使用Apache PDFBox实现拆分、合并PDF
使用Apache PDFBox实现拆分、合并PDF
问题背景
- 如何拆分PDF?
- 如何合并PDF?
- 如何拆分并合并PDF实现去除PDF的某些页?
Apache PDFBox介绍
Apache PDFBox 库是一个开源的 Java 工具,用于处理 PDF 文件。该项目允许创建新的PDF文档,操作 现有文档以及从文档中提取内容的能力。 PDFBox还包括几个命令行实用程序。PDFBox 发布 在 Apache 许可证下,版本 2.0。
也就是说,我们可以使用PDFBox实现拆分、合并PDF。
在maven项目中添加依赖:
<!--PDF操作-->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox-app</artifactId>
<version>1.8.10</version>
</dependency>
拆分PDF
我们需实现WPS这种按照范围拆分的拆分规则:

- 参考样例
以下是wiki教程中找到的样例,可以实现按照每页拆分成pdf。
public static void main(String[] args) throws IOException {
//Loading an existing PDF document
File file = new File("C:/PdfBox_Examples/sample.pdf");
PDDocument document = PDDocument.load(file);
//Instantiating Splitter class
Splitter splitter = new Splitter();
//splitting the pages of a PDF document
List<PDDocument> Pages = splitter.split(document);
//Creating an iterator
Iterator<PDDocument> iterator = Pages.listIterator();
//Saving each page as an individual document
int i = 1;
while(iterator.hasNext()) {
PDDocument pd = iterator.next();
pd.save("C:/PdfBox_Examples/sample"+ i++ +".pdf");
}
System.out.println("Multiple PDF’s created");
document.close();
}
org.apache.pdfbox.util.Splitter类
Splitter 类有三个拆分相关的参数
private int splitAtPage = 1;
private int startPage = -2147483648;
private int endPage = 2147483647;
分别代表拆分的页数范围,开始拆分的页数,结束拆分的页数。
也就是说,我们可以通过实现设置splitter的相关参数(如splitter.setStartPage(12)等)来实现按照范围拆分的功能。
- 匹配拆分规则
建立SplitterDTO
/**
* Splitter类的配置
*/
@Data
class SplitterDTO {
private int splitAtPage;
private int startPage;
private int endPage;
}
使用正则表达式校验按照范围拆分的拆分规则,将其参数保存在List<SplitterDTO>中:
// m-n 例如 3-5,拆分第三到第五页的pdf
private static final String ruleOne = "^[1-9]\\d*-[1-9]\\d*$";
// m 例如 7,拆分第七页的pdf
private static final String ruleTwo = "^[1-9]\\d*$";
/**
* 正则校验匹配 拆分规则
* @param splitRule 拆分规则
* @return
*/
private List<SplitterDTO> matchByRegex(String splitRule) {
List<SplitterDTO> result = new ArrayList<>();
String[] splits = splitRule.split(",");
for (String split : splits) {
SplitterDTO dto = new SplitterDTO();
if (split.matches(ruleOne)) {
String[] nums = split.split("-");
dto.setStartPage(Integer.parseInt(nums[0]));
dto.setEndPage(Integer.parseInt(nums[1]));
// 拆分的长度
dto.setSplitAtPage(dto.getEndPage() - dto.getStartPage() + 1);
result.add(dto);
} else if (split.matches(ruleTwo)) {
dto.setStartPage(Integer.parseInt(split));
dto.setEndPage(Integer.parseInt(split));
dto.setSplitAtPage(1);
result.add(dto);
} else {
System.out.println("错误的规则:" + split);
}
}
