JAVA中使用最广泛的本地缓存?Ehcache的自信从何而来 —— 感受来自Ehcache的强大实力

大家好,又见面了。
本文是笔者作为掘金技术社区签约作者的身份输出的缓存专栏系列内容,将会通过系列专题,讲清楚缓存的方方面面。如果感兴趣,欢迎关注以获取后续更新。
作为《深入理解缓存原理与实战设计》系列专栏,前面几篇文章中我们详细的介绍与探讨了Guava Cache与Caffeine的实现、特性与使用方式。提到JAVA本地缓存框架,还有一个同样无法被忽视的强大存在 —— Ehcache!它最初是由Greg Luck于2003年开始开发,截止目前,Ehcache已经演进到了3.10.0版本,各方面的能力已经构建的非常完善。Ehcache官网上也毫不谦虚的描述自己是“Java's most widely-used cache”,即JAVA中使用最广泛的缓存,足见Ehcache的强大与自信。

此外,Ehcache还是被Hibernate选中并默认集成的缓存框架,它究竟有什么魅力可以让著名的Hibernate对其青眼有加?它与Caffeine又有啥区别呢?我们实际的业务项目里又该如何取舍呢?带着这些疑问,接下来就来认识下Ehcache,一睹Ehcache那些闪闪发光的优秀特性吧!

Ehcache的闪光特性
支持多级缓存
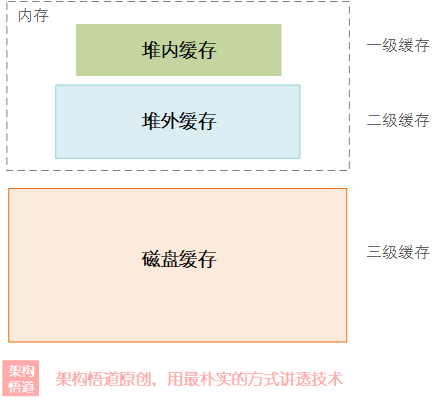
之前文章中我们介绍过的Guava Cache或者是Caffeine,都是纯内存缓存,使用上会受到内存大小的制约,而Ehcache则打破了这一约束。Ehcache2.x时代就已经支持了基于内存和磁盘的二级缓存能力,而演进到Ehcache3.x版本时进一步扩展了此部分能力,增加了对于堆外缓存的支持。此外,结合Ehcache原生支持的集群能力,又可以打破单机的限制,完全解决容量这一制约因素。
综合而言,Ehcache支持的缓存形式就有了如下四种:
- 堆内缓存(heap)
所谓的堆内(heap)缓存,就是我们常规意义上说的内存缓存,严格意义上来说,是指被JVM托管占用的部分内存。内存缓存最大的优势就是具有超快的读写速度,但是不足点就在于容量有限、且无法持久化。
在创建缓存的时候可以指定使用堆内缓存,也可以一并指定堆内缓存允许的最大字节数。
// 指定使用堆内缓存,并限制最大容量为100M
ResourcePoolsBuilder.newResourcePoolsBuilder().heap(100, MemoryUnit.MB);
除了按照总字节大小限制,还可以按照记录数进行约束:
// 指定使用堆内缓存,并限制最大容量为100个Entity记录
ResourcePoolsBuilder.newResourcePoolsBuilder().heap(100, EntryUnit.ENTRIES);
- 堆外缓存(off-heap)
堆外(off-heap)缓存,同样是存储在内存中。其实就是在内存中开辟一块区域,将其当做磁盘进行使用。由于内存的读写速度特别快,所以将数据存储在这个区域,读写上可以获得比本地磁盘读取更优的表现。这里的“堆外”,主要是相对与JVM的堆内存而言的,因为这个区域不在JVM的堆内存中,所以叫堆外缓存。这块的关系如下图示意:

看到这里,不知道大家是否有这么个疑问:既然都是内存中存储,那为何多此一举非要将其划分为堆外缓存呢?直接将这部分的空间类驾到堆内缓存上,不是一样的效果吗?
