python(4): regular expression正则表达式/re库/爬虫基础
python 获取网络数据也很方便
抓取
requests 第三方库适合做中小型网络爬虫的开发, 大型的爬虫需要用到 scrapy 框架
解析
BeautifulSoup 库, re 模块
(一) requests 库
基本方法: requests.get() : 请求获取指定URL位置的资源, 对应http 协议的get方法
注意: 在抓取网页前要看一看这个网站是不是有爬虫协议,
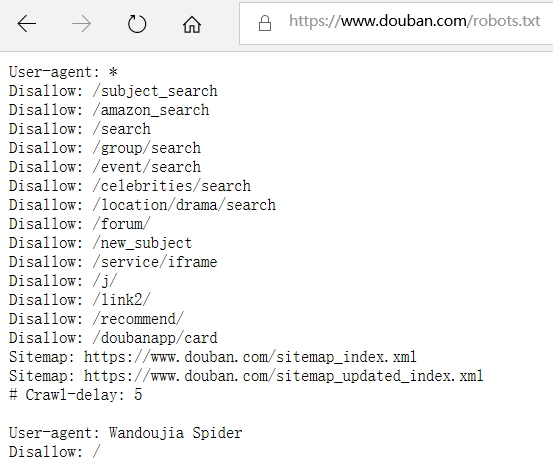
如何看网站的爬虫协议? 有的网站会提供robots.txt
例如豆瓣的 www.douban.com/robots.txt
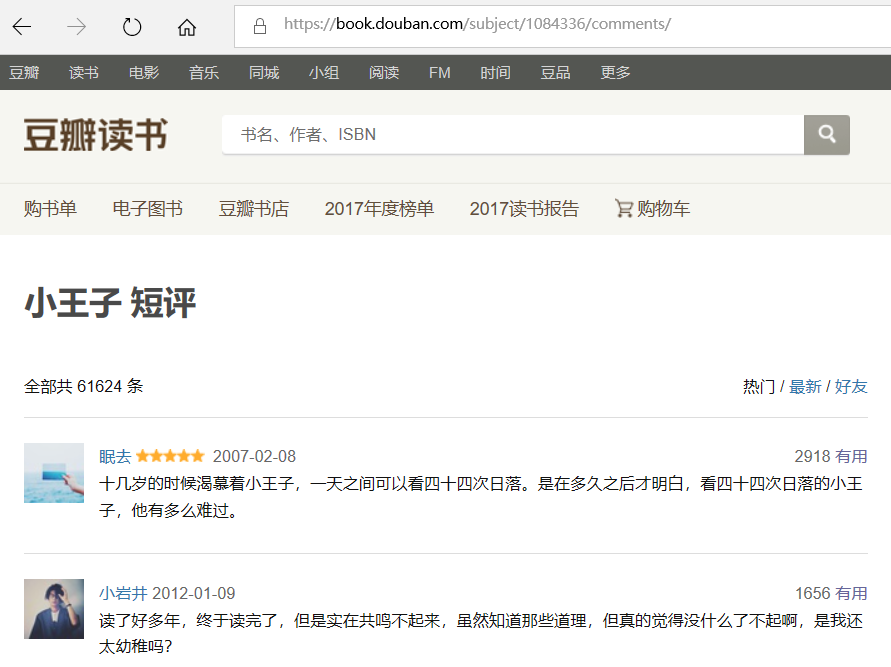
实例: 抓取豆瓣上小王子的一个书评
我们要抓取subject 目录, 从上述协议中看到它没有被禁止
抓取多个页面要注意他的延时, 这里是5s
import requests
r=requests.get('http://book.douban.com/subject/1084336/comments/')
print(r.status_code) # 200 则说明一切正常
print(r.text) # 获取页面内容
除了上述r.text 解码, 还有r.content, r.json 等
上述抓取的数据有很多以下结构
<p class="comment-content">
<span class="short">痛苦迷茫不是因为成为了“可笑”的大人,而是成为大人却没有真正长大。所以回过头来想要从怀念童年中解脱缓解痛苦那是本末倒置的做法。如果你作为一个成年人觉得痛苦,原因不是因为你“成年”了,也不是因为是生而为“人”,而是“你”停止了思考停止了学习</p>
可以用beautifulsoup进行解析, 举例来看
from bs4 import BeautifulSoup
markup='<p class="title"><b>The Little Prince</b></p>'
soup=BeautifulSoup(markup,'lxml') # 对于html使用lxml解析器较好
# soup 的对象有四种: tag , navigablestring, beautifulsoup, comment
#tag就是标签, 类似</b>**</b> 对文字内容的修饰
#navigablestring就是tag 中的字符串, 比如这里的The Little Prince
#comment 是navigablestring的子类
print(soup.b) # 标签b的内容: <b>The Little Prince</b>
print(type(soup.b)) # <class 'bs4.element.Tag'>
# tag 也有两个属性 name ,attrs
tag=soup.p
print(tag.name) # p
print(tag.attrs) # {'class': ['title']}
print(tag.string) # 取到了tag中包含的非属性的字符串:The Little Prince
print(type(tag.string)) # <class 'bs4.element.NavigableString'>
soup.find_all('b') # 找到所有b标签的内容
