[OpenCV实战]26 基于OpenCV实现选择性搜索算法
目录
本教程中,我们将了解目标检测中称为“选择性搜索”的重要概念。我们还将在OpenCV 中使用C ++和Python实现该算法。
1 背景
1.1 目标检测与目标识别
目标识别算法Target Recognition识别图像中存在哪些对象。它将整个图像作为输入,并输出该图像中存在的对象的类标签和类概率。例如,类标签可以是“狗”,相关的类概率可以是97%。另一方面,目标检测算法Target Detection不仅告诉您图像中存在哪些对象,还输出边界框(x,y,width,height)以表示图像内对象的位置。
所有目标检测算法的核心是物体识别算法。假设我们训练了一个目标识别模型,该模型识别图像中的狗。该模型将判断图像中是否有狗。它不会告诉对象的位置。
为了定位物体,我们必须要选择图片的次区域(子块)然后对这些图片子块应用目标识别算法。目标的位置由目标识别算法返回的类概率较高的图像块的位置给出。
最直接的生成较小的次区域的方法为滑动窗口方法。然而,滑动窗口方法有许多限制。这些限制叫做候选区域算法克服了。选择性搜索就是候选区域算法中最流行的一种。

1.2 滑动窗口算法
在滑动窗口方法中,我们在图像上滑动框或窗口以选择子块,并使用目标识别模型对窗口覆盖的每个图像子块进行分类。它是对整个图像上的对象的详尽搜索。我们不仅需要搜索图像中的所有可能位置,还必须搜索不同的比例。这是因为目标识别模型通常以特定尺度(或尺度范围)进行训练。这导致对数万个图像块进行分类。问题还不仅仅如此。滑动窗口方法对于固定的纵横比对象,如人脸或行人表现是好的。图像是三维物体的二维投影。根据图像拍摄的角度,诸如纵横比和形状等物体特征有很大的不同。因此当我们搜索多个纵横比时,滑动窗口方法的计算非常昂贵。
1.3 候选区域选择算法
到目前为止我们讨论的问题可以使用候选区域选择算法来解决。这种方法将图像作为输入,输出可能是包含目标对象子块的选择框。这些候选区域可能是嘈杂的、重叠的,并且可能不能完美地包含这个对象,但是在这些候选区域中,将会有一个非常接近于图像中的实际对象的候选区域。然后我们可以使用目标识别模型对这些候选区域进行分类。有分数最高的候选区域就是该物体的位置。
如下图所示,生成了多个候选区域,其中以绿色表示最后物体的位置框。

候选区域选择算法使用分割来识别图像中的目标。在分割中,我们根据颜色、纹理等标准对相邻的相似区域进行分组。。与我们在所有像素位置和所有尺度上寻找对象的滑动窗口方法不同,候选区域选择算法通过在更细分的像素组下进行分割。因此,生成的最终候选区域数量比滑动窗口方法少很多倍。这减少了我们必须分类的图像子块的数量。这些生成的区域具有不同的比例和宽高比。
候选区域选择算法的一个重要特性是具有非常高的召回率。这只是一种花哨的说法,即包含我们所寻找的对象的区域必须出现在我们的候选区域清单中。为了实现这一点,我们的区域候选区域列表最终可能会包含许多不包含任何对象的区域。换句话说,候选区域算法可以产生大量的误报,只要它能够捕获所有真正的对象。多数这些误报将被目标识别算法否定。当我们有更多的误报并且精度受到轻微影响时,检测所需的时间就会增加。但是,召回率高仍然是一个好主意,因为会丢失包含实际对象的区域的其他方法会严重影响检测率。
已经提出了几种候选区域选择方法,例如
1) Objectness
http://groups.inf.ed.ac.uk/calvin/objectness/
2) Constrained Parametric Min-Cuts for Automaticobject Segmentation
http://www.maths.lth.se/matematiklth/personal/sminchis/code/cpmc/index.html
3) Category Independent Object Proposals
http://vision.cs.uiuc.edu/proposals/
4) Randomized Prim
http://www.vision.ee.ethz.ch/~smanenfr/rp/index.html
5) Selective Search
http://koen.me/research/selectivesearch/
在所有这些区域提议方法中,选择性搜索是最常用的,因为它速度快且召回率很高。
2 选择性搜索算法
2.1 什么是选择性搜索?
选择性搜索是用于目标检测的候选区域选择算法。它快速并具有很高的召回率。它基于根据颜色,纹理,大小和形状兼容性计算相似区域的分层分组。它基于根据颜色,纹理,大小和形状等对相似区域进行分组。
选择性搜索首先使用Felzenszwalb和Huttenlocher 基于图形的分割方法,根据像素的强度对图像进行过度分割。算法的输出如下所示,图像分别为原图和包含了用纯色表示的分割区域。论文见http://cs.brown.edu/~pff/segment/


