6张图为你分析Kafka Producer 消息缓存模型
摘要:发送消息的时候, 当Broker挂掉了,消息体还能写入到消息缓存中吗?
本文分享自华为云社区《图解Kafka Producer 消息缓存模型》,作者:石臻臻的杂货铺。
在阅读本文之前, 希望你可以思考一下下面几个问题, 带着问题去阅读文章会获得更好的效果。
- 发送消息的时候, 当Broker挂掉了,消息体还能写入到消息缓存中吗?
- 当消息还存储在缓存中的时候, 假如Producer客户端挂掉了,消息是不是就丢失了?
- 当最新的Producer Batch还有空余的内存,但是接下来的一条消息很大,不足以加上上一个Batch中,会怎么办呢?
- 那么创建Producer Batch的时候,应该分配多少的内存呢?
什么是消息累加器Record Accumulator
kafka为了提高Producer客户端的发送吞吐量和提高性能,选择了将消息暂时缓存起来,等到满足一定的条件, 再进行批量发送, 这样可以减少网络请求,提高吞吐量。
而缓存这个消息的就是Record Accumulator类.
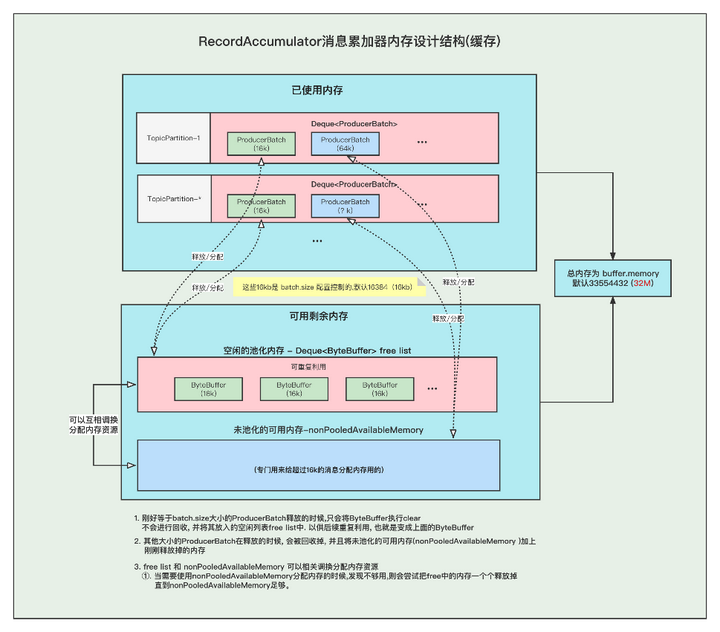
上图就是整个消息存放的缓存模型,我们接下来一个个来讲解。
消息缓存模型
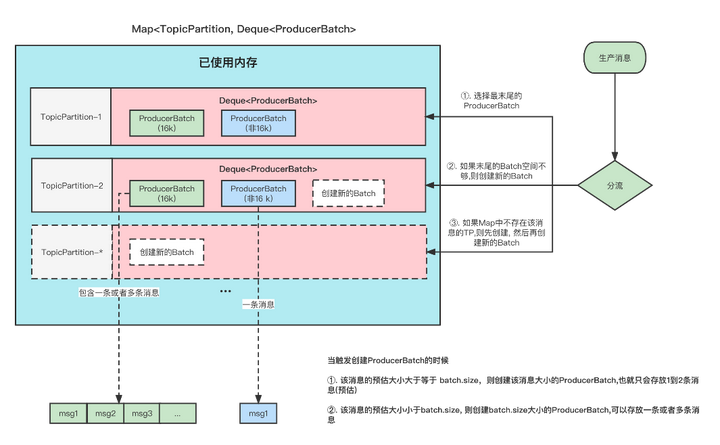
上图表示的就是 消息缓存的模型, 生产的消息就是暂时存放在这个里面。
- 每条消息,我们按照TopicPartition维度,把他们放在不同的Deque<ProducerBatch> 队列里面。
TopicPartition相同,会在相同Deque<ProducerBatch> 的里面。 - ProducerBatch : 表示同一个批次的消息, 消息真正发送到Broker端的时候都是按照批次来发送的,
这个批次可能包含一条或者多条消息。 - 如果没有找到消息对应的ProducerBatch队列, 则创建一个队列。
- 找到ProducerBatch队列队尾的Batch,发现Batch还可以塞下这条消息,则将消息直接塞到这个Batch中
- 找到ProducerBatch队列队尾的Batch,发现Batch中剩余内存,不够塞下这条消息,则会创建新的Batch
- 当消息发送成功之后, Batch会被释放掉。
ProducerBatch的内存大小
那么创建ProducerBatch的时候,应该分配多少的内存呢?
