零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程。
零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程。
1.通用文本分类技术UTC介绍
本项目提供基于通用文本分类 UTC(Universal Text Classification) 模型微调的文本分类端到端应用方案,打通数据标注-模型训练-模型调优-预测部署全流程,可快速实现文本分类产品落地。
文本分类是一种重要的自然语言处理任务,它可以帮助我们将大量的文本数据进行有效的分类和归纳。实际上,在日常生活中,我们也经常会用到文本分类技术。例如,我们可以使用文本分类来对新闻报道进行分类,对电子邮件进行分类,对社交媒体上的评论进行情感分析等等。但是,文本分类也面临着许多挑战。其中最重要的挑战之一是数据稀缺。由于文本数据往往非常庞大,因此获取足够的训练数据可能非常困难。此外,不同的文本分类任务也可能面临着领域多变和任务多样等挑战。为了应对这些挑战,PaddleNLP推出了一项零样本文本分类应用UTC。该应用通过统一语义匹配方式USM(Unified Semantic Matching)来将标签和文本的语义匹配能力进行统一建模。这种方法可以帮助我们更好地理解文本数据,并从中提取出有用的特征信息。
UTC具有低资源迁移能力,可以支持通用分类、评论情感分析、语义相似度计算、蕴含推理、多项式阅读理解等多种“泛分类”任务。这使得开发者可以更加轻松高效地实现多任务文本分类数据标注、训练、调优和上线,从而降低文本分类技术门槛。
总之,文本分类是一项重要的自然语言处理任务,它可以帮助我们更好地理解和归纳文本数据。尽管它面临着许多挑战,但是通过使用PaddleNLP的零样本文本分类应用UTC,开发者们可以简单高效实现多任务文本分类数据标注、训练、调优、上线,降低文本分类落地技术门槛。

1.1 分类落地面临难度
分类任务看似简单,然而在产业级文本分类落地实践中,面临着诸多挑战:
任务多样:单标签、多标签、层次标签、大规模标签等不同的文本分类任务,需要开发不同的分类模型,模型架构往往特化于具体任务,难以使用统一形式建模;
数据稀缺:部分领域数据稀缺,难以获取,且领域专业性使得数据标注门槛高;
标签迁移:不同领域的标签多样,并且迁移难度大,尤其不同领域间的标签知识很难迁移。
1.2 UTC亮点
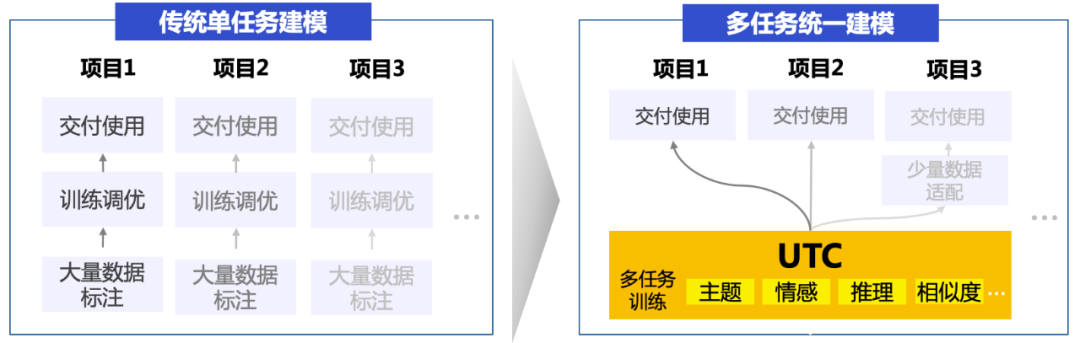
1.2.1 多任务统一建模
在传统技术方案中,针对不同的分类任务需要构建多个分类模型,模型需单独训练且数据和知识不共享。而在UTC方案下,单个模型能解决所有分类需求,包括但不限于单标签分类、多标签分类、层次标签分类、大规模事件标签检测、蕴含推理、语义相似度计算等,降低了开发成本和机器成本。
1.2.2 零样本分类和小样本迁移能力强
UTC通过大规模多任务预训练后,可以适配不同的行业领域,不同的分类标签,仅标注了几条样本,分类效果就取得大幅提升,大大降低标注门槛和成本。
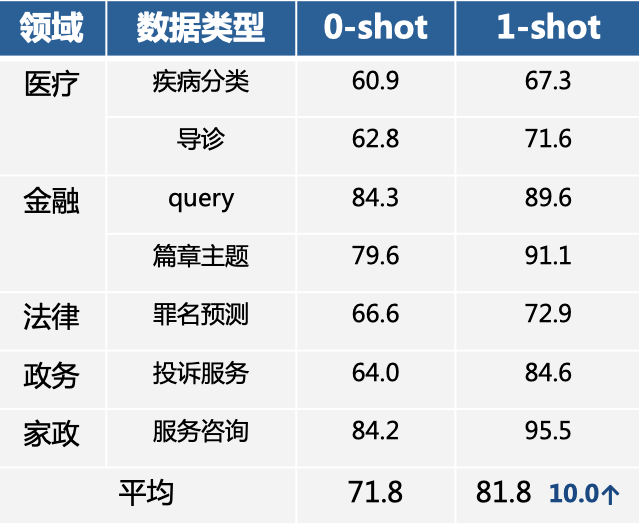
在医疗、金融、法律等领域中,无需训练数据的零样本情况下UTC效果平均可达到70%+(如下表所示),标注少样本也可带来显著的效果提升:每个标签仅仅标注1条样本后,平均提升了10个点!也就是说,即使在某些场景下表现欠佳,人工标几个样本,丢给模型后就会有大幅的效果提升。
1.3 UTC技术思路
UTC基于百度最新提出的统一语义匹配框架USM(Unified Semantic Matching)[1],将分类任务统一建模为标签与文本之间的匹配任务,对不同标签的分类任务进行统一建模。具体地说:
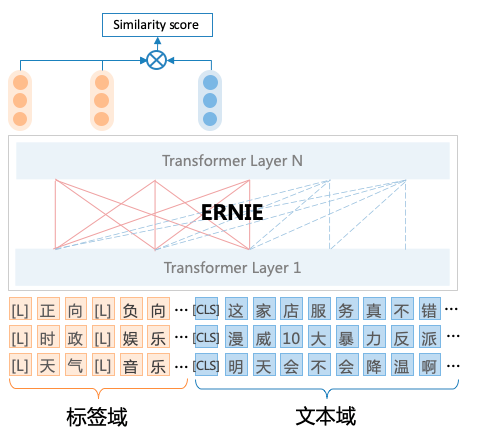
- 为了实现任务架构统一,UTC设计了标签与文本之间的词对连接操作(Label–>CLS-Token Linking),这使得模型能够适应不同领域和任务的标签信息,并按需求进行分类,从而实现了开放域场景下的通用文本分类。
