机器学习算法(九): 基于线性判别模型的LDA手写数字分类识别
1.机器学习算法(九): 基于线性判别模型的LDA手写数字分类识别
1.1 LDA算法简介和应用
线性判别模型(LDA)在模式识别领域(比如人脸识别等图形图像识别领域)中有非常广泛的应用。LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”。我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。即:将数据投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况,相同类别的点,将会在投影后的空间中更接近方法。
LDA算法的一个目标是使得不同类别之间的距离越远越好,同一类别之中的距离越近越好。那么不同类别之间的距离越远越好,我们是可以理解的,就是越远越好区分。同时,协方差不仅是反映了变量之间的相关性,同样反映了多维样本分布的离散程度(一维样本使用方差),协方差越大(对于负相关来说是绝对值越大),表示数据的分布越分散。所以上面的“欲使同类样例的投影点尽可能接近,可以让同类样本点的协方差矩阵尽可能小”就可以理解了。
$J(w)=\frac{w^T|\mu_1 - \mu_2~|2}{s2_1+s2_2}$
如上述公式 $J(w)$ 所示,分子为投影数据后的均值只差,分母为方差之后,LDA的目的就是使得 $J$ 值最大化,那么可以理解为最大化分子,即使得类别之间的距离越远,同时最小化分母,使得每个类别内部的方差越小,这样就能使得每个类类别的数据可以在投影矩阵 $w$ 的映射下,分的越开。
需要注意的是,LDA模型适用于线性可分数据,对于上述实战中用到的MNIST手写数据(其实是分线性的),但是依然可以取得较好的分类效果;但在以后的实战中需要注意LDA在非线性可分数据上的谨慎使用。
1.2.算法应用
LDA在模式识别领域(比如人脸识别,舰艇识别等图形图像识别领域)中有非常广泛的应用,因此我们有必要了解一下它的算法原理。不过在学习LDA之前,我们有必要将其与自然语言处理领域中的LDA区分开,在自然语言处理领域,LDA是隐含狄利克雷分布(Latent DIrichlet Allocation,简称LDA),它是一种处理文档的主题模型,我们本文讨论的是线性判别分析,因此后面所说的LDA均为线性判别分析。
LDA除了可以用于降维以外,还可以用于分类。一个常见的LDA分类基本思想是假设各个类别的样本数据符合高斯分布,这样利用LDA进行投影后,可以利用极大似然估计计算各个类别投影数据的均值和方差,进而得到该类别高斯分布的概率密度函数。当一个新的样本到来后,我们可以将它投影,然后将投影后的样本特征分别带入各个类别的高斯分布概率密度函数,计算它属于这个类别的概率,最大的概率对应的类别即为预测类别。
2.相关流程
- 掌握LDA算法基本原理
- 掌握利用LDA进行代码实战
Part 1 Demo实践
- Step1:库函数导入
- Step2:模型训练
- Step3:模型参数查看
- Step4:数据和模型可视化
- Step5:模型预测
Part 2 基于LDA手写数字分类实践
- Step1:库函数导入
- Step2:数据读取/载入
- Step3:数据信息简单查看与可视化
- Step4:利用LDA在手写数字上进行训练和预测
3.代码实战
3.1 Demo实践
- Step1:库函数导入
# 基础数组运算库导入
import numpy as np
# 画图库导入
import matplotlib.pyplot as plt
# 导入三维显示工具
from mpl_toolkits.mplot3d import Axes3D
# 导入LDA模型
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# 导入demo数据制作方法
from sklearn.datasets import make_classification
- Step2:模型训练
# 制作四个类别的数据,每个类别100个样本
X, y = make_classification(n_samples=1000, n_features=3, n_redundant=0,
n_classes=4, n_informative=2, n_clusters_per_class=1,