return result;
}
- 根据拆分规则拆分PDF
根据拆分规则开始拆分PDF并保存为pdf。
/**
* 拆分pdf
* @param sourcePdf 源pdf(路径+文件名+文件后缀)
* @param splitPath 拆分后的文件路径
* @param splitFileName 拆分后的文件名(不含后缀)
* @param splitterDTOS 拆分规则
* @return finalPdfs 最终拆分成的pdf
*/
private List<String> spitPdf(String sourcePdf, String splitPath, String splitFileName, List<SplitterDTO> splitterDTOS) throws IOException, COSVisitorException {
List<String> finalPdfs = new ArrayList<>();
int j = 1;
String splitPdf = splitPath + "\\" + splitFileName + "_";
for (SplitterDTO splitterDTO : splitterDTOS) {
// Loading an existing PDF document
File file = new File(sourcePdf);
PDDocument document = PDDocument.load(file);
// Instantiating Splitter class
Splitter splitter = new Splitter();
splitter.setStartPage(splitterDTO.getStartPage());
splitter.setSplitAtPage(splitterDTO.getSplitAtPage());
splitter.setEndPage(splitterDTO.getEndPage());
// splitting the pages of a PDF document
List<PDDocument> Pages = splitter.split(document);
// Creating an iterator
Iterator<PDDocument> iterator = Pages.listIterator();
// Saving each page as an individual document
while(iterator.hasNext()) {
PDDocument pd = iterator.next();
String pdfName = splitPdf+ j++ +".pdf";
pd.save(pdfName);
finalPdfs.add(pdfName);
}
// System.out.println("Multiple PDF’s created");
document.close();
}
return finalPdfs;
}
- 拆分测试
public static void main(String[] args) throws Exception {
// 拆分规则:如拆分成1-4,5,以及8三个pdf
String splitRule = "1-4,5,8";
String sourcePdf = "D:\\BaiduNetdiskDownload\\test\\测试用pdf.pdf";
// 拆分后pdf所放的文件夹
String splitPath = "D:\\BaiduNetdiskDownload\\test";
// 拆分后的文件名
String splitFileName = UUID.randomUUID().toString().replace("-", "");
/**
* 1、拆分
*/
PdfUtils pdfUtils = new PdfUtils();
List<SplitterDTO> splitterDTOS = pdfUtils.matchByRegex(splitRule);
List<String> pdfList = pdfUtils.spitPdf(sourcePdf, splitPath, splitFileName, splitterDTOS);
System.out.println("pdf文件拆分成功------------");
pdfList.forEach(System.out::println);
}
控制台输出结果:
pdf文件拆分成功------------
D:\BaiduNetdiskDownload\test\a5f1b001f2d64a75ac63e75bdb4809e6_1.pdf
D:\BaiduNetdiskDownload\test\a5f1b001f2d64a75ac63e75bdb4809e6_2.pdf
D:\BaiduNetdiskDownload\test\a5f1b001f2d64a75ac63e75bdb4809e6_3.pdf
对应文件夹生成三个pdf文件:
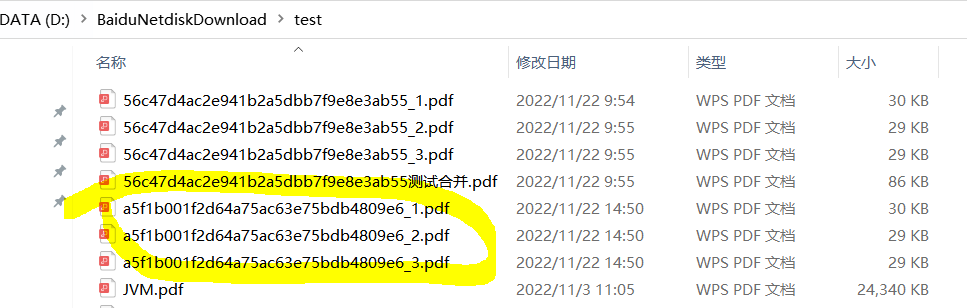
合并PDF
- 代码
/**
* 合并PDF
* @param inputStreams 需合并的pdf文件流
* @param bothPath 合并后的pdf文件路径
* @param destinationFileName 合并后的pdf文件名
*/
public static void MergePdf(List<InputStream> inputStreams, String bothPath, String destinationFileName) throws Exception {