先说结论: 当消息预估内存大于batch.size的时候,则按照消息预估内存创建, 否则按照batch.size的大小创建(默认16k).
我们来看一段代码,这段代码就是在创建ProducerBatch的时候预估内存的大小
RecordAccumulator#append
/**
* 公众号: 石臻臻的杂货铺
* 微信:szzdzhp001
**/
// 找到 batch.size 和 这条消息在batch中的总内存大小的 最大值
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
// 申请内存
buffer = free.allocate(size, maxTimeToBlock);
- 假设当前生产了一条消息为M, 刚好消息M找不到可以存放消息的ProducerBatch(不存在或者满了),那么这个时候就需要创建一个新的ProducerBatch了
- 预估消息的大小 跟batch.size 默认大小16384(16kb). 对比,取最大值用于申请的内存大小的值。
原文地址:图解Kafka Producer 消息缓存模型
那么, 这个消息的预估是如何预估的?纯粹的是消息体的大小吗?
DefaultRecordBatch#estimateBatchSizeUpperBound
预估需要的Batch大小,是一个预估值,因为没有考虑压缩算法从额外开销
/**
* 使用给定的键和值获取只有一条记录的批次大小的上限。
* 这只是一个估计,因为它没有考虑使用的压缩算法的额外开销。
**/
static int estimateBatchSizeUpperBound(ByteBuffer key, ByteBuffer value, Header[] headers) {
return RECORD_BATCH_OVERHEAD + DefaultRecord.recordSizeUpperBound(key, value, headers);
}
- 预估这个消息M的大小 + 一个RECORD_BATCH_OVERHEAD的大小
- RECORD_BATCH_OVERHEAD是一个Batch里面的一些基本元信息,总共占用了 61B
- 消息M的大小也并不是单单的只有消息体的大小,总大小=(key,value,headers)的大小+MAX_RECORD_OVERHEAD
- MAX_RECORD_OVERHEAD :一条消息头最大占用空间, 最大值为21B
也就是说创建一个ProducerBatch,最少就要83B .
比如我发送一条消息 " 1 " , 预估得到的大小是 86B, 跟batch.size(默认16384) 相比取最大值。 那么申请内存的时候取最大值 16384 。
内存分配
我们都知道RecordAccumulator里面的缓存大小是一开始定义好的, 由buffer.memory控制, 默认33554432 (32M)
当生产的速度大于发送速度的时候,就可能出现Producer写入阻塞。
而且频繁的创建和释放ProducerBatch,会导致频繁GC, 所有kafka中有个缓存池的概念,这个缓存池会被重复使用,但是只有固定( batch.size)的大小才能够使用缓存池。
PS:以下16k指得是 batch.size的默认值.
