python学习-Day9
记忆不清点回顾
- 字符编码只针对文本文件
字符编码相关知识
ASCII码:记录了英文字符与数字的对应关系
1bytes(8bit)来表示英文
"""
A-Z:65-90
a-z:97-122
""" GBK:记录了英文、中文与数字的对应关系
1bytes(8bit)来表示英文
2bytes(16bit)来表示中文(很多时候都是3bytes)
Euc_kr:记录了英文、韩文与数字的对应关系
shift_JIS:记录了英文、日文与数字的对应关系
"""
乱码:'编写'和'翻译'阶段使用的编码表不一致
""" unicode:万国码
所有的字符都是2bytes起步存储
会浪费空间和IO时间
utf8:万国码的转换版本
"""
内存使用的是unicode 硬盘使用的是utf8
"""
今日概要
- 大作业讲解
- 字符编码的实际应用
- 文件操作简介
- 文件的读写模式
- 文件的操作模式
- 文件内置方法
今日内容
大作业讲解
"""
写代码最好写一个功能就测试一个,这样可以缩小排查范围
"""
# 代码实战篇
# 1.添加员工信息
# 提示:编号(不能重复)、姓名、年龄、薪资
# 2.查询特定员工
# 提示:根据编号查找 展示结构用格式化输出美化
# 3.修改员工薪资
# 提示:先根据编号查找之后再修改薪资
# 4.查询所有员工
# 提示:循环一行行展示
# 5.删除特定员工
# 提示根据编号确定
# 答案:
# 1.定义一个存储用户数据的字典
user_data_dict = {}
"""
{'员工编号':{员工数据}, '员工编号':{员工数据}, '员工编号':{员工数据}}
"""
# 2.循环打印系统功能
while True:
print("""
1.添加员工信息
2.修改员工薪资
3.查看指定员工
4.查看所有员工
5.删除员工数据
""")
# 3.获取用户想要执行的功能编号
choice = input('请输入您想要执行的功能编号>>>:').strip()
# 4.判断用户想要执行的功能
if choice == '1':
# pass # TODO:补全语法 但是本身没有任何功能
# 1.先获取员工编号
emp_id = input('请输入新员工的编号>>>:').strip()
# 2.判断员工编号是否已存在 如果存在则提示重复 不存在则正常往下执行
if emp_id in user_data_dict:
print('员工编号已存在 无法添加')
continue # 3.存在 则直接结束本次循环
# 4.正常获取员工的其他数据
emp_name = input('请输入员工的姓名>>>:').strip()
emp_age = input('请输入员工的年龄>>>:').strip()
emp_salary = input('请输入员工的薪资>>>:').strip()
# 5.临时构建一个用户小字典
user_dict = {'emp_id': emp_id, 'emp_name': emp_name, 'emp_age': emp_age, 'emp_salary': emp_salary}
# 6.将数据添加到大字典中
user_data_dict[emp_id] = user_dict # 键不存在则新增键值对
# 7.打印提示信息
print(f'员工{emp_name}添加成功')
elif choice == '2':
# 1.先获取想要修改薪资的员工编号
target_id = input('请输入您想要修改的员工编号>>>:').strip()
# 2.判断当前编号是否存在
if target_id not in user_data_dict:
print('员工编号不存在 无法修改')
continue # 3.存在 则直接结束本次循环
# 4.获取对应员工的字典
user_dict = user_data_dict.get(target_id)
# 5.获取新的薪资
new_salary = input('请输入该员工新的薪资待遇>>>:').strip()
# 6.修改员工字典数据
user_dict['emp_salary'] = new_salary
# 7.修改大字典数据
user_data_dict[target_id] = user_dict
# 8.提示信息
print(f'编号为{target_id}的员工薪资成功修改为{new_salary}')
elif choice == '3':
# 1.获取员工编号
target_id = input('请输入您想要查看的员工编号>>>:').strip()
# 2.判断当前编号是否存在
if target_id not in user_data_dict:
print('员工编号不存在 无法查看')
continue # 3.存在 则直接结束本次循环
# 4.直接获取对应的员工数据字典
user_dict = user_data_dict.get(target_id)
# 5.打印员工数据
print("""
------------emp info------------
员工编号:%s
员工姓名:%s
员工年龄:%s
员工薪资:%s
---------------end--------------
""" % tuple(user_dict.values())) # %(1,2,3,4) 简便写法
elif choice == '4':
for user_dict in user_data_dict.values(): # {} {} {}
print("""
------------emp info------------
员工编号:%s
员工姓名:%s
员工年龄:%s
员工薪资:%s
---------------end--------------
""" % tuple(user_dict.values())) # %(1,2,3,4) 简便写法
# print("""
# ------------emp info------------
# 员工编号:%s
# 员工姓名:%s
# 员工年龄:%s
# 员工薪资:%s
# --------------end---------------
# """ % (user_dict.get('emp_id'), user_dict.get('emp_name'), user_dict.get('emp_age'),
# user_dict.get('emp_salary'))) # %(1,2,3,4)
elif choice == '5':
# 1.获取想要删除的员工编号
delete_id = input('请输入您想要删除的员工编号>>>:').strip()
# 2.判断当前编号是否存在
if delete_id not in user_data_dict:
print('员工编号不存在 无法删除')
continue # 3.存在 则直接结束本次循环
# 3.根据字典的key删除数据
res = user_data_dict.pop(delete_id)
# 4.提示
print(f'员工信息删除完毕',res)
else:
print('请输入正确的功能编号')

字符编码实际应用
编码与解码
编码
将人类能够读懂的字符编码成计算机能够直接读懂的字符
s1 = '事已至此 何不一搏'
# 编码 encode
print(s1.encode('gbk'))
解码
将计算机能够直接读懂的字符解码成人类能够读懂的字符
# 解码 decode
res = b'\xca\xc2\xd2\xd1\xd6\xc1\xb4\xcb \xba\xce\xb2\xbb\xd2\xbb\xb2\xab'
print(res.decode('gbk'))
"""
字符串前面如果加了字母b 表示该数据类型为 bytes类型
bytes类型可以看成是二进制
"""
"""
基于网络传输数据 数据都必须是二进制格式
所以肯定涉及到编码与解码
"""
# 3.python解释器层面
python2解释器默认的编码是ASCII码
1.文件头:必须写在文件的最上方 告诉解释器使用指定的编码
# coding:utf8
# -*- coding:utf8 -*- 美化写法
2.字符前缀:在使用python2解释器的环境下定义字符串习惯在前面加u
name = u'你好啊'
python3解释器默认的编码是utf8
如何解决乱码的问题
数据当初以什么编码编写的 就以什么编码解码即可
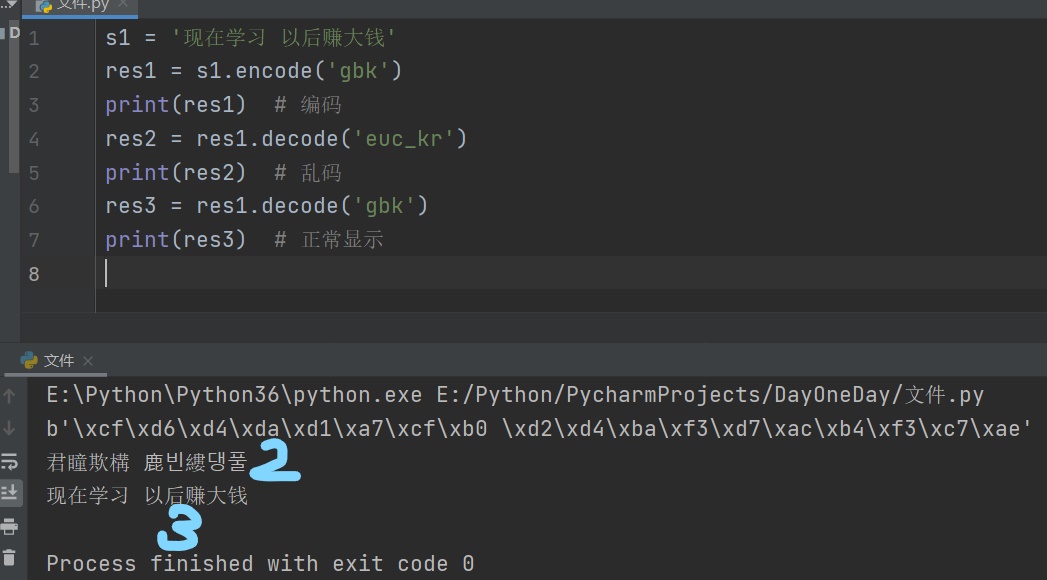
res1 = s1.encode('gbk')
print(res1) # 编码
res2 = res1.decode('euc_kr')
print(res2) # 乱码
res3 = res1.decode('gbk')
print(res3) # 正常显示
文件操作简介
什么是文件
操作系统暴露给用户可以直接操作硬盘的快捷方式(接口)
代码操作文件
代码操作文件的流程
1.打开文件、创建文件
f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r
2.编辑文件内容
data=f.read()
data=f.writ()
3.保存文件内容
4.关闭文件
f.close()
基本语法结构
结构1(了解即可):
f1 = open()
f1.close()
