印尼医疗龙头企业Halodoc的数据平台转型之Lakehouse架构
1. 摘要
在 Halodoc,我们始终致力于为最终用户简化医疗保健服务,随着公司的发展,我们不断构建和提供新功能。 我们两年前建立的可能无法支持我们今天管理的数据量,以解决我们决定改进数据平台架构的问题。 在我们之前的博客中,我们谈到了现有平台的挑战以及为什么我们需要采用 Lake House 架构来支持业务和利益相关者以轻松访问数据。
在这篇博客中,我们将讨论我们的新架构、涉及的组件和不同的策略,以拥有一个可扩展的数据平台。
2. 新架构
让我们首先看一下经过改进的新数据平台 2.0 的高级架构。

我们将架构分为 4 层:
1. 数据摄取/提取层
该层更关心在原始区域层中摄取数据,这些数据可以稍后在已处理区域中使用和卸载。大多数点击流捕获工具都支持来自其产品的内部数据摄取服务,从而可以轻松获取或加入原始区域以进行进一步处理。对于 MySQL、Postgres 等事务性数据源,我们开始利用基于 CDC 的方法进行数据提取。由于我们的基础设施主要托管在 AWS 中,因此我们选择了数据迁移服务 (DMS) 来执行基于 CDC 的迁移。
2. 处理层
这里我们没有执行任何繁重的转换,而是将原始数据转换为 HUDI 数据集。源数据以不同的格式(CSV、JSON)摄取,需要将其转换为列格式(例如parquet),以将它们存储在 Data Lake 中以进行高效的数据处理。数据类型基于数据湖兼容性进行类型转换,时区调整为 WIB 时间戳。
3. 转换层
数据工程的一大挑战是有效地处理大量数据并保持成本不变。我们选择 Apache Spark 进行处理,因为它支持分布式数据处理,并且可以轻松地从千兆字节扩展到 TB 级数据处理。转换层在数据仓库中生成数据模型,并成为报表使用数据并支持仪表板或报表用例的基础。
4. 报告层
报告层主要从维度和事实表中聚合数据,并在这些数据库之上提供视图供下游用户使用。大多数仪表板将建立在这些报告表和物化视图之上,从而减少为重复性任务和报告用例连接不同表的计算成本。
一旦我们将平台实现为不同的层,下一个挑战就是选择能够支持我们大多数下游用例的组件。当我们调研市场上的数据工程工具/产品时,我们可以轻松找到大量工具。我们计划利用 AWS 云和开源项目构建内部解决方案,而不是购买第三方许可工具。
让我们更深入地了解上述平台中使用的组件。
涉及的组件:
1. 管理系统
DMS 代表数据迁移服务。这是一项 AWS 服务,可帮助在 MySQL、Postgres 等数据库上执行 CDC(更改数据捕获)。我们利用 DMS 从 MySQL DB 读取二进制日志并将原始数据存储在 S3 中。我们已经自动化了在 Flask 服务器和 boto3 实现的帮助下创建的 DMS 资源。我们可以轻松地在控制表中配置的原始区域参数中加入新表。
2. S3 - 原始区域
DMS 捕获的所有 CDC 数据都存储在 S3 中适当分区的原始区域中。该层不执行数据清洗。只要源系统中发生插入或更新,数据就会附加到新文件中。原始区域对于在需要时执行数据集的任何回填非常重要。
这还存储从点击流工具或任何其他数据源摄取的数据。原始区域充当处理区域使用数据的基础层。
3. EMR - HUDI + PySpark
Apache HUDI 用于对位于 Data Lake 中的数据利用 UPSERT 操作。我们正在运行 PySpark 作业,这些作业按预定的时间间隔运行,从原始区域读取数据,处理并存储在已处理区域中。已处理区域复制源系统的行为。这里只是发生了一个 UPSERT 操作并转换为 HUDI 数据集。
4. S3 - 处理区
S3 处理层是 Halodoc 的数据湖。我们存储可变和不可变数据集。 HUDI 被用于维护可变数据集。 CSV 或 JSON 数据等不可变数据集也被转换为列格式(parquet)并存储在该区域中。该层还维护或纠正分区以有效地查询数据集。
5. Glue数据目录
AWS Glue 数据目录用于注册表,并可通过 Athena 进行查询以进行临时分析。
6. Athena
Athena 是一个无服务器查询引擎,支持查询 S3 中的数据。用户利用 Athena 对位于数据湖中的数据集进行任何临时分析。
7. Redshift
Redshift 用作数据仓库来构建数据模型。所有报告/BI 用例均由 Redshift 提供服务。我们在 Redshift 中创建了 2 个图层。一层负责存储包含事实和维度的 PD、CD、Appointments、Insurance 和 Labs 的所有数据模型。我们已经构建了一个报告层框架来进行聚合和连接,以创建可通过 BI 工具访问的报告表。我们还在这些层中维护物化视图。我们还在我们的数据模型中实现了 SCD type1 和 SCD type2,以捕捉数据集中的历史变化。
8. MWAA
MWAA 用于编排工作流程。
9. Cloud Watch和EFK
Cloud Watch 和 EFK 相结合,构建集中的日志记录、监控和警报系统。
10. Dynamicdb
平台中使用 Dynamodb 将失败的事件存储在控制表中发布。开发了一个再处理框架来处理失败的事件并按预定的频率将它们推送到控制表。
3. 为什么选择基于 CDC 的方法?