我们知道JVM会基于GC机制自动的对内存中不再使用的对象进行垃圾回收,而GC的时候对系统性能的影响是非常大的。堆内缓存的数据越多,GC的压力就会越大,对系统性能的影响也会越明显。所以为了降低大量缓存对象的GC回收动作的影响,便出现了off-heap处理方式。在JVM堆外的内存中开辟一块空间,可以像使用本地磁盘一样去使用这块内存区域,这样就既享受了内存的高速读写能力,又避免频繁GC带来的烦恼。
可以在创建缓存的时候,通过offheap方法来指定使用堆外缓存并设定堆外缓存的容量大小,这样当heap缓存容量满之后,其余的数据便会存储到堆外缓存中。
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(100, MemoryUnit.KB) // 堆内缓存100K
.offheap(10, MemoryUnit.MB); // 堆外缓存10M
堆外缓存的时候,offheap的大小设定需要注意两个原则:
- offheap需要大于heap的容量大小(前提是heap大小设定的是字节数而非Entity数)
- offheap大小必须1M以上。
如果设定的时候不满足上述条件,会报错:
Caused by: java.lang.IllegalArgumentException: The value of maxBytesLocalOffHeap is less than the minimum allowed value of 1M. Reconfigure maxBytesLocalOffHeap in ehcache.xml or programmatically.
at org.ehcache.impl.internal.store.offheap.HeuristicConfiguration.<init>(HeuristicConfiguration.java:55)
at org.ehcache.impl.internal.store.offheap.OffHeapStore.createBackingMap(OffHeapStore.java:102)
at org.ehcache.impl.internal.store.offheap.OffHeapStore.access$500(OffHeapStore.java:69)
总结下堆内缓存与堆外缓存的区别与各自优缺点:
堆内缓存是由JVM管理的,在JVM中可以直接去以引用的形式去读取,所以读写的速度会特别高。而且JVM会负责其内容的回收与清理,使用起来比较“省心”。堆外缓存是在内存中划定了一块独立的存储区域,然后可以将这部分内存当做“磁盘”进行使用。需要使用方自行维护数据的清理,读写前需要序列化与反序列化操作,但可以省去GC的影响。
- 磁盘缓存(disk)
当我们需要缓存的数据量特别大、内存容量无法满足需求的时候,可以使用disk磁盘存储来作为补充。相比于内存,磁盘的读写速度显然要慢一些、但是胜在其价格便宜,容量可以足够大。
我们可以在缓存创建的时候,指定使用磁盘缓存,作为堆内缓存或者堆外缓存的补充。
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(10, MemoryUnit.MB)
.offheap(1, MemoryUnit.MB)
.disk(10, MemoryUnit.GB); // 指定使用10G磁盘缓存空间
需要注意这里磁盘的容量设定一定要大于前面的heap以及offHeap的大小,否则会报错:
Exception in thread "main" java.lang.IllegalArgumentException: Tiering Inversion: 'Pool {100 MB offheap}' is not smaller than 'Pool {20 MB disk}'