例如,对于事件检测任务,可将一系列事件标签拼接为[L]上映[L]夺冠[L]下架 ,然后与原文本一起作为整体输入到UTC中,UTC将不同标签标识符[L]与[CLS]进行匹配,可对不同标签类型的分类任务统一建模,直接上图:
- 为了实现通用能力共享,让不同领域间的标签知识跨域迁移,UTC构建了统一的异质监督学习方法进行多任务预训练,使不同领域任务具备良好的零/少样本迁移性能。统一的异质监督学习方法主要包括三种不同的监督信号:
- 直接监督:分类任务直接相关的数据集,如情感分类、新闻分类、意图识别等。
- 间接监督:分类任务间接相关的数据集,如选项式阅读理解、问题-文章匹配等。
- 远程监督:标签知识库或层级标题与文本对齐后弱标注数据。
更多内容参考论文见文末链接 or fork一下项目论文已上传
2.文本分类任务Label Studio教程
2.1 Label Studio安装
以下标注示例用到的环境配置:
- Python 3.8+
- label-studio == 1.7.2
在终端(terminal)使用pip安装label-studio:
pip install label-studio==1.7.2
安装完成后,运行以下命令行:
label-studio start
在浏览器打开http://localhost:8080/,输入用户名和密码登录,开始使用label-studio进行标注。
2.2 文本分类任务标注
2.2.1 项目创建
点击创建(Create)开始创建一个新的项目,填写项目名称、描述,然后在Labeling Setup中选择Text Classification。
- 填写项目名称、描述
- 数据上传,从本地上传txt格式文件,选择
List of tasks,然后选择导入本项目
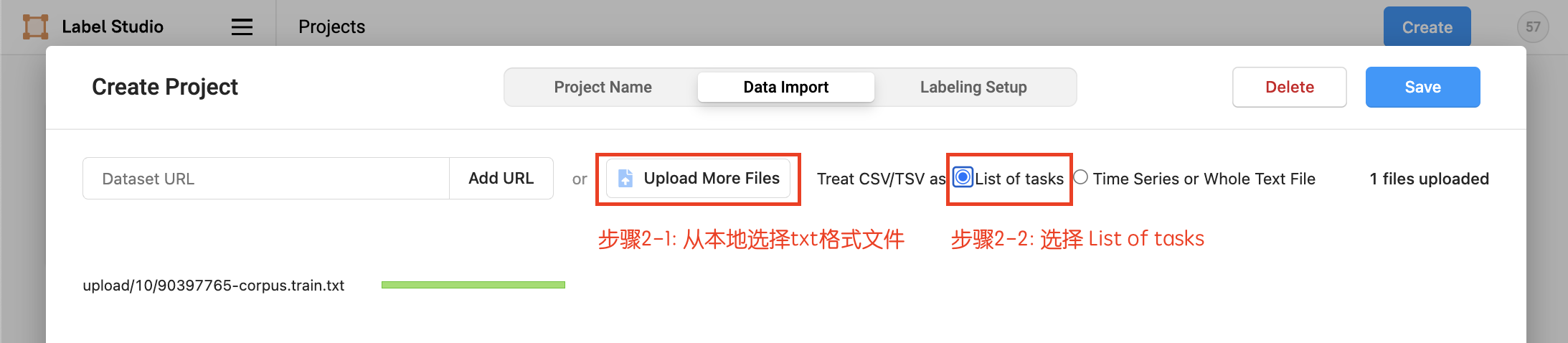
- 设置任务,添加标签
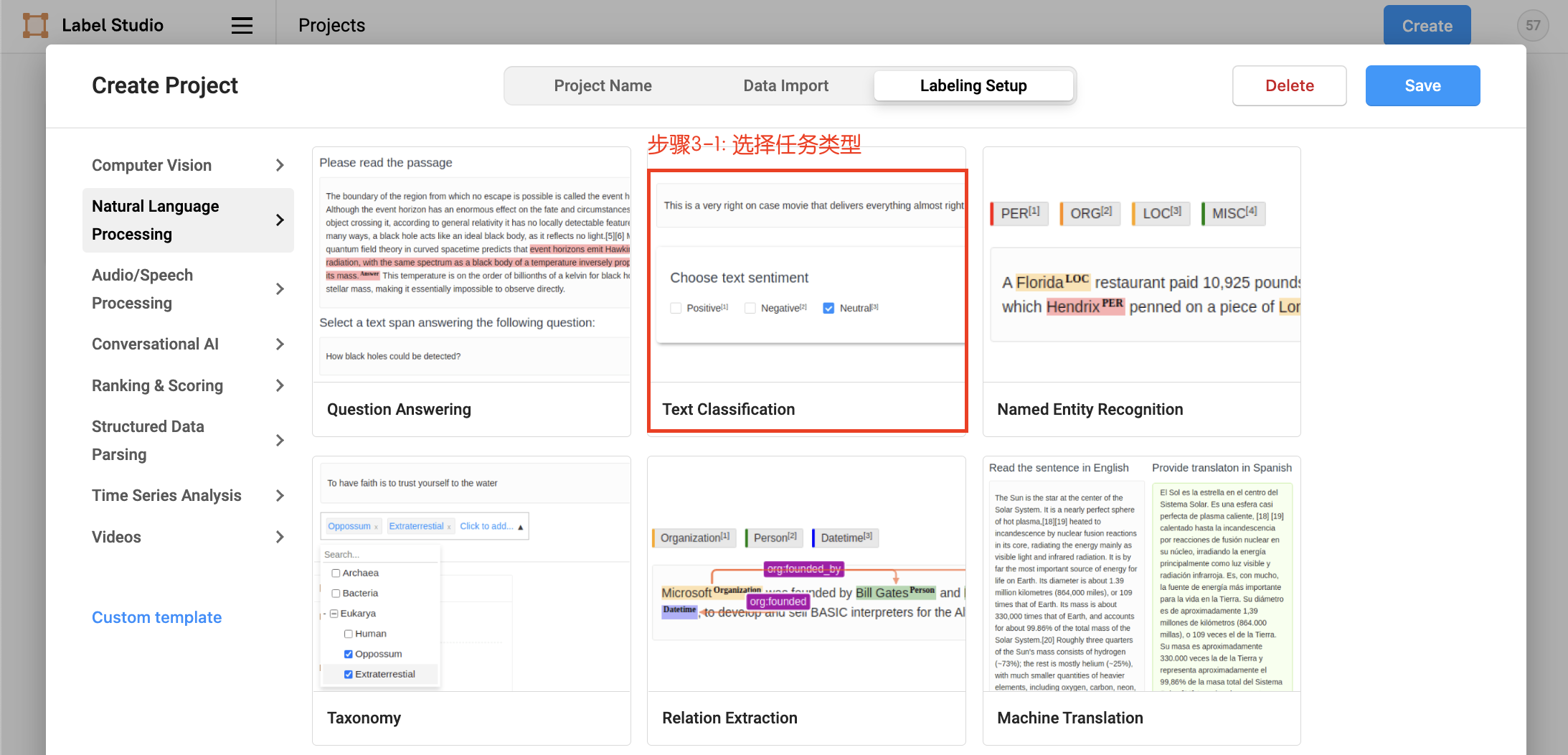
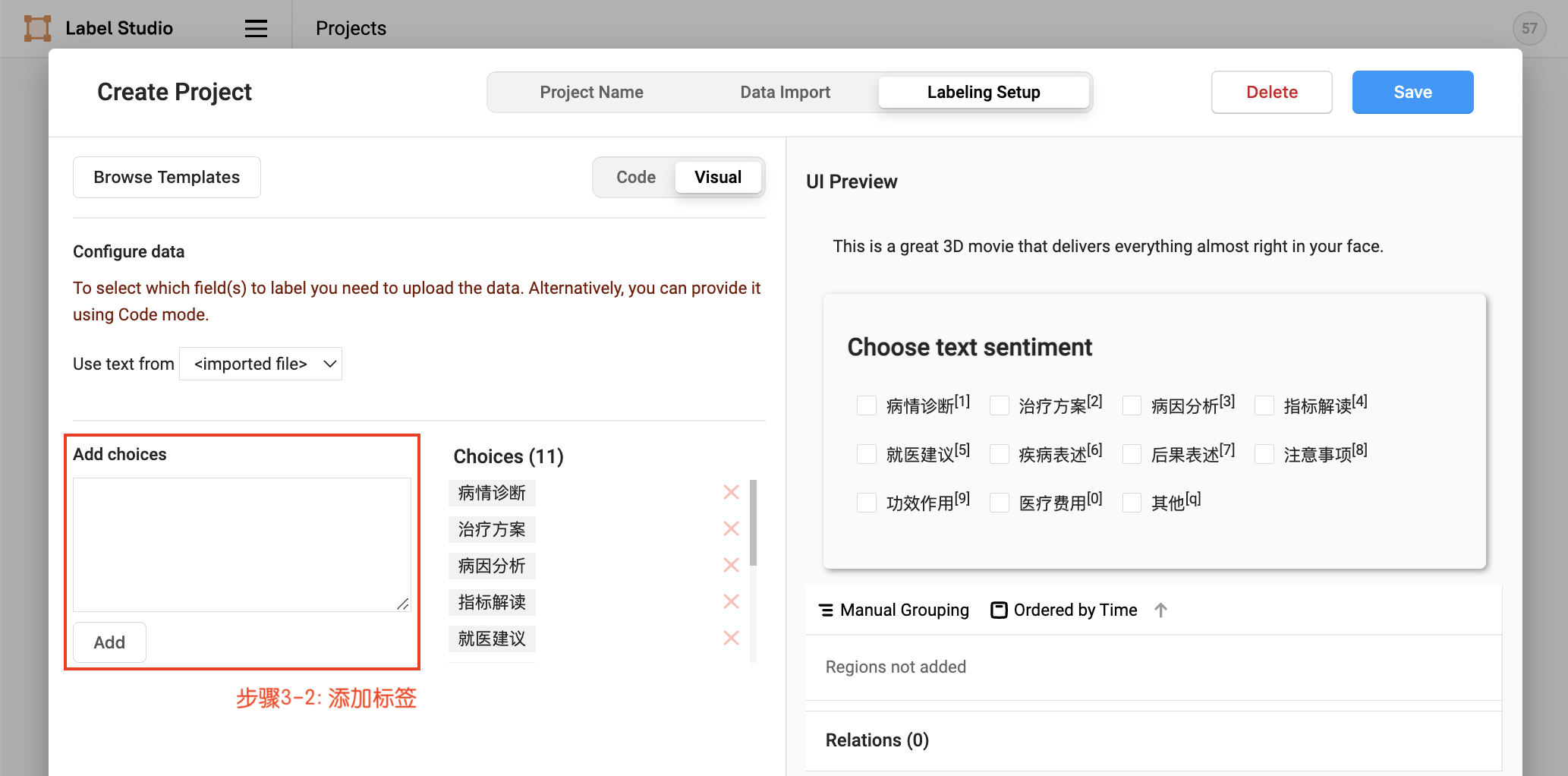
- 数据上传
项目创建后,可在Project/文本分类任务中点击Import继续导入数据,同样从本地上传txt格式文件,选择List of tasks 。
2.2.2 标签构建
项目创建后,可在Setting/Labeling Interface中继续配置标签,
默认模式为单标签多分类数据标注。对于多标签多分类数据标注,需要将choice的值由single改为multiple。

2.2.3 任务标注
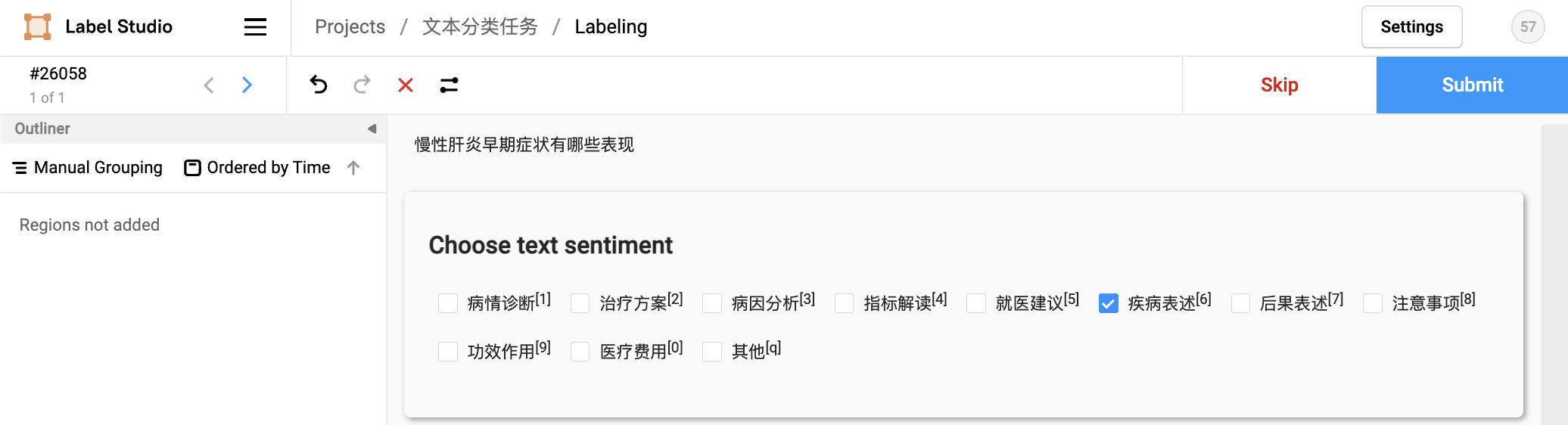
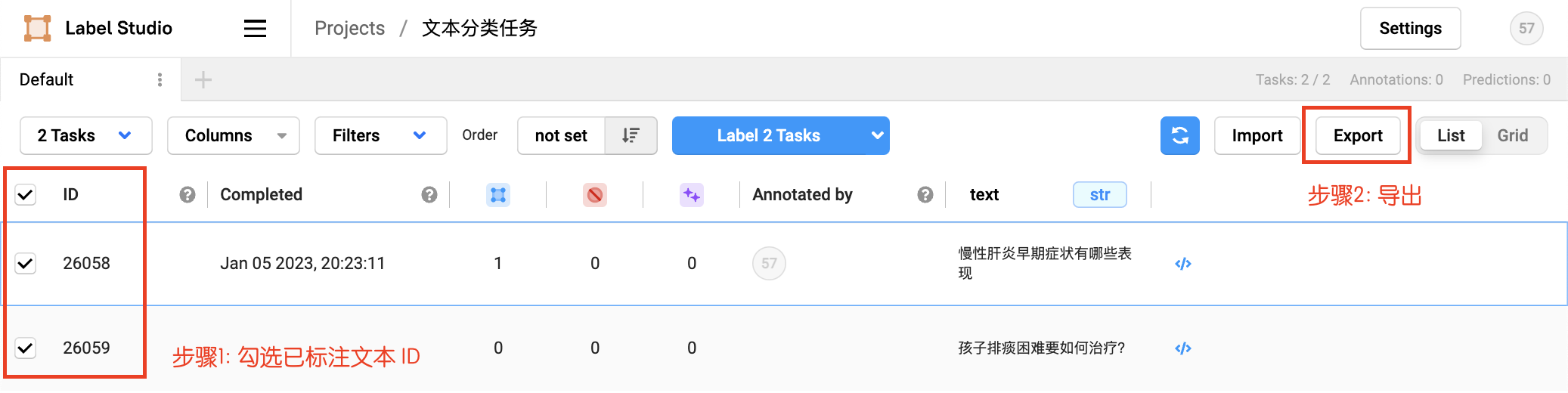
2.2.4 数据导出
勾选已标注文本ID,选择导出的文件类型为JSON,导出数据:
参考链接:
3.数据转换
将导出的文件重命名为label_studio.json后,放入./data目录下。通过label_studio.py脚本可转为UTC的数据格式。
在数据转换阶段,还需要提供标签候选信息,放在./data/label.txt文件中,每个标签占一行。例如在医疗意图分类中,标签候选为["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"],也可通过options参数直接进行配置。
这里提供预先标注好的医疗意图分类数据集的文件,可以运行下面的命令行下载数据集,我们将展示如何使用数据转化脚本生成训练/验证/测试集文件,并使用UTC模型进行微调。
#下载医疗意图分类数据集:
!wget https://bj.bcebos.com/paddlenlp/datasets/utc-medical.tar.gz
!tar -xvf utc-medical.tar.gz
!mv utc-medical data
!rm utc-medical.tar.gz
数据集部分展示
