终极套娃 2.0|云原生 PaaS 平台的可观测性实践分享
某个周一上午,小涛像往常一样泡上一杯热咖啡 ️,准备打开项目协同开始新一天的工作,突然隔壁的小文喊道:“快看,用户支持群里炸锅了 …”
用户 A:“Git 服务有点问题,代码提交失败了!”
用户 B:“帮忙看一下,执行流水线报错……”
用户 C:“我们的系统今天要上线,现在部署页面都打不开了,都要急坏了!”
用户 D:……
小涛只得先放下手中的咖啡,屏幕切换到堡垒机,登录到服务器上一套行云流水的操作,“哦,原来是上周末上线的代码漏了一个参数验证造成 panic 了”,小涛指着屏幕上一段容器的日志对小文说到。
十分钟后,小文使用修复后的安装包更新了线上的系统,用户的问题也得到了解决。
虽然故障修复了,但是小涛也陷入了沉思,“为什么我们没有在用户之前感知到系统的异常呢?现在排查问题还需要登录到堡垒机上看容器的日志,有没有更快捷的方式和更短的时间里排查到线上故障发生的原因?”
这时,坐在对面的小 L 说道:“我们都在给用户讲帮助他们实现系统的可观测性,是时候 Erda 也需要被观测了。”
小涛:“那要怎么做呢…?”且听我们娓娓道来~
通常情况下,我们会搭建独立的分布式追踪、监控和日志系统来协助开发团队解决微服务系统中的诊断和观测问题。但同时 Erda 本身也提供了功能齐全的服务观测能力,而且在社区也有一些追踪系统(比如 Apache SkyWalking 和 Jaeger)都提供了自身的可观测性,给我们提供了使用平台能力观测自身的另一种思路。
最终,我们选择了在 Erda 平台上实现 Erda 自身的可观测,使用该方案的考虑如下:
平台已经提供了服务观测能力,再引入外部平台造成重复建设,对平台使用的资源成本也有增加
开发团队日常使用自己的平台来排查故障和性能问题,吃自己的狗粮对产品的提升也有一定的帮助
对于可观测性系统的核心组件比如 Kafka 和 数据计算组件,我们通过 SRE 团队的巡检工具来旁路覆盖,并在出问题时触发报警消息
Erda 微服务观测平台提供了 APM、用户体验监控、链路追踪、日志分析等不同视角的观测和诊断工具,本着物尽其用的原则,我们也把 Erda 产生的不同观测数据分别进行了处理,具体的实现细节且继续往下看。
OpenTelemetry 数据接入
在之前的文章里我们介绍了如何在 Erda 上接入 Jaeger Trace ,首先我们想到的也是使用 Jaeger Go SDK 作为链路追踪的实现,但 Jaeger 作为主要实现的 OpenTracing 已经停止维护,因此我们把目光放到了新一代的可观测性标准 OpenTelemetry 上面。
OpenTelemetry 是 CNCF 的一个可观测性项目,由 OpenTracing 和 OpenCensus 合并而来,旨在提供可观测性领域的标准化方案,解决观测数据的数据模型、采集、处理、导出等的标准化问题,提供与三方 vendor 无关的服务。