Out[24]: [<b>The Little Prince</b>]
小王子的解析
import requests
from bs4 import BeautifulSoup
r=requests.get('http://book.douban.com/subject/1084336/comments/')
soup=BeautifulSoup(r.text,'lxml') # 获得beautifulsoup 对象soup
pattern=soup.find_all('p','comment-content')
#评论的属性是标签p,属性是comment-content, 返回列表
for item in pattern: print(item.string)
没有结果, 全是none!! 为啥??
(二)regular expression
正则表达式可以简化字符串, 'py','pyy','pyyy','pyyy....' 这些都可以用 正则表达式py+ 表示
常用表达式:

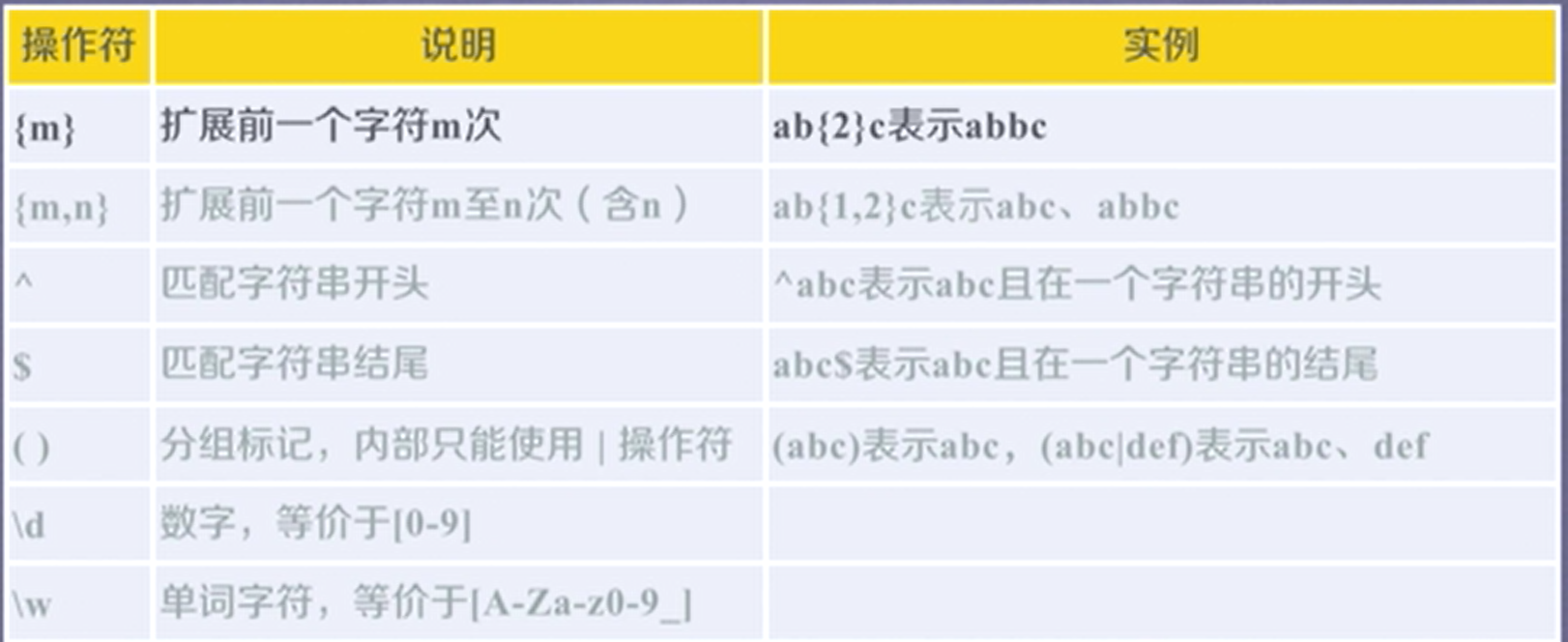
补充: \D 表示非数字字符 {m,} 至少扩展m次, {:m}扩展0-m次
\b :匹配一个单词边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。
\B :匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。
举例:
p(y|yt|yth|ytho)?n 表示: ?表示扩展0次或者1次, 表示为pn,pyn,pytn,pythn,python
python+ 表示: python ,pythonn,pythonnn,....
py[th]on 表示:pyton ,pyhon
py[^th]?on 表示:pyon,pyaon,pybon,....,其中排除 t h的字母进行0次或1次扩展
py{:3}on 表示pon pyon pyyon pyyyon (扩展y 0 1 2 3次)
^[A-Za-z]+$ 匹配字符串开头和结尾 ,表示 由26个字母组成的字符串
^[A-Za-z0-9]+$ 匹配字符串开头和结尾, 表示 由26个字母和10个数字组成的字符串
^-?\d+$ 整数形式的字符串(可能是负数)
^[0-9]*[1-9][0-9]*$ 正整数形式的字符串
[1-9]\d{5} 中国境内邮政编码(6位数)
[\u4e00-\u9fa5] 匹配中文字符
\d{3}-\d{8} 或者 \d{4}-\d{7} 表示国内电话号码: 010-62914227
举例: 匹配IP地址的正则表达式:
一个IP地址分为 四段,每段是0-255
\d+.\d+.\d+.\d+ 这个没有限制位数 :+可以扩展1次或者无限次
\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3} 这个有限制位数 每次是1 2 3位 ,但还是不精确 300.300.300.300也可以匹配
0-99表示为[0-9]?\d 100-199 表示为 1\d{2} 200-249 表示为2[0-4]\d 250-255 表示为25[0-5]
所示0-255由上面四段取| (或)得到,0-255表示为(([0-9]?\d |1\d{2}|2[0-4]\d|25[0-4]).){3}([0-9]?\d |1\d{2}|2[0-4]\d|25[0-4])
