Python数据科学手册-Pandas:层级索引
一维数据 和 二维数据 分别使用Series 和 DataFrame 对象存储。
多维数据:数据索引 超过一俩个 键。
Pandas提供了Panel 和 Panel4D对象 解决三维数据和四维数据。
实践中,更直观的形式是通过 层级索引(Hierarchical indexing, 多级索引 = 》 muti-indexing)
配合 多个不同 等级的一级索引 一起使用。
本节介绍 MultiIndex对象的使用,以及 普通索引 与 层级索引的转换
多级索引Series
- 笨方法

- 好方法: MultiIndex
上面的笨方法 是用元组来表示索引 就是 多级索引的基础。
可以用元组创建一个多级索引

levels 属性表示索引的等级 。
前面的 Series对象 使用索引重置(reindex)就转换为MultiIndex

切片获取 2010 年的数据

- 高维数据的多级索引
可以使用一个带行 列 索引的 简单DataFrame 代替前面的多级索引。
unstack()方法可以快速将一个多级索引的Series 转换为普通索引的DataFrame.

stack()方法 反过来

why:
可以使用含多级索引的一维Series 表示 二维数据,
就可以使用
Series 或DataFrame 表示 三维 甚至更高维度的数据。
多级索引 每 增加 以及,就表示数据增加一维。
比如:增加一列显示每一年 各州的人口统计指标。
对于带有MultiIndex的对象。增加一列,就和DataFrame一样简单。

多级索引创建方法
为Series 和 DataFrame 创建多级索引 最 直接 的办法就是将index参数设置为至少 二维的索引数组。
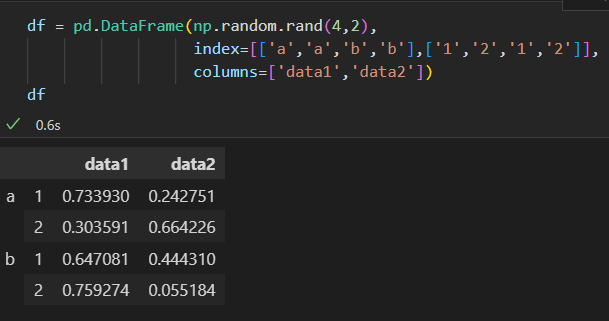
同理,将元组作为键的字典传递给Pandas, Pandas也会默认转换为MultiIndex
显示的创建多级索引
- 一个不同等级的若干简单数组组成的列表来构见MultiIndex

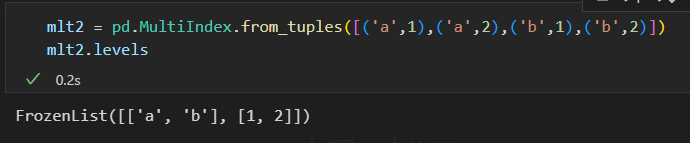
2) 包含多个索引值得元组构成的列表
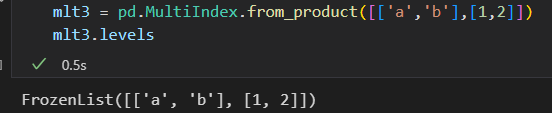
3) 俩个索引的笛卡尔积
4)直接提供levels ,注意老版本是labels,新版本是code了。

在创建Series 或 DataFrame时,可以将这些对象作为index参数。 或者通过reindex方法更新Series/DataFrame.
多级索引的等级名称

多级列索引
行与列是对称的。

多级索引的取值与切片
1)Series多级索引
单个元素

局部取值
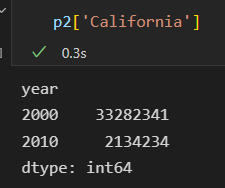
局部切片

较低层级的索引

布尔掩码

花哨索引

2)DataFrame多级索引
DataFrame的基本索引是列索引。

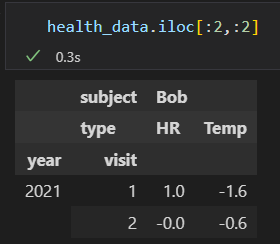

传递多个层级的索引元组


2022年5月31日23:18:51
多级索引行列转换
1) 有序的索引和无序的索引
如果MultiIndex不是有序的索引,那么大多数切片操作都会失败。
局部切片要求MultiIndex各级索引 有序。 按照字典序。


索引排序。 sort_index() sortlevel()


- 索引stack与unstack
unstack 将一个多级的索引数据 转为 简单的二维形式, level 设置转换的索引层级。

levle=1

stack是unstack的逆操作。
3)索引的设置 与 重置
层级数据维度转换的另一种方法是 行列标签转换。
可以通过reset_index方法实现。
Series中使用该方法, 会生成一个列标签中包含之前行索引 标签的state 和 year的 DataFrame.

