:31'),
('第7篇','2017-03-01 15:33:21'),
('第8篇','2017-03-01 17:32:21'),
('第9篇','2017-03-01 18:31:21'); #3. 提取sub_time字段的值,按照格式后的结果即"年月"来分组
SELECT DATE_FORMAT(sub_time,'%Y-%m'),COUNT(1) FROM blog GROUP BY DATE_FORMAT(sub_time,'%Y-%m'); #结果
+-------------------------------+----------+
| DATE_FORMAT(sub_time,'%Y-%m') | COUNT(1) |
+-------------------------------+----------+
| 2015-03 | 2 |
| 2016-07 | 4 |
| 2017-03 | 3 |
+-------------------------------+----------+
rows in set (0.00 sec)
DATE_FORMAT需要掌握
六、流程控制
1.条件语句
举例一
delimiter //
CREATE PROCEDURE proc_if ()
BEGIN declare i int default 0;
if i = 1 THEN
SELECT 1;
ELSEIF i = 2 THEN
SELECT 2;
ELSE
SELECT 7;
END IF; END //
delimiter ;
举例二
#函数中不要写sql语句,它仅仅只是一个功能,是一个在sql中被应用的功能
#若要想在begin...end...中写sql,请用存储过程
delimiter //
create function f5(
i int
)
returns int
begin
declare res int default 0;
if i = 10 then
set res=100;
elseif i = 20 then
set res=200;
elseif i = 30 then
set res=300;
else
set res=400;
end if;
return res;
end //
delimiter ;
2.循环语句
delimiter //
CREATE PROCEDURE proc_while ()
BEGIN DECLARE num INT ;
SET num = 0 ;
WHILE num < 10 DO
SELECT
num ;
SET num = num + 1 ;
END WHILE ; END //
delimiter ;
while
delimiter //
CREATE PROCEDURE proc_repeat ()
BEGIN DECLARE i INT ;
SET i = 0 ;
repeat
select i;
set i = i + 1;
until i >= 5
end repeat; END //
delimiter ;
repeat
BEGIN
declare i int default 0;
loop_label: loop
set i=i+1;
if i<8 then
iterate loop_label;
end if;
if i>=10 then
leave loop_label;
end if;
select i;
end loop loop_label;
END
loop
mysql之视图,触发器,事务等。。。的更多相关文章
- MySQL拓展 视图,触发器,事务,存储过程,内置函数,流程控制,索引,慢查询优化,数据库三大设计范式
视图: 1.什么是视图 视图就是通过查询得到一张虚拟表,然后保存下来,下次直接使用即可 2.为什么要用视图 如果要频繁使用一张虚拟表,可以不用重复查询 3.如何使用视图 create view tea ...
- mysql 查询表,视图,触发器,函数,存储过程
1. mysql查询所有表: SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = '数据库名' AND TAB ...
- MySQL 视图触发器事务存储过程函数
事务 致命三问 什么是事务:开启了一个包含多条SQL语句的事务,这些SQL语句要么都执行成功,要么有别想成功:例如A向B转账,二人账户并不属于一家银行,在转账过程中由于网络问题,导致A显示转账 成功 ...
- MySQL 视图 触发器 事务 存储过程 函数 流程控制 索引与慢查询优化
视图 1.什么是视图? 视图就是通过查询得到的一张虚拟表,然后保存下来,下次可直接使用 2.为什么要使用视图? 如果要频繁使用一张虚拟表,可以不用重复查询 3.如何使用视图? create view ...
- MySQL——视图/触发器/事务/存储过程/函数/流程控制
一 视图 视图是一个虚拟表(非真实存在),其本质是[根据SQL语句获取动态的数据集,并为其命名],用户使用时只需使用[名称]即可获取结果集,可以将该结果集当做表来使用. 使用视图我们可以把查询过程中的 ...
- MySQL视图,触发器,事务,存储过程,函数
create triggr triafterinsertcmdlog after insert on cmd_log FOR EACH ROW trigger_body .#NEW : 代表新的记录 ...
- day 7-20 视图,触发器,事务
一.视图 视图是一个虚拟表(非真实存在),其本质是[根据SQL语句获取动态的数据集,并为其命名],用户使用时只需使用[名称]即可获取结果集,可以将该结果集当做表来使用. 使用视图我们可以把查询过程中的 ...
- Python11/26--mysql之视图/触发器/事务/存储过程
视图: 1.什么是视图 视图就是通过查询得到一张虚拟表,然后保存下来,下次用的时候直接使用即可 2.为什么用视图 如果要频繁使用一张虚拟表,可以不用重复查询 3.如何用视图 select * from ...
- Mysql学习---视图/触发器/存储过程/函数/执行计划/sql优化 180101
视图 视图: 视图是一个虚拟表(非真实存在),动态获取数据,仅仅能做查询操作 本质:[根据SQL语句获取动态的数据集,并为其命名],用户使用时只需使用[名称]即可获取结果集,并可以将其当作表来使用.由 ...
- MySQL_视图/触发器/事务/存储过程/函数
视图.触发器.事务.存储过程.函数 视图 视图是一个虚拟表(非真实存在),其本质是根据SQL语句获取动态的数据集,并为其命名,用户使用时只需使用名称即可获取结果集,可以将该结果集当作表来使用 #创建视 ...
随机推荐
- 2017ICPC南宁 M题 The Maximum Unreachable Node Set【二分图】
题意: 找出不能相互访问的点集的集合的元素数量. 思路: 偏序集最长反链裸题. 代码: #include<iostream> #include<cstring> using n ...
- 第26月第2天 vim javacomplete
1. 将解压出来的autoload 和 doc的内容添加到~/.vim/下的相应目录下,如果~/.vim下没有这两个文件夹就手动创建其中autoload里的有javacomplete.vim java ...
- 关于cmd命令
F: 直接进入F盘 cd\ 进入当前盘的根目录 md 文件名 创建文件名 cd 文件名 进入文件名 rd 文件名 删除文件夹
- 线程变量---ThreadLocal类
用处:保存线程的独立变量.对一个线程类(继承自Thread) 思想:如果一个资源会引起线程竞争,那就为每一个线程配置一个资源.相比于synchronized是一种空间换时间的策略 当使用ThreadL ...
- 常用的Character方法
- [转]Python中的eval()、exec()及其相关函数
Python中的eval().exec()及其相关函数 刚好前些天有人提到eval()与exec()这两个函数,所以就翻了下Python的文档.这里就来简单说一下这两个函数以及与它们相关的几个函数 ...
- keepalived 的某台vip连接不通【原创】
keepalived 的某台vip连接不通,vip可以漂移到这台服务器,但是ping vip不通,telnet vip 3306服务也不通,但是telnet 服务器真实物理IP 3306是通的. 切换 ...
- python3+selenium入门13-操作cookie
可以把cookie理解为自己账户的身份证.因为http协议是无状态的,上一个请求和下一个请求没有关系.但是有时需要有关联.比如登录之后,才能进行操作这样的设置.这个就是cookie在起作用.登录成功时 ...
- Memcached技术
Memcached技术 介绍: memcached是一种缓存技术, 他可以把你的数据放入内存,从而通过内存访问提速,因为内存最快的, memcached技术的主要目的提速, 在memachec 中维护 ...
- CAD版本 注册表信息
AutoCAD2002 AutoCAD.Application.15 AutoCAD2003 AutoCAD.Application.15.1 AutoCAD2004 AutoCAD.Applic ...