Spark1.0.0 源码编译和部署包生成
问题导读:
1、如何对Spark1.0.0源码编译?
2、如何生成Spark1.0的部署包?
3、如何获取包资源?
Spark1.0.0的源码编译和部署包生成,其本质只有两种:Maven和SBT,只不过针对不同场景而已:
Maven编译
SBT编译
IntelliJ IDEA编译(可以采用Maven或SBT插件编译),适用于开发人员
部署包生成(内嵌Maven编译),适用于维护人员
编译的目的是生成指定环境下运行Spark本身或开发Spark Application的JAR包,本次编译的目的生成运行在hadoop2.2.0上的Spark JAR包。缺省编译所支持的hadoop环境是hadoop1.0.4。
1:获取Spark1.0.0 源码官网下载
2:SBT编译
将源代码复制到指定目录,然后进入该目录,运行:
- SPARK_HADOOP_VERSION=2.2.0 SPARK_YARN=true sbt/sbt assembly
复制代码
3:Maven编译
事先安装好maven3.04或maven3.05,并设置要环境变量MAVEN_HOME,将$MAVEN_HOME/bin加入PATH变量。然后将源代码复制到指定目录,然后进入该目录,先设置Maven参数:
- export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m"
复制代码
再运行:
- mvn -Pyarn -Dhadoop.version=2.2.0 -Dyarn.version=2.2.0 -DskipTests clean package
复制代码
<ignore_js_op>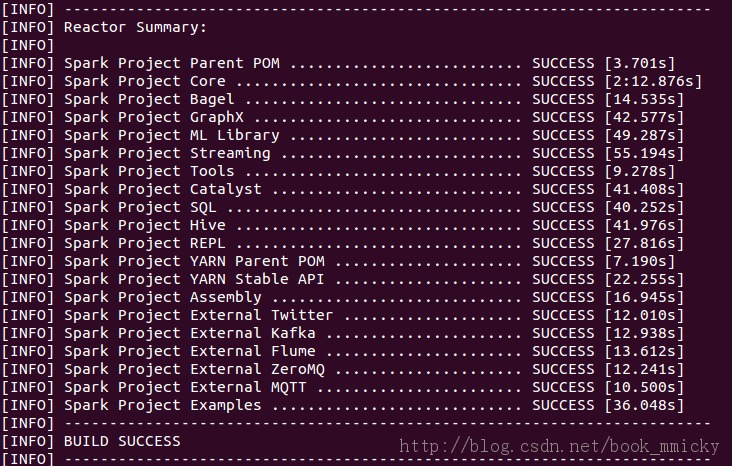
4:IntelliJ IDEA编译
IntelliJ IDEA是个优秀的scala开发IDE,所以顺便就提一下IntelliJ IDEA里的spark编译。
首先将源代码复制到指定目录,然后启动IDEA -> import project -> import project from external model -> Maven编译目录中的pom.xml -> 在选择profile时选择hadoop2.2 -> 直到导入项目。
<ignore_js_op>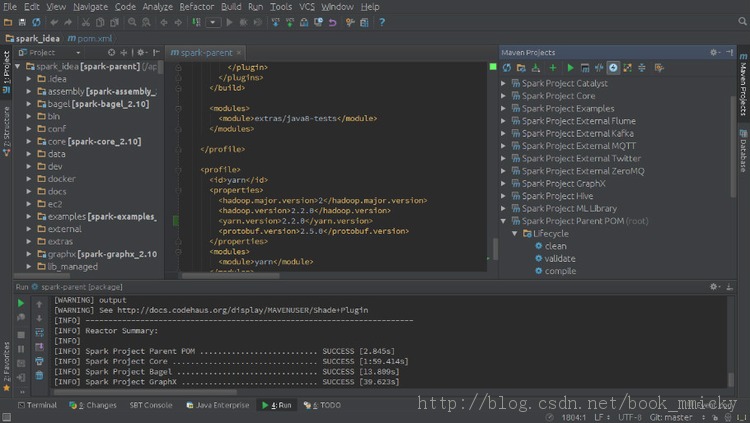
在maven projects视图选择Spark Project Parent POM(root),然后选中工具栏倒数第四个按钮(ship Tests mode)按下,这时Liftcycle中test是灰色的。
接着按倒数第一个按钮进入Maven设置,在runner项设置VM option:
- -Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m
复制代码
<ignore_js_op>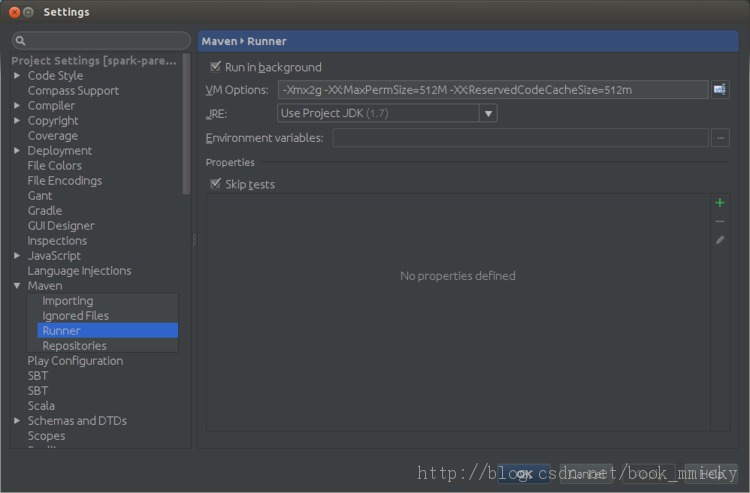
按OK 保存。
回到maven projects视图,点中Liftcycle中package,然后按第5个按钮(Run Maven Build按钮),开始编译。其编译结果和Maven编译是一样的。
5:生成spark部署包
编译完源代码后,虽然直接用编译后的目录再加以配置就可以运行spark,但是这时目录很庞大,又3G多吧,部署起来很不方便,所以需要生成部署包。
spark源码根目录下带有一个脚本文件make-distribution.sh可以生成部署包,其参数有:
--hadoop VERSION:打包时所用的Hadoop版本号,不加此参数时hadoop版本为1.0.4。
--with-yarn:是否支持Hadoop YARN,不加参数时为不支持yarn。
--with-hive:是否在Spark SQL 中支持hive,不加此参数时为不支持hive。
--skip-java-test:是否在编译的过程中略过java测试,不加此参数时为略过。
--with-tachyon:是否支持内存文件系统Tachyon,不加此参数时不支持tachyon。
--tgz:在根目录下生成 spark-$VERSION-bin.tgz,不加此参数时不生成tgz文件,只生成/dist目录。
--name NAME:和--tgz结合可以生成spark-$VERSION-bin-$NAME.tgz的部署包,不加此参数时NAME为hadoop的版本号。
如果要生成spark支持yarn、hadoop2.2.0的部署包,只需要将源代码复制到指定目录,进入该目录后运行:
- ./make-distribution.sh --hadoop 2.2.0 --with-yarn --tgz
复制代码
如果要生成spark支持yarn、hive的部署包,只需要将源代码复制到指定目录,进入该目录后运行:
- ./make-distribution.sh --hadoop 2.2.0 --with-yarn --with-hive --tgz
复制代码
如果要生成spark支持yarn、hadoop2.2.0、techyon的部署包,只需要将源代码复制到指定目录,进入该目录后运行:
- ./make-distribution.sh --hadoop 2.2.0 --with-yarn --with-tachyon --tgz
复制代码
生成在部署包位于根目录下,文件名类似于spark-1.0.0-bin-2.2.0.tgz。
值得注意的是:make-distribution.sh已经带有Maven编译过程,所以不需要先编译再打包。
资源下载包-较全
6:后记
解压部署包后或者直接在编译过的目录,通过配置conf下的文件,就可以使用spark了。
Spark有下列几种部署方式:
Standalone
YARN
Mesos
Amazon EC2
其实说部署,还不如说运行方式,Spark只是利用不同的资源管理器来申请计算资源。其中Standalone方式是使用Spark本身提供的资源管理器,可以直接运行;而在YARN运行,需要提供运行Spark Application的jar包(或者直接在NM节点上部署Spark):
maven编译的jar包为:./assembly/target/scala-2.10/spark-assembly-1.0.0-hadoop2.2.0.jar
SBT编译的jar包为:./assembly/target/scala-2.10/spark-assembly-1.0.0-hadoop2.2.0.jar
具体使用参见:Spark1.0.0 YARN模式部署
TIPS:
众所周知的网络问题,编译的时候经常会发生卡死的现象,对于maven编译,只需要安ctrl+z结束进程重新编译就可以了;而对于sbt编译,由于有时候会有文件锁定的问题,在按ctrl+z结束进程后,最好退出终端后再开启一个新的终端进行编译
Spark1.0.0 源码编译和部署包生成的更多相关文章
- 英蓓特Mars board的android4.0.3源码编译过程
英蓓特Mars board的android4.0.3源码编译过程 作者:StephenZhu(大桥++) 2013年8月22日 若要转载,请注明出处 一.编译环境搭建及要点: 1. 虚拟机软件virt ...
