Elasticsearch:定制分词器(analyzer)及相关性
转载自:https://elasticstack.blog.csdn.net/article/details/114278163
在许多的情况下,我们使用现有的分词器已经足够满足我们许多的业务需求,但是也有许多的情况,我们需要定制一个特定的分词器来满足我们特定的需求。我们知道要实现全文搜索,在文档被导入到 Elasticsearch 后,每个字段都需要被分析。这里就涉及到分词。如果你对分词器还不是很了解的话,那么请参考我之前的文章 “Elasticsearch: analyzer”。
一旦文档被导入到 Elasticsearch 之后,我们就可以对其中的字段进行搜索了。通常它会依据默认的 BM25 算法对每个文档的相关性进行打分。关于每个文档的分数是如何得到的,我们可以参照文档 “Elasticsearch:分布式计分” 来了解更多。这个打分会影响搜索返回结果的先后顺序。打分最高的文档排在返回结果的最前面,紧接着是排名第二的分数,依次类推。默认的 BM25 打分规则虽然能满足我们绝大多数的需求,但是在实际的使用中,有时不能完全满足我们的需求,比如我希望一首排名靠前的歌曲的会影响最终的得分,离我们位置最近的新闻排在前面,最近发生的新闻优先排在许多年前的新闻之前。针对这些特殊的需求,我们需要定制分数的算法。
在今天的展示中,我将展示如何实现一个定制的分词器 (custom analyzer)及定制相关性。
安装
如果你还没有安装好自己的 Elastic Stack, 请参阅我之前的文章 “Elastic:菜鸟上手指南” 安装好自己的 Elasticsearch 及 Kibana。
定制 analyzer
默认情况下,如果未应用自定义设置,Elasticsearch 将使用 “standard” 分词器分析输入文本。比如:
POST _analyze
{
"text": "Hélène Ségara it's !<>#"
}
在上面的字符串是一些外文的文字。它们看起来很不整齐,而且其中还有一些除字母数字之外的符号。上面的返回结果为:
{
"tokens" : [
{
"token" : "hélène",
"start_offset" : 0,
"end_offset" : 6,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "ségara",
"start_offset" : 7,
"end_offset" : 13,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "it's",
"start_offset" : 14,
"end_offset" : 18,
"type" : "<ALPHANUM>",
"position" : 2
}
]
}
上面使用 standard 分词器把文本进行了分词。当我们搜索时按照上面的 token 进行搜索,就可以搜索到这个文档。
下面,我们来输入 4 个文档:
POST content/_bulk
{"index":{"_id":"a1"}}
{"type":"ARTIST","artist_id":"a1","artist_name":"Sezen Aksu","ranking":10}
{"index":{"_id":"a2"}}
{"type":"ARTIST","artist_id":"a2","artist_name":"Selena Gomez","ranking":100}
{"index":{"_id":"a3"}}
{"type":"ARTIST","artist_id":"a3","artist_name":"Shakira","ranking":10}
{"index":{"_id":"a4"}}
{"type":"ARTIST","artist_id":"a4","artist_name":"Hélène Ségara","ranking":1000}
上面是假设的一个音乐库里的文档。它包含了艺术家的 id,艺术家的名字,以及艺术家的 ranking,也就是排名。执行上面的命令。这样我们就把上面的 4 个文档导入到 Elasticsearch 中去了。
假设我们在手机里有如下的一个搜索界面:
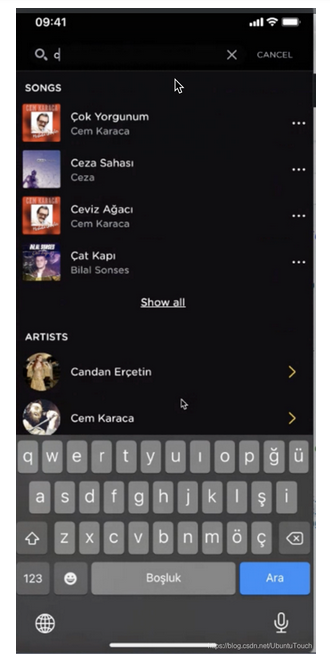
在上面,我们在输入字母 c 的时候,马上就有以 c 开头的所有艺术家的名字列表出来供我们来选择。针对我们的情况,我们打入如下的命令来搜索 artist_name 是以 s 开头的:
POST content/_search
{
"query": {
"multi_match": {
"query": "s",
"fields": [
"artist_name"
]
}
}
}
上面的搜索将不会返回任何的内容。这个结果一点也不奇怪,因为所有的字段里的分词没有一个是含有 "s" 的 token。
我们下面先用一个例子来进行展示如何创建一个定制的 analyzer。首先,我们可以使用 pattern_replace 这个 char_filter 来替换其中的一些字符:
POST _analyze
{
"text": "Hélène Ségara it's !<>#",
"char_filter": [
{
"type": "pattern_replace",
"pattern": "[^\\s\\p{L}\\p{N}]",
"replacement": ""
}
],
"tokenizer": "standard"
}
在这里的 pattern 它使用了 regular expression。你可以参阅链接了解更多关于 Java Regular Expressions。上面的意思是替换任何以空格开始的但不是字母和数字的字符为空字符。上面命令运行的结果为:
{
"tokens" : [
{
"token" : "Hélène",
"start_offset" : 0,