[{"id":26092,"annotations":[{"id":59,"completed_by":1,"result":[{"value":{"choices":["注意事项"]},"id":"7iya31L9oc","from_name":"sentiment","to_name":"text","type":"choices","origin":"manual"}],"was_cancelled":false,"ground_truth":false,"created_at":"2023-01-09T07:13:18.982993Z","updated_at":"2023-01-09T07:13:18.983032Z","lead_time":4.022,"prediction":{},"result_count":0,"task":26092,"parent_prediction":null,"parent_annotation":null}],"file_upload":"838fb89a-10-shot.txt","drafts":[],"predictions":[],"data":{"text":"烧氧割要注意那些问题"},"meta":{},"created_at":"2023-01-09T06:48:10.725717Z","updated_at":"2023-01-09T07:13:19.022666Z","inner_id":35,"total_annotations":1,"cancelled_annotations":0,"total_predictions":0,"comment_count":0,"unresolved_comment_count":0,"last_comment_updated_at":null,"project":5,"updated_by":1,"comment_authors":[]},
{"id":26091,"annotations":[{"id":4,"completed_by":1,"result":[{"value":{"choices":["病因分析"]}]
# 生成训练/验证集文件:
!python label_studio.py \
--label_studio_file ./data/utc-medical/label_studio.json \
--save_dir ./data \
--splits 0.8 0.1 0.1 \
--options ./data/utc-medical/label.txt
[32m[2023-04-14 11:28:46,056] [ INFO][0m - Save 45 examples to ./data/train.txt.[0m
[32m[2023-04-14 11:28:46,057] [ INFO][0m - Save 6 examples to ./data/dev.txt.[0m
[32m[2023-04-14 11:28:46,057] [ INFO][0m - Save 6 examples to ./data/test.txt.[0m
[32m[2023-04-14 11:28:46,057] [ INFO][0m - Finished! It takes 0.00 seconds[0m
[0m
{"text_a": "老年痴呆的症状有哪些", "text_b": "", "question": "", "choices": ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"], "labels": [5]}
label_studio_file: 从label studio导出的数据标注文件。save_dir: 训练数据的保存目录,默认存储在data目录下。splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。options: 指定分类任务的类别标签。若输入类型为文件,则文件中每行一个标签。is_shuffle: 是否对数据集进行随机打散,默认为True。seed: 随机种子,默认为1000.