- spark2.1.0的源码编译
本文介绍spark2.1.0的源码编译 1.编译环境: Jdk1.8或以上 Hadoop2.7.3 Scala2.10.4 必要条件: Maven 3.3.9或以上(重要) 点这里下载 http:// ...
- 非寻常方式学习ApacheTomcat架构及10.0.12源码编译
概述 开启博客分享已近三个月,感谢所有花时间精力和小编一路学习和成长的伙伴们,有你们的支持,我们继续再接再厉 **本人博客网站 **IT小神 www.itxiaoshen.com 定义 Tomcat官 ...
- 解决Tomcat10.0.12源码编译问题进而剖析其优秀分层设计架构
概述 Tomcat.Jetty.Undertow这几个都是非常有名实现Servlet规范的应用服务器,Tomcat本身也是业界上非常优秀的中间件,简单可将Tomcat看成是一个Http服务器+Serv ...
- android 5.0 (lollipop)源码编译环境搭建(Mac OS X)
硬件环境:MacBook Pro Retina, 13-inch, Late 2013 处理器 2.4 GHz Intel Core i5 内存 8 GB 1600 MHz DDR3 硬盘60G以 ...
- hadoop2.0 eclipse 源码编译
在eclipse下编译hadoop2.0源码 http://www.cnblogs.com/meibenjin/archive/2013/07/05/3172889.html hadoop cdh4编 ...
- Spark-2.0.2源码编译
注:图片如果损坏,点击文章链接:https://www.toutiao.com/i6813925210731840013/ Spark官网下载地址: http://spark.apache.org/d ...
- kafka 0.11.0.3 源码编译
首先下载 kafka 0.11.0.3 版本 源码: http://mirrors.hust.edu.cn/apache/kafka/0.11.0.3/ 下载源码 首先安装 gradle,不再说明 1 ...
- anroid 6.0.1_r77源码编译
一.源码下载(基本类似4.4.4_r1) 二.必须使用openjdk1.7 sudo add-apt-repository ppa:openjdk-r/ppa sudo apt-get update ...
随机推荐
- [转]如何在Angular4中引入jquery
本文转自:https://blog.csdn.net/home_zhang/article/details/77992734 1.anjq是我的项目名称: 在anjq目录下打开dos命令窗口,然后依次 ...
- 重构——一个小例子
菜鸟区域,老鸟绕路! 原代码,这是一个可以借阅影片的小程序,你可以想象成某个大型系统,我想代码应该都能很容易看懂: using System; using System.Collections.Gen ...
- Spring-继承JdbcDaoSupport类后简化配置文件内容
正常情况下,我们在实现类中想要晕用模板类需要在配置文件中注入连接池,再将连接池注入给模板类,然后在实现类中得到. <!-- 配置C3P0连接池 --> <bean id = &quo ...
- js中字符串和数组的使用
函数: 函数在调用的时候,会形成一个私有作用域,内部的变量不会被外面访问,这种保护机制叫闭包.这就意味着函数调用完毕,这个函数形成的栈内存会被销毁. 但有时候我们不希望他被销毁. 函数归属谁跟它在哪调 ...
- 应用分类&练手项目计划
应用分类 练手项目 [应用] 通讯录 xx管理 聊天室 [组件] web容器 db 中间件
- C#DataTable添加列、C#指定位置添加列
DataSet ds = SQlHelper.GetDataTable(Con, sb.ToString()); ds.Tables[].Columns.Add("Check", ...
- 13.Odoo产品分析 (二) – 商业板块(6) –采购(3)
接上一篇 查看Odoo产品分析系列--目录 接上一篇Odoo产品分析 (二) – 商业板块(6) –采购(2) 7. 仓库 仓库是在安装采购管理模块时出现的菜单.用于管理工厂库存,包括已经在手的货物 ...
- power designer的安装
PowerDesigner的安装 原由:新学期要开概要设计(软件设计与体系结构)这门课,老师推荐了两个CASE工具. Rational Rose Power Designer 本来想找rose的资源, ...
- Flask路由与蓝图Blueprint
需求分析: 当一个庞大的系统中有很多小模块,在分配路由的时候怎么处理呢?全部都堆到一个py程序中,调用@app.route? 显然这是很不明智的,因为当有几十个模块需要写路由的时候,这样程序员写着写着 ...
- Javascript数组系列一之栈与队列
所谓数组(英语:Array),是有序的元素序列. 若将有限个类型相同的变量的集合命名,那么这个名称为数组名. 组成数组的各个变量称为数组的分量,也称为数组的元素,有时也称为下标变量. ---百度百科 ...