linux下redis_单机版_主从_集群_部署文档
一 单机版部署
1.1 Redis下载地址
http://download.redis.io/releases/
本次部署版本:3.2.8
当前最新版本:5.0.5
1.2 安装
- 部署路径说明规划
/usr/local/redis/data部署组件元数据存储目录,按组件名目录存储(如/部署路径/redis)
/usr/local/redis/logs部署组件运行日志信息目录,按组件名目录存储(如/部署路径/redis)
/usr/local/redis/tmp部署组件运行时进程存储目录,按组件名目录存储(如/部署路径/redis)
创建文件夹
mkdir /usr/local/redis
cd /usr/local/redis
mkdir data
mkdir logs
mkdir tmp
- 上传解压
tar -zxvf /root/redis-3.2.8.tar.gz -C /usr/local/redis/
- 编译环境检查
rpm -qa | grep gcc
若没有安装则挂载yum源进行安装
[root@BigData yum.repos.d]# yum install gcc gcc-c++ -y
- 编译
进入到redis解压目录:cd /usr/local/redis/redis-3.2.8
执行编译命令:make
若出现下面提示则表示编译成功

- 安装
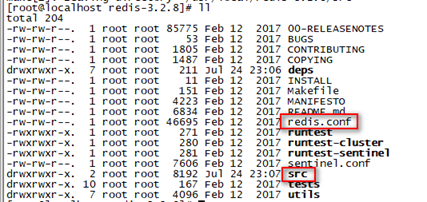
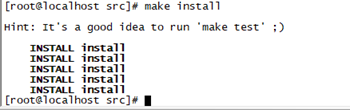
编译成功后,进入src文件夹,执行make install进行Redis安装
cd src
make install
1.3 部署
安装成功后,下面对Redis 进行部署
- 为方便管理,将Redis文件中的conf配置文件和常用命令移动到统一文件中
- 创建文件夹
cd /usr/local/redis/redis-3.2.8
mkdir bin
mkdir etc
- 移动相关文件
mv redis.conf etc/
mv src/mkreleasehdr.sh bin/
mv src/redis-benchmark bin/
mv src/redis-check-aof bin/
mv src/redis-cli bin/
mv src/redis-server bin/
- 修改配置文件
cd etc/
vi redis.conf
为了方便修改,可将文件放到本地修改,修改完成之后再上传到服务器,需要配置如下:
bind 192.168.194.91
daemonize yes
pidfile /usr/local/redis/tmp/redis_6379.pid
logfile /usr/local/redis/logs/redis_6379.log
dbfilename dump.rdb
dir /usr/local/redis/data
appendonly yes
cluster-enabled no
maxmemory 300mb
maxmemory-policy volatile-lru
maxclients 10000protected-mode no 5.0.2 中需要配置的项目。不配置会报错
配置项介绍
|
1.绑定IP bind 192.168.194.91 2.监听端口号,默认为 6379 dbfilename dump.rdb 7. 指定本地数据库存放目录 dir /opt/beh/data/redis 8.是否启动集群模式 cluster-enabled no 9.Redis群集节点每次发生更改时自动保留群集配置(基本上为状态)的文件 cluster-config-file nodes.conf 10. 集群超时时间,节点超过这个时间没反应就断定是宕机 cluster-node-timeout 15000 11. 最大使用内存 可根据业务量及机器内存配置 12. 根据LRU算法生成的过期时间来删除key。,优先移除最近未使用的key requirepass <password> |
- 启动测试
启动:
cd /usr/local/redis/redis-3.2.8
bin/redis-server etc/redis.conf
查看进程:
ps -ef | grep redis

连接测试:
关闭防火墙或开放相应端口
bin/redis-cli -h 192.168.194.91 -p 6379
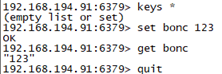
查看所有keys:
192.168.194.91:6379> keys *
(empty list or set)
添加数据:
192.168.194.91:6379> set bonc 123
OK
查看数据:
192.168.194.91:6379> get bonc
"123"
单机版搭建完成
二 redis主从复制部署
单节点的Redis,当出现机器故障或机器重启时,存储在Redis里的数据将丢失,且单节点的Redis并发访问量有限。为了解决Redis单节点问题,实现Redis的高可用,会将数据复制多个副本到其他节点上。采用主从复制,一主多从的模式。由redis sentinel(哨兵)对redis系统进行监控,监控主数据库和从数据库是否运行正常,当主节点出现故障时自动的将从库转化为主库。实现对数据的冗余备份,从而保证数据和服务的高可用。
一主一从:

一主一从适用于没有太大并发量的场景的高可用,当master宕机时,slave提供故障转移支持
一主多从
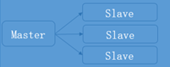
一主多从适用于读并发量比较大的场景,实现读写分离的架构,同时也实现了高可用
树状主从结构

从节点可以从主节点复制数据,也可以从其他节点复制数据,这种架构主要用于降低主节点负载
2.1 Redis下载地址
http://download.redis.io/releases/
本次部署版本:3.2.8
当前最新版本:5.0.5
2.2 安装
- 部署机器
|
部署机器ip |
主/从 |
|
192.168.194.93 |
Master |
|
192.168.194.94 |
Slave |
- 部署路径说明规划
/usr/local/redis/data部署组件元数据存储目录,按组件名目录存储(如/部署路径/redis)
/usr/local/redis/logs部署组件运行日志信息目录,按组件名目录存储(如/部署路径/redis)
/usr/local/redis/tmp部署组件运行时进程存储目录,按组件名目录存储(如/部署路径/redis)
在两台机器上分别创建文件夹
mkdir /usr/local/redis
cd /usr/local/redis
mkdir data
mkdir logs
mkdir tmp
- 上传解压
tar -zxvf /root/redis-3.2.8.tar.gz -C /usr/local/redis/
- 编译环境检查
rpm -qa | grep gcc
若没有安装则挂载yum源进行安装
[root@BigData yum.repos.d]# yum install gcc gcc-c++ -y
- 编译
进入到redis解压目录:cd /usr/local/redis/redis-3.2.8
执行编译命令:make
若出现下面提示则表示编译成功

- 安装
编译成功后,进入src文件夹,执行make install进行Redis安装
cd src
make install

2.3 部署
安装成功后,下面对Redis 进行部署
- 为方便管理,将Redis文件中的conf配置文件和常用命令移动到统一文件中
1、创建文件夹
cd /usr/local/redis/redis-3.2.8
mkdir bin
mkdir etc
2、移动相关文件
mv redis.conf etc/
mv src/mkreleasehdr.sh bin/
mv src/redis-benchmark bin/
mv src/redis-check-aof bin/
mv src/redis-cli bin/
mv src/redis-server bin/
- 修改配置文件
cd etc/(redis安装目录下的etc文件夹,并非根目录下的)
vi redis.conf
1、Master参数配置
|
bind 192.168.194.93 port 6379 daemonize yes pidfile /usr/local/redis/tmp/redis_6379.pid logfile /usr/local/redis/logs/redis_6379.log dbfilename dump.rdb dir /usr/local/redis/data appendonly yes cluster-enabled no maxmemory 300mb maxmemory-policy volatile-lru |
2、salve参数配置
|
bind 192.168.194.94 port 6379 #如果在一台机器上部署多个redis实例,则这个端口需要修改 daemonize yes pidfile /usr/local/redis/tmp/redis_6379.pid logfile /usr/local/redis/logs/redis_6379.log dbfilename dump.rdb dir /usr/local/redis/data appendonly yes cluster-enabled no maxmemory 300mb maxmemory-policy volatile-lru slaveof 192.168.194.93 6379 |
需要注意,主从复制的开启,完全是在从节点发起的;不需要我们在主节点做任何事情。
从节点开启主从复制,有3种方式:
(1)配置文件
在从服务器的配置文件中加入:slaveof <masterip> <masterport>
(2)启动命令
redis-server启动命令后加入 --slaveof <masterip> <masterport>
(3)客户端命令
Redis服务器启动后,直接通过客户端执行命令:slaveof <masterip> <masterport>,则该Redis实例成为从节点。
本方法种采用的是第一种,修改配置文件,当需要有多个从节点时,则依次按照上述方法添加从节点即可
- 启动测试
关闭防火墙或开放相应端口
启动:
cd /usr/local/redis/redis-3.2.8
bin/redis-server etc/redis.conf
查看进程:
ps -ef | grep redis