备注:
- 默认情况下 label_studio.py 脚本会按照比例将数据划分为 train/dev/test 数据集
- 每次执行 label_studio.py 脚本,将会覆盖已有的同名数据文件
- 对于从label_studio导出的文件,默认文件中的每条数据都是经过人工正确标注的。
使用Label Studio 数据标注工具进行标注,如果已有标注好的本地数据集,我们需要将数据集整理为文档要求的格式,
4.模型训练预测
多任务训练场景可分别进行数据转换再进行混合:通用分类、评论情感分析、语义相似度计算、蕴含推理、多项式阅读理解等众多“泛分类”任务
##代码结构
├── deploy/simple_serving/ # 模型部署脚本
├── utils.py # 数据处理工具
├── run_train.py # 模型微调脚本
├── run_eval.py # 模型评估脚本
├── label_studio.py # 数据格式转换脚本
├── label_studio_text.md # 数据标注说明文档
└── README.md
4.1 模型微调
推荐使用 PromptTrainer API 对模型进行微调,该 API 封装了提示定义功能,且继承自 Trainer API 。只需输入模型、数据集等就可以使用 Trainer API 高效快速地进行预训练、微调等任务,可以一键启动多卡训练、混合精度训练、梯度累积、断点重启、日志显示等功能,Trainer API 还针对训练过程的通用训练配置做了封装,比如:优化器、学习率调度等。
使用下面的命令,使用 utc-base 作为预训练模型进行模型微调,将微调后的模型保存至output_dir:
4.1.1 单卡训练
#安装最新版本paddlenlp
!pip install --upgrade paddlenlp
# 单卡启动:
!python run_train.py \
--device gpu \
--logging_steps 10 \
--save_steps 10 \
--eval_steps 10 \
--seed 1000 \
--model_name_or_path utc-base \
--output_dir ./checkpoint/model_best \
--dataset_path ./data/ \
--max_seq_length 512 \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--gradient_accumulation_steps 8 \
--num_train_epochs 20 \
--learning_rate 1e-5 \
--do_train \
--do_eval \
--do_export \
--export_model_dir ./checkpoint/model_best \
--overwrite_output_dir \
--disable_tqdm True \
--metric_for_best_model macro_f1 \
--load_best_model_at_end True \
--save_total_limit 1 \
--save_plm
eval_loss: 0.3148668706417084, eval_micro_f1: 0.9848484848484849, eval_macro_f1: 0.9504132231404958, eval_runtime: 0.0757, eval_samples_per_second: 79.286, eval_steps_per_second: 39.643, epoch: 19.6957
[2023-04-13 17:02:45,941] [ INFO] - epoch = 19.6957
[2023-04-13 17:02:45,941] [ INFO] - train_loss = 0.9758
[2023-04-13 17:02:45,942] [ INFO] - train_runtime = 0:00:45.91
[2023-04-13 17:02:45,942] [ INFO] - train_samples_per_second = 19.602
[2023-04-13 17:02:45,942] [ INFO] - train_steps_per_second = 0.871
二分类时需要注意的问题
- ModuleNotFoundError: No module named 'fast_tokenizer'
安装一下fast tokenizer
pip install --upgrade fast_tokenizer
- 开启single_label时需要将运行脚本中的 metric_for_best_model 参数改为accuracy
metric_value = metrics[metric_to_check]
KeyError: 'eval_macro_f1'
4.1.2 多卡训练
如果在GPU环境中使用,可以指定gpus参数进行多卡训练:
# !python -u -m paddle.distributed.launch --gpus "0,1,2,3" run_train.py \
# --device gpu \
# --logging_steps 10 \
# --save_steps 10 \
# --eval_steps 10 \
# --seed 1000 \
# --model_name_or_path utc-base \
# --output_dir ./checkpoint/model_best \
# --dataset_path ./data/ \
# --max_seq_length 512 \
# --per_device_train_batch_size 2 \
# --per_device_eval_batch_size 2 \
# --gradient_accumulation_steps 8 \
# --num_train_epochs 20 \
# --learning_rate 1e-5 \
# --do_train \
# --do_eval \
# --do_export \
# --export_model_dir ./checkpoint/model_best \
# --overwrite_output_dir \
# --disable_tqdm True \
# --metric_for_best_model macro_f1 \
# --load_best_model_at_end True \
# --save_total_limit 1 \
# --save_plm
该示例代码中由于设置了参数 --do_eval,因此在训练完会自动进行评估。
可配置参数说明:
single_label: 每条样本是否只预测一个标签。默认为False,表示多标签分类。device: 训练设备,可选择 'cpu'、'gpu' 其中的一种;默认为 GPU 训练。logging_steps: 训练过程中日志打印的间隔 steps 数,默认10。save_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。eval_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。seed:全局随机种子,默认为 42。model_name_or_path:进行 few shot 训练使用的预训练模型。默认为 "utc-base", 可选"utc-xbase", "utc-base", "utc-medium", "utc-mini", "utc-micro", "utc-nano", "utc-pico"。output_dir:必须,模型训练或压缩后保存的模型目录;默认为None。dataset_path:数据集文件所在目录;默认为./data/。train_file:训练集后缀;默认为train.txt。dev_file:开发集后缀;默认为dev.txt。max_seq_len:文本最大切分长度,包括标签的输入超过最大长度时会对输入文本进行自动切分,标签部分不可切分,默认为512。per_device_train_batch_size:用于训练的每个 GPU 核心/CPU 的batch大小,默认为8。per_device_eval_batch_size:用于评估的每个 GPU 核心/CPU 的batch大小,默认为8。num_train_epochs: 训练轮次,使用早停法时可以选择 100;默认为10。learning_rate:训练最大学习率,UTC 推荐设置为 1e-5;默认值为3e-5。do_train:是否进行微调训练,设置该参数表示进行微调训练,默认不设置。do_eval:是否进行评估,设置该参数表示进行评估,默认不设置。do_export:是否进行导出,设置该参数表示进行静态图导出,默认不设置。export_model_dir:静态图导出地址,默认为None。overwrite_output_dir: 如果True,覆盖输出目录的内容。如果output_dir指向检查点目录,则使用它继续训练。disable_tqdm: 是否使用tqdm进度条。metric_for_best_model:最优模型指标, UTC 推荐设置为macro_f1,默认为None。load_best_model_at_end:训练结束后是否加载最优模型,通常与metric_for_best_model配合使用,默认为False。save_total_limit:如果设置次参数,将限制checkpoint的总数。删除旧的checkpoints输出目录,默认为None。--save_plm:保存模型进行推理部署
4.2 模型评估
通过运行以下命令进行模型评估预测:
!python run_eval.py \
