哈希-hash
一. 概念
1.引例
有线性表(1,75,324,43,1353,90,46,… )
目的:查找值为90的元素
常见做法:
1、通过一维数组进行遍历查找 (依次比较)( O(n) )
2、如果关键字有序,可采用二分查找 ( O(logn) )
缺陷:当数据规模极大的时候,查找将会变得效率低下。
假设:如果知道待查询关键字的地址,则只需要一次就可以查到。
问题:如何立刻知道关键字的地址?
Hash函数: 根据关键字直接计算出元素所在位置的函数。
例:设哈希函数为:H(K)=K/3+1,则构造关键字序列为 1、2、5、9、11、13、16、21、27 的哈希表(散列表)为:

2.哈希表
根据设定的哈希函数 H(key) 和处理冲突的方法将一组关键字映象到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“象”作为记录在表中的存储位置,这种表便称为哈希表,这一映象过程称为哈希造表或散列,所得存储位置称为哈希地址或散列地址。
简单的说,哈希表可以根据一个key值来直接访问数据。其实,哈希表其实本质上就是一个数组
3.冲突
两个不同的关键字具有相同的存储位置。(多个关键字通过hash函数得到的地址是同一个地址)

在哈希存储中,若发生冲突,则必须采取特殊的方法来解决冲突问题,才能使哈希查找能顺利进行。虽然冲突不可避免,但可以减少冲突的发生,发生冲突的可能性与三个方面因素有关。
1、装填因子α
装填因子是指哈希表中己存入的元素个数 n 与哈希表的大小 m 的比值,即α=n/m。α越小,发生冲突的可能性越小,反之,发生冲突的可能性就越大。但是,α太小又会造成大量存贮空间的浪费,因此必须兼顾存储空间和冲突两个方面。
2、所构造的哈希函数
构造好的哈希函数,使冲突尽可能的少。
3、解决冲突的方法
设计有效解决冲突的方法 。
二.哈希函数的构造方法
构造哈希函数的方法很多,下面我们来列举常见的几种:
1.直接定址法
取关键字或关键字的某个线性函数值为散列地址,即H(K)=K 或 H(K)=a * K + b(其中a、b为常数)。
例:关键字集合为 { 100,300,500,700,800,900 }, 选取哈希函数为 Hash(key)=key/100,则存储结构(哈希表)如下:
优点:以关键码 key 的某个线性函数值为哈希地址,不会产生冲突。
缺点:要占用连续地址空间,空间效率低。
2.除后余数法
取关键字被不大于散列表表长 m 的数 p 除后所得的余数为哈希函数。即
H(K)=K mod p (p≤m)
ps:经验得知,一般可选p为质数 或 不包含小于20的质因子的合数。
p一般取131,1331,13331……
3. 随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key)=random (key) 其中random为随机函数(random是C语言函数)。
通常,当关键字长度不等时采用此法构造哈希函数较恰当
ps:随机都是伪随机,都是通过某种算法实现的对应值,C++使用cstdlib头。文件



实际操作中需视不同情况采用不同的哈希函数。
通常考虑的因素:
(1)计算哈希函数所需时间(包括硬件指令的因素);
(2)关键字的长度;
(3)哈希表的大小;
(4)关键字的分布情况;
(5)记录的查找频率。
三.处理冲突的方法
1.开放地址法
开放地址就是表中尚未被占用的地址,当新插入的记录所选地址已被占用时,即转而寻找其它尚开放的地址。
(1)线性探测法
设散列函数 H(K) = K mod m (m为表长),若发生冲突,则沿着一个探查序列逐个探查(也就是加上一个增量),那么,第i次计算冲突的散列地址为:
Hi = (H(K)+di) mod m (di=1,2,…,m-1)
2.链地址法
基本思想:
将具有相同哈希地址的记录链成一个单链表,m个哈希地址就设 m个单链表,然后用一个数组将m个单链表的表头指针存储起来,形成一个动态的结构。
例:设{ 47, 7, 29, 11, 16, 92, 22, 8, 3, 50, 37, 89 }的哈希函数为:Hash(key)=key mod 11,用拉链法处理冲突,建表。
有冲突的元素可以插在表尾,也可以插在表头(此例为头插法)。