原文地址:图解Kafka Producer 消息缓存模型
Batch的创建和释放
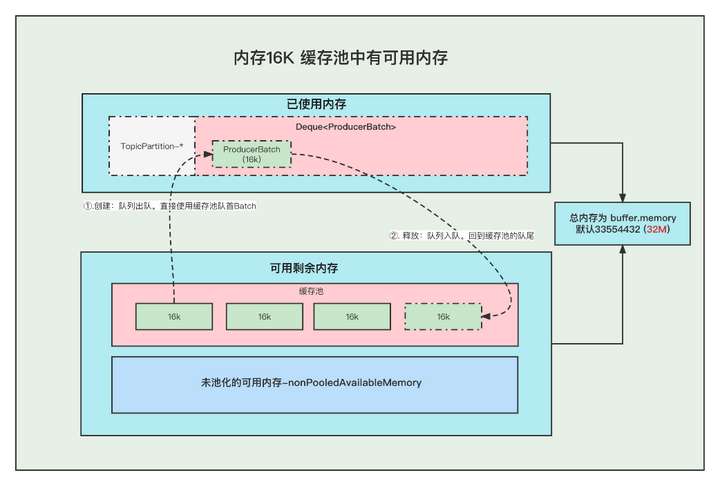
1. 内存16K 缓存池中有可用内存
①. 创建Batch的时候, 会去缓存池中,获取队首的一块内存ByteBuffer 使用。
②. 消息发送完成,释放Batch, 则会把这个ByteBuffer,放到缓存池的队尾中,并且调用ByteBuffer.clear 清空数据。以便下次重复使用
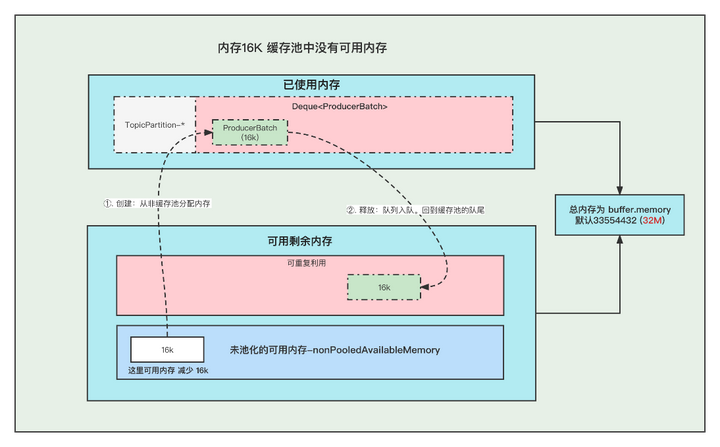
2. 内存16K 缓存池中无可用内存
①. 创建Batch的时候, 去非缓存池中的内存获取一部分内存用于创建Batch. 注意:这里说的获取内存给Batch, 其实就是让 非缓存池nonPooledAvailableMemory 减少 16K 的内存, 然后Batch正常创建就行了, 不要误以为好像真的发生了内存的转移。
②. 消息发送完成,释放Batch, 则会把这个ByteBuffer,放到缓存池的队尾中,并且调用ByteBuffer.clear 清空数据, 以便下次重复使用
原文地址:图解Kafka Producer 消息缓存模型
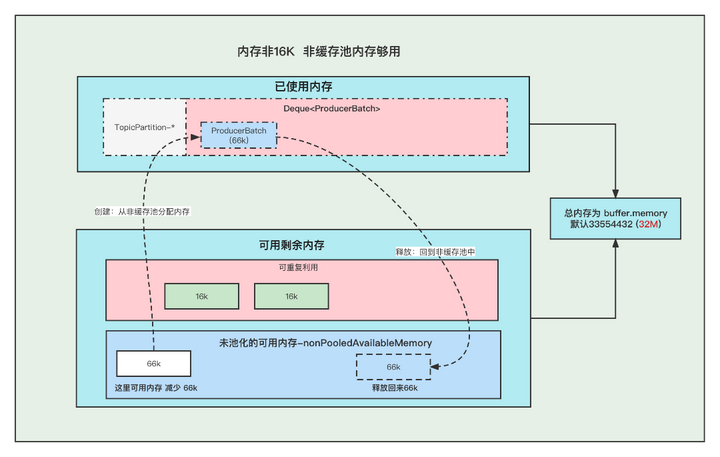
3. 内存非16K 非缓存池中内存够用
①. 创建Batch的时候, 去非缓存池(nonPooledAvailableMemory)内存获取一部分内存用于创建Batch. 注意:这里说的获取内存给Batch, 其实就是让 非缓存池(nonPooledAvailableMemory) 减少对应的内存, 然后Batch正常创建就行了, 不要误以为好像真的发生了内存的转移。
②. 消息发送完成,释放Batch, 纯粹的是在非缓存池(nonPooledAvailableMemory)中加上刚刚释放的Batch内存大小。 当然这个Batch会被GC掉
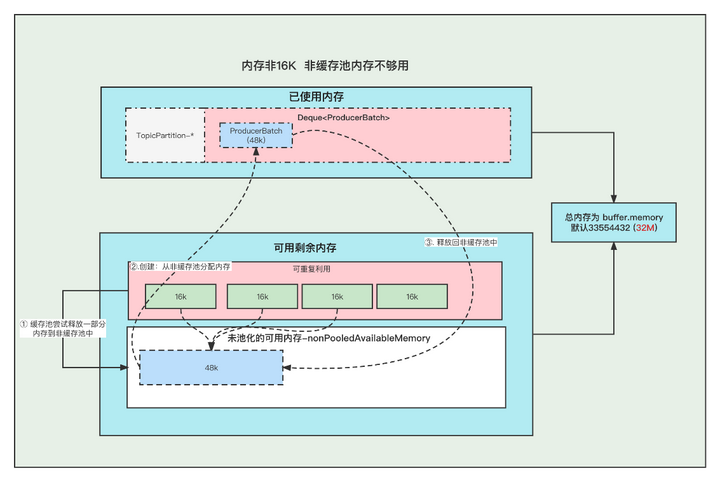
4. 内存非16K 非缓存池内存不够用
①. 先尝试将 缓存池中的内存一个一个释放到 非缓存池中, 直到非缓存池中的内存够用与创建Batch了
②. 创建Batch的时候, 去非缓存池(nonPooledAvailableMemory)内存获取一部分内存用于创建Batch. 注意:这里说的获取内存给Batch, 其实就是让 非缓存池(nonPooledAvailableMemory) 减少对应的内存, 然后Batch正常创建就行了, 不要误以为好像真的发生了内存的转移。
③. 消息发送完成,释放Batch, 纯粹的是在非缓存池(nonPooledAvailableMemory)中加上刚刚释放的Batch内存大小。 当然这个Batch会被GC掉