class_sep=3, random_state=10)
# 将四个类别的数据进行三维显示
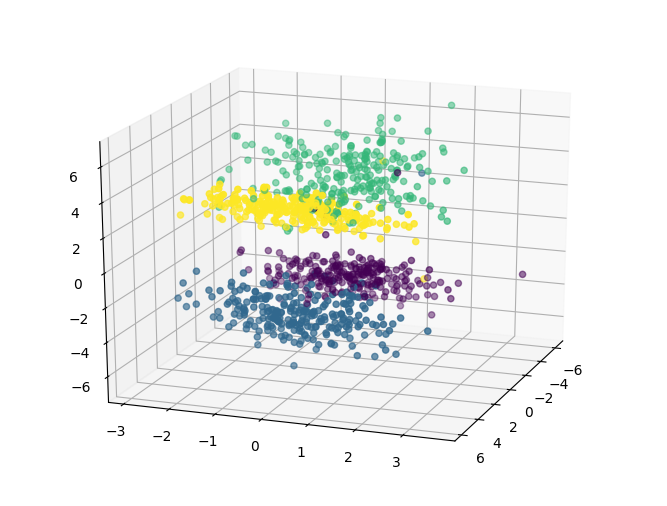
fig = plt.figure()
ax = Axes3D(fig, rect=[0, 0, 1, 1], elev=20, azim=20)
ax.scatter(X[:, 0], X[:, 1], X[:, 2], marker='o', c=y)
plt.show()
# 建立 LDA 模型
lda = LinearDiscriminantAnalysis()
# 进行模型训练
lda.fit(X, y)
LinearDiscriminantAnalysis()
- Step3:模型参数查看
# 查看 LDA 模型的参数
lda.get_params()
{'covariance_estimator': None,
'n_components': None,
'priors': None,
'shrinkage': None,
'solver': 'svd',
'store_covariance': False,
'tol': 0.0001}
- Step4:数据和模型可视化
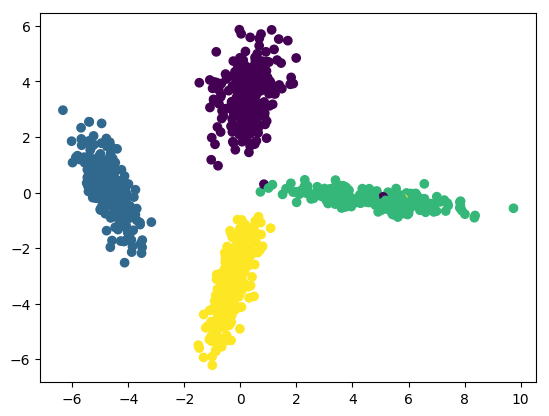
# 进行模型预测
X_new = lda.transform(X)
# 可视化预测数据
plt.scatter(X_new[:, 0], X_new[:, 1], marker='o', c=y)
plt.show()
- Step5:模型预测
# 进行新的测试数据测试
a = np.array([[-1, 0.1, 0.1]])
print(f"{a} 类别是: ", lda.predict(a))
print(f"{a} 类别概率分别是: ", lda.predict_proba(a))
a = np.array([[-12, -100, -91]])
print(f"{a} 类别是: ", lda.predict(a))
print(f"{a} 类别概率分别是: ", lda.predict_proba(a))
a = np.array([[-12, -0.1, -0.1]])
print(f"{a} 类别是: ", lda.predict(a))
print(f"{a} 类别概率分别是: ", lda.predict_proba(a))
a = np.array([[0.1, 90.1, 9.1]])
print(f"{a} 类别是: ", lda.predict(a))
print(f"{a} 类别概率分别是: ", lda.predict_proba(a))
[[-1. 0.1 0.1]] 类别是: [0]
[[-1. 0.1 0.1]] 类别概率分别是: [[9.37611354e-01 1.88760664e-05 3.36891510e-02 2.86806189e-02]]
[[ -12 -100 -91]] 类别是: [1]
[[ -12 -100 -91]] 类别概率分别是: [[1.08769337e-028 1.00000000e+000 1.54515810e-221 9.05666876e-183]]
[[-12. -0.1 -0.1]] 类别是: [2]
[[-12. -0.1 -0.1]] 类别概率分别是: [[1.60268201e-07 1.46912978e-39 9.99999840e-01 3.57001075e-28]]
[[ 0.1 90.1 9.1]] 类别是: [3]
[[ 0.1 90.1 9.1]] 类别概率分别是: [[8.42065614e-08 9.45021749e-11 8.63060269e-02 9.13693889e-01]]
3.2 Part 2 基于LDA手写数字分类实践
- Step1:库函数导入
# 导入手写数据集 MNIST
from sklearn.datasets import load_digits
# 导入训练集分割方法
from sklearn.model_selection import train_test_split
# 导入LDA模型
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# 导入预测指标计算函数和混淆矩阵计算函数
