Mysql 存储引擎以及 SQL语句
存储引擎
文件格式有很多种,针对不同的文件格式会有对应的不同存储方式和处理机制。
针对不同的数据应该有对应的不同处理机制来存储。
存储引擎就是不同的处理机制
MySQL主要的存储引擎
Innodb
是MySQL5.5版本之后默认的存储引擎
存储数据更加安全
myisam
是MySQL5.5版本之前默认的存储引擎
速度比Innodb快,但是我们更注重于数据的安全
memory
内存引擎(数据全部存放在内存中)断电数据丢失
blackhole
无论存储什么立刻消失(黑洞)
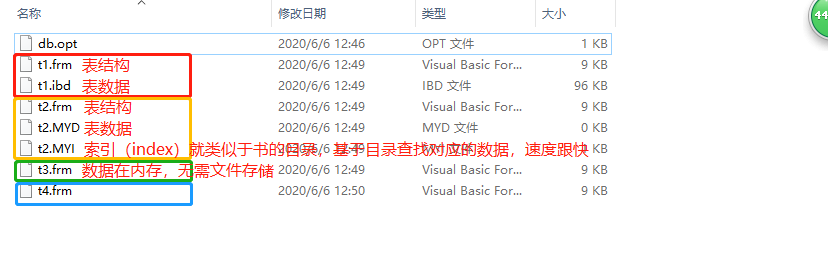
'''
# 查看所有的存储引擎
show engines;
# 不同的存储引擎在存储的时候 异同点
create table t1(id int) engine=innodb;
create table t2(id int) engine=myisam;
create table t3(id int) engine=memory;
create table t4(id int) engine=blackhole;
# 存储数据
insert into t1 value(1);
insert into t2 value(1);
insert into t3 value(1);
insert into t4 value(1);
'''
创建表的完整语法
# 语法
create table 表名(
字段名1 类型(宽度) 约束条件,
字段名2 类型(宽度) 约束条件,
字段名3 类型(宽度) 约束条件
)
# 注意
1 在同一张表中字段名不能重复
2 宽度和约束条件是可选的(可写可不写)而字段名和字段类型是必须
约束条件可以写多个
字段名1 类型(宽度) 约束条件1 约束条件2 ...,
3 最后一行不能有逗号
create table t5(
id int,
name char,
); 报错
'''补充'''
# 宽度
一般情况下值的是对存储数据的限制
create table t6(name char); 默认宽度为1
insert into t6 values('hp');
insert into t6 values(null); null是关键字
针对不同的版本会出现不同的效果
5.6版本默认没有开启严格模式,规定只能存一个字符,给了对多个字符,会自动截取。
5.7版本以上或者开启严格模式,规定只能存几个就不能超过,一旦超过范围就会立刻报错。
# 约束条件 null not null 不能插入null
create table t7(id int,name char not null); #限制name插入null
'''
宽度和约束条件的关系
宽度是用来限制数据的存储
约束条件是在宽度的基础之上增加的而外的约束
'''

严格模式
# 查看严格模式
show variables like "%mode";
'''
模糊匹配
关键字 like
%:匹配任意多个字符
_: 匹配任意单个字符
'''
# 修改严格模式
set session 只在当前窗口有效
set global 全局有效
set global sql_mode = 'STRICT_TRANS_TABLES';
修改完成后重新进入服务端
MySQL的基本数据类型
整型
分类
TINYINT、SAMLLINT、MEDUIMINT、INT、BINGINT
作用
存储年龄、等级、id、号码等
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1字节 | (-128, 127) | (0, 255) | 小整数值 |
| SAMLLINT | 2字节 | (-32 768, 32 767) | (0, 65535) | 大整数值 |
| MEDUIMINT | 3字节 | (-8 388 608, 8 388 607) | (0, 16777215) | 大整数值 |
| INT或INTEGER | 4字节 | (-2 147 483 648, 2 147 483 647) | (0, 4294967295) | 大整数值 |
| BINGINT | 8字节 | (-9 233 372 036 854 775 808, 9 233 372 036 854 775 807) | (0, 18446744073709551615) | 极大整数值 |
'''
整型默认情况下都是带有符号的
以TINYINT
是否有符号
默认情况下是带符号的
超出如何
超出限制只存最大可接受值
'''
create table t8(id tinyint);
insert into t8 values(-128),(256);
# 约束条件之unsigned 无符号
create table t9(id tinyint unsigned);
"""
特例:只有整型括号里面的数字不是表示限制的位数而是显示的长度
id int(8)
如果数字没有超出8位 默认用空格填至8
如果数字超出8位 那么有几位就存几位(遵守最大范围)
"""
create table t10(id int(8) unsigned zerofill)
# unsigned无字符,zerofill用0填充至8位
总结