如下图所示,在 Erda 可观测性平台接入 OpenTelemetry 的 Trace 数据,我们需求在 gateway 组件实现 otlp 协议的 receiver,并且在数据消费端实现一个新的 span analysis组件把 otlp 的数据分析为 Erda APM 的可观测性数据模型。
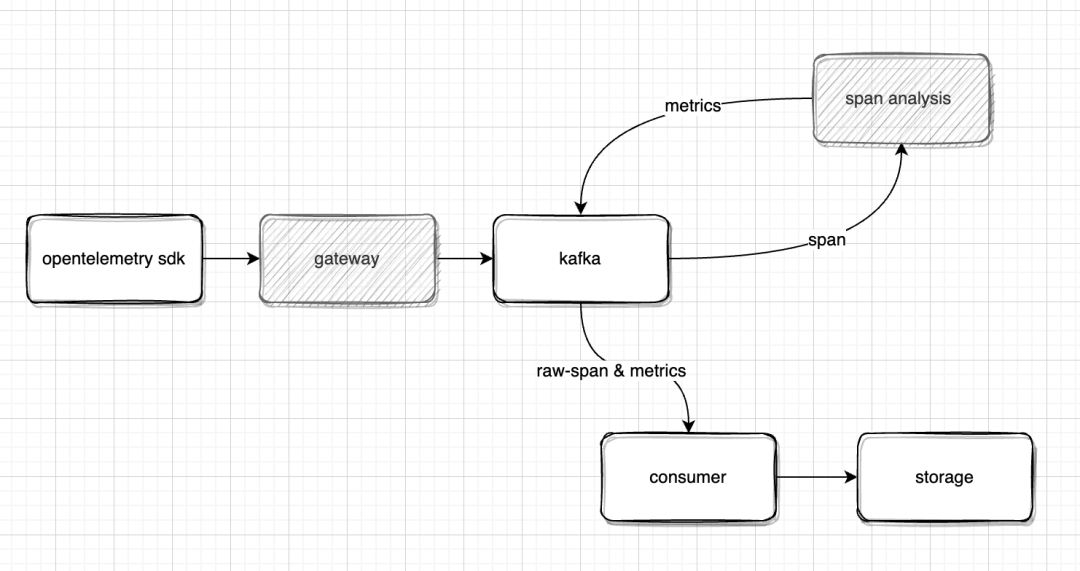
OpenTelemetry 数据接入和处理流程
其中,gateway 组件使用 Golang 轻量级实现,核心的逻辑是解析 otlp 的 proto 数据,并且添加对租户数据的鉴权和限流。
关键代码参考 receivers/opentelemetry
span_analysis 组件基于 Flink 实现,通过 DynamicGap 时间窗口,把 opentelemetry 的 span 数据聚合分析后产生如下的 Metrics:
service_node 描述服务的节点和实例
service_call_* 描述服务和接口的调用指标,包括 HTTP、RPC、DB 和 Cache
service_call_*_error 描述服务的异常调用,包括 HTTP、RPC、DB 和 Cache
service_relation 描述服务之间的调用关系
同时 span_analysis 也会把 otlp 的 span 转换为 Erda 的 span 标准模型,将上面的 metrics 和转换后的 span 数据流转到 kafka ,再被 Erda 可观测性平台的现有数据消费组件消费和存储。
关键代码参考 analyzer/tracing
通过上面的方式,我们就完成了 Erda 对 OpenTelemetry Trace 数据的接入和处理。
接下来,我们再来看一下 Erda 自身的服务是如何对接 OpenTelemetry。
Golang 无侵入的调用拦截
Erda 作为一款云原生 PaaS 平台,也理所当然的使用云原生领域最流行的 Golang 进行开发实现,但在 Erda 早期的时候,我们并没有在任何平台的逻辑中预置追踪的埋点。所以即使在 OpenTelemetry 提供了开箱即用的 Go SDK 的情况下,我们只在核心逻辑中进行手动的 Span 接入都是一个需要投入巨大成本的工作。
在我之前的 Java 和 .NET Core 项目经验中,都会使用 AOP 的方式来实现性能和调用链路埋点这类非业务相关的逻辑。虽然 Golang 语言并没有提供类似 Java Agent 的机制允许我们在程序运行中修改代码逻辑,但我们仍从 monkey 项目中受到了启发,并在对 monkey 、pinpoint-apm/go-aop-agent 和 gohook 进行充分的对比和测试后,我们选择了使用 gohook 作为 Erda 的 AOP 实现思路,最终在 erda-infra 中提供了自动追踪埋点的实现。
关于 monkey 的原理可以参考 monkey-patching-in-go
以 http-server 的自动追踪为例,我们的核心实现如下:
//go:linkname serverHandler net/http.serverHandler