from sklearn.metrics import classification_report, confusion_matrix
# 导入绘图包
import seaborn as sns
import matplotlib
- Step2:数据读取/载入
# 导入MNIST数据集
mnist = load_digits()
# 查看数据集信息
print('The Mnist dataeset:\n',mnist)
# 分割数据为训练集和测试集
x, test_x, y, test_y = train_test_split(mnist.data, mnist.target, test_size=0.1, random_state=2)
The Mnist dataeset:
{'data': array([[ 0., 0., 5., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 10., 0., 0.],
[ 0., 0., 0., ..., 16., 9., 0.],
...,
[ 0., 0., 1., ..., 6., 0., 0.],
[ 0., 0., 2., ..., 12., 0., 0.],
[ 0., 0., 10., ..., 12., 1., 0.]]), 'target': array([0, 1, 2, ..., 8, 9, 8]), 'frame': None, 'feature_names': ['pixel_0_0', 'pixel_0_1', 'pixel_0_2', 'pixel_0_3', 'pixel_0_4', 'pixel_0_5', 'pixel_0_6', 'pixel_0_7', 'pixel_1_0', 'pixel_1_1', 'pixel_1_2', 'pixel_1_3', 'pixel_1_4', 'pixel_1_5', 'pixel_1_6', 'pixel_1_7', 'pixel_2_0', 'pixel_2_1', 'pixel_2_2', 'pixel_2_3', 'pixel_2_4', 'pixel_2_5', 'pixel_2_6', 'pixel_2_7', 'pixel_3_0', 'pixel_3_1', 'pixel_3_2', 'pixel_3_3', 'pixel_3_4', 'pixel_3_5', 'pixel_3_6', 'pixel_3_7', 'pixel_4_0', 'pixel_4_1', 'pixel_4_2', 'pixel_4_3', 'pixel_4_4', 'pixel_4_5', 'pixel_4_6', 'pixel_4_7', 'pixel_5_0', 'pixel_5_1', 'pixel_5_2', 'pixel_5_3', 'pixel_5_4', 'pixel_5_5', 'pixel_5_6', 'pixel_5_7', 'pixel_6_0', 'pixel_6_1', 'pixel_6_2', 'pixel_6_3', 'pixel_6_4', 'pixel_6_5', 'pixel_6_6', 'pixel_6_7', 'pixel_7_0', 'pixel_7_1', 'pixel_7_2', 'pixel_7_3', 'pixel_7_4', 'pixel_7_5', 'pixel_7_6', 'pixel_7_7'], 'target_names': array([0, 1, 2, 3, 4, 5, 6, 7,
[ 0., 0., 13., ..., 15., 5., 0.],
[ 0., 3., 15., ..., 11., 8., 0.],
...,
[ 0., 4., 11., ..., 12., 7., 0.],
[ 0., 2., 14., ..., 12., 0., 0.],
[ 0., 0., 6., ..., 0., 0., 0.]],
[[ 0., 0., 0., ..., 5., 0., 0.],
[ 0., 0., 0., ..., 9., 0., 0.],
[ 0., 0., 3., ..., 6., 0., 0.],
...,
[ 0., 0., 1., ..., 6., 0., 0.],
[ 0., 0., 1., ..., 6., 0., 0.],
