02 Spark架构与运行流程
1. 为什么要引入Yarn和Spark。
YARN优势
1、YARN的设计减小了JobTracker的资源消耗,并且让监测每一个Job子任务(tasks)状态的程序分布式化了,更安全、更优美。
2、在新的Yarn中,ApplicationMaster是一个可变更的部分,用户可以对不同的编程模型写自己的AppMst,让更多类型的编程模型能够跑在Hadoop集群中。
3、对于资源的表示以内存为单位,比之前以剩余slot数目更加合理。
4、MRv1中JobTracker一个很大的负担就是监控job下的tasks的运行状况,现在这个部分就扔给ApplicationMaster做了,
而ResourceManager中有一个模块叫做ApplicationManager,它是监测ApplicationMaster的运行状况,如果出问题,会在其他机器上重启。
5、Container用来作为YARN的一个资源隔离组件,可以用来对资源进行调度和控制。
spark
轻:Spark 0.6核心代码有2万行,Hadoop 1.0为9万行,2.0为22万行。一方面,感谢Scala语言的简洁和丰富表达力;另一方面,Spark很好地利用了Hadoop和Mesos(伯克利 另一个进入孵化器的项目,主攻集群的动态资源管理)的基础设施。虽然很轻,但在容错设计上不打折扣。主创人Matei声称:“不把错误当特例处理。”言下 之意,容错是基础设施的一部分。
快:Spark对小数据集能达到亚秒级的延迟,这对于Hadoop MapReduce(以下简称MapReduce)是无法想象的(由于“心跳”间隔机制,仅任务启动就有数秒的延迟)。就大数据集而言,对典型的迭代机器 学习、即席查询(ad-hoc query)、图计算等应用,Spark版本比基于MapReduce、Hive和Pregel的实现快上十倍到百倍。其中内存计算、数据本地性 (locality)和传输优化、调度优化等该居首功,也与设计伊始即秉持的轻量理念不无关系。
灵:Spark提供了不同层面的灵活性。在实现层,它完美演绎了Scala trait动态混入(mixin)策略(如可更换的集群调度器、序列化库);在原语(Primitive)层,它允许扩展新的数据算子 (operator)、新的数据源(如HDFS之外支持DynamoDB)、新的language bindings(Java和Python);在范式(Paradigm)层,Spark支持内存计算、多迭代批量处理、即席查询、流处理和图计算等多种 范式。
巧:巧在借势和借力。Spark借Hadoop之势,与Hadoop无缝结合;接着Shark(Spark上的数据仓库实现)借了Hive的势;图计算借 用Pregel和PowerGraph的API以及PowerGraph的点分割思想。一切的一切,都借助了Scala(被广泛誉为Java的未来取代 者)之势:Spark编程的Look'n'Feel就是原汁原味的Scala,无论是语法还是API。在实现上,又能灵巧借力。为支持交互式编 程,Spark只需对Scala的Shell小做修改(相比之下,微软为支持JavaScript Console对MapReduce交互式编程,不仅要跨越Java和JavaScript的思维屏障,在实现上还要大动干戈)。
2. Spark已打造出结构一体化、功能多样化的大数据生态系统,请简述Spark生态系统。
Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算
Spark不仅支持Scala编写应用程序,而且支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。
Spark生态圈即BDAS===》

Spark具有很强的适应性,能够读取HDFS、Cassandra、HBase、S3和Techyon为持久层读写原生数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算。
spark跟hadoop的比较:
Spark是在借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷,具体如下:
首先,Spark把中间数据放到内存中,迭代运算效率高。MapReduce中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而Spark支持DAG图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。
其次,Spark容错性高。Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即充许基于数据衍生过程)对它们进行重建。另外在RDD计算时可以通过CheckPoint来实现容错,而CheckPoint有两种方式:CheckPoint Data,和Logging The Updates,用户可以控制采用哪种方式来实现容错。
最后,Spark更加通用。不像Hadoop只提供了Map和Reduce两种操作,Spark提供的数据集操作类型有很多种,大致分为:Transformations和Actions两大类。Transformations包括Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort和PartionBy等多种操作类型,同时还提供Count, Actions包括Collect、Reduce、Lookup和Save等操作。另外各个处理节点之间的通信模型不再像Hadoop只有Shuffle一种模式,用户可以命名、物化,控制中间结果的存储、分区等。
Spark支持多种分布式存储系统:HDFS和S3
3. 用图文描述你所理解的Spark运行架构,运行流程。
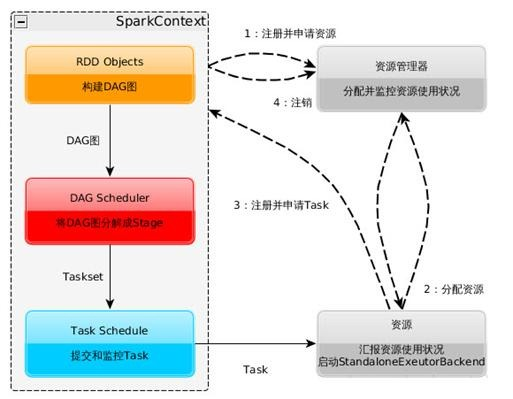
Spark运行基本流程参见下面示意图
1. 构建Spark Application的运行环境(启动SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源;
2. 资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上;
3. SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给Task Scheduler。Executor向SparkContext申请Task,Task Scheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor。
4. Task在Executor上运行,运行完毕释放所有资源。
Spark运行架构特点:
l每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行tasks。这种Application隔离机制有其优势的,无论是从调度角度看(每个Driver调度它自己的任务),还是从运行角度看(来自不同Application的Task运行在不同的JVM中)。当然,这也意味着Spark Application不能跨应用程序共享数据,除非将数据写入到外部存储系统。
lSpark与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了。
l提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark Application运行过程中SparkContext和Executor之间有大量的信息交换;如果想在远程集群中运行,最好使用RPC将SparkContext提交给集群,不要远离Worker运行SparkContext。
lTask采用了数据本地性和推测执行的优化机制。
02 Spark架构与运行流程的更多相关文章
- 浅析MyBatis(一):由一个快速案例剖析MyBatis的整体架构与运行流程
MyBatis 是轻量级的 Java 持久层中间件,完全基于 JDBC 实现持久化的数据访问,支持以 xml 和注解的形式进行配置,能灵活.简单地进行 SQL 映射,也提供了比 JDBC 更丰富的结果 ...