3.再哈希法
基本思想:
Hi= RHi(key) i=1,2,3,……,k。
其中,RHi均是不同的哈希函数,即在同义词产生地址冲突时计算另一个哈希函数地址,直到冲突不再发生。
4.建立一个公共溢出区
基本思想:
假设哈希函数的值域为[0,m-1],则设向量HashTable[0,m-1]为基本表。在此基础上,再建立一个溢出表,在之后的哈希操作中,无论关键字的同义词生成怎样的哈希地址,一旦发生冲突,就将其放入溢出表中。
Show Time
No.1 Crazy Search
【思路】把每一个子串都hash为NC进制的整数s,判断hash[s]是否出现过,再进行统计。
Code
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
ll mp[20000005];
int main(){
map<char,int> ma;
memset(mp,0,sizeof(mp));
string s;
ll n,nc,sum,idx=1,ans=0;
scanf("%lld%lld",&n,&nc);
cin>>s;
for(int i=0;i<s.length();i++){
if(!ma[s[i]]){
ma[s[i]]=i;
}
}
for(ll i=0;i<s.length()-n+1;i++){
sum=0,idx=1;
for(ll j=i;j<i+n;j++){
sum+=ma[s[j]]*pow(nc,n-idx);
idx++;
}
if(!mp[sum]){
mp[sum]=1;
ans++;
}
}
printf("%lld",ans);
return 0;
} No.2 兔子与兔子
【思路】 字符串哈希:将一个字符串通过一种映射关系(字符串到p进制数,p一般取131或1331)转化为一个整数,通过整数对比来反映字符串关系。我们可以用一个大整数来举例:
如:91234599912345,我们如何比较两个12345串呢?
第一个12345串可以用912345-9*100000=12345;
第二个12345串可以用91234599912345-912345999*100000=12345。
大家明白了吗?上例的整数我们用的10进制,如果把它迁移到一个字符串上,由于字符有26个,所以我们可以用一个大于26进制的进制来处理,一般选用131或1331或13331来作为字符串进制。
Code
#include <bits/stdc++.h>
using namespace std;
int hashh[1000005],deg[1000005];
char s[1000005];
int l1,l2,r1,r2;
int n,len,q;
int main()
{
scanf("%s",s+1);
len=strlen(s+1);
scanf("%d",&q);
deg[0]=1;
for(int i=1;i<=len;i++)
{
hashh[i]=hashh[i-1]*131+(s[i]-'a'+1);
deg[i]=deg[i-1]*131;
}
for(int i=0;i<q;i++)
{
scanf("%d%d%d %d",&l1,&r1,&l2,&r2);
if(hashh[r1]-hashh[l1-1]*deg[r1-l1+1]==hashh[r2]-hashh[l2-1]*deg[r2-l2+1])
printf("Yes\n");
else
printf("No\n");
}
return 0;
}No.3 Hash 键值 (hash)
【思路】按照正常模拟,很容易写出代码,如图:
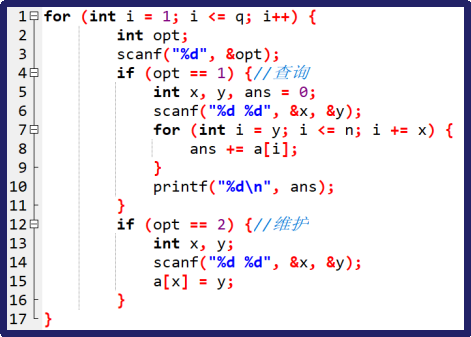
观察时间复杂度q*n,1e10了,TLE,思考优化。
你会发现q个操作是无法简化的,而只能在查询上入手。
首先,定义一个名为sum的二维数组,sum[i][j]表示所有模i余j的数的总和;
再输入一个a[i]以后,就用一重循环遍历,代码如下:

观察发现又一个n方出现了,肯定不行!其实我们只需要收集模i余数在根号n范围内的sum[i][j],如果我们输入的x<根号n,那么我们O(1)输出sum[x][y],否则我们用方法1,这个时候i+=x跨越度就非常大了,这样我们查询就分两类解决了。但又出现了新的问题,维护a[x] = y时sum[i][j]也会变,所以还得维护sum[i][j]。