--model_path ./checkpoint/model_best \
--test_path ./data/test.txt \
--per_device_eval_batch_size 16 \
--max_seq_len 512 \
--output_dir ./checkpoint_test
测试结果
[2023-04-13 17:06:59,413] [ INFO] - test_loss = 1.6392
[2023-04-13 17:06:59,413] [ INFO] - test_macro_f1 = 0.8167
[2023-04-13 17:06:59,413] [ INFO] - test_micro_f1 = 0.9394
[2023-04-13 17:06:59,413] [ INFO] - test_runtime = 0:00:00.87
[2023-04-13 17:06:59,413] [ INFO] - test_samples_per_second = 6.835
[2023-04-13 17:06:59,413] [ INFO] - test_steps_per_second = 1.139
可配置参数说明:
model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件model_state.pdparams及配置文件model_config.json。test_path: 进行评估的测试集文件。per_device_eval_batch_size: 批处理大小,请结合机器情况进行调整,默认为16。max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。single_label: 每条样本是否只预测一个标签。默认为False,表示多标签分类。
4.3模型预测
paddlenlp.Taskflow装载定制模型,通过task_path指定模型权重文件的路径,路径下需要包含训练好的模型权重文件model_state.pdparams。
!pip install onnxruntime-gpu onnx onnxconverter-common
!pip install paddle2onnx
#如果出现这个报错 local variable 'paddle2onnx' referenced before assignment ,请安装上述库onnx 的包需要安装
#中途出现一些警告可以忽视
from pprint import pprint
from paddlenlp import Taskflow
schema = ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"]
# my_cls = Taskflow("zero_shot_text_classification", model="utc-base", schema=schema, task_path='/home/aistudio/checkpoint/model_best/plm', precision="fp16")
my_cls = Taskflow("zero_shot_text_classification", model="utc-base", schema=schema, task_path='/home/aistudio/checkpoint/model_best/plm')
#支持FP16半精度推理加速,需要安装onnx
pprint(my_cls(["老年斑为什么都长在面部和手背上","老成都市哪家内痔医院比较好怎么样最好?","中性粒细胞比率偏低"]))
[2023-04-14 11:45:11,057] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'utc-base'.
[2023-04-14 11:45:11,059] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/utc-base/utc_base_vocab.txt
[2023-04-14 11:45:11,083] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/utc-base/tokenizer_config.json
[2023-04-14 11:45:11,085] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/utc-base/special_tokens_map.json
[2023-04-14 11:45:11,088] [ INFO] - Assigning ['[O-MASK]'] to the additional_special_tokens key of the tokenizer
[{'predictions': [{'label': '病因分析', 'score': 0.7360146263899581}],
'text_a': '老年斑为什么都长在面部和手背上'},
{'predictions': [{'label': '就医建议', 'score': 0.9940570944549809}],
'text_a': '老成都市哪家内痔医院比较好怎么样最好?'},
{'predictions': [{'label': '指标解读', 'score': 0.6683004187689248}],
'text_a': '中性粒细胞比率偏低'}]
from pprint import pprint
from paddlenlp import Taskflow
schema = ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"]
my_cls = Taskflow("zero_shot_text_classification", model="utc-base", schema=schema)
pprint(my_cls(["老年斑为什么都长在面部和手背上","老成都市哪家内痔医院比较好怎么样最好?","中性粒细胞比率偏低"]))
[2023-04-14 11:45:20,869] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'utc-base'.
[2023-04-14 11:45:20,872] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/utc-base/utc_base_vocab.txt
[2023-04-14 11:45:20,897] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/utc-base/tokenizer_config.json
[2023-04-14 11:45:20,900] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/utc-base/special_tokens_map.json
[2023-04-14 11:45:20,903] [ INFO] - Assigning ['[O-MASK]'] to the additional_special_tokens key of the tokenizer
[{'predictions': [], 'text_a': '老年斑为什么都长在面部和手背上'},
{'predictions': [{'label': '就医建议', 'score': 0.9283481315032535},
{'label': '其他', 'score': 0.5083715719139965}],
'text_a': '老成都市哪家内痔医院比较好怎么样最好?'},
{'predictions': [{'label': '其他', 'score': 0.9437889944553786}],
'text_a': '中性粒细胞比率偏低'}]
4.3.1 预测结果对比
| 模型 | 文本 | 预测结果 | 评估得分 |
|---|---|---|---|
| utc-base | 老年斑为什么都长在面部和手背上 | 空 | --- |
| utc-base | 老成都市哪家内痔医院比较好怎么样最好? | 就医建议/其他 | 0.92/0.51 |
| utc-base | 中性粒细胞比率偏低 | 其他 | 0.94 |
| utc-base+微调 | 老年斑为什么都长在面部和手背上 | 病因分析 | 0.73 |
| utc-base+微调 | 老成都市哪家内痔医院比较好怎么样最好? | 就医建议 | 0.99 |
| utc-base+微调 | 中性粒细胞比率偏低 | 指标解读 | 0.66 |
明显可以看到在通过样本训练后,在test测试的结果小样本本微调的结果显著提升
4.3.2 各个模型见对比
Micro F1更关注整个数据集的性能,而Macro F1更关注每个类别的性能。
医疗意图分类数据集 KUAKE-QIC 验证集 zero-shot 实验指标和小样本下训练对比:
| Macro F1 | Micro F1 | 微调后 Macro F1 | 微调后 Micro F1 | |
|---|---|---|---|---|
| utc-xbase | 66.30 | 89.67 | ||
| utc-base | 64.13 | 89.06 | 81.67(+17.54) | 93.94 (+4.88) |
| utc-medium | 69.62 | 89.15 | ||
| utc-micro | 60.31 | 79.14 | ||
| utc-mini | 65.82 | 89.82 | ||
| utc-nano | 62.03 | 80.92 | ||