// org.apache.pdfbox.util.PDFMergerUtility:pdf合并工具类
PDFMergerUtility mergePdf = new PDFMergerUtility();
File file = new File(bothPath);
if (!file.exists()) {
file.mkdirs();
}
mergePdf.addSources(inputStreams);
// 设置合并生成pdf文件名称
mergePdf.setDestinationFileName(bothPath + File.separator + destinationFileName);
// 合并PDF
mergePdf.mergeDocuments();
for (InputStream in : inputStreams) {
if (in != null) {
in.close();
}
}
}
- 合并测试
public static void main(String[] args) throws Exception {
/**
* 合并
*/
// 合并pdf生成的文件名
String destinationFileName = DateUtils.format(new Date());
// 需要合并的PDF文件
List<InputStream> inputStreams = new ArrayList<>();
inputStreams.add(new FileInputStream(new File("D:\\ToPDF\\pdf\\水印冲鸭.pdf")));
inputStreams.add(new FileInputStream(new File("D:\\ToPDF\\pdf\\testtest.pdf")));
// 合并后pdf存放路径
String bothPath = "D:\\ToPDF\\pdf";
MergePdf(inputStreams, bothPath, destinationFileName+"测试合并.pdf");
System.out.println("pdf文件合并成功");
}
控制台输出结果:
pdf文件合并成功
对应文件夹生成合并的pdf文件:
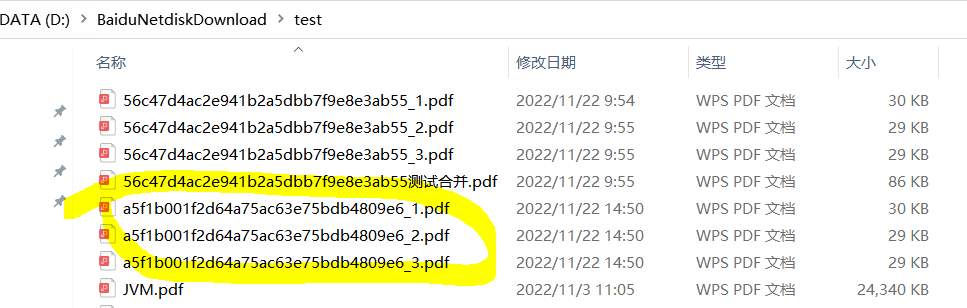
拆分 + 合并
- 测试代码
public static void main(String[] args) throws Exception {
// 拆分规则:如拆分成1-4,5,以及8三个pdf
String splitRule = "1-4,5,8";
String sourcePdf = "D:\\BaiduNetdiskDownload\\test\\测试用pdf.pdf";
// 拆分后pdf所放的文件夹
String splitPath = "D:\\BaiduNetdiskDownload\\test";
// 拆分后的文件名
String splitFileName = UUID.randomUUID().toString().replace("-", "");
/**
* 1、拆分
*/
PdfUtils pdfUtils = new PdfUtils();
List<SplitterDTO> splitterDTOS = pdfUtils.matchByRegex(splitRule);
List<String> pdfList = pdfUtils.spitPdf(sourcePdf, splitPath, splitFileName, splitterDTOS);
System.out.println("pdf文件拆分成功------------");
pdfList.forEach(System.out::println);
/**
* 2、合并
*/
// 合并pdf生成的文件名
String destinationFileName = splitFileName;
// 需要合并的PDF文件
List<InputStream> inputStreams = new ArrayList<>();
for (String pdf : pdfList) {
inputStreams.add(new FileInputStream(new File(pdf)));
}
// 合并后pdf存放路径
String bothPath = "D:\\BaiduNetdiskDownload\\test";
MergePdf(inputStreams, bothPath, destinationFileName + "测试合并.pdf");
System.out.println("pdf文件合并成功-----------");
}
- 测试结果
控制台输出结果:
pdf文件拆分成功------------
D:\BaiduNetdiskDownload\test\a5f1b001f2d64a75ac63e75bdb4809e6_1.pdf
D:\BaiduNetdiskDownload\test\a5f1b001f2d64a75ac63e75bdb4809e6_2.pdf
D:\BaiduNetdiskDownload\test\a5f1b001f2d64a75ac63e75bdb4809e6_3.pdf
pdf文件合并成功-----------
对应文件夹生成拆分后以及合并的pdf文件:
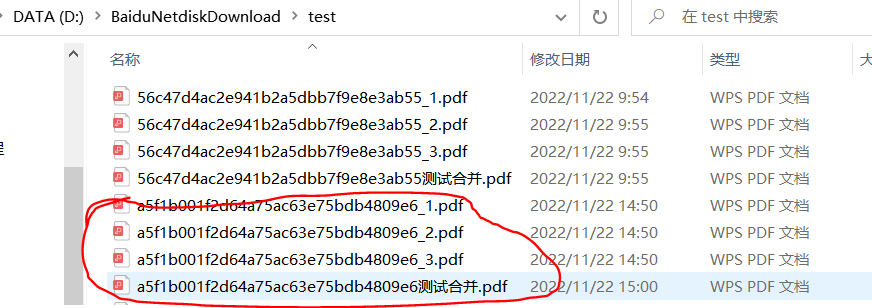
完整代码
package com.example.demo.utils;
import lombok.Data;