set_index 逆操作。

多级索引的数据累计方法
可以设置参数 level实现对数据子集的累计操作。

增加axis参数。就可以累计了

Python数据科学手册-Pandas:层级索引的更多相关文章
- Python数据科学手册-Pandas:累计与分组
简单累计功能 Series sum() 返回一个 统计值 DataFrame sum.默认对每列进行统计 设置axis参数,对每一行 进行统计 describe()可以计算每一列的若干常用统计值. 获 ...
- Python数据科学手册-Pandas:向量化字符串操作、时间序列
向量化字符串操作 Series 和 Index对象 的str属性. 可以正确的处理缺失值 方法列表 正则表达式. Method Description match() Call re.match() ...
- Python数据科学手册-Pandas:数值运算方法
Numpy 的基本能力之一是快速对每个元素进行运算 Pandas 继承了Numpy的功能,也实现了一些高效技巧. 对于1元运算,(函数,三角函数)保留索引和列标签 对于2元运算,(加法,乘法),Pan ...
- Python数据科学手册-Pandas:数据取值与选择
Numpy数组取值 切片[:,1:5], 掩码操作arr[arr>0], 花哨的索引 arr[0, [1,5]],Pandas的操作类似 Series数据选择方法 Series对象与一维Nump ...
- Python数据科学手册-Pandas数据处理之简介
Pandas是在Numpy基础上建立的新程序库,提供了一种高效的DataFrame数据结构 本质是带行标签 和 列标签.支持相同类型数据和缺失值的 多维数组 增强版的Numpy结构化数组 行和列不在只 ...
- Python数据科学手册-Pandas:合并数据集
将不同的数据源进行合并 , 类似数据库 join merge . 工具函数 concat / append pd.concat() 简易合并 合并高维数据 默认按行合并. axis=0 ,试试 axi ...
- 100天搞定机器学习|day45-53 推荐一本豆瓣评分9.3的书:《Python数据科学手册》
<Python数据科学手册>共五章,每章介绍一到两个Python数据科学中的重点工具包.首先从IPython和Jupyter开始,它们提供了数据科学家需要的计算环境:第2章讲解能提供nda ...
- Python数据科学手册
Python数据科学手册(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1KurSdjNWiwMac3o3iLrzBg 提取码:qogy 复制这段内容后打开百度网盘手 ...
- Matplotlib 使用 - 《Python 数据科学手册》学习笔记
一.引入 import matplotlib as mpl import matplotlib.pyplot as plt 二.配置 1.画图接口 Matplotlib 有两种画图接口: (1)一个是 ...
随机推荐
- NC14683 储物点的距离
NC14683 储物点的距离 题目 题目描述 一个数轴,每一个储物点会有一些东西,同时它们之间存在距离. 每次给个区间 \([l,r]\) ,查询把这个区间内所有储物点的东西运到另外一个储物点的代价是 ...
- 深入浅出理解SVM支持向量机算法
支持向量机是Vapnik等人于1995年首先提出的,它是基于VC维理论和结构风险最小化原则的学习机器.它在解决小样本.非线性和高维模式识别问题中表现出许多特有的优势,并在一定程度上克服了" ...
- Kalman卡尔曼滤波,Least Square最小二乘估计,加权最小二乘,递归最小二乘
以下是Kalman的收敛性证明思路: cite:Stochastic Processes and Filtering Theory
- Java 插入公式到PPT幻灯片
PowerPoint幻灯片中可插入公式,用于在幻灯片放映时演示相关内容的论证.推算的依据,能有效地为演讲者提供论述的数据支撑.通过后端程序代码,我们可借助特定的工具来实现在幻灯片中的插入公式,本文,将 ...
- CTO与CIO选型数据中台的几大建议
企业数字化转型离不开企业数字化技术的配备.但企业在选择数字化技术时也面临着一个问题,就是如何在大胆采用先进的数字化技术和对技术进行投资之间找到平衡,将投资风险降到最低,毕竟错误的技术选型会给企业带来不 ...
- Re:用webpack从零开始的vue-cli搭建'生活'
有了vue-cli的帮助,我们创建vue的项目非常的方便,使用vue create然后选择些需要的配置项就能自动帮我们创建配置好的webpack项目脚手架了,实在是'居家旅行'必备良药.这次借着学习w ...
- OPC UA分布式IO模块
OPC UA IO模块对工业物联网的影响 OPC UA IO模块是指IO模块支持OPC UA协议,可以直接与OPC Client进行通信,这样就可以从OPC Client上直接远程通过以太网对IO口进 ...
- 用户认证(Authentication)进化之路:由Basic Auth到Oauth2再到jwt
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_98 用户认证是一个在web开发中亘古不变的话题,因为无论是什么系统,什么架构,什么平台,安全性是一个永远也绕不开的问题 在HTTP ...
- 霜皮剥落紫龙鳞,下里巴人再谈数据库SQL优化,索引(一级/二级/聚簇/非聚簇)原理
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_206 举凡后端面试,面试官不言数据库则已,言则必称SQL优化,说起SQL优化,网络上各种"指南"和" ...
- 数据仓库模型之CDM、LDM与PDM的区别
在数据仓库建设中,概念数据模型设计与逻辑数据模型设计.物理数据模型设计是数据库及数据仓库模型设计的三个主要步骤. conceptual data model 概念数据模型是最终用户对数据存储的看法,反 ...