(二)re库介绍
re 是python的标准库,主要功能是用于字符串的匹配
import re 调用
正则表达式的表示类型:re库采用了raw string类型表示正则表达式,表示为r'text'
举例: r'[1-9]\d{5}' 大陆邮政编码
r'\d{3}-\d{8}|\d{4}-\d{7}' 国内电话号码
原生字符串与普通字符串不同在于 前面加一个r
区别在于原生字符串不包含转义符 \的 ,原生字符串中的\ 不解释为转义符
r'[1-9]\d{5}' 用普通字符串表示为:'[1-9]\\d{5}' 要用双斜杠\\

具体介绍上述函数:
(1) re.search(pattern, string, flags=0), pattern 表示正则表达式的字符串或者原生字符串
string表示待匹配字符串 ,flags表示一些控制标记

举例:
import re
match=re.search(r'[1-9]\d{5}','BIT 100081')
print(match)
print(match.group(0)) ans:
<_sre.SRE_Match object; span=(4, 10), match=''>
100081
(2)re.match(pattern, string, flags=0)
import re
match=re.match(r'[1-9]\d{5}','BIT 100081')
print(match)
print(match.group(0)) ans:AttributeError: 'NoneType' object has no attribute 'group'
报错了,因为这个字符串的开头不匹配
若要对匹配结果进行使用,为了防止报错,增加if 判断
import re
match=re.match(r'[1-9]\d{5}','BIT 100081')
if match:
print(match.group(0))
此时不会报错,但是也不会print 结果,因为匹配结果是空的!,以下正确!!可以匹配
import re
match=re.match(r'[1-9]\d{5}','100081 BIT')
if match:
print(match.group(0)
ans:
100081
(3)re.findall(pattern, string, flags=0) 返回列表类型
import re
ls=re.findall(r'[1-9]\d{5}','BIT 100081 XYT 100099')
if ls:
print(ls) ans:
['', '']
(4)re.split(pattern, string, maxsplit=0,flags=0) 返回列表类型,maxsplit最大分割数,超过它的作为一个整体最后再输出来.
import re
print(re.split(r'[0-9]\d{5}','BIT 100081 XYT 100099')) ans:
['BIT ', ' XYT ', '']
上述将匹配的删除,增加maxsplit=1,结果是:
import re
print(re.split(r'[0-9]\d{5}','BIT 100081 XYT 100099',maxsplit=1)) ans:
['BIT ', ' XYT 100099']
(5)re.finditer(pattern, string,flags=0)
import re