例如: 下面我们需要创建 48k的batch, 因为超过了16k,所以需要在非缓存池中分配内存, 但是非缓存池中当前可用内存为0 , 分配不了, 这个时候就会尝试去 缓存池里面释放一部分内存到 非缓存池。
释放第一个ByteBuffer(16k) 不够,则继续释放第二个,直到释放了3个之后总共48k,发现内存这时候够了, 再去创建Batch。
注意:这里我们涉及到的 非缓存池中的内存分配, 仅仅指的的内存数字的增加和减少。
问题和答案
1、发送消息的时候, 当Broker挂掉了,消息体还能写入到消息缓存中吗?
当Broker挂掉了,Producer会提示下面的警告️, 但是发送消息过程中
这个消息体还是可以写入到 消息缓存中的,也仅仅是写到到缓存中而已。
WARN [Producer clientId=console-producer] Connection to node 0 (/172.23.164.192:9090) could not be established. Broker may not be available

2、当最新的ProducerBatch还有空余的内存,但是接下来的一条消息很大,不足以加上上一个Batch中,会怎么办呢?
那么会创建新的ProducerBatch。
3、那么创建ProducerBatch的时候,应该分配多少的内存呢?
触发创建ProducerBatch的那条消息预估大小大于batch.size ,则以预估内存创建。
否则,以batch.size创建。
还有一个问题供大家思考:
当消息还存储在缓存中的时候, 假如Producer客户端挂掉了,消息是不是就丢失了?
6张图为你分析Kafka Producer 消息缓存模型的更多相关文章
- Kafka生成消息时的3种分区策略
摘要:KafkaProducer在发送消息的时候,需要指定发送到哪个分区, 那么这个分区策略都有哪些呢? 本文分享自华为云社区<Kafka生产者3中分区分配策略>,作者:石臻臻的杂货铺. ...
- Kafka Producer相关代码分析【转】
来源:https://www.zybuluo.com/jewes/note/63925 @jewes 2015-01-17 20:36 字数 1967 阅读 1093 Kafka Producer相关 ...
- 关于高并发下kafka producer send异步发送耗时问题的分析
最近开发网关服务的过程当中,需要用到kafka转发消息与保存日志,在进行压测的过程中由于是多线程并发操作kafka producer 进行异步send,发现send耗时有时会达到几十毫秒的阻塞,很大程 ...
- 一张图了解Spring Cloud微服务架构
Spring Cloud作为当下主流的微服务框架,可以让我们更简单快捷地实现微服务架构.Spring Cloud并没有重复制造轮子,它只是将目前各家公司开发的比较成熟.经得起实际考验的服务框架组合起来 ...