针对整型字段 括号内无需指定宽度,默认的宽度足够显示所有的数据
浮点型
分类
FLOAT、DOUBLE、DECIMAL
作用
存储身高、体重、薪资等
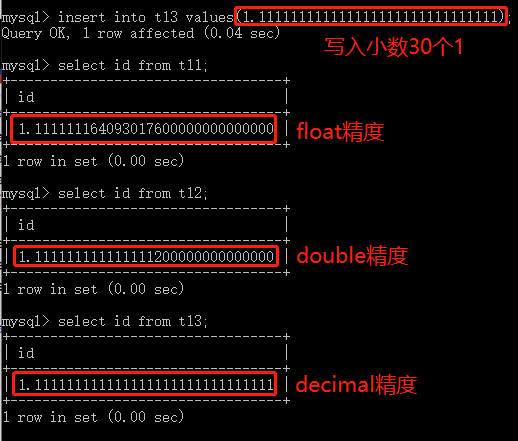
# 存储限制
float(255,30) # 总共255位,小数部分占30位
double(255,30) # 总共255位,小数部分占30位
decimal(65,30) # 总共65位,小数部分占30位
# 精确度验证
create table t11(id float(255,30));
create table t12(id double(255,30));
create table t13(id decimal(65,30));
写入
insert into t11 values(1.111111111111111111111111111111);
insert into t12 values(1.111111111111111111111111111111);
insert into t13 values(1.111111111111111111111111111111);
精确度
float < double < decimal
字符类型
分类
'''
char
定长
char(4) 超过四个字符直接报错,不够四个字符空格补全
varchar
变长
varchar(4) 数据超过四个字符直接报错,不够有几个存几个
'''
create table t14(name char(4));
create table t15(name varchar(4));
insert into t14 values('a');
insert into t15 values('a');
# 验证是否补全四个空格
# 通过char_length统计字段长度
select char_length(name) from t14;
select char_length(name) from t15;
'''
可以肯定的是 char硬盘上存的绝对是真正的数据 带有空格
但是在显示的时候MySQL会自动将多余的空格剔除
'''
# 修改 sql_mode 让MySQL不要自动剔除操作
set global sql_mode = 'STRICT_TRANS_TABLES,PAD_CHAR_TO_FULL_LENGYH';
char与varchar对比
'''
char:
缺点:浪费空间
优点:存储简单
直接按照固定的字符存储数据即可
按照几个字符存,取出也是按照几个字符
varchar:
优点:节省空间
缺点:存取较麻烦
存储的时候需要制作报头
取值的时候先读取报头,再读取数据
'''
时间类型
分类
date:年月日 2020-06-07
datetime:年月日时分秒 2020-06-07 12:12:12
time:时分秒 12:12:12
year:年 2020
create table student(
id int,
name varchar(16),
born_year year, #出生年份
birth data, #生日
study_time time, #日期
reg_time datatime #注册时间
);
insert into student values(1,'hp','2020','2020-01-01','11:11:11','2020-06-07 11:11:11');
枚举与集合类型
分类
'''
枚举(enum):多选一
集合(set):多选多
'''
使用
create table user(
id int,
name char(16),
gender enum('male','female','others')
);
insert into user values(1,'hp','male');
insert into user values(2,'sj','xxxxx'); #报错
# 枚举字段,后期在存储数据的时候只能在枚举里面选择一个存储
create table teacher(
id int,
name char(16),
gender enum('male','female','others'),
hobby set('read','rap','sing')
);
insert into teacher values(1,'hp','male','read');
insert into teacher values(2,'sj','famale','read,rap,sing');
insert into teacher values(2,'mzx','others','篮球'); # 报错
# 集合,可以只写一个,但不能写没有列举的
约束条件
default默认值
# 补充知识
# 插入数据的时候可以指定字段
create table t1(
id int,
name char(16)
);
insert into t1(name,id) values('hp',1);
# 默认值
create table t2(
id int,
name char(16)
gender enum('male','female','others') default 'male'
);