在 Halodoc,当我们开始数据工程之旅时,我们采用了基于时间戳的数据迁移。我们依靠修改后的时间戳将数据从源迁移到目标。我们几乎用这个管道服务了 2 年。随着业务的增长,我们的数据集呈指数级增长,这要求我们将迁移实例增加到更大的集群以支持大量数据。
问题如下:
- 由于源处生成的大量数据导致迁移集群大小增加,因此成本高。
- 由于某些后端问题,未更新已修改列时的数据质量问题。
- 架构更改很难在目标中处理。
- 在基于 CDC 的情况下,我们通过在 MySQL 中启用 binlog(二进制日志)和在 Postgres 中启用 WAL(预写日志)来开始读取事务数据。提取每个事件更改的新文件是一项昂贵的操作,因为会有很多 S3 Put 操作。为了平衡成本,我们将 DMS 二进制日志设置为每 60 秒读取和拉取一次。每 1 分钟,通过 DMS 插入新文件。基于 CDC 还解决了数据量大增长的问题,因为我们开始以最大分钟间隔迁移,而不是每小时间隔数据。
4. 使用Apache Hudi
HUDI 提供内置功能来支持开放数据湖。在我们的平台中加入或集成 HUDI 时,我们面临以下一些挑战并试图解决它们。
保留 HUDI 数据集中的最大提交
HUDI 根据配置集清理/删除较旧的提交文件。默认情况下,它已将保留的提交设置为 10。必须根据一个工作负载正确设置这些提交。由于我们在 5 分钟内运行了大部分事务表迁移,因此我们将 hoodie.cleaner.commits.retained 设置为 15,以便我们有 75 分钟的时间来完成 ETL 作业。甚至压缩和集群添加到提交,因此必须分析和设置更清洁的策略,以使增量查询不间断地运行。
确定要分区的表
在数据湖中对数据进行分区总是可以减少扫描的数据量并提高查询性能。同样,在湖中拥有大分区会降低读取查询性能,因为它必须合并多个文件来进行数据处理。我们选择我们的数据湖来进行最小的每日分区,并计划将历史数据归档到其他存储层,如 Glacier 或低成本的 S3 存储层。
选择正确的存储类型
HUDI 目前支持 2 种类型的存储,即。 MoR(读取时合并)和 CoW(写入时复制)。必须根据用例和工作负载精确选择存储类型。我们为具有较低数据延迟访问的表选择了 MoR,为可能具有超过 2 小时数据延迟的表选择了 CoW。
MoR 数据集的不同视图