[ 0., 0., 0., ..., 10., 0., 0.]],
[[ 0., 0., 0., ..., 12., 0., 0.],
[ 0., 0., 3., ..., 14., 0., 0.],
[ 0., 0., 8., ..., 16., 0., 0.],
...,
[ 0., 9., 16., ..., 0., 0., 0.],
[ 0., 3., 13., ..., 11., 5., 0.],
[ 0., 0., 0., ..., 16., 9., 0.]],
...,
[[ 0., 0., 1., ..., 1., 0., 0.],
[ 0., 0., 13., ..., 2., 1., 0.],
[ 0., 0., 16., ..., 16., 5., 0.],
...,
[ 0., 0., 16., ..., 15., 0., 0.],
[ 0., 0., 15., ..., 16., 0., 0.],
[ 0., 0., 2., ..., 6., 0., 0.]],
[[ 0., 0., 2., ..., 0., 0., 0.],
[ 0., 0., 14., ..., 15., 1., 0.],
[ 0., 4., 16., ..., 16., 7., 0.],
...,
[ 0., 0., 0., ..., 16., 2., 0.],
[ 0., 0., 4., ..., 16., 2., 0.],
[ 0., 0., 5., ..., 12., 0., 0.]],
[[ 0., 0., 10., ..., 1., 0., 0.],
[ 0., 2., 16., ..., 1., 0., 0.],
[ 0., 0., 15., ..., 15., 0., 0.],
...,
[ 0., 4., 16., ..., 16., 6., 0.],
[ 0., 8., 16., ..., 16., 8., 0.],
[ 0., 1., 8., ..., 12., 1., 0.]]]), 'DESCR': ".. _digits_dataset:\n\nOptical recognition of handwritten digits dataset\n--------------------------------------------------\n\n**Data Set Characteristics:**\n\n :Number of Instances: 1797\n :Number of Attributes: 64\n :Attribute Information: 8x8 image of integer pixels in the range 0..16.\n :Missing Attribute Values: None\n :Creator: E. Alpaydin (alpaydin '@' boun.edu.tr)\n :Date: July; 1998\n\nThis is a copy of the test set of the UCI ML hand-written digits datasets\nhttps://archive.ics.uci.edu/ml/datasets/Optical+Recognition+of+Handwritten+Digits\n\nThe data set contains images of hand-written digits: 10 classes where\neach class refers to a digit.\n\nPreprocessing programs made available by NIST were used to extract\nnormalized bitmaps of handwritten digits from a preprinted form. From a\ntotal of 43 people, 30 contributed to the training set and different 13\nto the test set. 32x32 bitmaps are divided into
- Step3:数据信息简单查看与可视化
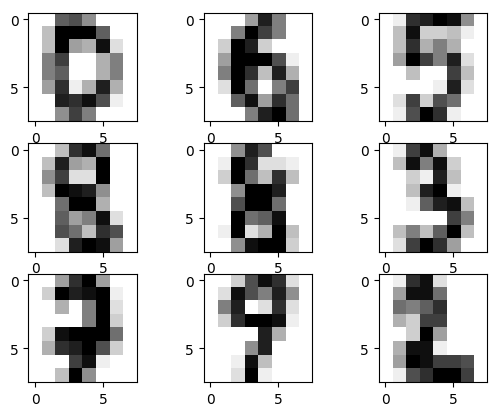
## 输出示例图像
images = range(0,9)