insert into t2(id,name) values(1,'hp'); # 默认为male
insert into t2 values(2,'sj','female');
unique 唯一
# 单列唯一
create table t3(
id int unique,
name cahr(16)
);
insert into t3 values(1,'hp'),(1,'sj'); # 报错
insert into t3 values(1,'hp'),(2,'sj');
# 联合唯一
'''
ip和port端口
单个都可以重复,但是加载一起必须是唯一的
'''
create table t4(
id int,
ip cahr(16),
port int,
unique(ip,port)
);
insert into t4 values(1,'127.0.0.1',8080);
insert into t4 values(2,'127.0.0.1',8081);
insert into t4 values(3,'127.0.0.1',8080); # 报错
primary key主键
'''
1.约束效果上看primary key等价于 not null + unique
非空且唯一
'''
create table t5(id int primary key);
insert into t5 values(null); #报错
insert into t5 values(1),(1); #报错
insert into t5 values(1),(2);
'''
2.除了有约束效果之外,还有Innodb存储引擎组织数据的依据
Innodb存储引擎在创建表的时候必须有primary key
它类似于书的目录,能够帮助提示插叙效率并且也是创建表的依据
'''
# 1)一张表中有且只有一个主键,如果没有设置主键,name会从上往下搜索直到遇到一个非空且唯一的字段将它自动升级为主键
create table t6(
id int,
name char(16),
age int not null unique,
addr char(32) not null unique
);
# 2)如果表中没有主键也没有其他任何非空且唯一字段,那么Innodb会采用自己内部提供的隐藏字段作为主键,隐藏字段意味着无法使用它,就无法提示查询速度
# 3)一张表中通常都应该有一个主键字段并且通常将id、uid、sid字段作为主键
# 单个字段主键
create table t7(
id int primary key,
name cahr(16)
);
# 联合主键(多个字段联合起来作为表的主键,本质还是一个主键)
create table t8(
id int,
ip cahr(16),
port int,
primary key(ip,port)
);
"""
创建id、uid、sid字段一定要加primary key
"""
auto_increment自增
'''
当编号特别多的时候,人为去维护十分麻烦
'''
create table t9(
id int primary key auto_increment,
name char(16)
);
insert into t8(name) values('hp'),('sj'),('mzx')
# 注意auto_increment只能加在主键上,不能加在普通字段
补充
delete from t9;在删除表中的数据的时候,主键的自增不会停止
truncate t9; 清空数据并且重置主键
表与表之间的关系
外键foregin key
外键就是用来帮助我们建立表与表之间的关系。
表关系
表与表之间的关系(四种):
- 一对多关系
- 多对多关系
- 一对一关系
- 没有关系
一对多关系
'''
以员工和部门为例:
在员工方面思考:一个员工只能对应一个部门
在部门方面思考:一个部门可以对应多个员工
员工与部门是单向的一对多关系。
'''
**********************************
1.一对多关系,外键字段建立在多的一方
2.创建表的时候,一定先建被关联表
3.在录入数据的时候,必须先录入被关联表
**********************************
# SQL语句建立关系
# 部门表(dep)
create table dep(
id int primary key auto_increment,
dep_name char(16),
dep_desc char(32)
);
# 员工表(emp)
create table emp(
id int primary key auto_increment,
name char(16),
gender enum('male','female','others') default 'male',
dep_id int,
foregin key(dep_id) references dep(id) # dep_id为外键与dep表的id有关系(references)
);
# 修改dep表里面的id字段(不行,报错)
update dep set id=200 where id=2;
# 删除dep表里面的数据(不行,报错)
delete from dep;
'''
如何删除?