我们可以在这个图像中使用分割的部分作为候选区域吗?答案是否定的,我们不能这样做有两个原因:
1)原始图像中的大多数实际对象包含两个或多个分割区域;
2)对于被遮挡的物体,如杯子所覆盖的盘子或装满咖啡的杯子的候选区域不能用这种方法生成。
如果我们试图通过进一步合并相邻的区域来解决第一个问题,我们最终会得到一个包含两个对象的分割区域。完美的分割不是我们的目标。我们只是想获得许多候选区域,比如其中一些应该与实际的对象有非常高的重叠。选择性搜索使用 Felzenszwalb 和 huttenlocher 的方法中的过分割作为初始种子。一个过分割的图像是这样的。

、
选择性搜索算法将这些过分割作为初始输入,并执行以下步骤
1)将与分割部分对应的所有边界框添加到候选区域列表中
2)基于相似度合并相邻分割区域
3)回到第一步
在每次迭代中,形成更大的部分并添加到区域候选区域列表中。因此,我们通过自下而上的方法从较小的部分到更大的部分获得候选区域。:这就是我们所说的使用 Felzenszwalb 和 huttenlocher 的过分割来计算“分层”分割的意思。下图显示了分层分割过程的初始,中间和最后一步。
详细见:https://www.koen.me/research/selectivesearch/

2.2 选择性搜索相似性度量
让我们深入探讨如何计算两个区域之间的相似性。选择性搜索使用基于颜色,纹理,大小和形状兼容性的4种相似性度量方法。具体见:
https://www.cnblogs.com/zyly/p/9259392.html#_label3_0
(1)颜色相似性
针对图像的每个通道计算25个区间的颜色直方图,并且连接所有通道的直方图以获得颜色描述符,得到25×3=75维颜色描述符。
两个区域的颜色相似性基于直方图交集,可以计算为:
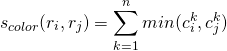
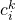 是在颜色描述符直方图中
是在颜色描述符直方图中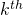 组的值
组的值
(2)纹理相似性
纹理特征是通过在每个通道的8个方向提取高斯导数来计算的。对于每一个方向和每个颜色通道,计算一个10组直方图,形成一个10× 8×3=240维的特征描述符。
利用直方图相交法计算两个区域的纹理相似度。
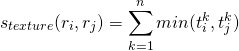
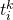 是在纹理描述符直方图中
是在纹理描述符直方图中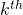 组的值
组的值
(3)大小相似度
大小相似促使较小的区域尽早合并。它确保了在所有尺度上的区域建议都是在图像的所有部分形成的。如果没有考虑到这种相似性度量,单个区域将会一个接一个地吞噬所有较小的相邻区域,因此在这个位置只会产生多个尺度的候选区域。大小相似性被定义为:

其中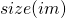 是图像的大小,以像素为单位。
是图像的大小,以像素为单位。
(4)形状兼容性
形状兼容性测量两个区域(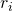 和
和 )之间的匹配程度。如果
)之间的匹配程度。如果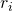 和形状匹配,我们会合并它们以填补空白,否则,它们就不应该合并。
和形状匹配,我们会合并它们以填补空白,否则,它们就不应该合并。
形状兼容性定义如下:
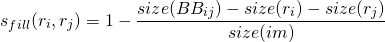
这里 是在
是在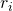 和
和 周围的边界框。
周围的边界框。
(5)最终相似度
两个区域之间的最终相似性被定义为前述4个相似性的线性组合。

其中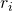 和
和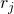 是图像中的两个区域或区段,并
是图像中的两个区域或区段,并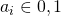 表示是否使用该相似性度量。
表示是否使用该相似性度量。
2.3 结果
OpenCV中的选择性搜索实现提供了数千个按对象有效程度递减顺序排列的区域方案。为了清晰起见,我们将与图像上绘制的前200-250个框共享结果。一般来说,1000-1200个候选区域足以获得所有正确的目标区域。下图为250个候选框结果和200候选框结果图。