at org.ehcache.impl.config.ResourcePoolsImpl.validateResourcePools(ResourcePoolsImpl.java:137)
at org.ehcache.config.builders.ResourcePoolsBuilder.<init>(ResourcePoolsBuilder.java:53)
- 集群缓存(Cluster)
作为单机缓存,数据都是存在各个进程内的,在分布式组网系统中,如果缓存数据发生变更,就会出现各个进程节点中缓存数据不一致的问题。为了解决这一问题,Ehcache支持通过集群的方式,将多个分布式节点组网成一个整体,保证相互节点之间的数据同步。
需要注意的是,除了堆内缓存属于JVM堆内部,可以直接通过引用的方式进行访问,其余几种类型都属于JVM外部的数据交互,所以对这部分数据的读写时,需要先进行序列化与反序列化,因此要求缓存的数据对象一定要支持序列化与反序列化。
不同的缓存类型具有不同的运算处理速度,堆内缓存的速度最快,堆外缓存次之,集群缓存的速度最慢。为了兼具处理性能与缓存容量,可以采用多种缓存形式组合使用的方式,构建多级缓存来实现。组合上述几种不同缓存类型然后构建多级缓存的时候,也需要遵循几个约束:
- 多级缓存中必须有堆内缓存,必须按照
堆内缓存 < 堆外缓存 < 磁盘缓存 < 集群缓存的顺序进行组合; - 多级缓存中的容量设定必须遵循
堆内缓存 < 堆外缓存 < 磁盘缓存 < 集群缓存的原则; - 多级缓存中不允许磁盘缓存与集群缓存同时出现;
按照上述原则,可以组合出所有合法的多级缓存类型:
堆内缓存 + 堆外缓存
堆内缓存 + 堆外缓存 + 磁盘缓存
堆内缓存 + 堆外缓存 + 集群缓存
堆内缓存 + 磁盘缓存
堆内缓存 + 集群缓存
支持缓存持久化
常规的基于内存的缓存都有一个通病就是无法持久化,每次重新启动的时候,缓存数据都会丢失,需要重新去构建。而Ehcache则支持使用磁盘来对缓存内容进行持久化保存。
如果需要开启持久化保存能力,我们首先需要在创建缓存的时候先指定下持久化结果存储的磁盘根目录,然后需要指定组合使用磁盘存储的容量,并选择开启持久化数据的能力。
public static void main(String[] args) {
CacheManager cacheManager = CacheManagerBuilder.newCacheManagerBuilder()
.withCache("myCache", CacheConfigurationBuilder.newCacheConfigurationBuilder(Integer.class,
String.class,
ResourcePoolsBuilder.newResourcePoolsBuilder()
.heap(1, MemoryUnit.MB)
.disk(10, MemoryUnit.GB, true)) // 指定需要持久化到磁盘
.build())
.with(CacheManagerBuilder.persistence("d:\\myCache\\")) // 指定持久化磁盘路径
.build(true);
Cache<Integer, String> myCache = cacheManager.getCache("myCache", Integer.class, String.class);
myCache.put(1, "value1");
myCache.put(2, "value2");
System.out.println(myCache.get(2));
cacheManager.close();
}