登陆master查看主从情况
[root@localhost redis-3.2.8]# bin/redis-cli -h 192.168.194.93 -p 6379
192.168.194.93:6379> info replication
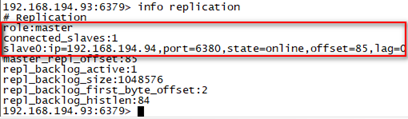
登陆slave查看主从情况
[root@localhost redis-3.2.8]# bin/redis-cli -h 192.168.194.94 -p 6380
192.168.194.94:6380> info replication
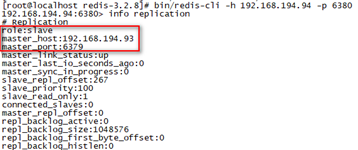
主从复制测试
在主上写数据
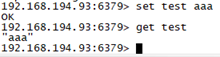
在从上查询数据

2.4 主从切换
在Master不可用的情况下,停止Mater,将Slave的设定无效化后,Slave升级为Master,可以采用手动切换和哨兵模式自动切换。手动切换在master不可用的情况下需要自己停止master,再手动将salve升级为master,不智能,所以本文将直接采用哨兵模式实现自动切换
- 哨兵配置
cd /usr/local/redis/redis-3.2.8
cp sentinel.conf etc/ #将配置文件复制到etc下方便管理
编辑配置文件 vi etc/sentinel.conf
|
bind 192.168.194.93 #允许远程连接哨兵,在java的jedis中需要连接哨兵 port 26379 daemonize yes pidfile "/usr/local/redis/tmp/redis-sentinel_26379.pid" logfile "/usr/local/redis/logs/redis-sentinel_26379.log" dir /usr/local/redis/data/redis-sentinel ---需要创建redis-sentinel目录 #配置监视的集群的主节点ip和端口 2表示至少需要几个哨兵统一认定才可以做出判断 sentinel monitor mymaster 192.168.194.93 6379 2 #设置连接master和slave时的密码,注意的是sentinel不能分别为master和slave设置不同的密码,因此master和slave的密码应该设置相同。 sentinel auth-pass mymaster redis123 –-redis如果没有设置密码则无需配置 #表示如果5s内mymaster没响应,就认为DOWN sentinel down-after-milliseconds mymaster 10000 #表示如果15秒后,mysater仍没活过来,则启动failover,从剩下从节点序曲新的主节点 sentinel failover-timeout mymaster 60000 |
- 启动哨兵
复制执行文件到bin目录下
cp src/redis-sentinel bin/
执行启动命令
bin/redis-sentinel etc/sentinel.conf
查看进程
ps -ef | grep sentinel

可以配置多个哨兵同时监测实现哨兵的高可用
- 主(master)/从(slave)切换测试
杀死主redis线程
查看:ps -ef | grep redis

杀死:kill -9 25552
等待10秒种之后(哨兵监测maste 10秒种无响应才认为主已经down,是在sentinel.conf中配置)
查看哨兵日志
cat -f /usr/local/redis/logs /redis-sentinel_26379.log
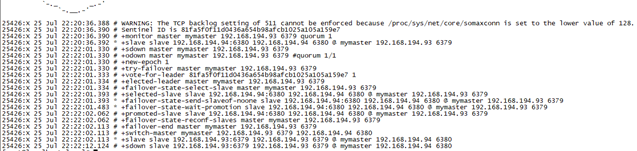
再从上查看主从信息,发现从已经升级为主,
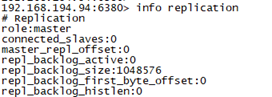
读写测试(slave没升级为主之前只能可读不可写,当master down之后slave升级为主之后才有可写)
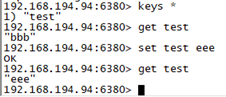
再次启动原来的主(93),查看主从信息
bin/redis-cli -h 192.168.194.93 -p 6379