"end_offset" : 6,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "Ségara",
"start_offset" : 7,
"end_offset" : 13,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "its",
"start_offset" : 14,
"end_offset" : 18,
"type" : "<ALPHANUM>",
"position" : 2
}
]
}
在上,我们可以看到有大写的字母在最后的 token 里,我们可以使用如下的方法来把所有的字母都变为小写的字母:
POST _analyze
{
"text": "Hélène Ségara it's !<>#",
"char_filter": [
{
"type": "pattern_replace",
"pattern": "[^\\s\\p{L}\\p{N}]",
"replacement": ""
}
],
"tokenizer": "standard",
"filter": [
"lowercase"
]
}
在上面的 filter 中,我们添加了 lowercase。这个 filter 它可以把所的字母都变为小写字母。上面命令输出的结果是:
{
"tokens" : [
{
"token" : "hélène",
"start_offset" : 0,
"end_offset" : 6,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "ségara",
"start_offset" : 7,
"end_offset" : 13,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "its",
"start_offset" : 14,
"end_offset" : 18,
"type" : "<ALPHANUM>",
"position" : 2
}
]
}
从上面我们可以看出所有的 token 都变为小写的字母了。我们也可以看到其中的一些很怪的字母,比如 é。这个字母在英文字母中不可见。我们可以通过 asciifolding 这个过滤器来对它进行处理:
POST _analyze
{
"text": "Hélène Ségara it's !<>#",
"char_filter": [
{
"type": "pattern_replace",
"pattern": "[^\\s\\p{L}\\p{N}]",
"replacement": ""
}
],
"tokenizer": "standard",
"filter": [
"lowercase",
"asciifolding"
]
}
在上面,我们添加了 asciifolding 过滤器,那么它的输出为:
{
"tokens" : [
{
"token" : "helene",
"start_offset" : 0,
"end_offset" : 6,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "segara",
"start_offset" : 7,
"end_offset" : 13,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "its",
"start_offset" : 14,
"end_offset" : 18,
"type" : "<ALPHANUM>",
"position" : 2
}
]
}
从上面的输出中,我们可以看到所有的字母都变为小写,并且都是英文字母。接下来,我们希望对其中的每个 token 进行更进一步的分词,从而使它们变为可以搜索的 token,比如 'h', 'he', 'hel', 'hele'。这个我们需要使用到 ngram。你可以参阅我之前的文档 “Elasticsearch: Ngrams, edge ngrams, and shingles”。
POST _analyze
{
"text": "Hélène Ségara it's !<>#",
"char_filter": [
{
"type": "pattern_replace",
"pattern": """[^\s\p{L}\p{N}]""",
"replacement": ""
}
],
"tokenizer": "standard",
"filter": [
"lowercase",
"asciifolding",
{
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
}
]
}
上面的命令输出的结果为:
{
"tokens" : [
{
"token" : "h",
"start_offset" : 0,
"end_offset" : 6,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "he",
"start_offset" : 0,
"end_offset" : 6,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "hel",
"start_offset" : 0,
"end_offset" : 6,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "hele",
"start_offset" : 0,
"end_offset" : 6,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "helen",
"start_offset" : 0,
"end_offset" : 6,
"type" : "<ALPHANUM>",
"position" : 0
},
...