执行之后,指定的目录里面会留有对应的持久化文件记录:
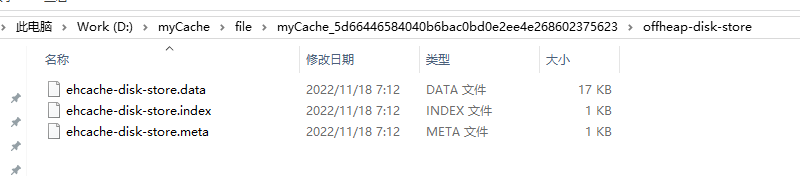
这样在进程重新启动的时候,会自动从持久化文件中读取内容并加载到缓存中,可以直接使用。比如我们将代码修改下,缓存创建完成后不执行put操作,而是直接去读取数据。比如还是上面的这段代码,将put操作注释掉,重新启动执行,依旧可以获取到缓存值。
支持变身分布式缓存
在本专栏开立后的第一篇文章《聊一聊作为高并发系统基石之一的缓存,会用很简单,用好才是技术活》中,我们介绍了下在集群多节点场景下本地缓存经常会出现的一个缓存漂移问题。比如一个互动论坛系统里面,其中一个节点处理了修改请求并同步更新了自己的本地缓存,但是其余节点没有感知到这个变更操作,导致相互之间内存数据不一致,这个时候查询请求就会出现一会正常一会异常的情况。
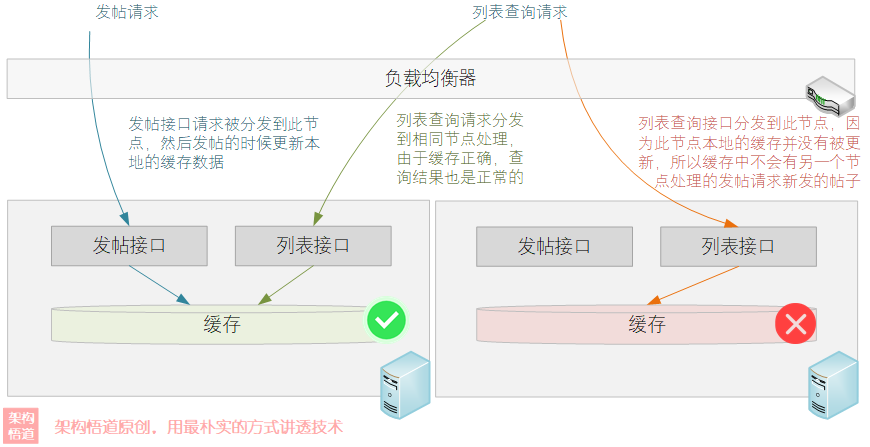
对于分布式系统,或者是集群场景下,并非是本地缓存的主战场。为了保证集群内数据的一致性,很多场景往往就直接选择Redis等集中式缓存。但是集中式缓存也弊端,比如有些数据并不怎么更新、但是每个节点对其依赖度却非常高,如果频繁地去Redis请求交互,又会导致大量的性能损耗在网络IO交互处理上。
针对这种情况,Ehcache给出了一个相对完美的答案:本地 + 集群化策略。即在本地缓存的基础上,将集群内各本地节点组成一个相互连接的网,然后基于某种机制,将一个节点上发生的变更同步给其余节点进行同步更新自身缓存数据,这样就可以实现各个节点的缓存数据一致。
Ehcache提供了多种不同的解决方案,可以将其由本地缓存变身为“分布式缓存”:
RMI组播方式JMS消息方式Cache Server模式JGroup方式Terracotta方式
在下一篇文章中,将专门针对上面的几种方式进行展开介绍。
更灵活和细粒度的过期时间设定
前面我们介绍过的本地缓存框架Caffeine与Guava Cache,它们支持设定过期时间,但是仅允许为设定缓存容器级别统一的过期时间,容器内的所有元素都遵循同一个过期时间。
Ehcache不仅支持缓存容器对象级别统一的过期时间设定,还会支持为容器中每一条缓存记录设定独立过期时间,允许不同记录有不同的过期时间。这在某些场景下还是非常友好的,可以指定部分热点数据一个相对较长的过期时间,避免热点数据因为过期导致的缓存击穿。
同时支持JCache与SpringCache规范
Ehcache作为一个标准化构建的通用缓存框架,同时支持了JAVA目前业界最为主流的两大缓存标准,即官方的JSR107标准以及使用非常广泛的Spring Cache标准,这样使得业务中可以基于标准化的缓存接口去调用,避免了Ehcache深度耦合到业务逻辑中去。
作为当前绝对主流的Spring框架,Ehcache可以做到无缝集成,便于项目中使用。在下面的章节中会专门介绍如何与Spring进行集成,此处先不赘述。
Hibernate的默认缓存策略
Hibernate是一个著名的开源ORM框架实现,提供了对JDBC的轻量级封装实现,可以在代码中以面向对象的方式去操作数据库数据,此前著名的SSH框架中的H,指的便是Hibernate框架。Hibernate支持一二级缓存,其中一级缓存是session级别的缓存,默认开启。而Hibernate的二级缓存,默认使用的便是Ehcache来实现的。能够被大名鼎鼎的Hibernate选中作为默认的缓存实现,也可以证明Ehcache不俗的实力。
Ehcache、Caffeine、Redis如何选择
之前的文章中介绍过Caffeine的相关特性与用法,两者虽然同属JVM级别的本地缓存框架,但是两者在目标细分领域,还是各有侧重的。而作为具备分布式能力的本地缓存,Ehcache与天生的分布式集中式缓存之间似乎也存在一些功能上的重合度,那么Ehcache、Caffeine、Redis三者之间应该如何选择呢?先看下三者的定位:
- Caffeine
- 更加轻量级,使用更加简单,可以理解为一个增强版的HashMap;
- 足够纯粹,适用于仅需要本地缓存数据的常规场景,可以获取到绝佳的命中率与并发访问性能。
- Redis
- 纯粹的集中缓存,为集群化、分布式多节点场景而生,可以保证缓存的一致性;
- 业务需要通过网络进行交互,相比与本地缓存而言性能上会有损耗。
- Ehcache
- 支持多级缓存扩展能力。通过
内存+磁盘等多种存储机制,解决缓存容量问题,适合本地缓存中对容量有特别要求的场景; - 支持缓存数据
持久化操作。允许将内存中的缓存数据持久化到磁盘上,进程启动的时候从磁盘加载到内存中; - 支持多节点
集群化组网。可以将分布式场景下的各个节点组成集群,实现缓存数据一致,解决缓存漂移问题。
相比而言,Caffeine专注于提供纯粹且简单的本地基础缓存能力、Redis则聚焦统一缓存的数据一致性方面,而Ehcache的功能则是更为的中庸,介于两者之间,既具有本地缓存无可比拟的性能优势,又兼具分布式缓存的多节点数据一致性与容量扩展能力。项目里面进行选型的时候,可以结合上面的差异点,评估下自己的实际诉求,决定如何选择。
简单来说,把握如下原则即可:
如果只是本地简单、少量缓存数据使用的,选择
Caffeine;如果本地缓存数据量较大、内存不足需要使用磁盘缓存的,选择
EhCache;如果是大型分布式多节点系统,业务对缓存使用较为重度,且各个节点需要依赖并频繁操作同一个缓存,选择
Redis。
小结回顾
好啦,关于Ehcache的一些问题关键特性,就介绍到这里了。不知道小伙伴们是否开始对Ehcache更加的感兴趣了呢?后面我们将一起来具体看下如何在项目中进行集成与使用Ehcache,充分去发掘与体验其强大之处。而关于Ehcache你是否有自己的一些想法与见解呢?欢迎评论区一起交流下,期待和各位小伙伴们一起切磋、共同成长。
补充说明1 :
本文属于《深入理解缓存原理与实战设计》系列专栏的内容之一。该专栏围绕缓存这个宏大命题进行展开阐述,全方位、系统性地深度剖析各种缓存实现策略与原理、以及缓存的各种用法、各种问题应对策略,并一起探讨下缓存设计的哲学。
如果有兴趣,也欢迎关注此专栏。
补充说明2 :
- 关于本文中涉及的演示代码的完整示例,我已经整理并提交到github中,如果您有需要,可以自取:https://github.com/veezean/JavaBasicSkills
我是悟道,聊技术、又不仅仅聊技术~
如果觉得有用,请点赞 + 关注让我感受到您的支持。也可以关注下我的公众号【架构悟道】,获取更及时的更新。
期待与你一起探讨,一起成长为更好的自己。

JAVA中使用最广泛的本地缓存?Ehcache的自信从何而来 —— 感受来自Ehcache的强大实力的更多相关文章
- java中常用的几种缓存类型介绍
在平时的开发中会经常用到缓存,比如locache.redis等,但一直没有对缓存有过比较全面的总结.下面从什么是缓存.为什么使用缓存.缓存的分类以及对每种缓存的使用分别进行分析,从而对缓存有更深入的了 ...
- 在java中构建高效的结果缓存
文章目录 使用HashMap 使用ConcurrentHashMap FutureTask 在java中构建高效的结果缓存 缓存是现代应用服务器中非常常用的组件.除了第三方缓存以外,我们通常也需要在j ...
- 认识理解Java中native方法(本地方法)
Java不是完美的,Java的不足除了体现在运行速度上要比传统的C++慢许多之外,Java无法直接访问到操作系统底层(如系统硬件等),为此Java使用native方法来扩展Java程序的功能. 可 ...