plt.figure(dpi=100)
for i in images:
plt.subplot(330 + 1 + i)
plt.imshow(x[i].reshape(8, 8), cmap = matplotlib.cm.binary,interpolation="nearest")
# show the plot
plt.show()
- Step4:利用LDA在手写数字上进行训练和预测
# 建立 LDA 模型
m_lda = LinearDiscriminantAnalysis()
# 进行模型训练
m_lda.fit(x, y)
LinearDiscriminantAnalysis()
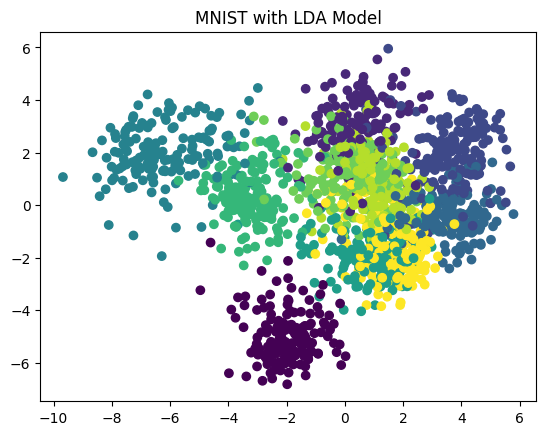
# 进行模型预测
x_new = m_lda.transform(x)
# 可视化预测数据
plt.scatter(x_new[:, 0], x_new[:, 1], marker='o', c=y)
plt.title('MNIST with LDA Model')
plt.show()
# 进行测试集数据的类别预测
y_test_pred = m_lda.predict(test_x)
print("测试集的真实标签:\n", test_y)
print("测试集的预测标签:\n", y_test_pred)
测试集的真实标签:
[4 0 9 1 4 7 1 5 1 6 6 7 6 1 5 5 4 6 2 7 4 6 4 1 5 2 9 5 4 6 5 6 3 4 0 9 9
8 4 6 8 8 5 7 9 6 9 6 1 3 0 1 9 7 3 3 1 1 8 8 9 8 5 4 4 7 3 5 8 4 3 1 3 8
7 3 3 0 8 7 2 8 5 3 8 7 6 4 6 2 2 0 1 1 5 3 5 7 6 8 2 2 6 4 6 7 3 7 3 9 4
7 0 3 5 8 5 0 3 9 2 7 3 2 0 8 1 9 2 1 9 1 0 3 4 3 0 9 3 2 2 7 3 1 6 7 2 8
3 1 1 6 4 8 2 1 8 4 1 3 1 1 9 5 4 8 7 4 8 9 5 7 6 9 0 0 4 0 0 4]
测试集的预测标签:
[4 0 9 1 8 7 1 5 1 6 6 7 6 2 5 5 8 6 2 7 4 6 4 1 5 2 9 5 4 6 5 6 3 4 0 9 9
8 4 6 8 1 5 7 9 6 9 6 1 3 0 1 9 7 3 3 1 1 8 8 9 8 5 8 4 9 3 5 8 4 3 9 3 8
7 3 3 0 8 7 2 8 5 3 8 7 6 4 6 2 2 0 1 1 5 3 5 7 1 8 2 2 6 4 6 7 3 7 3 9 4
7 0 3 5 1 5 0 3 9 2 7 3 2 0 8 1 9 2 1 9 9 0 3 4 3 0 8 3 2 2 7 3 1 6 7 2 8
3 1 1 6 4 8 2 1 8 4 1 3 1 1 9 5 4 9 7 4 8 9 5 7 6 9 6 0 4 0 0 9]
# 进行预测结果指标统计 统计每一类别的预测准确率、召回率、F1分数
print(classification_report(test_y, y_test_pred))
precision recall f1-score support
0 1.00 0.93 0.96 14
1 0.86 0.86 0.86 22
2 0.93 1.00 0.97 14
3 1.00 1.00 1.00 22
4 1.00 0.81 0.89 21
5 1.00 1.00 1.00 16
6 0.94 0.94 0.94 18
7 1.00 0.94 0.97 18
8 0.80 0.84 0.82 19
9 0.75 0.94 0.83 16
accuracy 0.92 180
macro avg 0.93 0.93 0.93 180
weighted avg 0.93 0.92 0.92 180
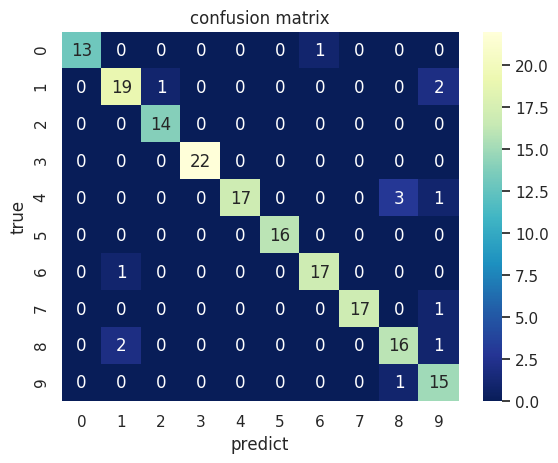
# 计算混淆矩阵
C2 = confusion_matrix(test_y, y_test_pred)
# 打混淆矩阵
print(C2)
# 将混淆矩阵以热力图的防线显示
sns.set()
f, ax = plt.subplots()