for m in re.finditer(r'[1-9]\d{5}','BIT 100081 XYT 100099'):
if m:
print(m.group(0)) ans:
100081
100099
100081
100099
(6)re.sub(pattern,repl, string,count=0,flags=0):替换所有匹配的字符串,并返回替换后的字符串
其中repl:表示替代匹配字符串的字符串(新的字符串)
count 表示匹配最大替换的次数
import re
subs=re.sub(r'[1-9]\d{5}',':zipcode','BIT 100081 XYT 100099')
print(subs) ans:
BIT :zipcode XYT :zipcode
上述六个常用的归纳:
其中re.search() re.match() 返回match对象, re.finditer()每个迭代元素是match对象
补充:re 的另一种等价用法
import re
rst1=re.search(r'[1-9]\d{5}','BIT 100081 XYT 100099')
print(rst1.group(0)) pat=re.compile(r'[1-9]\d{5}')#先进行编译,
rst2=pat.search('BIT 100089 XYT 100099')
print(rst2.group(0)) ans:
100081
100089
#re.compile可以将正则表达式的字符串形式编译成正则表达式对象
re.compile(pattern,flags=0)
(三)返回match对象 啥是match对象??

match对象的使用方法::

举例:
import re
m=re.search(r'[1-9]\d{5}','BIT 100081 XYT 100099')
print(m.string)
print(m.re)
print(m.pos)
print(m.endpos)
print(m.group(0))#只返回一次匹配结果,若要多次匹配结果则 用re.finditer()
print(m.start())
print(m.end())
print(m.span())
结果:
BIT 100081 XYT 100099
re.compile('[1-9]\\d{5}') #说明了只有经过compile的才是真正的正则表达式
0
21
100081#返回第一个匹配结果
4 #匹配结果在原字符串中的起始位置
10
(4, 10)
(四)re的贪婪匹配
import re
#re默认采用贪婪匹配,即输出匹配最长的子串
m=re.search(r'py.*n','pyanbbncccn')
print(m.group()) #如何匹配最短的字符串? 最小匹配,加一个?就可以了
m1=re.search(r'py.?*n','pyanbbncccn')
print(m1.group()) ans:
pyanbbncccn
pyan

python(4): regular expression正则表达式/re库/爬虫基础的更多相关文章
- Regular Expression(正则表达式)之邮箱验证
正则表达式(regular expression, 常常缩写为RegExp) 是一种用特殊符号编写的模式,描述一个或多个文本字符串.使用正则表达式匹配文本的模式,这样脚本就可以轻松的识别和操作文本.其 ...