结构2(推荐使用):
with open() as f:
pass
使用关键字打开文件
'''以后写路径为了防止特殊符号 直接加r'''
open(r'a.txt') # 相对路径
open(r'D:\py1\day09\a.txt') # 绝对路径
res = open(r'a.txt', 'r', encoding='utf8')
"""
open(文件的路径,文件的操作模式,文件的编码)
1.文件的路径是必写的
2.文件的操作模式、文件的编码有时候不用写
"""
print(res.read()) # 读取文件内容
res.close() # 关闭文件
"""上述操作open完,最后都需要执行close() 但经常被遗忘"""
with上下文管理
with open(r'a.txt', 'r', encoding='utf8') as f: # f = open()
data = f.read()
print(data)
文件的读写模式
r read 只读模式:只能读不能写
w write 只写模式:只能写不能读
a append 只追加模式:在文件末尾添加内容
r 模式
with open(r'b.txt', 'r', encoding='utf8') as f1:
# pass (推荐)补全语法结构 本身没有任何功能
# ... (不推荐)补全语法结构 本身没有任何功能
pass
# 路径存在:正常打开文件并等待内容读取
with open(r'a.txt', 'r', encoding='utf8') as f1:
print(f1.read()) # 一次性读取文件内所有的内容
f1.write('学会python!!!') # 报错
"""
readable 具备读的能力
writable 具备写的能力
"""
w 模式
# 路径不存在:自动创建文件
with open(r'b.txt', 'w', encoding='utf8') as f1:
# pass (推荐)补全语法结构 本身没有任何功能
# ... (不推荐)补全语法结构 本身没有任何功能
pass
# 路径存在:先清空文件内容 之后再写入数据
with open(r'a.txt', 'w', encoding='utf8') as f1:
f1.write('你们是我见过的最优秀一批学生1\n') # 写入文件内容
f1.write('你们是我见过的最优秀一批学生2\r') # 写入文件内容
f1.write('你们是我见过的最优秀一批学生3\n') # 写入文件内容
print(f1.read())
换行
"""
换行在最早的时候:\r\n
为了节省空间支持一个字符 根据操作系统的不同可能有所区别
\n 、 \r
"""
a 模式
# 路径不存在:自动创建文件
with open(r'c.txt', 'a', encoding='utf8') as f1:
pass
# 路径存在:不会清空文件内容 而是在文件末尾等待新内容的添加
with open(r'a.txt', 'a', encoding='utf8') as f1:
f1.write('她怎么还不向我表白')

文件的操作模式
t模式
文本模式-->是默认的模式
r rt
w wt
a at
1.该模式只能操作文本文件
2.该模式必须要指定encoding参数
3.该模式读写都是以字符串为最小单位
b模式
二进制模式-->可以操作任意类型的文件
rb 不能省略b
wb 不能省略b
ab 不能省略b
1.该模式可以操作任意类型的文件
2.该模式不需要指定encoding参数
3.该模式读写都是以bytes类型为最小单位
文件内置方法
read() # 一次性读取文件内容
1.执行完之后光标在文件末尾 继续读取没有内容
2.当文件内容特别大的时候 容易造成内存溢出(满了)
readline() # 一次只读一行内容
readlines() # 结果是一个列表 里面的各个元素是文件的一行行内容
readable() # 判断当前文件是否可读
支持for循环 # 一行行读取文件内容(推荐使用) 内存中同一时刻只会有一行内容
write() # 写入文件内容(字符串或者bytes类型)
writelines() # 可以将列表中多个元素写入文件
writable() # 判断文件是否可写
flush() # 相当于主动按了ctrl+s(保存)

没啦~
python学习-Day9的更多相关文章
- python学习day9
目录 一.队列 二.生产者消费者模型 三.协程 四.select\poll\epoll 五.paramiko 六.mysql API调用 一.队列(queue) 队列分以下三种: class queu ...