MoR 支持 _ro 和 _rt 视图。 _ro 代表读取优化视图,_rt 代表实时视图。根据用例,必须确定要查询哪个表。我们为 ETL 工作负载选择了 _ro 视图,因为数据模型中的数据延迟约为 1 小时。
建立在数据湖之上的报告正在查询 _rt 表以获取数据集的最新视图。
HUDI 中的索引
索引在 HUDI 中对于维护 UPSERT 操作和读取查询性能非常有用。有全局索引和非全局索引。我们使用默认的bloom索引并为索引选择了一个静态列,即非全局索引。我们依靠 HUDI 提交时间来获取增量数据。这也有助于将迟到的数据处理到要处理的数据湖,而无需任何人工干预。
5. 为什么框架驱动
我们之前的大部分实施都是管道驱动的,这意味着我们为每个数据源手动构建管道以服务于业务用例。在 Platform 2.0 中,我们对实现模型进行了细微的更改,并采用了框架驱动的管道。我们开始在每一层上构建一个框架,例如数据摄取框架、数据处理框架和报告框架。每个框架都专用于使用预定义的输入执行某些任务。采用框架驱动减少了冗余代码,以维护和简化数据湖中新表的载入过程。
使用表格格式的控制平面的好处
在我们的平台中,控制平面是一个关键组件,用于存储元数据并帮助轻松载入数据湖和数据仓库中的新表。它存储启用数据迁移所需的必要配置。对于构建任何产品,元数据在自动化和控制管道流程方面起着至关重要的作用。在 Yaml、DynamoDB 或 RDBMS 中,我们有不同的选项可供选择。
我们选择 RDS 的原因如下:
- 轻松在元数据之上执行任何分析,例如活动管道的数量。
- 易于载入新表或数据模型。
- 借助 python flask API 轻松构建 API 层。
- 审计可以很容易地完成。
- 数据安全
在医疗保健领域,安全一直是我们数据平台中启用的重中之重。我们在私有子网中托管了几乎所有基础设施,并启用 Lake Formation 来管理对 Data Lake 的访问。我们还对静态数据使用 AWS 加密。这提供了数据湖和整体数据平台的安全存储。
自动化
自动化总是有助于减少构建和维护平台的工程工作量。 在 Platform 2.0 中,我们的大部分流水线都使用 Jenkins 和 API 实现自动化。
我们通过部署烧瓶服务器并使用 boto3 创建资源来自动创建 DMS 资源。
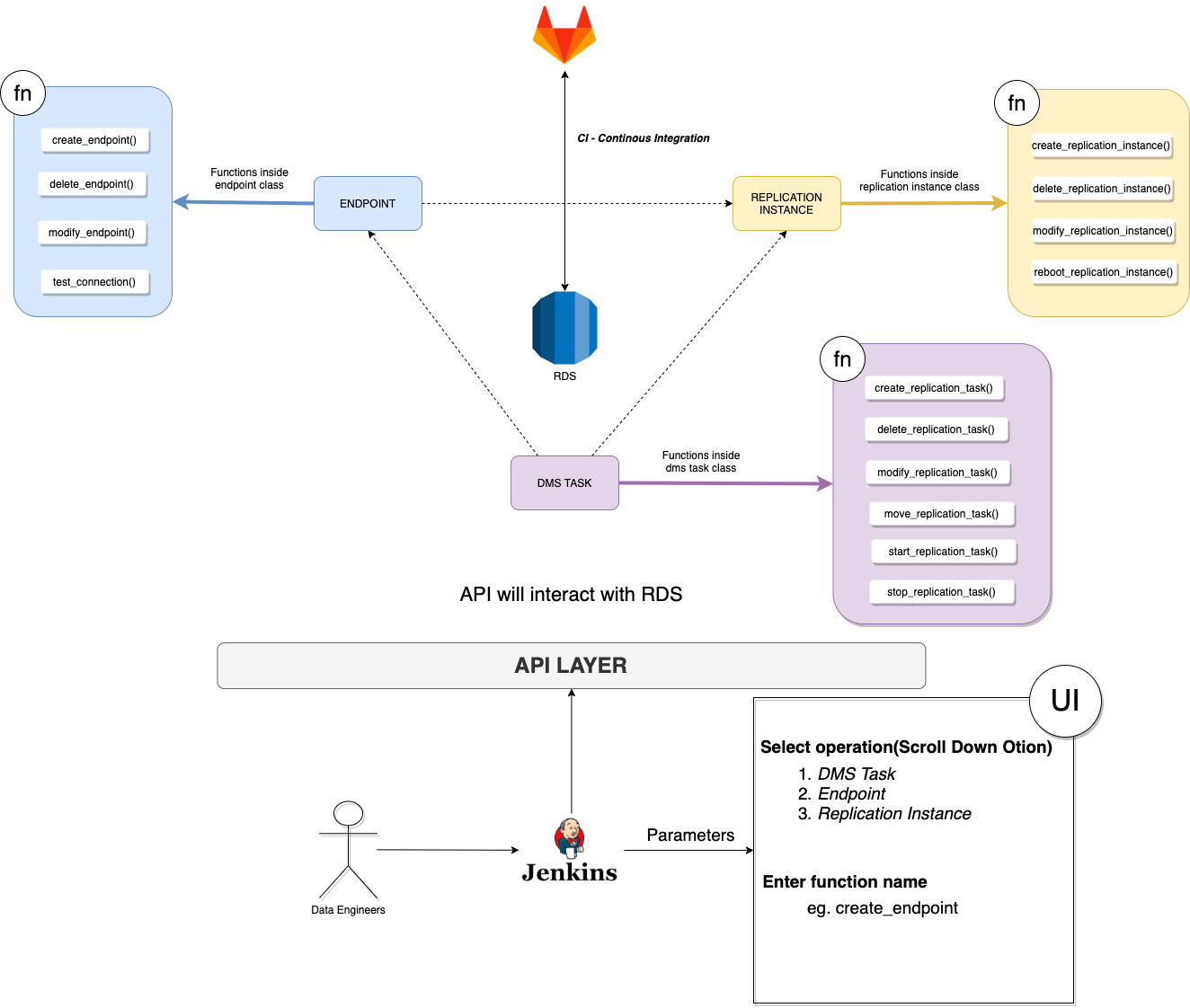
我们几乎所有的基础设施/资源都是通过 Terraform 创建的。 SRE 在建立我们的大部分数据平台基础设施方面发挥了重要作用。