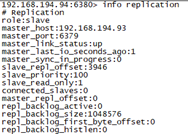
发现93已经成功启动,并把94当做为主,自己为从,查看数据,主从复制依然正常

当主挂了之后再次启动则会以从的身份加入到集群,不会一直再自动切换为主,如果想要再切换到主的身份则需要手动切换,当只有一主一从时,可以将原来的从杀死再启动,哨兵就可以再次把主切换到原来的主上
三 redis分布式集群部署
要想搭建一个最简单的Redis集群,那么至少需要6个节点:3个Master和3个Slave。为什么需要3个Master呢?类似于Zookeeper,一般分布式要求基数个节点,这样便于选举(少数服从多数的原则)。
搭建思路很简单,开启6个Redis实例,并且这6个Redis各自有自己IP和端口。如果机器不够也可以在一台机器上开启多个redis实例,本文采用3太虚拟机,每台开启两个实例这样的话,相当于模拟出了6台机器了。然后在以这6个实例组建Redis集群就可以了。
3.1 Redis下载地址
http://download.redis.io/releases/
本次部署版本:3.2.8
当前最新版本:5.0.5
3.2安装
|
部署机器ip |
部署实例 |
|
192.168.194.97 |
192.168.194.97:6379 192.168.194.97:6380 |
|
192.168.194.98 |
192.168.194.98:6379 192.168.194.98:6380 |
|
192.168.194.99 |
192.168.194.99:6379 192.168.194.99:6380 |
- 部署路径说明规划
/usr/local/redis/data部署组件元数据存储目录,按组件名目录存储(如/部署路径/redis)
/usr/local/redis/logs部署组件运行日志信息目录,按组件名目录存储(如/部署路径/redis)
/usr/local/redis/tmp部署组件运行时进程存储目录,按组件名目录存储(如/部署路径/redis)
在三台机器上分别创建文件夹
mkdir /usr/local/redis
cd /usr/local/redis
mkdir data
mkdir logs
mkdir tmp
- 上传解压
tar -zxvf /root/redis-3.2.8.tar.gz -C /usr/local/redis/
- 编译环境检查
rpm -qa | grep gcc
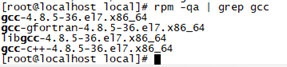
若没有安装则挂载yum源进行安装
[root@BigData yum.repos.d]# yum install gcc gcc-c++ -y
- 编译
进入到redis解压目录:cd /usr/local/redis/redis-3.2.8
执行编译命令:make
若出现下面提示则表示编译成功