type serverHandler struct {
srv *http.Server
}
//go:linkname serveHTTP net/http.serverHandler.ServeHTTP
//go:noinline
func serveHTTP(s *serverHandler, rw http.ResponseWriter, req *http.Request)
//go:noinline
func originalServeHTTP(s *serverHandler, rw http.ResponseWriter, req *http.Request) {}
var tracedServerHandler = otelhttp.NewHandler(http.HandlerFunc(func(rw http.ResponseWriter, r *http.Request) {
injectcontext.SetContext(r.Context())
defer injectcontext.ClearContext()
s := getServerHandler(r.Context())
originalServeHTTP(s, rw, r)
}), "", otelhttp.WithSpanNameFormatter(func(operation string, r *http.Request) string {
u := *r.URL
u.RawQuery = ""
u.ForceQuery = false
return r.Method + " " + u.String()
}))
type _serverHandlerKey int8
const serverHandlerKey _serverHandlerKey = 0
func withServerHandler(ctx context.Context, s *serverHandler) context.Context {
return context.WithValue(ctx, serverHandlerKey, s)
}
func getServerHandler(ctx context.Context) *serverHandler {
return ctx.Value(serverHandlerKey).(*serverHandler)
}
//go:noinline
func wrappedHTTPHandler(s *serverHandler, rw http.ResponseWriter, req *http.Request) {
req = req.WithContext(withServerHandler(req.Context(), s))
tracedServerHandler.ServeHTTP(rw, req)
}
func init() {
hook.Hook(serveHTTP, wrappedHTTPHandler, originalServeHTTP)