也就是说当我们输入 'h' 时, 该文档也会被搜索到。当我们输入 'he' 时,该文档,也可以被搜索到。
到现在我们是时候定义我们定制 analyzer 了。我们首先删除之前的 content 索引:
DELETE /content
我们接着使用如下的命令来创建 content 索引:
PUT content
{
"settings": {
"analysis": {
"filter": {
"front_ngram": {
"type": "edge_ngram",
"min_gram": "1",
"max_gram": "12"
}
},
"analyzer": {
"i_prefix": {
"filter": [
"lowercase",
"asciifolding",
"front_ngram"
],
"tokenizer": "standard"
},
"q_prefix": {
"filter": [
"lowercase",
"asciifolding"
],
"tokenizer": "standard"
}
}
}
},
"mappings": {
"properties": {
"type": {
"type": "keyword"
},
"artist_id": {
"type": "keyword"
},
"ranking": {
"type": "double"
},
"artist_name": {
"type": "text",
"analyzer": "standard",
"index_options": "offsets",
"fields": {
"prefix": {
"type": "text",
"term_vector": "with_positions_offsets",
"index_options": "docs",
"analyzer": "i_prefix",
"search_analyzer": "q_prefix"
}
},
"position_increment_gap": 100
}
}
}
}
在上面,有两个部分:settings 及 mappings。在 settings 的部分,它定义两个分词器: i_prefix 及 q_prefix。它们分别是 input,也就是导入文档时要使用的分词器,而 q_prefix 则指的是在 query,也就是在搜索时使用的分词器。如果大家读这个还不是很明白的话,请参阅我之前的文档 “Elasticsearch: analyzer”。在 mappings 里,针对 content,它是一个 multi-field 的字段。除了 content 可以被正常搜索以外,我们添加 content.prefix 字段。针对这个字段,在导入时使用 i_prefix 分词器,而对搜索文字来说,它使用 q_prefix 分词器。
接下来,我们使用先前的方法来重新导入之前的四个文档:
POST content/_bulk
{"index":{"_id":"a1"}}
{"type":"ARTIST","artist_id":"a1","artist_name":"Sezen Aksu","ranking":10}
{"index":{"_id":"a2"}}
{"type":"ARTIST","artist_id":"a2","artist_name":"Selena Gomez","ranking":100}
{"index":{"_id":"a3"}}
{"type":"ARTIST","artist_id":"a3","artist_name":"Shakira","ranking":10}
{"index":{"_id":"a4"}}
{"type":"ARTIST","artist_id":"a4","artist_name":"Hélène Ségara","ranking":1000}
一旦数据被导入,我们可以使用如下的命令来对文档进行搜索:
POST content/_search
{
"query": {
"multi_match": {
"query": "s",
"fields": [
"artist_name.prefix"
]
}
}
}
我们可以看到 4 个文档都被搜索到了。我们可以打入如下的搜索:
POST content/_search
{
"query": {
"multi_match": {
"query": "se",
"fields": [
"artist_name.prefix"
]
}
}
}
上面的命令输出的结果为:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 0.3359957,
"hits" : [
{
"_index" : "content",
"_type" : "_doc",
"_id" : "a1",
"_score" : 0.3359957,
"_source" : {
"type" : "ARTIST",
"artist_id" : "a1",
"artist_name" : "Sezen Aksu",
"ranking" : 10
}
},
{
"_index" : "content",
"_type" : "_doc",
"_id" : "a2",
"_score" : 0.30920535,
"_source" : {
"type" : "ARTIST",
"artist_id" : "a2",
"artist_name" : "Selena Gomez",
"ranking" : 100
}
},
{
"_index" : "content",
"_type" : "_doc",
"_id" : "a4",
"_score" : 0.29735082,
"_source" : {
"type" : "ARTIST",
"artist_id" : "a4",
"artist_name" : "Hélène Ségara",
"ranking" : 1000
}
}
]
}
}
从上面的返回结果来看,索引以 se 开头的艺术家的名字都被正确地搜索到了,并返回。但是也有一些不如意的地方,比如 Sezen Aksu 的得分最高,但是他的 ranking 却只有 10,相反 Hélène Ségara 的得分最低,但是它的 ranking 却非常高。这个返回结果的 score 显然和我们的需求不太一样。如果你仔细阅读一些文章 “Elasticsearch:分布式计分”,你就会发现 Sezen 的字符串长度比 Ségara 要短。这也是它为什么得分比较高的原因。接下来,我们来通过一些算法来定制相关性。