- 安装
编译成功后,进入src文件夹,执行make install进行Redis安装
cd src
make install
3.3 部署
安装成功后,下面对Redis 进行部署
- 为方便管理,将Redis文件中的conf配置文件和常用命令移动到统一文件中
1、创建文件夹
cd /usr/local/redis/redis-3.2.8
mkdir bin
mkdir etc
2、移动相关文件
mv redis.conf etc/
mv src/mkreleasehdr.sh bin/
mv src/redis-benchmark bin/
mv src/redis-check-aof bin/
mv src/redis-cli bin/
mv src/redis-server bin/
- 修改配置文件
第一个实例配置文件实例
|
bind 192.168.194.97 port 6379 daemonize yes pidfile /usr/local/redis/tmp/redis_6379.pid logfile /usr/local/redis/logs/redis_6379.log dbfilename dump.rdb dir /usr/local/redis/data/redis_6379 ##需要在data目录下创建相应的 redis_6379目录,最好提前创建,防止遗忘 appendonly yes cluster-enabled yes //开启集群 把注释#去掉 cluster-config-file /usr/local/redis/tmp/nodes_6379.conf //集群的配 置配置文件首次启动自动生成 cluster-node-timeout 15000 maxmemory 300mb maxmemory-policy volatile-lru |
其他配置文件可以参考上面的配置,具体说明如下
|
1、绑定的本机IP, bind 192.168.194.97 2、端口,redis默认端口是6379,若一台机器要启动多个实例时这个不能一样 port 6379 3、设置redis后台运行,Redis采用的是单进程多线程的模式,开启守护进程模式,redis会在后台运行,并将进程pid号写入至redis.conf选项pidfile设置的文件中,此时redis将一直运行,除非手动kill该进程 daemonize yes 4、当redis作为守护进程运行的时候,指定pid文件位置,每个实例都有都要有一个不通的对应文件,可以如redis_6379.pid、redis_6380.pid pidfile /usr/local/redis/tmp/redis_6379.pid 5、指定日志文件的位置,每个实例都有都要有一个不通的对应文件,可以如redis_6379.log、redis_6380.log logfile /usr/local/redis/logs/redis_6379.log 6、指定本地数据库文件名 dbfilename dump.rdb 7、指定本地数据库存放目录,最好每个实例有一个独立的目录,该目录要提前创建好,为了防止遗忘建议在修改配置文件时就创建 dir /usr/local/redis/data/redis_6379 8、aof日志开启 有需要就开启,它会每次写操作都记录一条日志 appendonly yes 9、开启集群 把注释#去掉 cluster-enabled yes 10、集群的配置配置文件,首次启动自动生成,每个实例都需要配置一个,可以如:nodes_6379.conf、nodes_6380.conf cluster-config-file /usr/local/redis/tmp/nodes_6379.conf 11、请求超时 默认15秒,可自行设置 cluster-node-timeout 15000 12、最大使用内存 可根据业务量及机器内存配置,形式可以如21474836480、300mb、64gb maxmemory 300mb 13、根据LRU算法生成的过期时间来删除key,优先移除最近未使用的key maxmemory-policy volatile-lru 14、设置同一时间最大客户端连接数 15设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通 过AUTH <password>命令提供密码,默认关闭,如果设置,集群的所有机器要一样 requirepass <password> |
3.4 启动
- 启动各个节点
分别在3台机器上启动两个redis实例
第一台机器:
cd /usr/local/redis/redis-3.2.8
bin/redis-server etc/redis_6379.conf
bin/redis-server etc/redis_6380.conf
一台服务器上只需要部署一次redis即可,在需要启动多个实例时只要指定不通的配置文件就可以,同时配置文件中配置的文件信息需要有差别,如port、pidfile、logfile等配置要不一样,但是bind可以一样。
其他机器:同第一台机器类似,进入到相应文件夹执行启动命令,多个实例使用不同的配置文件
- 查看redis启动情况
ps -ef | grep redis
netstat -tnlp | grep redis

可以看到每台机器上都有两个redis实例分别对应不同的端口
同时查看tmp、logs等目录下
3.5 创建集群
- 安装ruyb
要搭建集群的话,需要使用一个工具(脚本文件),这个工具在redis解压文件的源代码里。因为这个工具是一个ruby脚本文件,所以这个工具的运行需要ruby的运行环境。
可以先查看机器中是否安装有ruyb,若显示版本号则已经安装,无需再安装
ruyb –v
安装ruby指令如下:
yum install ruby
然后需要把ruby相关的包安装到服务器
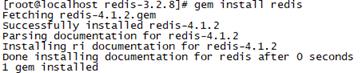
gem install redis
执行gem install redis可能会出现错误