}
在解决了 Golang 的自动埋点后,我们还遇到的一个棘手问题是在异步的场景中,因为上下文的切换导致 TraceContext 无法传递到下一个 Goroutine 中。同样在参考了 Java 的 Future 和 C# 的 Task 两种异步编程模型后,我们也实现了自动传递 Trace 上下文的异步 API:
future1 := parallel.Go(ctx, func(ctx context.Context) (interface{}, error) {
req, err := http.NewRequestWithContext(ctx, http.MethodGet, "http://www.baidu.com/api_1", nil)
if err != nil {
return nil, err
}
resp, err := http.DefaultClient.Do(req)
if err != nil {
return nil, err
}
defer resp.Body.Close()
byts, err := ioutil.ReadAll(resp.Body)
if err != nil {
return nil, err
}
return string(byts), nil
})
future2 := parallel.Go(ctx, func(ctx context.Context) (interface{}, error) {
req, err := http.NewRequestWithContext(ctx, http.MethodGet, "http://www.baidu.com/api_2", nil)
if err != nil {
return nil, err
}
resp, err := http.DefaultClient.Do(req)
if err != nil {
return nil, err
}
defer resp.Body.Close()
byts, err := ioutil.ReadAll(resp.Body)
if err != nil {
return nil, err
}
return string(byts), nil
}, parallel.WithTimeout(10*time.Second))
body1, err := future1.Get()
if err != nil {
return nil, err
}
body2, err := future2.Get()
if err != nil {
return nil, err
}
return &pb.HelloResponse{
Success: true,
Data: body1.(string) + body2.(string),
}, nil
写在最后
在使用 OpenTelemetry 把 Erda 平台调用产生的 Trace 数据接入到 Erda 自身的 APM 中后,我们首先能得到的收益是可以直观的得到 Erda 的运行时拓扑:
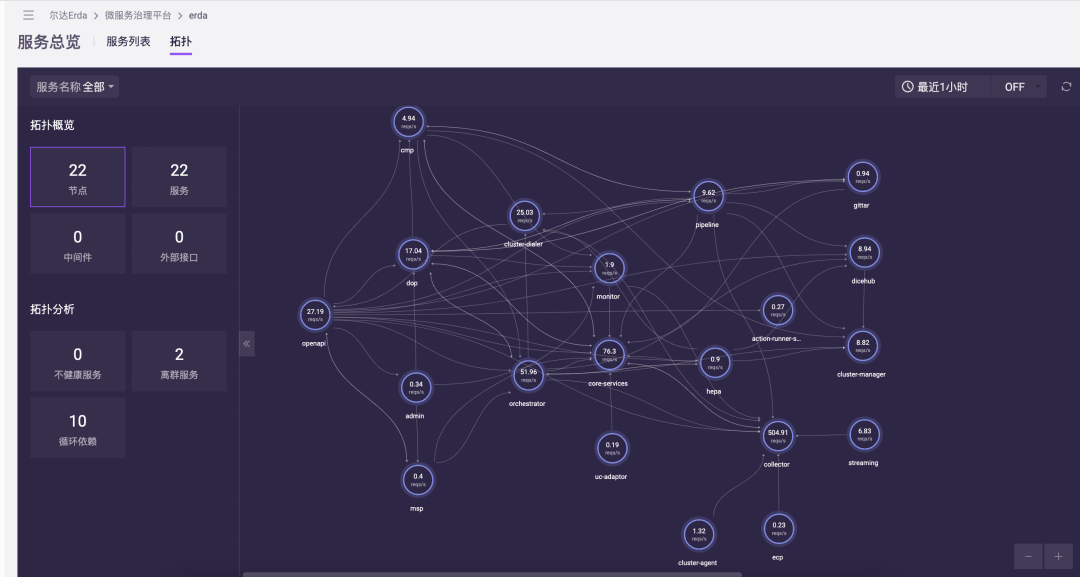
Erda 运行时拓扑
通过该拓扑,我们能够看到 Erda 自身在架构设计上存在的诸多问题,比如服务的循环依赖、和存在离群服务等。根据自身的观测数据,我们也可以在每个版本迭代中逐步去优化 Erda 的调用架构。
对于我们隔壁的 SRE 团队,也可以根据 Erda APM 自动分析的调用异常产生的告警消息,能够第一时间知道平台的异常状态:

最后,对于我们的开发团队,基于观测数据,能够很容易地洞察到平台的慢调用,以及根据 Trace 分析故障和性能瓶颈:
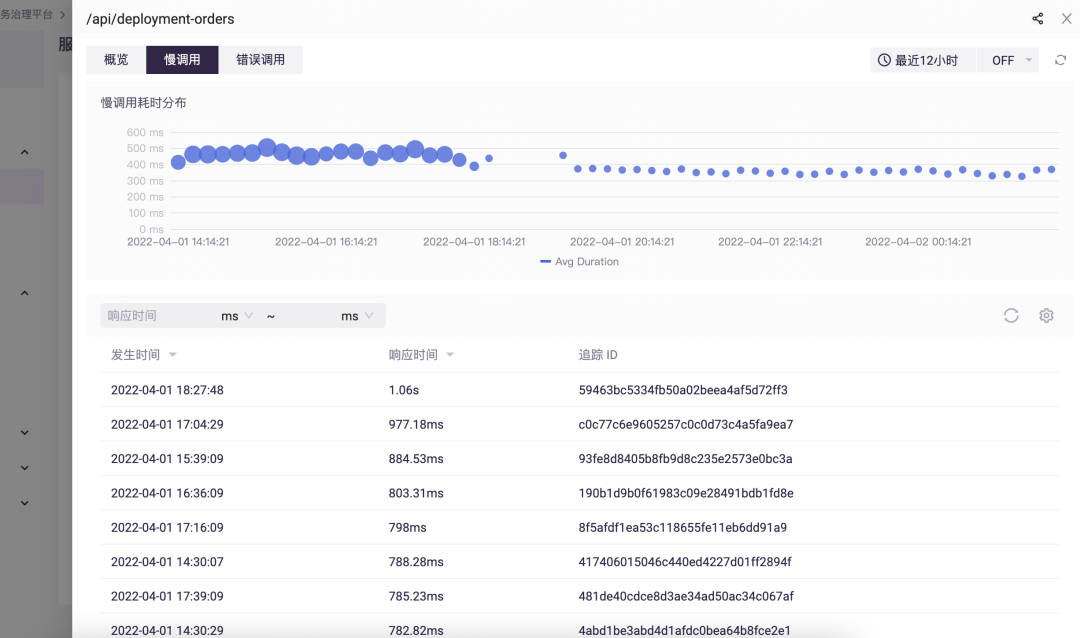
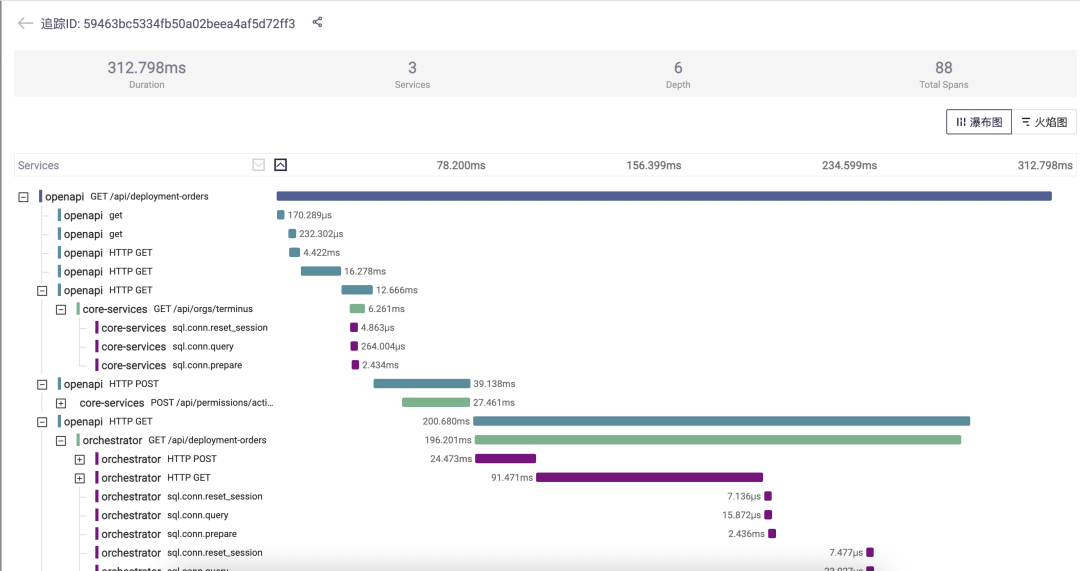
小 L:“除了上面这些,我们还可以把平台的日志、页面访问速度等都使用类似的思路接入到 Erda 的可观测性平台。”
小涛恍然大悟道:“我知道了,原来套娃观测还可以这么玩!以后就可以放心地喝着咖啡做自己的工作了。”
我们致力于决社区用户在实际生产环境中反馈的问题和需求,
如果您有任何疑问或建议,
欢迎关注【尔达Erda】公众号给我们留言,
加入 Erda 用户群参与交流或在 Github 上与我们讨论!
终极套娃 2.0|云原生 PaaS 平台的可观测性实践分享的更多相关文章
- 云原生PaaS平台通过插件整合SkyWalking,实现APM即插即用
一. 简介 SkyWalking 是一个开源可观察性平台,用于收集.分析.聚合和可视化来自服务和云原生基础设施的数据.支持分布式追踪.性能指标分析.应用和服务依赖分析等:它是一种现代 APM,专为云原 ...
- 终极指南:企业级云原生 PaaS 平台日志分析架构全面解析
早些时候 Erda Show 针对微服务监控.日志等内容做了专场分享,很多同学听完后意犹未尽,想了解更多关于日志分析的内容.Erda 团队做日志分析也有一段时间了,所以这次打算和大家详细分享一下我们在 ...
- 重大升级!灵雀云发布全栈云原生开放平台ACP 3.0
云原生技术的发展正在改变全球软件业的格局,随着云原生技术生态体系的日趋完善,灵雀云的云原生平台也进入了成熟阶段.近日,灵雀云发布重大产品升级,推出全栈云原生开放平台ACP 3.0.作为面向企业级用户的 ...
- 公有云上构建云原生 AI 平台的探索与实践 - GOTC 技术论坛分享回顾
7 月 9 日,GOTC 2021 全球开源技术峰会上海站与 WAIC 世界人工智能大会共同举办,峰会聚焦 AI 与云原生两大以开源驱动的前沿技术领域,邀请国家级研究机构与顶级互联网公司的一线技术专家 ...
- 基于 Golang 构建高可扩展的云原生 PaaS(附 PPT 下载)
作者|刘浩杨 来源|尔达 Erda 公众号 本文整理自刘浩杨在 GopherChina 2021 北京站主会场的演讲,微信添加:Erda202106,联系小助手即可获取讲师 PPT. 前言 当今时 ...