'''
# 1.先删除员工对应部门表某个部门的所有员工的数据,再删除部门(操作太过繁琐)
# 2.真正做到数据之间的关系
更新同步更新
删除同步删除
'''
级联更新 on update cascade
级联删除 on delete cascade
'''
# 部门表(dep)
create table dep(
id int primary key auto_increment,
dep_name char(16),
dep_desc char(32)
);
# 员工表(emp)
create table emp(
id int primary key auto_increment,
name char(16),
gender enum('male','female','others') default 'male',
dep_id int,
foregin key(dep_id) references dep(id)
on update cascade # 同步更新
on delete cascade # 同步删除
# dep_id为外键与dep表的id有关系(references)同步更新和同步删除
);
多对多关系
'''
以书籍和作者为例:
一本书可以是多个作者写的
一个作者可以写多本书
所有作者与书籍是双向的多对多关系
'''
# 书籍表
create table book(
id int primary key auto_increment,
title varchar(32),
price int
);
# 作者表
create table author(
id int primary key auto_increment,
name varchar(32),
age int
);
# 媒介表
create table book2author(
id int primary key auto_increment,
book_id,
foregin key(book_id) references book(id)
on update cascade
on detele cascade,
author_id,
foregin key(author_id) references author(id)
on update cascade
on detele cascade
)
一对一关系
'''
以生份证为例:
一个生份证号对应一个人
一个人只有一个生份证号
一个人与一个身份证号的关系是一对一或者没有关系
'''
一对一外键字段健在任意一方都可以,但是推荐健在查询频率比较高的表中
# 作者信息
create table authordatail(
id int primary key auto_increment,
phone int,
addr varchar(64)
);
# 作者
create table author(
id int primary key auto_increment,
name varchar(32),
age int,
authordatail_id int unique,
foregin key(authordatail_id) references authordatail(id)
on update cascade
on delete cascade
)
修改表
# MySQL 不区分大小写
'''
1.修改表名
alter table 表名 rename 新表名;
2.增加字段
alter table 表名 add 字段 字段类型(宽度) 约束条件; #在尾部
alter table 表名 add 字段 字段类型(宽度) 约束条件 fitst; #头部
alter table 表名 add 字段 字段类型(宽度) 约束条件 after 字段名; #在某个字段后面
3.删除字段
alter table 表名 drop 字段名;
4.修改字段
alter table 表名 modify 字段名 字段类型(宽度) 约束条件;
alter table 表名 change 旧字段名 新字段名 字段类型(宽度) 约束条件;
'''
复制表
'''
sql语句查询的结果其实是一张虚拟表
'''
create table 新表名 select * from 旧表名; #不能复制主键,外键,索引等,只能复制表结构和数据
SQL其他命令
前期表准备
create table emp(
id int not null unique auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male',
age int(3) unsigned not null default 28,
hire_date date not null, # 雇佣数据
post varchar(50), # 职位
post_comment varchar(100), # 职位描述
salary double(15,2), # 薪资
office int, # 办公室
depart_id int # 职位id
);
# 插入记录
# 三个部门:运营,销售,教师
insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values
('hp','male',18,'20200101','teacher',1000000,101,1),
('sj','female',20,'20190202','teacher',10001.11,402,1),
('mzx','female',22,'20170504','teacher',1000.55,206,1),
('小明','male',25,'20160426','teacher',7542,311,1),
('小蓝','male',24,'20150211','sale',4542.89,401,2),
('曦曦','female',23,'20140526','sale',5542.55,403,2),
('月月','female',24,'20160116','sale',5552.34,405,2),
('乐乐','female',23,'20141106','operation',11252.34,406,3),
('木木','male',22,'20121222','operation',45262.34,406,3);
# 当表字段特别多展示的时候错乱可以使用\G分行展示
select * from emp\G;
# 插入中文的时候可能出现乱码或者空白的现象,将字符编码统一设置成GBK
几个关键字的执行顺序
# 书写顺序
select id,namme from emp where id > 3;
# 执行顺序
from -> where -> select
'''