原因是安装的ruby版本低于2.3.0,需要安装2.3.0以上的版本,可以用ruby –v查看版本

centOS7使用yum install ruby默认安装的ruby版本是2.0.0,因此需要重新安装更高版本安装过程如下
1、安装curl,可以先试下curl www.baidu.com能否成功,若成功则无需再安装(需要联网)
yum -y install curl
2、安装RVM
#curl -L get.rvm.io | bash -s stable
3、获得秘钥
gpg --keyserver hkp://keys.gnupg.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3
4、继续执行
curl -sSL https://get.rvm.io | bash -s stable
5、RVM安装完成
使用source让当前shell读入路径为/usr/local/rvm/scripts/rvm的shell文件并依次执行文件中的所有语句,并重新执行刚修改的初始化文件,使之立即生效,而不必注销并重新登录
source /usr/local/rvm/scripts/rvm
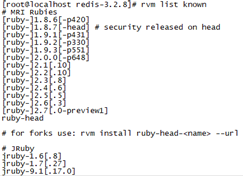
6、查看Ruby可用版本
# rvm list known
7、安装
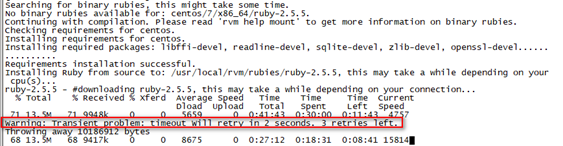
选择一个版本进行安装,这里选择2.5.5版本安装,等待时间比较长
rvm install 2.5.5
可能会出现超时问题,应该是下载时间不能超过30分钟,多试两次,取决于网络,下载网速特别慢,这一步特别浪费时间,如果能离线安装比较好
8、使用安装的2.5.5版本
rvm use 2.5.5
9、设置默认版本
rvm use 2.5.5 –default
10、查看ruby版本
ruby --version
接着返回继续执行gem install redis命令
- 执行创建集群命令
关闭防火墙或开放相应端口
Redis 官方提供了 redis-trib.rb 这个工具,就在解压目录的 src 目录中,可以将文件拷贝到bin目录中统一管理,方便使用,cp src/redis-trib.rb bin/。使用下面这个命令即可完成安装。
bin/redis-trib.rb create --replicas 1 192.168.194.97:6379 192.168.194.97:6380 192.168.194.98:6379 192.168.194.98:6380 192.168.194.99:6379 192.168.194.99:6380
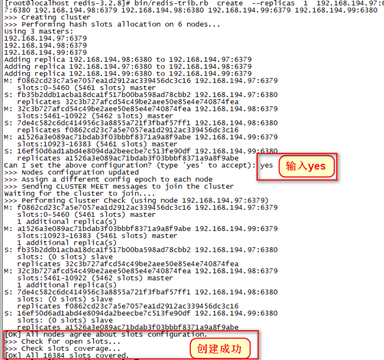
Redi集群搭建成功!在最后一段文字,显示了每个节点所分配的slots(哈希槽),这里总共6个节点,其中3个是从节点,所以3个主节点分别映射了0-5460、5461-10922、10923-16383 solts。
- 集群连接测试
连接方式为 :
bin/redis-cli -h 192.168.194.97 -c -p 6379
加参数 -C 可连接到集群,因为上面 redis.conf 将 bind 改为了ip地址,所以 -h 参数不可以省略。
添加数据,可以看到数据被平均的分配到了各个主节点中
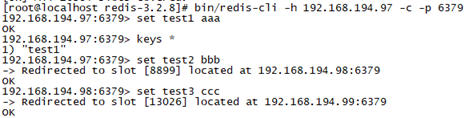
再登陆其他节点或实例查看内容(使用keys *查看列表时可能显示不全,但是数据在任何一台都可以查询到的)