- 新书《OpenShift云原生架构:原理与实践》第一章第三节:企业级PaaS平台OpenShift
近十年来,信息技术领域在经历一场技术大变革,这场变革正将我们由传统IT架构及其所支撑的臃肿应用系统时代,迁移至云原生架构及其所支撑的敏捷应用系统时代.在这场变革中,新技术的出现.更新和淘汰之迅速,以及 ...
- 搜狐云景paas平台实践之路
前言: 搜狐云景作为搜狐的paas平台,在2014年5月22日的云计算大会上正式发布了公测.初测,注册用户必须先申请邀请码参与公测会赠送用户100元电子券,经过实名认证之后会再赠送100电子券,目测可 ...
- 浅谈搜狐云景PAAS平台
前言: 搜狐云景作为搜狐的paas平台,在2014年5月22日的云计算大会上正式公布了公測.初測,注冊用户必须先申请邀请码參与公測会赠送用户100元电子券,经过实名认证之后会再赠送100电子券.目測能 ...
- 开放融合 | “引擎级”深度对接!POLARDB与SuperMap联合构建首个云原生时空平台
阿里巴巴新一代自研云数据库POLARDB与超图软件SuperMap GIS实现 “引擎级”深度对接,构建了自治.弹性.高可用的云原生时空数据管理平台联合解决方案,推出了业界首个“云原生数据库+云原生G ...
随机推荐
- 关于MVC WebAPI 中加入任务调度功能的问题 (MVC WebAPI 任务调度)
在MVC WebAPI中加入任务调度功能.即在MVC WebAPI启动时,启用任务调度程序. 但是这里有一个问题点,就是部署好IIS站点后,发现任务调度并没有启用.原因为何? 原因是部署好IIS站点后 ...
- mycat的基本介绍 看这一篇就够了
1.前置知识 1.分布式系统 分布式系统是指其组件分布在网络上,组件之间通过传递消息进行通信和动作协调的系统.它的核心理念是让多台服务器协同工作,完成单台服务器无法处理的任务,尤其是高并发或者大数 ...
- CodeTON Round 1 (Div. 1 + Div. 2, Rated, Prizes!) A ~ D
A. 给定一个序列,对于任意1<=k<=n 都满足|ai−ak|+|ak−aj|=|ai−aj|, 找满足条件的i和j并输出 思路: 观察样例,发现输出的是最大值和最小值,那么猜答案是最大 ...
- CF17E Palisection(manacher/回文树)
CF17E Palisection(manacher/回文树) Luogu 题解时间 直接正难则反改成求不相交的对数. manacher求出半径之后就可以差分搞出以某个位置为开头/结尾的回文串个数. ...
- webapi_2 今天全是大经典案例
今天的案例又大又经典 我想想怎么搞呢因为要用到外联样式之类的了 写入内联也太大了 1. 先来一个单独小页面的吧 一个仿淘宝右侧侧边栏的案例 不多说都在注释里了 <!DOCTYPE html> ...
- Java 将CSV转为Excel
CSV(Comma Separated Values)文件是一种纯文本文件,包含用逗号分隔的数据,常用于将数据从一个应用程序导入或导出到另一个应用程序.通过将CSV文件转为EXCEL,可执行更多关于数 ...
- java的泛型hei
泛型是一种未知的数据类型,当我们不知道使用什么数据类型的时候就可以使用泛型 泛型也可以看出是一个变量,用来接受数据类型 E e :Element 元素 T t: Type 类型 /* Collecti ...
- spring DAO 有什么用?
Spring DAO 使得 JDBC,Hibernate 或 JDO 这样的数据访问技术更容易以一 种统一的方式工作.这使得用户容易在持久性技术之间切换.它还允许您在编写 代码时,无需考虑捕获每种技术 ...
- 全方位讲解 Nebula Graph 索引原理和使用
本文首发于 Nebula Graph Community 公众号 index not found?找不到索引?为什么我要创建 Nebula Graph 索引?什么时候要用到 Nebula Graph ...
- 小技巧之“将Text文件中的数据导入到Excel中,这里空格为分割符为例”
1.使用场景 将数据以文本导出后,想录入到Excel中,的简便方案, 起因:对于Excel的导出,Text导出明显会更方便些 2.将Text文件中的数据导入到Excel中,这里空格为分割符为例的步骤 ...