- Python学习-day9 线程
这节内容主要是关于线程的学习 首先要了解的什么是进程,什么是线程 进程与线程 什么是进程(process)? 程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称 ...
- python学习Day9 内存管理
复习 :文件处理 1. 操作文件的三步骤:-- 打开文件:此时该文件在硬盘的空间被操作系统持有 | 文件对象被应用程序持用 -- 操作文件:读写操作 -- 释放文件:释放操作系统对文件在硬盘间的持有 ...
- python学习day9 字符编码和文件处理
1.字符编码 x='上' #unicode的二进制--------->编码-------->gbk格式的二进制 res=x.encode('gbk') #bytes 字节类型 print( ...
- Python学习day9 函数Ⅰ(基础)
函数Ⅰ(基础) 三目运算 基本结构 v = 前面 if 条件 else 后面 #条件为真v=前面,条件为假v=后面.#等同于if 条件: v = '前面'else: v = '后面' ...
- 【目录】Python学习笔记
目录:Python学习笔记 目标:坚持每天学习,每周一篇博文 1. Python学习笔记 - day1 - 概述及安装 2.Python学习笔记 - day2 - PyCharm的基本使用 3.Pyt ...
- Python学习--04条件控制与循环结构
Python学习--04条件控制与循环结构 条件控制 在Python程序中,用if语句实现条件控制. 语法格式: if <条件判断1>: <执行1> elif <条件判断 ...
- Python学习--01入门
Python学习--01入门 Python是一种解释型.面向对象.动态数据类型的高级程序设计语言.和PHP一样,它是后端开发语言. 如果有C语言.PHP语言.JAVA语言等其中一种语言的基础,学习Py ...
- Python 学习小结
python 学习小结 python 简明教程 1.python 文件 #!/etc/bin/python #coding=utf-8 2.main()函数 if __name__ == '__mai ...
随机推荐
- Windows&Linux文件传输方式总结
在渗透过程中,通常会需要向目标主机传送一些文件,来达到权限提升.权限维持等目的,本篇文章主要介绍一些windows和Linux下常用的文件传输方式. Windows 利用FTP协议上传 在本地或者VP ...
- leetcode-3无重复字符的最长子串
题目原题: 给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度. 示例 1: 输入: s = "abcabcbb" 输出: 3 解释: 因为无重复字符的最长子串是 ...
- RPC框架 和 fegin原理
打个比方,你有一些想法,你把他们变成文字写在信纸上,这是http 你把这个信纸塞进信封,这个信封是tcp 你把这个信封写上地址交给邮局,这地址是IP 一层套一层 会话层,表示层,应用层归到一起 就是 ...
- http和https到底区别在哪
一.Http和Https的基本概念 Http:超文本传输协议(Http,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议.设计Http最初的目的是为了提供一 ...
- resin服务之一---安装及部署
参考网站: http://caucho.com/ http://www.oschina.net/p/resin http://caucho.com/resin-4.0/admin/starting-r ...
- 如何解决Visual Studio 2017 运行后控制台窗口一闪就消失了
出现这种情况的原因 安装使用Visual Studio 2017 后,用Ctrl+F5运行程序,结果控制台窗口一闪就没了,也没有出现"press any key to continue-&q ...
- js 简易模块加载器 示例分析
前端模块化 关注前端技术发展的各位亲们,肯定对模块化开发这个名词不陌生.随着前端工程越来越复杂,代码越来越多,模块化成了必不可免的趋势. 各种标准 由于javascript本身并没有制定相关标准(当然 ...
- 深入理解ES6之《用模块封装代码》
什么是模块 模块是自动运行在严格模式下并且没有办法退出运行的Javascript代码 在模块的顶部this的值是undefined 其模块不支持html风格的代码注释除非用default关键字,否则不 ...
- 从kill-chain的角度检测APT攻击
前言 最近一直在考虑如何结合kill chain检测APT攻击.出发点是因为尽管APT是一种特殊.高级攻击手段,但是它还是会具有攻击的common feature,只要可以把握住共同特征,就能进行检测 ...
- python-for循环跳过第一行
代码: for i in data[1:]: 即可跳过第一行