查看当前集群信息
cluster info
查看集群里有多少个节点
cluster nodes
- 补充redis原理
redis cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。所以我们在测试的时候看到set 和 get 的时候,直接跳转到了其他端口端口的节点。
Redis 集群会把数据存在一个 master 节点,然后在这个 master 和其对应的salve 之间进行数据同步。当读取数据时,也根据一致性哈希算法到对应的 master 节点获取数据。只有当一个master 挂掉之后,才会启动一个对应的 salve 节点,充当 master 。
需要注意的是:必须要3个或以上的主节点,否则在创建集群时会失败,并且当存活的主节点数小于总节点数的一半时,整个集群就无法提供服务了。
linux下redis_单机版_主从_集群_部署文档的更多相关文章
- ElasticSearch 5.0.0 集群安装部署文档
1. 搭建环境 3台物理机 操作系统 centos7 es1 192.168.31.141 4g内存 2核 es2 192.168.31.142 4g内存 2核 es3 ...
- Linux下使用Magent+Memcached缓存服务器集群部署
1.编译安装libevent cd /root/soft_hhf/ wget http://cloud.github.com/downloads/libevent/libevent/libeven ...
- 分享一份关于Hadoop2.2.0集群环境搭建文档
目录 一,准备环境 三,克隆VM 四,搭建集群 五,Hadoop启动与测试 六,安装过程中遇到的问题及其解决方案 一,准备环境 PC基本配置如下: 处理器:Intel(R) Core(TM) i5-3 ...
- LVS+Keepalived+Squid+Nginx+MySQL主从高性能集群架构部署方案
方案一,在tomcat的workers.properties里面配置相关条件 worker.tomcat.lbfactor= worker.tomcat.cachesize= worker.tomca ...
- Linux下的换行符\n\r以及txt和word文档的使用
Linux doc WINDOWS下记事本编写的文档和LINUX下VIM或者GEDIT等编写的文档的不同! 例如WINDOWS下编写的SH脚本,放到LINUX下执行可能会出错. 解决方法: 原因是:W ...
- 【Redis学习专题】- Redis主从+哨兵集群部署
集群版本: redis-4.0.14 集群节点: 节点角色 IP redis-master 10.100.8.21 redis-slave1 10.100.8.22 redis-slave2 10.1 ...
- Centos6.9下RocketMQ3.4.6高可用集群部署记录(双主双从+Nameserver+Console)
之前的文章已对RocketMQ做了详细介绍,这里就不再赘述了,下面是本人在测试和生产环境下RocketMQ3.4.6高可用集群的部署手册,在此分享下: 1) 基础环境 ip地址 主机名 角色 192. ...
- Cloudera Manager安装_搭建CDH集群
2017年2月22日, 星期三 Cloudera Manager安装_搭建CDH集群 cpu 内存16G 内存12G 内存8G 默认单核单线 CDH1_node9 Server || Agent ...
- Linux下zookeeper单机版详细安装
Linux下zookeeper单机版详细安装 1.zookeeper简介 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop ...
- 大数据运维尖刀班 | 集群_监控_CDH_Docker_K8S_两项目_腾讯云服务器
说明:大数据时代,传统运维向大数据运维升级换代很常见,也是个不错的机会.如果想系统学习大数据运维,个人比较推荐通信巨头运维大咖的分享课:https://url.cn/5HIqOOr,主要是实战强.含金 ...
随机推荐
- Golang可能会踩的58个坑之初级篇
前言 Go 是一门简单有趣的编程语言,与其他语言一样,在使用时不免会遇到很多坑,不过它们大多不是 Go 本身的设计缺陷.如果你刚从其他语言转到 Go,那这篇文章里的坑多半会踩到. 如果花时间学习官方 ...
- git-secret:在 Git 存储库中加密和存储密钥(下)
在之前的文章中(点击此处查看上一篇文章),我们了解了如何识别包含密钥的文件,将密钥添加到 .gitignore ,通过 git-secret 进行加密,以及将加密文件提交到存储库.在本篇文章中,将带你 ...
- vue-axios删除操作
<template> <div class="nav"> <input v-model="location" type=" ...
- JVM学习笔记——内存结构篇
JVM学习笔记--内存结构篇 在本系列内容中我们会对JVM做一个系统的学习,本片将会介绍JVM的内存结构部分 我们会分为以下几部分进行介绍: JVM整体介绍 程序计数器 虚拟机栈 本地方法栈 堆 方法 ...
- Nginx负载均衡策略的介绍与调优
工作中经常会用到nginx负载均衡这一块,下面对nginx负载均衡策略做个总结.本人在工作中最常用到的负载均衡策略是轮询策略. 在一般情况下,Web中间件最大的作用就是负责对请求进行分发,也就是我们常 ...
- 重新整理 .net core 实践篇 ———— dotnet-dump [外篇]
前言 本文的上一篇为: https://www.cnblogs.com/aoximin/p/16861797.html 该文为dotnet-dump 和 procdump 的实战介绍一下. 正文 现在 ...
- 基于iNeuOS工业互联网平台的板材实时质检系统
1. 项目背景 刨花板生产线由于原料.生产工艺等原因,会有一些产品板面出现颤纹.漏砂.胶斑.胶块.大刨花.粉尘斑.板面划痕和油污等缺陷.表面缺陷会降低板材强度.影响板材外观和二次加工,给企业带来经济 ...
- Jenkinsfile Pipeline 使用 SSH 连接
前提 首先你需要将用到的 SSH 私钥保存到 Jenkins 的凭据中,这样你会获得一个 credentialId.这不是本文主要的内容,故不在此展开赘述,详情可参考官方文档:https://www. ...
- 😀 Java并发 - (并发基础)
Java并发 - (并发基础) 1.什么是共享资源 堆是被所有线程共享的一块内存区域.在虚拟机启动时创建.此内存区域的唯一目的就是存放对象实例 Java中几乎所有的对象实例都在这里分配内存.方法区与堆 ...
- mindxdl--common--head_handler.go
// Copyright (c) 2021. Huawei Technologies Co., Ltd. All rights reserved.// Package common the commo ...