- python learning Regular Expression.py
# 正则表达式,又称规则表达式.(英语:Regular Expression,在代码中常简写为regex.regexp或RE),计算机科学的一个概念.正则表达式通常被用来检索.替换那些符合某个模式(规 ...
- [Leetcode][Python][DP]Regular Expression Matching
# -*- coding: utf8 -*-'''https://oj.leetcode.com/problems/regular-expression-matching/ Implement reg ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
- 六 web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode("utf-8")将字节转化成字符串 ...
- 【python】版本35 正则-非库-爬虫-读写xlw文件
#交代:代码凌乱,新手一个,论坛都是高手,我也是鼓了很大勇气,发出来就是被批评和进步的 #需求:需要对某网站的某id子标签批量爬取,每个网页的id在xlw里,爬取完,再批量存取到这xlw里的第6行 ...
- Regular Expression 正则表达式
1. "^"表示以什么字符开始,"$"表示以什么字符结束: 2. \w表示字符类,包括大小写字母和数字: 3. “+”表示一个或多个,"*" ...
- python中在计算机视觉中的库及基础用法
基于python脚本语开发的数字图像处理包有很多,常见的比如PIL.Pillow.opencv.scikit-image等.PIL和pillow只提供了基础的数字图像处理,功能有限:OpenCV实际上 ...
- 正则表达式-使用说明Regular Expression How To (Perl, Python, etc)
notepad++ wiki about regular expression 正则表达式-使用说明Regular Expression How To (Perl, Python, etc) http ...
随机推荐
- openwrt package 依赖关系
参考链接: https://blog.csdn.net/zxygww/article/details/49181065
- 【转载】java abstract class和interface的区别
转载:https://blog.csdn.net/b271737818/article/details/3950245 在Java语言中,abstract class和interface是支持抽象类定 ...
- 使用Docker部署javaWeb应用
1. 安装Dcoker http://www.cnblogs.com/zhangqian27/p/9089815.html 2. 查看镜像 $ docker images 3. 搜索镜像 $ dock ...
- J - Joyful HDU - 5245 (概率)
题目链接: J - Joyful HDU - 5245 题目大意:给你一个n*m的矩阵,然后你有k次涂色机会,然后每一次可以选定当前矩阵的一个子矩阵染色,问你这k次用完之后颜色个数的期望. 具体思路 ...
- MySQL触发器trigger的使用
https://www.cnblogs.com/geaozhang/p/6819648.html 触发器的触发 语句的错误 和 触发器里面 错误 都不会运行 NEW与OLD详解 MySQL 中定义了 ...
- 论文笔记:Selective Search for Object Recognition
与 Selective Search 初次见面是在著名的物体检测论文 「Rich feature hierarchies for accurate object detection and seman ...
- Delphi 三层框架 DataSnap 的服务器端设置
elphi 三层框架 DataSnap 的服务器端设置: DataSnap 框架有三个模块:DataSnap Server,Server Module,DataSnap Client Module. ...
- boost 实现http断点续传
// testc.cpp : Defines the entry point for the console application. // #include "stdafx.h" ...
- 激活函数Sigmoid、Tanh、ReLu、softplus、softmax
原文地址:https://www.cnblogs.com/nxf-rabbit75/p/9276412.html 激活函数: 就是在神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端. 常见 ...
- expect学习笔记及实例详解
因为最近正在学习expect脚本,但是发现网上好多文章都是转载的,觉得这篇文章还不错,所以简单修改之后拿过来和大家分享一下~ 1. expect是基于tcl演变而来的,所以很多语法和tcl类似,基本的 ...