| utc-pico | 53.63 | 83.57 |
其余模型就不一一验证了,感兴趣同学自行验证。
5.模型部署
目前 UTC 模型提供基于多种部署方式,包括基于 FastDeploy 的本地 Python 部署以及 PaddleNLP SimpleServing 的服务化部署。
5.1 FastDeploy UTC 模型 Python 部署示例
以下示例展示如何基于 FastDeploy 库完成 UTC 模型完成通用文本分类任务的 Python 预测部署,可通过命令行参数--device以及--backend指定运行在不同的硬件以及推理引擎后端,并使用--model_dir参数指定运行的模型。模型目录为 application/zero_shot_text_classification/checkpoint/model_best(用户可按实际情况设置)。
在部署前,参考 FastDeploy SDK 安装文档安装 FastDeploy Python SDK。
本目录下提供 infer.py 快速完成在 CPU/GPU 的通用文本分类任务的 Python 部署示例。
- 依赖安装
直接执行以下命令安装部署示例的依赖。
# 安装 fast_tokenizer 以及 GPU 版本 fastdeploy
pip install fast-tokenizer-python fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
以下示例展示如何基于 FastDeploy 库完成 UTC 模型进行文本分类任务的 Python 预测部署,可通过命令行参数--device以及--backend指定运行在不同的硬件以及推理引擎后端,并使用--model_dir参数指定运行的模型,具体参数设置可查看下面[参数说明])。示例中的模型是按照 [UTC 训练文档]导出得到的部署模型,其模型目录为 application/zero_shot_text_classification/checkpoint/model_best(用户可按实际情况设置)。
# CPU 推理
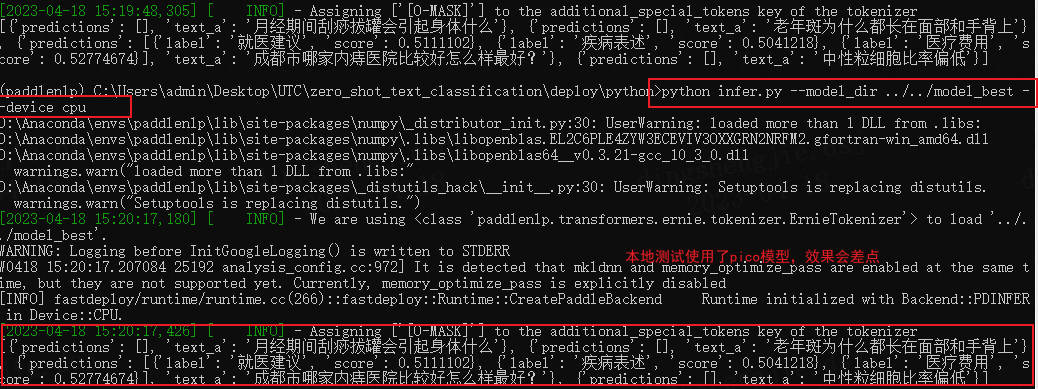
python /home/aistudio/deploy/python/infer.py--model_dir /home/aistudio/checkpoint/model_best --device cpu
# GPU 推理
python /home/aistudio/deploy/python/infer.py --model_dir /home/aistudio/checkpoint/model_best --device gpu
运行完成后返回的结果如下:
- 参数说明
| 参数 | 参数说明 |
|---|---|
| --model_dir | 指定部署模型的目录, |
| --batch_size | 输入的batch size,默认为 1 |
| --max_length | 最大序列长度,默认为 128 |
| --num_omask_tokens | 最大标签数量,默认为64 |
| --device | 运行的设备,可选范围: ['cpu', 'gpu'],默认为'cpu' |
| --device_id | 运行设备的id。默认为0。 |
| --cpu_threads | 当使用cpu推理时,指定推理的cpu线程数,默认为1。 |
| --backend | 支持的推理后端,可选范围: ['onnx_runtime', 'paddle', 'tensorrt', 'paddle_tensorrt'],默认为'paddle' |
| --use_fp16 | 是否使用FP16模式进行推理。使用tensorrt和paddle_tensorrt后端时可开启,默认为False |
- FastDeploy 高阶用法
FastDeploy 在 Python 端上,提供 fastdeploy.RuntimeOption.use_xxx() 以及 fastdeploy.RuntimeOption.use_xxx_backend() 接口支持开发者选择不同的硬件、不同的推理引擎进行部署。在不同的硬件上部署 UTC 模型,需要选择硬件所支持的推理引擎进行部署,下表展示如何在不同的硬件上选择可用的推理引擎部署 UTC 模型。
符号说明: (1) : 已经支持; (2) : 正在进行中; (3) N/A: 暂不支持;
| 硬件 | 硬件对应的接口 | 可用的推理引擎 | 推理引擎对应的接口 | 是否支持 Paddle 新格式量化模型 | 是否支持 FP16 模式 |
| CPU | use_cpu() | Paddle Inference | use_paddle_infer_backend() | N/A | |
| ONNX Runtime | use_ort_backend() | N/A | |||
| GPU | use_gpu() | Paddle Inference | use_paddle_infer_backend() | N/A | |
| ONNX Runtime | use_ort_backend() | ||||
| Paddle TensorRT | use_paddle_infer_backend() + paddle_infer_option.enable_trt = True | ||||
| TensorRT | use_trt_backend() | ||||
| 昆仑芯 XPU | use_kunlunxin() | Paddle Lite | use_paddle_lite_backend() | N/A | |
| 华为 昇腾 | use_ascend() | Paddle Lite | use_paddle_lite_backend() | ||
| Graphcore IPU | use_ipu() | Paddle Inference | use_paddle_infer_backend() | N/A |
# !pip install --user fast-tokenizer-python fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
#比较大1.4G 去终端安装
在notebook执行出现问题,可能需要本地对fastdeploy应用调试,或者有小伙伴解决了可以再评论区发表一下,一起解决。
- 在studio 目前显示是安装成功了,但是初始化是失败的
File "/home/aistudio/.data/webide/pip/lib/python3.7/site-packages/fastdeploy/c_lib_wrap.py", line 166, in <module>
raise RuntimeError("FastDeploy initalized failed!")
RuntimeError: FastDeploy initalized failed!
- 在本地测试模型使用了utc-pico,cpu情况下调试。
效果如下:
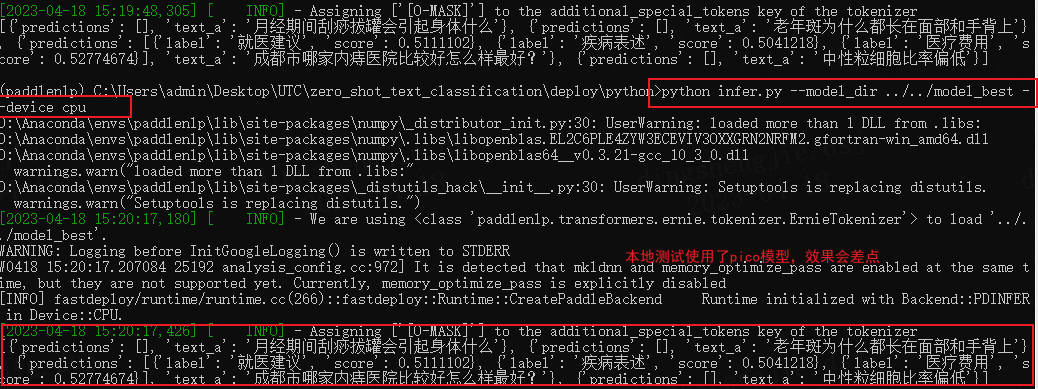
记得修改infer文件对应的预测内容
predictor = Predictor(args, schema=["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"])
results = predictor.predict(["月经期间刮痧拔罐会引起身体什么","老年斑为什么都长在面部和手背上","成都市哪家内痔医院比较好怎么样最好?","中性粒细胞比率偏低"])
推理:模型目录需要包含:model.pdmodel等文件
5.2 SimpleServing 的服务化部署
在 UTC 的服务化能力中我们提供基于PaddleNLP SimpleServing 来搭建服务化能力,通过几行代码即可搭建服务化部署能力。
- 环境准备
使用有SimpleServing功能的PaddleNLP版本(或者最新的develop版本)
pip install paddlenlp >= 2.5.0
- Server服务启动
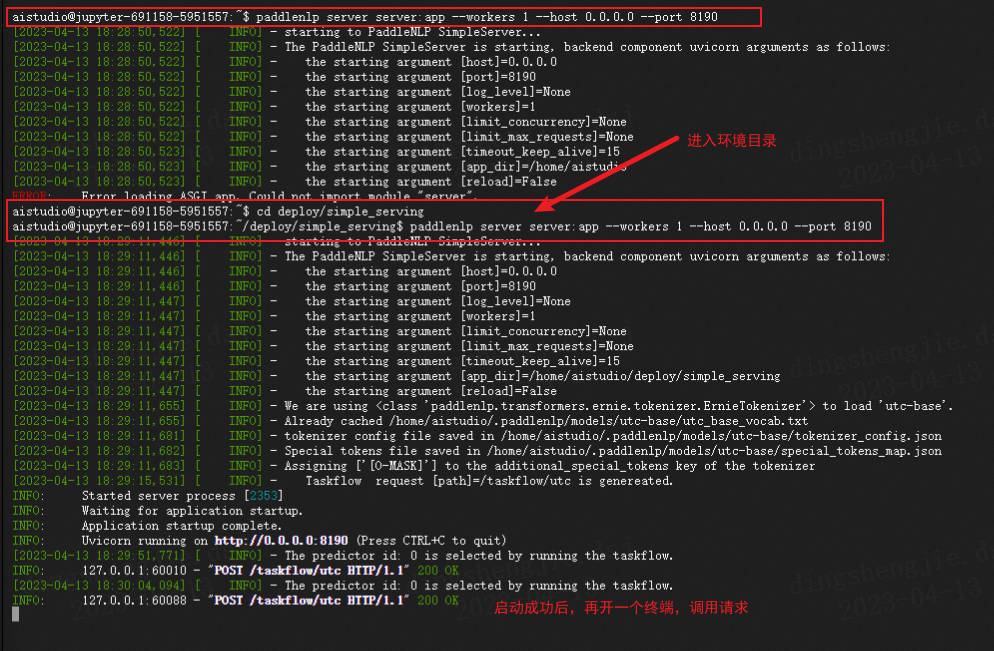
进入文件当前所在路径
paddlenlp server server:app --workers 1 --host 0.0.0.0 --port 8190
- Client请求启动
python client.py
服务化自定义参数
Server 自定义参数
schema替换
# Default schema
schema = ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"]
* 设置模型路径
# Default task_path
utc = Taskflow("zero_shot_text_classification", model="utc-base", task_path="../../checkpoint/model_best/plm", schema=schema)
* 多卡服务化预测
PaddleNLP SimpleServing 支持多卡负载均衡预测,主要在服务化注册的时候,注册两个Taskflow的task即可,下面是示例代码
utc1 = Taskflow("zero_shot_text_classification", model="utc-base", task_path="../../checkpoint/model_best", schema=schema)
utc2 = Taskflow("zero_shot_text_classification", model="utc-base", task_path="../../checkpoint/model_best", schema=schema)