- 在 java 中守护线程和本地线程区别?
java 中的线程分为两种:守护线程(Daemon)和用户线程(User). 任何线程都可以设置为守护线程和用户线程,通过方法 Thread.setDaemon(bool on):true 则把该线程 ...
- Java中如何使用Redis做缓存
基本功能测试 1.程序基本结构 2.主要类 1)功能类 package com.redis; import java.util.ArrayList; import java.util.Iterator ...
- .net core系列之《在.net core中使用MemoryCache实现本地缓存》
说到内存缓存MemoryCache不由的让我想起.Net Framework中的MemoryCache,它位于 System.Runtime.Caching 程序集中. 接下来我们来看看.net co ...
- Java中Redis简单入门
Redis是一个开源的,先进的 key-value 存储可用于构建高性能,可扩展的 Web 应用程序的解决方案. Redis官方网网站是:http://www.redis.io/,如下: Redis ...
- 使用Guava cache构建本地缓存
前言 最近在一个项目中需要用到本地缓存,在网上调研后,发现谷歌的Guva提供的cache模块非常的不错.简单易上手的api:灵活强大的功能,再加上谷歌这块金字招牌,让我毫不犹豫的选择了它.仅以此博客记 ...
- Java中Redis入门(1)
Redis是一个开源的,先进的 key-value 存储可用于构建高性能,可扩展的 Web 应用程序的解决方案. Redis官方网网站是:http://www.redis.io/,如下: Redis ...
- Java中ProcessBuilder应用实例
系列说明 浅析Java.lang.Runtime类 浅析Java.lang.Process类 浅析Java.lang.ProcessBuilder类 可以使用java中的ProcessBuilder执 ...
随机推荐
- Java开发学习(三十七)----SpringBoot多环境配置及配置文件分类
一.多环境配置 在工作中,对于开发环境.测试环境.生产环境的配置肯定都不相同,比如我们开发阶段会在自己的电脑上安装 mysql ,连接自己电脑上的 mysql 即可,但是项目开发完毕后要上线就需要该配 ...
- Flutter Cocoon 已达到 SLSA 2 级标准的要求
文/ Jesse Seales, Dart 和 Flutter 安全工作组工程师 今年年初,我们发布了 Flutter 2022 产品路线图,其中「基础设施建设」这部分提到:2022 年 Flutte ...
- C++函数模板和类模板的使用
一.函数模板 #include<iostream>using namespace std;template<class T1,class T2>T1 add(T1 x,T2 y ...
- 会话跟踪技术 - Cookie 和 Session 快速上手 + 登陆注册案例
目录 1. 会话跟踪技术概述 2. Cookie 2.1 Cookie的概念和工作流程 2.2 Cookie的基本使用 2.3 Cookie的原理分析 2.4 Cookie的使用细节 2.4.1 Co ...
- echarts的使用 超好用的报表制作、数据的图形化展示
地址链接:https://echarts.apache.org/zh/index.html 1.图形选择 2.对应的js代码
- Shell揭秘——程序退出状态码
程序退出状态码 前言 在本篇文章当中主要给大家介绍一个shell的小知识--状态码.这是当我们的程序退出的时候,子进程会将自己程序的退出码传递给父进程,有时候我们可以利用这一操作做一些进程退出之后的事 ...
- CentOS 7.9 Related Software Directory
一.CentOS 7.9 Related Software Directory Installing VMware Workstation Pro on Windows Installing Cent ...
- Archlinux + Dwm 配置流程
本着学习C的态度来了解dwm,本身作为一个i3wm的追崇者,与dwm会擦出怎么样的火花呢? 下载安装dwm archlinuxcn源配置 编辑/etc/pacman.conf文件,添加bfsu的arc ...
- springboot的全局异常处理类
import lombok.extern.slf4j.Slf4j; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import or ...
- 【题解】CF1503B 3-Coloring
题面传送门 解决思路 讲一下 \(\text{VP}\) 时的思路. 首先想到,只要能将棋盘中红色或蓝色部分全部填成同一个数,那么剩下的就不会受限了(可行有两个,限制只有一个): 但考虑到交互库可能有 ...