Code
#include<bits/stdc++.h>
using namespace std;
int a[100005],sum[10005][10005];//模i得j的总数量
int main(){
freopen("hash.in","r",stdin);
freopen("hash.out","w",stdout);
int n,q,opt,x,y;
scanf("%d%d",&n,&q);
for(int i=1;i<=n;i++){
scanf("%d",&a[i]);
for(int j=1;j<=sqrt(n);j++){
sum[j][i%j]+=a[i];
}
}
while(q--){
scanf("%d%d%d",&opt,&x,&y);
if(opt==1){
int ans=0;
if(x<=sqrt(n)) printf("%d\n",sum[x][y]);
else{
for(int i=y;i<=n;i+=x){
ans+=a[i];
}
printf("%d\n",ans);
}
}
else{
for(int i=1;i<=sqrt(n);i++){
sum[i][x%i]-=a[x];
sum[i][x%i]+=y;
}
a[x]=y;
}
}
return 0;
}未完待续……
哈希-hash的更多相关文章
- redis 哈希(hash)函数
哈希(hash)函数 hSet 命令/方法/函数 Adds a value to the hash stored at key. If this value is already in the has ...
- redist命令操作(二)--哈希Hash,列表List
1.Redis 哈希(Hash) 参考菜鸟教程:http://www.runoob.com/redis/redis-hashes.html Redis hash 是一个string类型的field和v ...
- Redis中的哈希(Hash)
Redis 哈希(Hash) Redis hash 是一个string类型的field和value的映射表,hash特别适合用于存储对象. Redis 中每个 hash 可以存储 232 - 1 键值 ...
- NSDictionary实现原理-ios哈希hash和isEqual
NSDictionary实现原理-ios哈希hash和isEqual OC中自定义类的NSCopying实现的注意事项(isEqual & hash实现) http://blog.csdn ...
- 大话Java中的哈希(hash)结构(一)
o( ̄▽ ̄)d 小伙伴们在上网或者搞程序设计的时候,总是会听到关于“哈希(hash)”的一些东西.比如哈希算法.哈希表等等的名词,那么什么是hash呢? 一.相关概念 1.hash算法:一类特殊的算法 ...
- Python操作redis系列以 哈希(Hash)命令详解(四)
# -*- coding: utf-8 -*- import redis #这个redis不能用,请根据自己的需要修改 r =redis.Redis(host=") 1. Hset 命令用于 ...
- Redis 命令,键(key),字符串(String),哈希(Hash),列表(List),集合(Set)(二)
Redis 命令 Redis 命令用于在 redis 服务上执行操作. 要在 redis 服务上执行命令需要一个 redis 客户端.Redis 客户端在我们之前下载的的 redis 的安装包中. ...
- 哈希--Hash,“散列”/“哈希”
哈希 Hash,翻译“散列”,音译为“哈希”,把任意长度的输入,通过散列算法,变换成固定长度的输出,该输出就是散列值.这种转换是一种压缩映射,也就是散列值的空间通常远小于输入的空间,不同的输入可能会散 ...
- 区块链 - 哈希(Hash)
章节 区块链 – 介绍 区块链 – 发展历史 区块链 – 比特币 区块链 – 应用发展阶段 区块链 – 非对称加密 区块链 – 哈希(Hash) 区块链 – 挖矿 区块链 – 链接区块 区块链 – 工 ...
- redis(八):Redis 哈希(Hash)
Redis 哈希(Hash) Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象. Redis 中每个 hash 可以存储 232 ...
随机推荐
- 关于 MyBatis-Plus 分页查询的探讨 → count 都为 0 了,为什么还要查询记录?
开心一刻 记得上初中,中午午休的时候,我和哥们躲在厕所里吸烟 听见外面有人进来,哥们猛吸一口,就把烟甩了 进来的是教导主任,问:你们干嘛呢? 哥们鼻孔里一边冒着白烟一边说:我在生气 环境搭建 依赖引入 ...
- linux中MySQL主从配置(Django实现主从读写分离)
一 linux中MySQL主从配置原理(主从分离,主从同步) mysql主从配置的流程大体如图: 1)master会将变动记录到二进制日志里面: 2)master有一个I/O线程将二进制日志发送到sl ...
- 华为OPS,自定义命令,动态执行命令
OPS 开放可编程系统OPS(Open Programmability System)是指设备通过提供统一的应用程序接口API(Application Programming Interfa ...
- 2021夏季学期华清大学EE数算OJ2:难缠的店长
2021年夏季学期华清大学电子系数算oj2题解 某知名oier锐评蒟蒻的oj1题解: 话不多说,进入oj2题解: 难缠的oj 之 难缠的店长 当时读完我已经因为无良甲方的行为出离愤怒了!但是做题还是要 ...
- 一图详解java-class类文件原理
摘要:徒手制作一张超大的类文件解析图,方便通过浏览这个图能马上回忆起class文件的结构以及内部的指令. 本文分享自华为云社区<[读书会第十二期]这可能是全网"最大".&qu ...
- 535. Encode and Decode TinyURL - LeetCode
Question 535. Encode and Decode TinyURL Solution 题目大意:实现长链接加密成短链接,短链接解密成长链接 思路:加密成短链接+key,将长链接按key保存 ...
- Fail2ban 命令详解 fail2ban-server
Fail2ban的服务端操作命令,用于启动一个Fail2ban服务. root@local:~# fail2ban-server --help Usage: /usr/bin/fail2ban-ser ...
- CMake进行C/C++开发(linux下)
开发环境配置 安装GCC,GDB sudo apt update # 通过以下命令安装编译器和调试器 sudo apt install build-essential gdb 安装成功确认 # 以下命 ...
- Go微服务框架go-kratos实战02:proto 代码生成和编码实现步骤
在上一篇 kratos quickstart 文章中,我们直接用 kratos new 命令生成了一个项目. 这一篇来看看 kratos API 的定义和使用. 一.kratos 中 API 简介 1 ...
- C#.NET中的程序集版本
更新记录 2022年4月16日:本文迁移自Panda666原博客,原发布时间:2021年8月22日. 在Visual Studio中查看程序集版本 在程序运行中获得程序集版本信息 除了在Visual ...