虽然执行顺序和书写顺序不一致,在写sql语句的时候不知道这么写
可以先按照书写顺序的 方式写sql
select * 先用*号占位
之后补全后面的SQL语句
之后将 * 号替换想要的具体字段
'''
where约束条件
# 作用:对整体数据的一个筛选操作
# 1.查询id大于等3小于等于6的数据
select * from emp where id >=3 and id <=6;
select * from emp where id between 3 and 6; # between 在什么之间
# 2.查询年龄是22或者23或者25的数据
select * from emp where age=22 or age=23 or age=25;
select * from emp where age in (22,23,25);
# 3.查询员工姓名中包含字母h的员工的姓名和薪资
'''
模糊查询,关键字:like
% 任意多个字符
- 任意一个字符
'''
select name,salary from emp where name like '%m%';
# 4.查询员工姓名是由三个字符组成的 名字和薪资的员工 char_length()
select name,salary from emp where name like '___';
select name,salary from emp where char_length(name)=3;
# 5.查询id小于3 或者 id大于6的
select * from emp where id < 3 or id > 6;
select * from emp where id not between 3 and 6 ;
# 6.查询岗位描述为空的员工姓名和岗位名 针对null不能用等号 用is
select name,post from emp where post_comment=null; #报错
select name,post from emp where post_comment is null;
group by分组
# 1.按照部门分组
select * from emp group by post;
'''
分组之后,最小可操作单位应该是组 而不是组内的单个数据
上述命令在没有设置严格模式的时候可正常执行,返回的是分组之后每个组的第一条数据
但是这不符合分组的规范:分组之后不应该考虑单个数据,而考虑以组为单位(分组之后,无法直接获取组内的单个数据)
设置严格模式上述命令直接报错!
'''
# 设置严格模式
set global sql_mode = 'strict_trans_tables,only_full_group_by';
设置严格模式之后,分组 默认只能拿到分组的依据
按照什么分组只能拿到什么分组
select post from emp group by post;
其他字段不能直接获取需要借助于其他方法(聚合函数)
'''
聚合函数:
max
min
avg
sum
count
'''
# 1.获取每个部门的最高薪资
select post,max(salary) from emp group by post;
select post as '部门',max(salary) as '最高薪资' from emp group by post;
# as可以给字段起别名,也可以直接忽略不写
# 2.获取每个部门的最低薪资
select post,min(salary) from emp group by post;
# 3.获取每个部门的平局薪资
select post,avg(salary) from emp group by post;
# 4.获取每个部门的工资总和
select post,sum(salary) from emp group by post;
# 5.获取每个部门的人数
select post,count(id) from emp group by post;
select post,count(salary) from emp group by post;
select post,count(age) from emp group by post;
select post,count(post_comment) from emp group by post; # 报错 Null不可以计数
# 6.查询分组之后的部门名称和每个部门下的所有员工的姓名
# group_concat 不但可以支持获取分组之后的其他字段值,还支持拼接操作
select post,group_concat(name) from emp group by post;
select post,group_concat(name,'_nb') from emp group by post; # 拼接_nb
select post,group_concat(name,':',age) from emp group by post; # 多个字段
#concat 不分组的时候使用
select concat('name:',name),concat('age:',age) from emp;
# 补充:# as可以给字段起别名,也可以给表起别名
select emp.id from emp;
select emp.id from emp as 员工表; # 报错
select 员工表.id from emp as 员工表;
分组的属于事项
# 关键字where和group by同时出现的时候group by必须在where的后面。
where先对整体的数据进行过滤再对分组操作
聚合函数只能在分组之后使用,where筛选条件不能使用聚合函数
select id,name age from emp where max(salary) > 3000; # 报错
select max(salary) from emp; # 不分组,默认整体就是一组
# 统计部门在22岁以上的员工平均薪资
1 先求所有年龄大于22 岁的员工
select * from emp where age > 22;
2 在对结果进行分组
select post,avg(salary) from emp where age > 22 group by post;
having分组之后的筛选条件
'''
having的语法和where是一致的
只不过having 是在分组之后进行过滤操作
having可以直接使用聚合函数
'''
# 统计各部门年龄在22岁以上的员工工资并保留平均工资大于10000的部门
select post,avg(salary) from emp
where age > 22
group by post
having avg(salary) > 10000
;
distinct去重
'''
一定要注意,必须是完全一样的数据才可以去重!