记录、监控和警报
尽管我们的基础设施是健壮的、容错的和高度可扩展的,但有时会出现可能导致基础设施停机的意外错误。为了识别和解决这些问题,我们使用 Cloud watch 和 EFK(Elasticsearch、Fluentbit 和 Kibana)堆栈对我们数据平台中涉及的每个组件启用了监控和警报。
工作流程编排
任何数据平台都需要调度能力来运行批处理数据管道。由于我们已经在之前的平台中使用 Airflow 进行工作流编排,因此我们继续使用相同的编排工具。 MWAA 已经在减少维护工作量和节省成本方面发挥了很大作用。我们在之前的博客中解释了我们在 MWAA 中评估的内容。
6. 概括
在这篇博客中,我们查看了 Lake House 架构、构建平台 2.0 所涉及的所有组件,以及我们将 HUDI 用作数据湖的关键要点。由于我们现在已经构建了 Data Platform 2.0 的基础部分,接下来我们计划专注于平台的以下方面:
- 数据质量 -> 维护整个数据存储的数据检查和数据一致性。
- 数据血缘 -> 提供数据转换的端到端步骤。
- BI 团队的自助服务平台 -> 减少对 DE 团队对入职报告表的依赖。
- 处理迟到的维度:保持我们的数据模型的一致性,并处理从湖到仓库的迟到的维度键。
印尼医疗龙头企业Halodoc的数据平台转型之Lakehouse架构的更多相关文章
- 印尼医疗龙头企业Halodoc的数据平台转型之路:数据平台V1.0
1. 摘要 数据是每项技术业务的支柱,作为一个健康医疗技术平台,Halodoc 更是如此,用户可以通过以下方式与 Halodoc 交互: 送药 与医生交谈 实验室测试 医院预约和药物 所有这些交互都会 ...
- 印尼医疗龙头企业Halodoc的数据平台转型之数据平台V2.0
1. 摘要 数据平台已经彻底改变了公司存储.分析和使用数据的方式--但为了更有效地使用它们,它们需要可靠.高性能和透明.数据在制定业务决策和评估产品或 Halodoc 功能的性能方面发挥着重要作用.作 ...
- 基于Hadoop的大数据平台实施记——整体架构设计[转]
http://blog.csdn.net/jacktan/article/details/9200979 大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底 ...