3 代码
OpenCV有自带的SelectiveSearchSegmentation类,使用起来很容易。需要包含ximgproc.hpp和其命名空间。但是速度很慢。所有代码见:
https://github.com/luohenyueji/OpenCV-Practical-Exercise、
C++:
#include "pch.h"
#include <opencv2/opencv.hpp>
#include <opencv2/ximgproc.hpp>
#include <iostream>
#include <ctime>
using namespace cv;
using namespace cv::ximgproc::segmentation;
int main()
{
// speed-up using multithreads 使用多线程
//开启CPU的硬件指令优化功能
setUseOptimized(true);
setNumThreads(4);
// read image 读图
Mat im = imread("./image/dogs.jpg");
if (im.empty())
{
return 0;
}
// resize image 图像大小重置
int newHeight = 200;
int newWidth = im.cols*newHeight / im.rows;
resize(im, im, Size(newWidth, newHeight));
// create Selective Search Segmentation Object using default parameters 默认参数生成选择性搜索类
Ptr<SelectiveSearchSegmentation> ss = createSelectiveSearchSegmentation();
// set input image on which we will run segmentation 要进行分割的图像
ss->setBaseImage(im);
// Switch to fast but low recall Selective Search method 快速搜索(速度快,召回率低)
//ss->switchToSelectiveSearchFast();
//精准搜索(速度慢,召回率高)
ss->switchToSelectiveSearchQuality();
// run selective search segmentation on input image 保存搜索到的框,按可能性从高到低排名
std::vector<Rect> rects;
ss->process(rects);
std::cout << "Total Number of Region Proposals: " << rects.size() << std::endl;
// number of region proposals to show 在图像中保存多少框
int numShowRects = 100;
while (1)
{
// create a copy of original image 做一份图像图像拷贝
Mat imOut = im.clone();
// itereate over all the region proposals 画框前numShowRects个
for (int i = 0; i < numShowRects; i++)
{
rectangle(imOut, rects[i], Scalar(0, 255, 0));
}
// show output
imshow("Output", imOut);
waitKey(0);
}
return 0;
}Python:
import sys
import cv2
if __name__ == '__main__':
# speed-up using multithreads
cv2.setUseOptimized(True)
cv2.setNumThreads(4);
# read image
im = cv2.imread('image/dogs.jpg')
# resize image
newHeight = 200
newWidth = int(im.shape[1]*200/im.shape[0])
im = cv2.resize(im, (newWidth, newHeight))
# create Selective Search Segmentation Object using default parameters
ss = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
# set input image on which we will run segmentation
ss.setBaseImage(im)
#ss.switchToSelectiveSearchFast()
ss.switchToSelectiveSearchQuality()
# run selective search segmentation on input image
rects = ss.process()
print('Total Number of Region Proposals: {}'.format(len(rects)))
# number of region proposals to show
numShowRects = 100
# increment to increase/decrease total number
# of reason proposals to be shown
increment = 50
while True:
# create a copy of original image
imOut = im.copy()
# itereate over all the region proposals
for i, rect in enumerate(rects):
# draw rectangle for region proposal till numShowRects
if (i < numShowRects):
x, y, w, h = rect
cv2.rectangle(imOut, (x, y), (x+w, y+h), (0, 255, 0), 1, cv2.LINE_AA)
else:
break
# show output
cv2.imshow("Output", imOut);
# record key press
k = cv2.waitKey(0) & 0xFF
# m is pressed
if k == 109:
# increase total number of rectangles to show by increment
numShowRects += increment
# l is pressed
elif k == 108 and numShowRects > increment:
# decrease total number of rectangles to show by increment
numShowRects -= increment
# q is pressed
elif k == 113:
break
# close image show window
cv2.destroyAllWindows()4 参考
https://www.learnopencv.com/selective-search-for-object-detection-cpp-python/
[OpenCV实战]26 基于OpenCV实现选择性搜索算法的更多相关文章
- [OpenCV实战]48 基于OpenCV实现图像质量评价
本文主要介绍基于OpenCV contrib中的quality模块实现图像质量评价.图像质量评估Image Quality Analysis简称IQA,主要通过数学度量方法来评价图像质量的好坏. 本文 ...
- [OpenCV实战]45 基于OpenCV实现图像哈希算法
目前有许多算法来衡量两幅图像的相似性,本文主要介绍在工程领域最常用的图像相似性算法评价算法:图像哈希算法(img hash).图像哈希算法通过获取图像的哈希值并比较两幅图像的哈希值的汉明距离来衡量两幅 ...
- [OpenCV实战]28 基于OpenCV的GUI库cvui
目录 1 cvui的使用 1.1 如何在您的应用程序中添加cvui 1.2 基本的"hello world"应用程序 2 更高级的应用 3 代码 4 参考 有很多很棒的GUI库,例 ...
- [OpenCV实战]47 基于OpenCV实现视觉显著性检测
人类具有一种视觉注意机制,即当面对一个场景时,会选择性地忽略不感兴趣的区域,聚焦于感兴趣的区域.这些感兴趣的区域称为显著性区域.视觉显著性检测(Visual Saliency Detection,VS ...
- [OpenCV实战]38 基于OpenCV的相机标定
文章目录 1 什么是相机标定? 2 图像形成几何学 2.1 设定 2.1.1 世界坐标系 2.1.2 相机坐标系 2.1.3 图像坐标系 2.2 图像形成方法总结 3 基于OpenCV的相机标定原理 ...
- [OpenCV实战]51 基于OpenCV实现图像极坐标变换与逆变换
在图像处理领域中,经常通过极坐标与笛卡尔直角坐标的互转来实现图像中圆形转为方形,或者通过极坐标反变换实现方形转圆形.例如钟表的表盘,人眼虹膜,医学血管断层都需要用到极坐标变换来实现圆转方. 文章目录 ...
- [OpenCV实战]11 基于OpenCV的二维码扫描器
目录 1 二维码(QRCode)扫描 2 结果 3 参考 在这篇文章中,我们将看到如何使用OpenCV扫描二维码.您将需要OpenCV3.4.4或4.0.0及更高版本来运行代码. 1 二维码(QRCo ...
- [OpenCV实战]15 基于深度学习的目标跟踪算法GOTURN
目录 1 什么是对象跟踪和GOTURN 2 在OpenCV中使用GOTURN 3 GOTURN优缺点 4 参考 在这篇文章中,我们将学习一种基于深度学习的目标跟踪算法GOTURN.GOTURN在Caf ...
- [OpenCV实战]5 基于深度学习的文本检测
目录 1 网络加载 2 读取图像 3 前向传播 4 处理输出 3结果和代码 3.1结果 3.2 代码 参考 在这篇文章中,我们将逐字逐句地尝试找到图片中的单词!基于最近的一篇论文进行文字检测. EAS ...
随机推荐
- 路径分析—QGIS+PostgreSQL+PostGIS+pgRouting(一)
前言 因业务需求,需要做最短路径分析.最近几天查询资料,并自己动手,实现了简单的路径分析. 下面就介绍具体的实现过程. 本篇文章最终结果是在 PostgreSQL 数据库中实现的,后续的可视化展示会继 ...
- Java学习之路:流程控制
2022-10-11 10:58:41 前言 本文开始流程控制方面的学习,主要包括用户交互和流程控制语句,适合新手学习. 1 用户交互Scanner 1.1 Scanner对象 Java提供了一个可以 ...
- RAID5 IO处理之写请求代码详解
我们知道RAID5一个条带上的数据是由N个数据块和1个校验块组成,其校验块由N个数据块通过异或运算得出,这样才能在任意一个成员磁盘失效时通过其他N个成员磁盘恢复出用户写入的数据.这也就要求RAID5条 ...
- jsp页面重定向后地址栏controller名重复而导致报404错误
今天做ssm项目时遇到了这种错误 看看代码: 无关代码省略... 22 <body> 23 <div id="container"> 24 <ifra ...
- 创建第一个springboot项目、用springboot实现页面跳转、@Controller和@RestController的区别
文章目录 一.第一个spring boot项目 二.spring boot跳转到指定页面 三.怎样将后台的信息传递到前台 四. @Controller和@RestController的区别? 一.第一 ...
- coding上创建项目、创建代码仓库、将IDEA中的代码提交到coding上的代码仓库、Git的下载、IDEA上配置git
文章目录 一.Git的安装以及子啊IDEA上配置Git(下载好的可以跳过) 二.怎样让IDEA和Git建立关系 三.在coding上创建项目 四.在coding上创建代码仓库 五.Git工作理论 六. ...
- 数据结构中的哈希表(java实现)利用哈希表实现学生信息的存储
哈希表 解释 哈希表是一种根据关键码去寻找值的数据映射结构,该结构通过把关键码映射的位置去寻找存放值的地方 内存结构分析图 1.定义一个类为结点,存储的信息 2.定义链表的相关操作 3.定义一个数组存 ...
- 三、Python语法介绍
三.Python语言介绍 3.1.了解Python语言 Python 是1989 年荷兰人 Guido van Rossum (简称 Guido)在圣诞节期间为了打发时间,发明的一门面向对象的解释性编 ...
- java学习之IO流
java io流有四大家族分别是: 1.InputStream(字节输入流) 2.OutputStream(字节输入出流)3.Reader(字符输入流)4.Writer(字符输出流)四个类都是抽象类 ...
- C#使用最小二乘法对多个离散点进行圆拟合
/// <summary> /// 最小二乘法拟合圆,计算拟合圆半径和拟合圆圆心 /// </summary> /// <param name="points& ...