不要忽视主键!有主键的情况下不可能去重
'''
select distinct id,age from emp; #不能去重
select distinct age from emp;
order by 排序
select * from emp order by salary;
select * from emp order by salary asc;
select * from emp order by salary desc;
'''
order by 默认是升序,关键字:asc ,asc可以省略不写
修改为降序,关键字:desc
'''
# 先按照年龄降序 碰到年龄相同在按照薪资升序排
select * from emp order by age desc,salary asc;
# 统计各部门年龄在22岁以上的员工工资并保留平均工资大于5000的部门,然后对平均工资进行排序
select post,avg(salary) from emp
where age > 22
group by post
having avg(salary)
order by avg(salary)
;
limit限制展示条数
select * from emp;
'''针对数据过多的情况,通常都是做分页处理'''
select * from emp limit 3; # 只展示3条数据
select * from emp limit 0,5;
select * from emp limit 5,5;
第一个为起始位置
第二个为展示条数
正则表达式
select * from emp where name regexp '^h.*(p|y)$';
多表操作
前期表准备
# 建表
create table dep(
id int not null unique,
name varchar(20)
);
create table emp1(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
# 插入数据
insert into dep values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运用');
insert into emp1(name,sex,age,dep_id) values
('hp','male',18,200),
('sj','female',20,201),
('mzx','female',22,202),
('tank','male',21,203),
('who','male',24,204);
表查询
# 拼表
select * from dep,emp1; # 结果,笛卡尔积,不是想要的结果
select * from emp1,dep where emp1.dep_id = dep.id;
'''
MySQL 开设对应的方法进行拼表操作
inner join 内连接
left join 左连接
right join 右连接
union 全连接
'''
# inner join 内连接
select * from emp1 inner join dep on emp1.dep_id = dep.id;
# 只拼接两张表中公有的数据部分
# left join 左连接
select * from emp1 left join dep on emp1.dep_id = dep.id;
# 左表所有的数据都展示出来,没有对应的数据用NULL
# right join 右连接
select * from emp1 right join dep on emp1.dep_id = dep.id;
# 右表所有的数据都展示出来,没有对应的数据用NULL
# union 全连接 左右两表的数据都展示出来
select * from emp1 left join dep on emp1.dep_id = dep.id
union
select * from emp1 right join dep on emp1.dep_id = dep.id;
子查询
'''
子查询就是解决问题的思路
分步骤解决问题
第一步
第二步
...
官方说法:将一个查询语句的结果当做另一个查询语句的条件去使用
'''
# 查询部门是技术或者人力资源的员工信息
1 先获取部门的id好
select id from dep where name='技术' or name='人力资源';
2 再去员工表里筛选对应的员工
select * from emp1 where dep_id in (200,201);
3 合起来
select * from emp1 where dep_id in (select id from dep where name='技术' or name='人力资源');
关键字exists
只返回布尔值 True False
返回True的时候外层查询语句执行
返回False的时候外层查询语句不再执行
select * from emp1 where exists (select id from dep where id>3)
Mysql 存储引擎以及 SQL语句的更多相关文章
- SQL学习笔记三(补充-1)之MySQL存储引擎
阅读目录 一 什么是存储引擎 二 mysql支持的存储引擎 三 使用存储引擎 一 什么是存储引擎 mysql中建立的库===>文件夹 库中建立的表===>文件 现实生活中我们用来存储数据的 ...
- Mysql存储引擎比较
Mysql作为一个开源的免费数据库,在平时项目当中会经常使用到,而在项目当中我们的着重点一般在设计使用数据库上而非mysql本身上,所以在提到mysql的存储引擎时,一般都不曾知道,这里经过网上相关文 ...
- MySQL存储引擎之Myisam和Innodb总结性梳理
Mysql有两种存储引擎:InnoDB与Myisam,下表是两种引擎的简单对比 MyISAM InnoDB 构成上的区别: 每个MyISAM在磁盘上存储成三个文件.第一个 文件的名字以表的名字开始 ...