定制相关性 (relevance)
所谓的相关性,也就是在搜索返回时的 score。相关性越高,那么得分就越高,它就会排在返回结果的前面,我们可通过 function_score 来定制相关性。为了能够让分数和 rangking 这个字段能有效地结合起来。我们希望 ranking 的值越高,能够在最终的得分钟起到一定的影响。我们可以通过这样的写法:
POST content/_search
{
"from": 0,
"size": 10,
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "se",
"fields": [
"artist_name.prefix"
]
}
},
"functions": [
{
"filter": {
"match_all": {
"boost": 1
}
},
"script_score": {
"script": {
"source": "Math.max(((!doc['ranking'].empty)? Math.log10(doc['ranking'].value) : 1), 1)",
"lang": "painless"
}
}
}
],
"boost": 1,
"boost_mode": "multiply",
"score_mode": "multiply"
}
},
"sort": [
{
"_score": {
"order": "desc"
}
}
]
}
在上面的第一部分:
"query": {
"multi_match": {
"query": "se",
"fields": [
"artist_name.prefix"
]
}
},
我们对文档含有 se 为开头的字符串文档进行搜索。在第二部分:
"functions": [
{
"filter": {
"match_all": {
"boost": 1
}
},
"script_score": {
"script": {
"source": "Math.max(((!doc['ranking'].empty)? Math.log10(doc['ranking'].value) : 1), 1)",
"lang": "painless"
}
}
}
],
我们针对 ranking 使用了自己的一个算法并得出来一个分数。在第三部分:
"boost": 1,
"boost_mode": "multiply",
"score_mode": "multiply"
我们使用刚才得到的分数和之前搜索得到得分进行相乘,并得出来最后的分数。基于这种算法,ranking 越高,给搜索匹配得出来的分数的加权值就越高。从某种程度上讲,ranking 的大小会影响最终的排名。
经过上面的改造之后,最后的排名为:
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 0.9777223,
"hits" : [
{
"_index" : "content",
"_type" : "_doc",
"_id" : "a4",
"_score" : 0.9777223,
"_source" : {
"type" : "ARTIST",
"artist_id" : "a4",
"artist_name" : "Hélène Ségara",
"ranking" : 1000
}
},
{
"_index" : "content",
"_type" : "_doc",
"_id" : "a2",
"_score" : 0.6778009,
"_source" : {
"type" : "ARTIST",
"artist_id" : "a2",
"artist_name" : "Selena Gomez",
"ranking" : 100
}
},
{
"_index" : "content",
"_type" : "_doc",
"_id" : "a1",
"_score" : 0.36826363,
"_source" : {
"type" : "ARTIST",
"artist_id" : "a1",
"artist_name" : "Sezen Aksu",
"ranking" : 10
}
}
]
}
}
这一次,我们看到 Hélène Ségara 排到了第一名。
在实际的使用中,由于有海量的数据,scripts 的计算会影响搜索的速度。我们可以针对一个用所关心的歌曲进行过滤:
POST /content/_search
{
"from": 0,
"size": 10,
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "s",
"fields": [
"artist_name.prefix"
]
}
},
"functions": [
{
"filter": {
"terms": {
"artist_id": [
"a4",
"a3"
]
}
},
"script_score": {
"script": {
"source": "params.boosts.get(doc[params.artistIdFieldName].value)",
"lang": "painless",
"params": {
"artistIdFieldName": "artist_id",
"boosts": {
"a4": 5,
"a3": 2
}
}
}
}
}
],
"boost": 1,
"boost_mode": "multiply",
"score_mode": "multiply"
}
},
"sort": [
{
"_score": {
"order": "desc"
}
}
]
}
在上面,比如针对不同的用户,这里的 artist_id 的列表将会发送改变。这样修改的结果可以节省 script 的运算,从而提高搜索的速度。
Elasticsearch:定制分词器(analyzer)及相关性的更多相关文章
- ES 09 - 定制Elasticsearch的分词器 (自定义分词策略)
目录 1 索引的分析 1.1 分析器的组成 1.2 倒排索引的核心原理-normalization 2 ES的默认分词器 3 修改分词器 4 定制分词器 4.1 向索引中添加自定义的分词器 4.2 测 ...
- ElasticSearch7.3 学习之定制分词器(Analyzer)
1.默认的分词器 关于分词器,前面的博客已经有介绍了,链接:ElasticSearch7.3 学习之倒排索引揭秘及初识分词器(Analyzer).这里就只介绍默认的分词器standard analyz ...