# 画热力图
sns.heatmap(C2, cmap="YlGnBu_r", annot=True, ax=ax)
# 标题
ax.set_title('confusion matrix')
# x轴为预测类别
ax.set_xlabel('predict')
# y轴实际类别
ax.set_ylabel('true')
plt.show()
[[13 0 0 0 0 0 1 0 0 0]
[ 0 19 1 0 0 0 0 0 0 2]
[ 0 0 14 0 0 0 0 0 0 0]
[ 0 0 0 22 0 0 0 0 0 0]
[ 0 0 0 0 17 0 0 0 3 1]
[ 0 0 0 0 0 16 0 0 0 0]
[ 0 1 0 0 0 0 17 0 0 0]
[ 0 0 0 0 0 0 0 17 0 1]
[ 0 2 0 0 0 0 0 0 16 1]
[ 0 0 0 0 0 0 0 0 1 15]]
4.总结
LDA算法的主要优点:
- 在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识;
- LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
LDA算法的主要缺点:
- LDA不适合对非高斯分布样本进行降维,PCA也有这个问题
- LDA降维最多降到类别数 k-1 的维数,如果我们降维的维度大于 k-1,则不能使用 LDA。当然目前有一些LDA的进化版算法可以绕过这个问题
- LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好
- LDA可能过度拟合数据,
本项目链接:https://www.heywhale.com/home/column/64141d6b1c8c8b518ba97dcc
参考链接:https://tianchi.aliyun.com/course/278/3426
本人最近打算整合ML、DRL、NLP等相关领域的体系化项目课程,方便入门同学快速掌握相关知识。声明:部分项目为网络经典项目方便大家快速学习,后续会不断增添实战环节(比赛、论文、现实应用等)。
- 对于机器学习这块规划为:基础入门机器学习算法--->简单项目实战--->数据建模比赛----->相关现实中应用场景问题解决。一条路线帮助大家学习,快速实战。
- 对于深度强化学习这块规划为:基础单智能算法教学(gym环境为主)---->主流多智能算法教学(gym环境为主)---->单智能多智能题实战(论文复现偏业务如:无人机优化调度、电力资源调度等项目应用)
- 自然语言处理相关规划:除了单点算法技术外,主要围绕知识图谱构建进行:信息抽取相关技术(含智能标注)--->知识融合---->知识推理---->图谱应用
上述对于你掌握后的期许:
- 对于ML,希望你后续可以乱杀数学建模相关比赛(参加就获奖保底,top还是难的需要钻研)
- 可以实际解决现实中一些优化调度问题,而非停留在gym环境下的一些游戏demo玩玩。(更深层次可能需要自己钻研了,难度还是很大的)
- 掌握可知识图谱全流程构建其中各个重要环节算法,包含图数据库相关知识。
这三块领域耦合情况比较大,后续会通过比如:搜索推荐系统整个项目进行耦合,各项算法都会耦合在其中。举例:知识图谱就会用到(图算法、NLP、ML相关算法),搜索推荐系统(除了该领域召回粗排精排重排混排等算法外,还有强化学习、知识图谱等耦合在其中)。饼画的有点大,后面慢慢实现。
机器学习算法(九): 基于线性判别模型的LDA手写数字分类识别的更多相关文章
- 在opencv3中实现机器学习算法之:利用最近邻算法(knn)实现手写数字分类
手写数字digits分类,这可是深度学习算法的入门练习.而且还有专门的手写数字MINIST库.opencv提供了一张手写数字图片给我们,先来看看 这是一张密密麻麻的手写数字图:图片大小为1000*20 ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
- GAN实战笔记——第三章第一个GAN模型:生成手写数字
第一个GAN模型-生成手写数字 一.GAN的基础:对抗训练 形式上,生成器和判别器由可微函数表示如神经网络,他们都有自己的代价函数.这两个网络是利用判别器的损失记性反向传播训练.判别器努力使真实样本输 ...