- 基于Hadoop的大数据平台实施记——整体架构设计
大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底是否适用于您的组织,至少在互联网上已经被吹嘘成无所不能的超级战舰.好像一夜之间我们就从互联网时代跳跃进了大 ...
- 电竞大数据平台 FunData 的系统架构演进
电竞大数据时代,数据对比赛的观赏性和专业性都起到了至关重要的作用.同样的,这也对电竞数据的丰富性与实时性提出了越来越高的要求. 电竞数据的丰富性从受众角度来看,可分为赛事.战队和玩家数据:从游戏角 ...
- 用Apache Kafka构建流数据平台的建议
在<流数据平台构建实战指南>第一部分中,Confluent联合创始人Jay Kreps介绍了如何构建一个公司范围的实时流数据中心.InfoQ前期对此进行过报道.本文是根据第二部分整理而成. ...
- 基于Ambari构建自己的大数据平台产品
目前市场上常见的企业级大数据平台型的产品主流的有两个,一个是Cloudera公司推出的CDH,一个是Hortonworks公司推出的一套HDP,其中HDP是以开源的Ambari作为一个管理监控工具,C ...
- 宜人贷PaaS数据服务平台Genie:技术架构及功能
上篇:架构及组件 一.数据平台的发展 1.1 背景介绍 随着数据时代的到来,数据量和数据复杂度的增加推动了数据工程领域的快速发展.为了满足各类数据获取/计算等需求,业内涌现出了诸多解决方案.但大部分方 ...
- 知名大厂如何搭建大数据平台&架构
今天我们来看一下淘宝.美团和滴滴的大数据平台,一方面进一步学习大厂大数据平台的架构,另一方面也学习大厂的工程师如何画架构图.通过大厂的这些架构图,你就会发现,不但这些知名大厂的大数据平台设计方案大同小 ...
随机推荐
- DOS、DOS攻击、DDOS攻击、DRDOS攻击
https://baike.baidu.com/item/dos%E6%94%BB%E5%87%BB/3792374?fr=aladdin DOS:中文名称是拒绝服务,一切能引起DOS行为的攻击都被称 ...
- 【分享】WeX5的正确打开方式(6)——数据组件初探
本文是[WeX5的正确打开方式]系列的第6篇文章,简单介绍一下WeX5中数据组件的特性和结构形式. 数据组件的由来 上一篇 WeX5绑定机制我们实现了一个简单的记账本应用,当时所有数据都用 JSON ...
- 一个命令完成[打包+同步七牛cdn+上传服务器]
webpack+gulp+qshell+npm-scripts实现一个命令完成[打包+同步cdn+上传服务器] 说明 由于我们用的七牛云存储,所以cdn也是走的七牛,所以并不适用于其他的cdn,但是思 ...
- 安装并使用Junit
在Eclipse中配置Junit的方法有两种方式: 第一种方法: 1.下载junit的jar包,目前它的版本是junit3.8.1,可以从www.junit.org上下载. 2.在要使用Junit的p ...
- vue中判断页面滚动开始和结束
参考链接:https://www.jianshu.com/p/adad39705ced 和 https://blog.csdn.net/weixin_44309374/article/deta ...
- Vmware虚拟机三种网络模式详解(转载)
原文来自http://note.youdao.com/share/web/file.html?id=236896997b6ffbaa8e0d92eacd13abbf&type=note 由于l ...
- python3拉勾网爬虫之(您操作太频繁,请稍后访问)
你是否经历过这个:那就对了~因为需要post和相关的cookie来请求~所以,一个简单的代码爬拉钩~~~
- Python Json分别存入Mysql、MongoDB数据库,使用Xlwings库转成Excel表格
将电影数据 data.json 数据通过xlwings库转换成excel表格,存入mysql,mongodb数据库中.python基础语法.xlwings库.mysql库.pymongo库.mongo ...
- 小米路由器3G R3G 刷入Breed和OpenWrt 20.02.2 的记录
小米 R3G 参数 Architecture: MIPS Vendor: Mediatek Bootloader: U-Boot System-On-Chip: MT7621 family CPU/S ...
- 通过OptaPlanner优化 COVID-19 疫苗接种预约安排(2)
本文为OptaPlanner官方博客<Optimizing COVID-19 vaccination appointment scheduling>的第二篇译文.第一篇介绍了通过OptaP ...