service.register_taskflow("taskflow/utc", [utc1, utc2])
- 更多配置
from paddlenlp import Taskflow
schema = ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"]
utc = Taskflow("zero_shot_text_classification",
schema=schema,
model="utc-base",
max_seq_len=512,
batch_size=1,
pred_threshold=0.5,
precision="fp32")
schema:定义任务标签候选集合。model:选择任务使用的模型,默认为utc-base, 可选有utc-xbase,utc-base,utc-medium,utc-micro,utc-mini,utc-nano,utc-pico。max_seq_len:最长输入长度,包括所有标签的长度,默认为512。batch_size:批处理大小,请结合机器情况进行调整,默认为1。pred_threshold:模型对标签预测的概率在0~1之间,返回结果去掉小于这个阈值的结果,默认为0.5。precision:选择模型精度,默认为fp32,可选有fp16和fp32。fp16推理速度更快。如果选择fp16,请先确保机器正确安装NVIDIA相关驱动和基础软件,确保CUDA>=11.2,cuDNN>=8.1.1,初次使用需按照提示安装相关依赖。其次,需要确保GPU设备的CUDA计算能力(CUDA Compute Capability)大于7.0,典型的设备包括V100、T4、A10、A100、GTX 20系列和30系列显卡等。更多关于CUDA Compute Capability和精度支持情况请参考NVIDIA文档:GPU硬件与支持精度对照表。- Client 自定义参数
# Changed to input texts you wanted
texts = ["中性粒细胞比率偏低"]
%cd /home/aistudio/deploy/simple_serving
!paddlenlp server server:app --workers 1 --host 0.0.0.0 --port 8190
#Error loading ASGI app. Could not import module "server".
#去终端执行即可
/home/aistudio/deploy/simple_serving
[2023-04-13 18:26:51,839] [ INFO] - starting to PaddleNLP SimpleServer...
[2023-04-13 18:26:51,840] [ INFO] - The PaddleNLP SimpleServer is starting, backend component uvicorn arguments as follows:
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [host]=0.0.0.0
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [port]=8190
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [log_level]=None
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [workers]=1
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [limit_concurrency]=None
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [limit_max_requests]=None
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [timeout_keep_alive]=15
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [app_dir]=/home/aistudio/deploy/simple_serving
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [reload]=False
[2023-04-13 18:26:52,037] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'utc-base'.
[2023-04-13 18:26:52,038] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/utc-base/utc_base_vocab.txt
[2023-04-13 18:26:52,067] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/utc-base/tokenizer_config.json
[2023-04-13 18:26:52,067] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/utc-base/special_tokens_map.json
[2023-04-13 18:26:52,069] [ INFO] - Assigning ['[O-MASK]'] to the additional_special_tokens key of the tokenizer
[2023-04-13 18:26:55,628] [ INFO] - Taskflow request [path]=/taskflow/utc is genereated.
INFO: Started server process [1718]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8190 (Press CTRL+C to quit)
^C
INFO: Shutting down
INFO: Waiting for application shutdown.
INFO: Application shutdown complete.
INFO: Finished server process [1718]
在notebook如果不行,可以直接进入终端进行调试,需要注意的是要在同一个路径下不然会报错
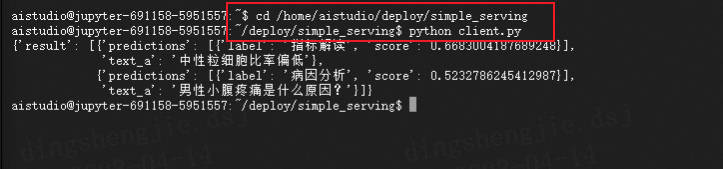
# Save at server.py
from paddlenlp import SimpleServer, Taskflow
schema = ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议"]
utc = Taskflow("zero_shot_text_classification",
model="utc-base",
schema=schema,
task_path="/home/aistudio/checkpoint/model_best/plm",
precision="fp32")
app = SimpleServer()
app.register_taskflow("taskflow/utc", utc)
# %cd /home/aistudio/deploy/simple_serving
!python client.py
6.总结
原项目链接:
https://blog.csdn.net/sinat_39620217/article/details/130237035
原文文末含码源以及地址
Macro F1和Micro F1都是评估分类模型性能的指标,但是它们计算方式不同。
Macro F1是每个类别的F1值的平均值,不考虑类别的样本数。它适用于数据集中各个类别的样本数量相近的情况下,可以更好地反映每个类别的性能。
Micro F1是所有类别的F1值的加权平均,其中权重为每个类别的样本数。它将所有类别的预测结果汇总为一个混淆矩阵,并计算出整个数据集的精确率、召回率和F1值。Micro F1适用于多分类问题,尤其是在数据集不平衡的情况下,可以更好地反映整体的性能。
总之,Micro F1更关注整个数据集的性能,而Macro F1更关注每个类别的性能。
医疗意图分类数据集 KUAKE-QIC 验证集 zero-shot 实验指标和小样本下训练对比:
| Macro F1 | Micro F1 | 微调后 Macro F1 | 微调后 Micro F1 | |
|---|---|---|---|---|
| utc-xbase | 66.30 | 89.67 | ||
| utc-base | 64.13 | 89.06 | 81.67(+17.54) | 93.94 (+4.88) |
| utc-medium | 69.62 | 89.15 | ||
| utc-micro | 60.31 | 79.14 | ||
| utc-mini | 65.82 | 89.82 | ||
| utc-nano | 62.03 | 80.92 | ||
| utc-pico | 53.63 | 83.57 |
6.1 更多任务适配
PaddleNLP结合文心ERNIE,基于UTC技术开源了首个面向通用文本分类的产业级技术方案。对于简单任务,通过调用 paddlenlp.Taskflow API ,仅用三行代码即可实现零样本(Zero-shot)通用文本分类,可支持情感分析、意图识别、语义匹配、蕴含推理等各种可转换为分类问题的NLU任务。仅使用一个模型即可同时支持多个任务,便捷高效!