import org.apache.pdfbox.exceptions.COSVisitorException;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.util.PDFMergerUtility;
import org.apache.pdfbox.util.Splitter;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.*;
/**
* @Author 似有风中泣
* @Description 操作PDF类
* @Data 2022/6/27 16:18
* @Version 1.0
*/
public class PdfUtils {
// m-n 例如 3-5,拆分第三到第五页的pdf
private static final String ruleOne = "^[1-9]\\d*-[1-9]\\d*$";
// m 例如 7,拆分第七页的pdf
private static final String ruleTwo = "^[1-9]\\d*$";
public static void main(String[] args) throws Exception {
// 拆分规则:如拆分成1-4,5,以及8三个pdf
String splitRule = "1-4,5,8";
String sourcePdf = "D:\\BaiduNetdiskDownload\\test\\测试用pdf.pdf";
// 拆分后pdf所放的文件夹
String splitPath = "D:\\BaiduNetdiskDownload\\test";
// 拆分后的文件名
String splitFileName = UUID.randomUUID().toString().replace("-", "");
/**
* 1、拆分
*/
PdfUtils pdfUtils = new PdfUtils();
List<SplitterDTO> splitterDTOS = pdfUtils.matchByRegex(splitRule);
List<String> pdfList = pdfUtils.spitPdf(sourcePdf, splitPath, splitFileName, splitterDTOS);
System.out.println("pdf文件拆分成功------------");
pdfList.forEach(System.out::println);
/**
* 2、合并
*/
// 合并pdf生成的文件名
String destinationFileName = splitFileName;
// 需要合并的PDF文件
List<InputStream> inputStreams = new ArrayList<>();
for (String pdf : pdfList) {
inputStreams.add(new FileInputStream(new File(pdf)));
}
// 合并后pdf存放路径
String bothPath = "D:\\BaiduNetdiskDownload\\test";
MergePdf(inputStreams, bothPath, destinationFileName + "测试合并.pdf");
System.out.println("pdf文件合并成功-----------");
}
/**
* 正则校验匹配 拆分规则
* @param splitRule 拆分规则
* @return
*/
private List<SplitterDTO> matchByRegex(String splitRule) {
List<SplitterDTO> result = new ArrayList<>();
String[] splits = splitRule.split(",");
for (String split : splits) {
SplitterDTO dto = new SplitterDTO();
if (split.matches(ruleOne)) {
String[] nums = split.split("-");
dto.setStartPage(Integer.parseInt(nums[0]));
dto.setEndPage(Integer.parseInt(nums[1]));
// 拆分的长度
dto.setSplitAtPage(dto.getEndPage() - dto.getStartPage() + 1);
result.add(dto);
} else if (split.matches(ruleTwo)) {
dto.setStartPage(Integer.parseInt(split));
dto.setEndPage(Integer.parseInt(split));
dto.setSplitAtPage(1);
result.add(dto);
} else {
System.out.println("错误的规则:" + split);
}
}
return result;
}
/**
* 拆分pdf
* @param sourcePdf 源pdf(路径+文件名+文件后缀)
* @param splitPath 拆分后的文件路径
* @param splitFileName 拆分后的文件名(不含后缀)
* @param splitterDTOS 拆分规则
* @return finalPdfs 最终拆分成的pdf
*/