- 【转】mysql存储引擎
http://www.cnblogs.com/kevingrace/p/5685355.html Mysql有两种存储引擎:InnoDB与Myisam,下表是两种引擎的简单对比 MyISAM In ...
- 第 3 章 MySQL 存储引擎简介
第 3 章 MySQL 存储引擎简介 前言 3.1 MySQL 存储引擎概述 MyISAM 存储引擎是 MySQL 默认的存储引擎,也是目前 MySQL 使用最为广泛的存储引擎之一.他的前身就是我们在 ...
- Mysql存储引擎__笔记
Mysql存储引擎(表类型): Mysql数据库: 通常意义上,数据库也就是数据的集合,具体到计算机上数据库可以使存储器上一些文件的集合或者一些内存 数据的内存数据的集合. Mysql数据库是开放源代 ...
- MySQL存储引擎,优化,事务
1唯一约束unique和主键key的区别? 1.什么是数据的存储引擎? 存储引擎就是如何存储数据.如何为存储的数据建立索引和如何更新.查询数据等技术的实现方法.因为在关系数据库中数 ...
- Mysql存储引擎概念特点介绍及不同业务场景选用依据
目录 MySQL引擎概述 1 MySAM引擎介绍 2 什么是InnoDB引擎? 3 生产环境中如何批量更改MySQL引擎 4 有关MySQL引擎常见企业面试题 MySQL引擎概述 Mysql表存储结构 ...
- MySQL存储引擎:InnoDB和MyISAM的差别/优劣评价/评测/性能测试
InnoDB和MyISAM简介 MyISAM:这个是默认类型,它是基于传统的ISAM类型,ISAM是Indexed Sequential Access Method (有索引的 顺序访问方法) 的缩写 ...
随机推荐
- 人机交互BS
B/S结构用户界面设计 [实验编号] 10003809548j Web界面设计 [实验学时] 8学时 [实验环境] l 所需硬件环境为微机: l 所需软件环境为dreamweaver ...
- 一个chome的广告拦截小插件
先附上下载地址:https://chromecj.com/productivity/2015-03/391.html 可以屏蔽绝大多数广告啊,浏览器用起来神清气爽! 下载完成后有一个名字为这个的文件, ...
- 支付宝小程序中“<”号写法
今天遇到一个小问题,记录一下 "<"号在h5页面都是可以直接显示的,但是在运行支付宝小程序时报错,找了一个解决办法 <text> {{char_lt}} 18.5 ...
- Ubuntu16更换flatabulous主题
Ubuntu16更换flatabulous主题 安装unity-tweak-tool sudo apt-get install unity-tweak-tool 安装flatabulous主题 sud ...
- 查看k8s的yaml里面反馈的错误,不仅仅是通过日志来查看错误
使用:kubectl describe pod......例如: kubectl describe pod api-55f5d8d49d-kzmcj ///////////////////////// ...
- 基于 Redis 分布式锁
1.主流分布式锁实现方案 基于数据库实现分布式锁 基于缓存(redis 等) 基于 Zookeeper 2.根据实现方式分类 : 类 CAS 自旋式分布式锁:询问的方式,类似 java 并发编程中的线 ...
- 共读《redis设计与实现》-单机(一)
上一章我们讲了 redis 基本类型的数据结构 和 对象系统 ,这篇来说一下单机redis 的知识点. 一.数据库 一个数据库在redis中就有一个结构体,而数据库的结构体是由redisServer这 ...
- HTML续集
计算机中PC:电脑 移动端:智能手机/智能电脑 html:超文本标记语言 图片标签<img src=" "> 图片的格式类型都有哪些? jpg,peg,gif(动图) ...
- Apache Doris ODBC外表之Postgresql使用指南
Apache Doris 社区 2022 年的总体规划,包括待开展或已开展.以及已完成但需要持续优化的功能.文档.社区建设等多方面,我们期待有更多的小伙伴参与进来讨论.同时也希望多多关注Doris,给 ...
- js console.log打印变量注意事项
如果是基本类型变量是没有异常的 let str = 'string' console.log(str) // string str = '改变了str变量' 如果是引用类型,打印就要注意了 let o ...