- Kafka producer介绍
Kafka 0.9版本正式使用Java版本的producer替换了原Scala版本的producer.本文着重讨论新版本producer的设计原理以及基本的使用方法. 新版本Producer 首先明确 ...
- Kafka设计解析(十四)Kafka producer介绍
转载自 huxihx,原文链接 Kafka producer介绍 Kafka 0.9版本正式使用Java版本的producer替换了原Scala版本的producer.本文着重讨论新版本produce ...
- 源码分析 Kafka 消息发送流程(文末附流程图)
温馨提示:本文基于 Kafka 2.2.1 版本.本文主要是以源码的手段一步一步探究消息发送流程,如果对源码不感兴趣,可以直接跳到文末查看消息发送流程图与消息发送本地缓存存储结构. 从上文 初识 Ka ...
- 源码分析Kafka 消息拉取流程
目录 1.KafkaConsumer poll 详解 2.Fetcher 类详解 本节重点讨论 Kafka 的消息拉起流程. @(本节目录) 1.KafkaConsumer poll 详解 消息拉起主 ...
- 干货 | 45张图庖丁解牛18种Queue,你知道几种?
在讲<21张图讲解集合的线程不安全>那一篇,我留了一个彩蛋,就是Queue(队列)还没有讲,这次我们重点来看看Java中的Queue家族,总共涉及到18种Queue.这篇恐怕是市面上最全最 ...
随机推荐
- Ext原码学习之lang-Object.js
// JavaScript Document (function(){ var TemplateClass = function(){}, ExtObject = Ext.Object = { cha ...
- 【论文阅读笔记】-针对RSA的短解密指数的密码学分析(Cryptanalysis of Short RSA Secret Exponents)
目录 1. 介绍 polynomially larger 2. 连分数背景知识 3. 连分数算法 4. 连分数算法在RSA中的应用 5. 例子 6. 对RSA连分数攻击的反制 7. 对于攻击的改进 8 ...
- Git配置ssh免密登录
一.在用户目录下的.ssh目录下生成秘钥与公钥 如果用户目录下没有.ssh目录,则需要新建一个 cd ~/.ssh ssh-keygen -t rsa 一路回车即可 注:国内很多博客都会带上-C &q ...
- postman中环境变量的设置方法、使用方法和实际中常见使用场景
文中共介绍2种添加环境变量的方法.2种使用环境变量的方法,以及不同方法的适用范围. 文中给出了环境变量的两种常见使用场景:切换环境.动态参数关联(前一个请求的响应作为下一个请求的入参) 2种添加环境变 ...
- 干工第一天,这个api超时优化把我干趴下了!
近日我司进行云服务商更换,恰逢由我负责新上线的三方调用 api 维护管理,在将服务由阿里云部署到腾讯云过程中,我们压测发现在腾讯云调用京东接口时 TP999 抖动十分剧烈,尽管业务层有重试操作但是超时 ...
- Linux基础:VLAN篇
一.二层基础知识 1.1 vlan介绍 本小节重点: vlan的含义 vlan的类型 交换机端口类型 vlan的不足 1.1.1 vlan的含义 局域网LAN的发展是VLAN产生的基础,因而先介绍一下 ...
- Solution -「LOCAL」舟游
\(\mathcal{Description}\) \(n\) 中卡牌,每种三张.对于一次 \(m\) 连抽,前 \(m-1\) 次抽到第 \(i\) 种的概率是 \(p_i\),第 \(m\) ...
- 【论文考古】Training a 3-Node Neural Network is NP-Complete
今天看到一篇1988年的老文章谈到了训练一个简单网络是NPC问题[1].也就是下面的网络结构,在线性激活函数下,如果要找到参数使得输入数据的标签估计准确,这个问题是一个NPC问题.这个文章的意义在于宣 ...
- 论文解读(DAEGC)《Improved Deep Embedded Clustering with Local Structure Preservation》
Paper Information Title:<Attributed Graph Clustering: A Deep Attentional Embedding Approach>Au ...
- 使用SpringBoot整合MybatisPlus出现 : java.lang.IllegalStateException: Unable to find a @SpringBootConfiguration, you need to use @ContextConfiguration or @SpringBootTest(classes=...) with your test
解决方案一: 将测试类的包路径改为和主启动类的一致 解决方法二: 不想改测试类的路径 就在测试类上添加要测试的类的classes