- Spark学习之路 (七)Spark 运行流程
一.Spark中的基本概念 (1)Application:表示你的应用程序 (2)Driver:表示main()函数,创建SparkContext.由SparkContext负责与ClusterMan ...
- Spark Streaming运行流程及源码解析(一)
本系列主要描述Spark Streaming的运行流程,然后对每个流程的源码分别进行解析 之前总听同事说Spark源码有多么棒,咱也不知道,就是疯狂点头.今天也来撸一下Spark源码. 对Spark的 ...
- Spark架构角色及基本运行流程
1. 集群角色 Application:基于spark的用户程序,包含了一个Driver program 和集群中多个Executor Driver Program:运行application的mai ...
- 【转载】Spark系列之运行原理和架构
参考 http://www.cnblogs.com/shishanyuan/p/4721326.html 1. Spark运行架构 1.1 术语定义 lApplication:Spark Applic ...
- Spark架构与作业执行流程简介(scala版)
在讲spark之前,不得不详细介绍一下RDD(Resilient Distributed Dataset),打开RDD的源码,一开始的介绍如此: 字面意思就是弹性分布式数据集,是spark中最基本的数 ...
- Spark学习之路 (七)Spark 运行流程[转]
Spark中的基本概念 (1)Application:表示你的应用程序 (2)Driver:表示main()函数,创建SparkContext.由SparkContext负责与ClusterManag ...
- 宜信开源|分布式任务调度平台SIA-TASK的架构设计与运行流程
一.分布式任务调度的背景 无论是互联网应用或者企业级应用,都充斥着大量的批处理任务.我们常常需要一些任务调度系统来帮助解决问题.随着微服务化架构的逐步演进,单体架构逐渐演变为分布式.微服务架构.在此背 ...
- Spark基本运行流程
不多说,直接上干货! Spark基本运行流程 Application program的组成 Job : 包含多个Task 组成的并行计算,跟Spark action对应. Stage : Job 的调 ...
- 【CDN+】 Spark 的入门学习与运行流程
前言 上文已经介绍了与Spark 息息相关的MapReduce计算模型,那么相对的Spark的优势在哪,有哪些适合大数据的生态呢? Spark对比MapReduce,Hive引擎,Storm流式计算引 ...
随机推荐
- css 网页置灰
body *{ -webkit-filter: grayscale(100%); /* webkit */ -moz-filter: grayscale(100%); /*firefox*/ -ms- ...
- case语法案例
case语法案例 制作nginx启停脚本 1.条件: 2.思路: 3.脚本 添加删除openvppn用户的脚本 1.实现要求 2.具体脚本 case语法案例 制作nginx启停脚本 1.条件: 启动服 ...
- C# 读取串口设备列表
ManagementObjectSearcher 解析不到头文件,需要手动 Add Referance 需要添加引用:System.Management,然后引入命名空间:using System.M ...
- 关于JWT中RSA数据加密协议在.net中应用
加密协议有哪些 加密协议分为对称加密和非对称加密. 对称加密就是将信息使用一个密钥进行加密,解密时使用同样的密钥,同样的算法进行解密. 非对称加密,又称公开密钥加密,是加密和解密使用不同密钥的算法,广 ...
- A Novel Cross-domain Access Control Protocol in Mobile Edge Computing
摘要 随着智能移动终端和移动通信技术的发展,移动边缘计算(MEC)已经应用到各个领域.然而,MEC也带来了新的数据安全威胁,包括数据访问威胁.针对MEC中的跨域访问控制问题,提出一种跨域访问控制协议C ...
- CCF 201812-1 小明上学
#include <iostream> #include <bits/stdc++.h> #include <string> using namespace std ...
- 路飞项目 day03 前端配置、后台主页、项目依赖问题
一.路飞项目前端配置 1.先删除一些不要的 删除多余的组件,只要app和首页组件 然后改一下组件的内部代码 -App.vue中 ______________ <template> ...
- WIN10操作系统如何利用无线网卡连接wifi再通过有线网卡共享网络给路由(双网卡)
首先有一台笔记本电脑,或者双网卡的电脑(wifi网卡 和 有线网卡) 找到两个个网卡,并重置他们的设置 然后同时选中,右单击选择桥接 桥接成功以后就可以用无线网卡连接wifi,然后把有线网口插上网线直 ...
- ES-分页查询
从一个分页问题开始 做分页查询,当分页达到一定量的时候,报如下错误 Result window is too large, from + size must be less than or equal ...
- 普罗米修斯-docker安装
1.只有一台服务器,所以使用docker来进行试验 #安装dockercurl -fsSL https://get.docker.com | bash -s docker --mirror Aliyu ...