private List<String> spitPdf(String sourcePdf, String splitPath, String splitFileName, List<SplitterDTO> splitterDTOS) throws IOException, COSVisitorException {
List<String> finalPdfs = new ArrayList<>();
int j = 1;
String splitPdf = splitPath + "\\" + splitFileName + "_";
for (SplitterDTO splitterDTO : splitterDTOS) {
// Loading an existing PDF document
File file = new File(sourcePdf);
PDDocument document = PDDocument.load(file);
// Instantiating Splitter class
Splitter splitter = new Splitter();
splitter.setStartPage(splitterDTO.getStartPage());
splitter.setSplitAtPage(splitterDTO.getSplitAtPage());
splitter.setEndPage(splitterDTO.getEndPage());
// splitting the pages of a PDF document
List<PDDocument> Pages = splitter.split(document);
// Creating an iterator
Iterator<PDDocument> iterator = Pages.listIterator();
// Saving each page as an individual document
while(iterator.hasNext()) {
PDDocument pd = iterator.next();
String pdfName = splitPdf+ j++ +".pdf";
pd.save(pdfName);
finalPdfs.add(pdfName);
}
// System.out.println("Multiple PDF’s created");
document.close();
}
return finalPdfs;
}
/**
* 合并PDF
* @param inputStreams 需合并的pdf文件流
* @param bothPath 合并后的pdf文件路径
* @param destinationFileName 合并后的pdf文件名
*/
public static void MergePdf(List<InputStream> inputStreams, String bothPath, String destinationFileName) throws Exception {
// pdf合并工具类
PDFMergerUtility mergePdf = new PDFMergerUtility();
File file = new File(bothPath);
if (!file.exists()) {
file.mkdirs();
}
mergePdf.addSources(inputStreams);
// 设置合并生成pdf文件名称
mergePdf.setDestinationFileName(bothPath + File.separator + destinationFileName);
// 合并PDF
mergePdf.mergeDocuments();
for (InputStream in : inputStreams) {
if (in != null) {
in.close();
}
}
}
}
/**
* Splitter类的配置
*/
@Data
class SplitterDTO {
private int splitAtPage;
private int startPage;
private int endPage;
}
参考:
https://iowiki.com/pdfbox/pdfbox_splitting_a_pdf_document.html
https://github.com/apache/pdfbox
https://javadoc.io/doc/org.apache.pdfbox/pdfbox/1.8.10/index.html
使用Apache PDFBox实现拆分、合并PDF的更多相关文章
- Apache PDFbox开发指南之PDF文档读取
转载请注明来源:http://blog.csdn.net/loongshawn/article/details/51542309 相关文章: <Apache PDFbox开发指南之PDF文本内容 ...
- PDF 拆分/合并
不会真的有人会去下载那些广告免费,实则要收会员费的黑心软件来进行PDF的拆分合并吧??? 在下载两个均不能免费实现PDF自由拆分.合并,以及PDF打印方式会增加文件大小的情况下,一个合格的程序员肯定不 ...
- APache PDFbox API使用(1)----简单介绍
因为项目的须要.近期在学习APache PDFbox API,Apache PDFbox API是Apache Java 开源社区中个一个项目,其受Apache 版权 V2的保护,其提供了以下的功能 ...
- java合并pdf
一.开发准备 下载pdfbox-app-1.7.1.jar包;下载地址:http://download.csdn.net/detail/yanning1314/4852276 二.简单小例子 在开发中 ...