- es的分词器analyzer
analyzer 分词器使用的两个情形: 1,Index time analysis. 创建或者更新文档时,会对文档进行分词2,Search time analysis. 查询时,对查询语句 ...
- Elasticsearch之分词器的作用
前提 什么是倒排索引? Analyzer(分词器)的作用是把一段文本中的词按一定规则进行切分.对应的是Analyzer类,这是一个抽象类,切分词的具体规则是由子类实现的,所以对于不同的语言,要用不同的 ...
- ElasticSearch7.3 学习之倒排索引揭秘及初识分词器(Analyzer)
一.倒排索引 1. 构建倒排索引 例如说有下面两个句子doc1,doc2 doc1:I really liked my small dogs, and I think my mom also like ...
- Lucene.net(4.8.0)+PanGu分词器问题记录一:分词器Analyzer的构造和内部成员ReuseStategy
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
- Lucene.net(4.8.0) 学习问题记录一:分词器Analyzer的构造和内部成员ReuseStategy
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
- Elasticsearch之分词器的工作流程
前提 什么是倒排索引? Elasticsearch之分词器的作用 Elasticsearch的分词器的一般工作流程: 1.切分关键词 2.去除停用词 3.对于英文单词,把所有字母转为小写(搜索时不区分 ...
- elasticsearch kibana + 分词器安装详细步骤
elasticsearch kibana + 分词器安装详细步骤 一.准备环境 系统:Centos7 JDK安装包:jdk-8u191-linux-x64.tar.gz ES安装包:elasticse ...
- Elasticsearch修改分词器以及自定义分词器
Elasticsearch修改分词器以及自定义分词器 参考博客:https://blog.csdn.net/shuimofengyang/article/details/88973597
随机推荐
- 解读Go分布式链路追踪实现原理
摘要:本文将详细介绍分布式链路的核心概念.架构原理和相关开源标准协议,并分享我们在实现无侵入 Go 采集 Sdk 方面的一些实践. 本文分享自华为云社区<一文详解|Go 分布式链路追踪实现原理& ...
- 4-9 基于Spring JDBC的事务管理(续)
10. 基于Spring JDBC的事务管理(续) 当需要方法是事务性的,可以使用@Transactional注解,此注解可以添加在: 接口 会使得此接口的实现类的所有实现方法都是事务性的 接口中的抽 ...
- 第2章 开始学习C++
说明 看<C++ Primer Plus>时整理的学习笔记,部分内容完全摘抄自<C++ Primer Plus>(第6版)中文版,Stephen Prata 著,张海龙 袁国忠 ...
- HTTP协议之Expect爬坑
前言 今天,在对接一个第三方平台开放接口时遇到一个很棘手的问题,根据接口文档组装好报文,使用HttpClient发起POST请求时一直超时,对方服务器一直不给任何响应. 发起请求的代码如下: usin ...
- SP8496 NOSQ - No Squares Numbers 题解
To SP8496 这道题可以用到前缀和思想,先预处理出所有的结果,然后 \(O(1)\) 查询即可. 注意: 是不能被 \(x^2(x≠1)\) 的数整除的数叫做无平方数. \(d\) 可以为 \( ...
- 6.4.2 用BFS求最短路
前面的篇幅占了太多,再次新开一章,讲述BFS求最短路的问题 注意此时DFS就没有BFS好用了,因为DFS更适合求全部解,而BFS适合求最优解 这边再次提醒拓扑变换的思想在图形辨认中的重要作用,需要找寻 ...
- LCA——树上倍增
首先,什么是LCA? LCA:最近公共祖先 祖先:从当前点到根节点所经过的点,包括他自己,都是这个点的祖先 A和B的公共祖先:同时是A,B两点的祖先的点 A和B的最近公共祖先:深度最大的A和B的公共祖 ...
- 转换流的原理和OutputStreamWriter介绍&代码实现
转换流的原理 OutputStreamWriter介绍&代码实现 package com.yang.Test.ReverseStream; import java.io.FileNotFoun ...
- CF Round #805 (Div. 3) 题解
A 直接模拟即可,注意 \(10^k\) 的情况(罚时!罚时!罚时!). A Code using namespace std; typedef long long ll; typedef pair& ...
- 丽泽普及2022交流赛day15 社论
前言 link 太牛逼了,补完我一定放代码 . orz 越看越牛逼 orz . 时间复杂度都是口胡,不要信 . 以下是目录 目录 目录 前言 A 题面 题解 代码 B 题面 题解 代码 C 题面 题解 ...