- 机器学习之路:python k均值聚类 KMeans 手写数字
python3 学习使用api 使用了网上的数据集,我把他下载到了本地 可以到我的git中下载数据集: https://github.com/linyi0604/MachineLearning 代码: ...
- 使用AI算法进行手写数字识别
人工智能 人工智能(Artificial Intelligence,简称AI)一词最初是在1956年Dartmouth学会上提出的,从那以后,研究者们发展了众多理论和原理,人工智能的概念也随之扩展 ...
- 【百度飞桨】手写数字识别模型部署Paddle Inference
从完成一个简单的『手写数字识别任务』开始,快速了解飞桨框架 API 的使用方法. 模型开发 『手写数字识别』是深度学习里的 Hello World 任务,用于对 0 ~ 9 的十类数字进行分类,即输入 ...
- OpenCV手写数字字符识别(基于k近邻算法)
摘要 本程序主要参照论文,<基于OpenCV的脱机手写字符识别技术>实现了,对于手写阿拉伯数字的识别工作.识别工作分为三大步骤:预处理,特征提取,分类识别.预处理过程主要找到图像的ROI部 ...
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 基于OpenCV的KNN算法实现手写数字识别
基于OpenCV的KNN算法实现手写数字识别 一.数据预处理 # 导入所需模块 import cv2 import numpy as np import matplotlib.pyplot as pl ...
- 手写数字识别 ----Softmax回归模型官方案例注释(基于Tensorflow,Python)
# 手写数字识别 ----Softmax回归模型 # regression import os import tensorflow as tf from tensorflow.examples.tut ...
随机推荐
- Netty基本编写
一. public class Server { public static void main(String[] args) throws Exception { //1 创建线两个程组 //一个是 ...
- vue后台管理系统——商品管理模块
电商后台管理系统的功能--商品管理模块 商品管理概述 商品管理模块用于维护电商平台的商品信息,包括商品的类型.参数.图片.详情等信息. 通过商品管理模块可以实现商品的添加.修改.展示和删除等功能. 1 ...
- windows 10 的VMware workstation Pro突然变成英文界面
电脑的VMware虚拟机界面是中文版的,后来在捣弄些电脑配置,突然变成英文版界面了. 后面发现原来是区域格式选错了:正确的格式是下图红框
- vue npm安装指令汇总
1.elmentui:npm i element-ui -S 2.打印插件:npm install vue-print-nb --save 3.时间转换插件Moment:npm install mom ...
- axios使用总结
一.请求配置 // 引入import axios from 'axios';import qs from 'qs';this.$axios({ method:"get", // g ...
- 如何卸载cad 2022?怎么把cad 2022彻底卸载删除干净重新安装的方法【转载】
标题:cad 2022重新安装方法经验总结,利用卸载清理工具完全彻底排查删除干净cad 2022各种残留注册表和文件.cad 2022显示已安装或者报错出现提示安装未完成某些产品无法安装的问题,怎么完 ...
- Vue+SSM+Element-Ui实现前后端分离(3)
前言:经过博文(1)vue搭建,(2)ssm搭建,到这里就该真真切切的实现小功能了<-_-> 规划:实现登录,用户列表查询,访问日志aop; 开始先解决跨域:在目录config/index ...
- power shell 删除应用
public static UwpAppInfo SearchUwpAppByName(string appName) { UwpAppInfo app = null; try { string re ...
- MySQL日常维护指南
一.常用命令 1.查看数据库默认编码 show variables like 'character%'; show variables like 'collation%'; 2.启动停止数据库 /et ...
- day49-数据类型、约束条件
数据类型: 1.整型--默认情况下都是带有符号的, id int(8)-- 如果数字没有超过9位,默认用0填充,如果数字超出8位,有几位存几位 总结:针对整型字段,括号内无需指定宽度,因为它默认的宽度 ...