- Java文件操作系列[1]——PDFBox实现分页提取PDF文本
需求:用java分页提取PDF文本. PDFBox是一个很好的可以满足上述需求的开源工具. 1.PDF文档结构 要解析PDF文本,我们首先要了解PDF文件的结构. 关于PDF文档,最重要的几点: 一, ...
- apache pdfbox
转 http://www.blogjava.net/sxyx2008/archive/2010/07/23/326890.html 轻松使用apache pdfbox将pdf文件生成图 近期在项目中使 ...
- C# / VB.NET合并PDF指定页
在前面的文章中,我们已经知道如何合并.拆分多个PDF文件,在这篇文章中的合并.拆分PDF文档主要是以方便文档管理的目的来操作文档,在文档查阅.管理及存储上很方便实用.但是我们如果想要合并多个文档中的部 ...
- Linux下分割、合并PDF(pdftk),用于Linux系统的6款最佳PDF页面裁剪工具
Linux下分割.合并PDF(pdftk),用于Linux系统的6款最佳PDF页面裁剪工具 Linux下分割.合并PDF(pdftk) pdftk http://www.pdflabs.com/doc ...
- 利用pdfbox和poi抽取pdf、doc以及docx格式的内容
使用pdfbox1.5.0抽取pdf格式文档内容,使用poi3.7抽取doc及docx文档内容: /** * Created by yan.shi on 2017/9/25. */ import or ...
- C#/VB.NET 合并PDF页面
本文以C#及vb.net代码为例介绍如何来实现合并PDF页面内容.本文中的合并并非将两个文档简单合并为一个文档,而是将多个页面内容合并到一个页面,目的是减少页面上的空白区域,使页面布局更为紧凑.合理. ...
随机推荐
- Cannot access child value on Newtonsoft.Json.Linq.JValue
开发项目框架为.net framework,遇到此问题原因是笔者在做接口转发时接口返回类型直接定义为了object类型,这导致格式化返回结果时出现如标题异常,具体代码如下 try { var resu ...
- 郁金香-了解MFC信息机制
控件的事件 窗口的信息
- Redis 源码解读之 Rehash 的调用时机
Redis 源码解读之 Rehash 的调用时机 背景和问题 本文想要解决的问题 什么时机触发 Rehash 操作? 什么时机实际执行 Rehash 函数? 结论 什么时机触发 Rehash 操作? ...
- JZOJ 3184. 【GDOI2013模拟7】最大异或和
最大异或和 可持久化字典树经典题 题目网上自己找 来波模板 \(Code\) #include<cstdio> #include<iostream> using namespa ...
- Median String
You are given two strings ss and tt, both consisting of exactly kk lowercase Latin letters, ss is le ...
- pdf地址展示成Swiper轮播方式-复制链接
1.安装vue-pdf插件,swiper插件.clipboard npm install vue-pdf -snpm install swiper -Snpm install clipborad -S ...
- PostGIS之空间索引
1. 概述 PostGIS 是PostgreSQL数据库一个空间数据库扩展,它添加了对地理对象的支持,允许在 SQL 中运行空间查询 PostGIS官网:About PostGIS | PostGIS ...
- 一键接入 ChatGPT,让你的QQ群变得热闹起来
目录 项目效果 安装环境 配置文件 启动Mirai 启动ChatGPT 项目效果 ChatGPT 的出现对于人们的生活和工作都有着重要的影响,作为一个强大的自然语言处理模型,可以理解和生成自然语言,所 ...
- Jmeter 快速生成测试报告
我们使用Jmeter工具进行接口测试或性能测试后一般是通过察看结果数.聚合报告等监听器来查看响应结果.一.Jmeter配置 首先要保证jmeter命令是ok的,如果你在cmd中输入jmeter -v, ...
- QP之QEP事件分配流程分析
*********************************1*********************************** QActive *AO_Blinky = &l_bl ...