from pprint import pprint
from paddlenlp import Taskflow
# 情感分析
cls = Taskflow("zero_shot_text_classification", schema=["这是一条好评", "这是一条差评"])
cls("房间干净明亮,非常不错")
>>>
[{'predictions': [{'label': '这是一条好评', 'score': 0.9695149765679986}],
'text_a': '房间干净明亮,非常不错'}]
# 意图识别
schema = ["病情诊断", "治疗方案", "病因分析", "指标解读", "就医建议", "疾病表述", "后果表述", "注意事项", "功效作用", "医疗费用", "其他"]
pprint(cls("先天性厚甲症去哪里治"))
>>>
[{'predictions': [{'label': '就医建议', 'score': 0.9628814210597645}],
'text_a': '先天性厚甲症去哪里治'}]
# 语义相似度
cls = Taskflow("zero_shot_text_classification", schema=["不同", "相同"])
pprint(cls([["怎么查看合同", "从哪里可以看到合同"], ["为什么一直没有电话来确认借款信息", "为何我还款了,今天却接到客服电话通知"]]))
>>>
[{'predictions': [{'label': '相同', 'score': 0.9775065319076257}],
'text_a': '怎么查看合同',
'text_b': '从哪里可以看到合同'},
{'predictions': [{'label': '不同', 'score': 0.9918983379165037}],
'text_a': '为什么一直没有电话来确认借款信息',
'text_b': '为何我还款了,今天却接到客服电话通知'}]
# 蕴含推理
cls = Taskflow("zero_shot_text_classification", schema=["中立", "蕴含", "矛盾"])
pprint(cls([["一个骑自行车的人正沿着一条城市街道朝一座有时钟的塔走去。", "骑自行车的人正朝钟楼走去。"],
["一个留着长发和胡须的怪人,在地铁里穿着一件颜色鲜艳的衬衫。", "这件衬衫是新的。"],
["一个穿着绿色衬衫的妈妈和一个穿全黑衣服的男人在跳舞。", "两人都穿着白色裤子。"]]))
>>>
[{'predictions': [{'label': '蕴含', 'score': 0.9944843058584897}],
'text_a': '一个骑自行车的人正沿着一条城市街道朝一座有时钟的塔走去。',
'text_b': '骑自行车的人正朝钟楼走去。'},
{'predictions': [{'label': '中立', 'score': 0.6659998351201399}],
'text_a': '一个留着长发和胡须的怪人,在地铁里穿着一件颜色鲜艳的衬衫。',
'text_b': '这件衬衫是新的。'},
{'predictions': [{'label': '矛盾', 'score': 0.9270557883904931}],
'text_a': '一个穿着绿色衬衫的妈妈和一个穿全黑衣服的男人在跳舞。',
'text_b': '两人都穿着白色裤子。'}]
零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程。的更多相关文章
- 基于CDH 5.9.1 搭建 Hive on Spark 及相关配置和调优
Hive默认使用的计算框架是MapReduce,在我们使用Hive的时候通过写SQL语句,Hive会自动将SQL语句转化成MapReduce作业去执行,但是MapReduce的执行速度远差与Spark ...
- Zero-shot learning(零样本学习)
一.介绍 在传统的分类模型中,为了解决多分类问题(例如三个类别:猫.狗和猪),就需要提供大量的猫.狗和猪的图片用以模型训练,然后给定一张新的图片,就能判定属于猫.狗或猪的其中哪一类.但是对于之前训练图 ...
- 文本分类实战(六)—— RCNN模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(四)—— Bi-LSTM模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 文本分类实战(二)—— textCNN 模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- DL4NLP —— 序列标注:BiLSTM-CRF模型做基于字的中文命名实体识别
三个月之前 NLP 课程结课,我们做的是命名实体识别的实验.在MSRA的简体中文NER语料(我是从这里下载的,非官方出品,可能不是SIGHAN 2006 Bakeoff-3评测所使用的原版语料)上训练 ...
- kaldi基于GMM的单音素模型 训练部分
目录 1. gmm-init-mono 模型初始化 2. compile-train-graghs 训练图初始化 3. align-equal-compiled 特征文件均匀分割 4. gmm-acc ...
- 课程报名 | 基于模型训练平台快速打造 AI 能力
我们常说的 AI 通用能力往往不针对具体的行业应用,而是主要解决日常或者泛化的问题,很多技术企业给出的方案是通用式的,比如通用文字识别,无论识别身份证.驾驶证.行驶证等,任何一张图片训练后的模型都会尽 ...
- ML.NET 示例:图像分类模型训练-首选API(基于原生TensorFlow迁移学习)
ML.NET 版本 API 类型 状态 应用程序类型 数据类型 场景 机器学习任务 算法 Microsoft.ML 1.5.0 动态API 最新 控制台应用程序和Web应用程序 图片文件 图像分类 基 ...
- 基于机器学习和TFIDF的情感分类算法,详解自然语言处理
摘要:这篇文章将详细讲解自然语言处理过程,基于机器学习和TFIDF的情感分类算法,并进行了各种分类算法(SVM.RF.LR.Boosting)对比 本文分享自华为云社区<[Python人工智能] ...
随机推荐
- 5.Vue前后端交互
一.前后端交互模式 1.1 接口调用方式 原生ajax 基于JQuery的ajax fetch axios 返回一个完整的HTML页面 也可以只返回特定格式的数据,比如json 1.2 URL地址格式 ...
- EL_获取域中存储的值_ List 集合&Map集合值和EL _ empty 运算符&隐式对象 pageContext
3.获取对線. List 集合. Map 集合的值 1.对線:${域名称,键名.属性名}本质上会去调用对線的 getter 方法 2. List 集合:${域名称.键名[索引]} List list ...
- mmdetection加载ndarray数据,并训练
1.构造coco数据集,file_name为具体的ndarray文件名,类名的改变和class_num的配置和之前一样.保存的npy文件是归一化之后的结果 2.修改数据加载代码,将 2.修改网络输入i ...
- CURL 常用命令
参考博客:https://blog.csdn.net/wangpengfei163/article/details/80900391
- 实践Pytorch中的模型剪枝方法
摘要:所谓模型剪枝,其实是一种从神经网络中移除"不必要"权重或偏差的模型压缩技术. 本文分享自华为云社区<模型压缩-pytorch 中的模型剪枝方法实践>,作者:嵌入式 ...
- 如何在 Apinto 实现 HTTP 与gRPC 的协议转换 (上)
什么是 gRPC 像gRPC是由google开发的一个高性能.通用的开源 RPC 框架,主要面向移动应用开发且基于HTTP/2协议标准而设计,同时支持大多数流行的编程语言. gRPC基于 HTTP/2 ...
- 从开源模型、框架到自研,声网 Web 端虚拟背景算法正式发布
根据研究发现,在平均 38 分钟的视频会议里面,大概会有 13 分钟左右的时间用于处理和干扰相关的事情.同时研究也表明在参加在线会议的时候,人们更加倾向于语音会议,其中一个关键原因就是大家不希望个人隐 ...
- 浅谈云原生基础入坑与docker 搭建redis-cluster集群
浅谈云原生基础入坑与docker 搭建redis-cluster集群 开篇来点自己的小感触:自从走上后端开发这条无法回头的互卷道路以后,在视野内可见新的技术在迭代,更新的技术在不断发行.就拿最近的Op ...
- git 从本地仓库提交至远程仓库 报错:error: failed to push some refs to "xxx"
**原因**:远程库里面有个文件,但是本地没有这个文件,比如: README.md,完全提交上去会覆盖之前的文件,所以git会提示报错警告! **解决方案**:如果只有 README.md文件,可以使 ...
- opencv-python 2 图像基本操作
图像的基本操作 获取并修改图像的像素值 可以通过行和列的坐标值获取该像素点的像素值.对于BGR图像,它返回一个蓝色,绿色,红色值的数组.对于灰度图像,仅返回相应的强度值. 可以用同样的方法修改像素点的 ...