Kafka 之 Streams
Kafka 之 Streams
一、概述
1.1 Kafka Streams
Kafka Streams。Apache Kafka开源项目的一个组成部分。是一个功能强大,易于使用的库。用于在Kafka上构建高可分布式、拓展性,容错的应用程序。
1.2 Kafka Streams特点
1)功能强大
高扩展性,弹性,容错
2)轻量级
无需专门的集群
一个库,而不是框架
3)完全集成
100%的Kafka 0.10.0版本兼容
易于集成到现有的应用程序
4)实时性
毫秒级延迟
并非微批处理
窗口允许乱序数据
允许迟到数据
1.3 为什么要有Kafka Stream
当前已经有非常多的流式处理系统,最知名且应用最多的开源流式处理系统有Spark Streaming和Apache Storm。Apache Storm发展多年,应用广泛,提供记录级别的处理能力,当前也支持SQL on Stream。而Spark Streaming基于Apache Spark,可以非常方便与图计算,SQL处理等集成,功能强大,对于熟悉其它Spark应用开发的用户而言使用门槛低。另外,目前主流的Hadoop发行版,如Cloudera和Hortonworks,都集成了Apache Storm和Apache Spark,使得部署更容易。
既然Apache Spark与Apache Storm拥用如此多的优势,那为何还需要Kafka Stream呢?主要有如下原因。
第一,Spark和Storm都是流式处理框架,而Kafka Stream提供的是一个基于Kafka的流式处理类库。框架要求开发者按照特定的方式去开发逻辑部分,供框架调用。开发者很难了解框架的具体运行方式,从而使得调试成本高,并且使用受限。而Kafka Stream作为流式处理类库,直接提供具体的类给开发者调用,整个应用的运行方式主要由开发者控制,方便使用和调试。

第二,虽然Cloudera与Hortonworks方便了Storm和Spark的部署,但是这些框架的部署仍然相对复杂。而Kafka Stream作为类库,可以非常方便的嵌入应用程序中,它对应用的打包和部署基本没有任何要求。
第三,就流式处理系统而言,基本都支持Kafka作为数据源。例如Storm具有专门的kafka-spout,而Spark也提供专门的spark-streaming-kafka模块。事实上,Kafka基本上是主流的流式处理系统的标准数据源。换言之,大部分流式系统中都已部署了Kafka,此时使用Kafka Stream的成本非常低。
第四,使用Storm或Spark Streaming时,需要为框架本身的进程预留资源,如Storm的supervisor和Spark on YARN的node manager。即使对于应用实例而言,框架本身也会占用部分资源,如Spark Streaming需要为shuffle和storage预留内存。但是Kafka作为类库不占用系统资源。
第五,由于Kafka本身提供数据持久化,因此Kafka Stream提供滚动部署和滚动升级以及重新计算的能力。
第六,由于Kafka Consumer Rebalance机制,Kafka Stream可以在线动态调整并行度。
二、Kafka Stream数据清洗案例
0)需求:
实时处理单词带有”>>>”前缀的内容。例如输入”atguigu>>>ximenqing”,最终处理成“ximenqing”
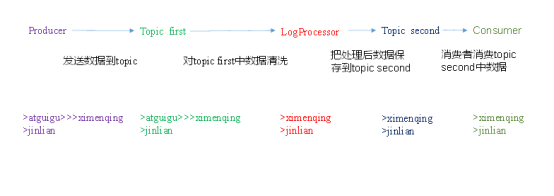
2)案例实操
(1)创建一个工程,并添加jar包
(2)创建主类
package com.libt.kafka.stream;
import java.util.Properties;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorSupplier;
import org.apache.kafka.streams.processor.TopologyBuilder; public class Application { public static void main(String[] args) { // 定义输入的topic
String from = "first";
// 定义输出的topic
String to = "second"; // 设置参数
Properties settings = new Properties();
settings.put(StreamsConfig.APPLICATION_ID_CONFIG, "logFilter");
settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop1:9092"); StreamsConfig config = new StreamsConfig(settings); // 构建拓扑
TopologyBuilder builder = new TopologyBuilder(); builder.addSource("SOURCE", from)
.addProcessor("PROCESS", new ProcessorSupplier<byte[], byte[]>() { @Override
public Processor<byte[], byte[]> get() {
// 具体分析处理
return new LogProcessor();
}
}, "SOURCE")
.addSink("SINK", to, "PROCESS"); // 创建kafka stream
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}
}
(3)具体业务处理
package com.libt.kafka.stream;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorContext; public class LogProcessor implements Processor<byte[], byte[]> { private ProcessorContext context; @Override
public void init(ProcessorContext context) {
this.context = context;
} @Override
public void process(byte[] key, byte[] value) {
String input = new String(value); // 如果包含“>>>”则只保留该标记后面的内容
if (input.contains(">>>")) {
input = input.split(">>>")[1].trim();
// 输出到下一个topic
context.forward("logProcessor".getBytes(), input.getBytes());
}else{
context.forward("logProcessor".getBytes(), input.getBytes());
}
} @Override
public void punctuate(long timestamp) { } @Override
public void close() { }
}
(4)运行程序
(5)在hadoop1上启动生产者
[hadoop1 kafka]$ bin/kafka-console-producer.sh \
--broker-list hadoop1:9092 --topic first >hello>>>world
>h>>>hello
>hahaha
(6)在hadoop2上启动消费者
[hadoop2 kafka]$ bin/kafka-console-consumer.sh \
--zookeeper hadoop1:2181 --from-beginning --topic second world
atguigu
hahaha
Kafka 之 Streams的更多相关文章
- Kafka Streams演示程序
本文从以下六个方面详细介绍Kafka Streams的演示程序: Step 1: 下载代码 Step 2: 启动kafka服务 Step 3: 准备输入topic并启动Kafka生产者 Step 4: ...
- Kafka Streams | 流,实时处理和功能
1.目标 在我们之前的Kafka教程中,我们讨论了Kafka中的ZooKeeper.今天,在这个Kafka Streams教程中,我们将学习Kafka中Streams的实际含义.此外,我们将看到Kaf ...
- 翻译 - Kafka Streams 介绍(一)
2019独角兽企业重金招聘Python工程师标准>>> 资料 [原文地址](http://kafka.apache.org/11/documentation/streams/) 正文 ...
- 3 kafka介绍
本博文的主要内容有 .kafka的官网介绍 http://kafka.apache.org/ 来,用官网上的教程,快速入门. http://kafka.apache.org/documentatio ...
- Kafka Ecosystem(Kafka生态)
http://kafka.apache.org/documentation/#ecosystem https://cwiki.apache.org/confluence/display/KAFKA/E ...
- Kafka 0.11.0.0 实现 producer的Exactly-once 语义(英文)
Exactly-once Semantics are Possible: Here’s How Kafka Does it I’m thrilled that we have hit an excit ...
- How Cigna Tuned Its Spark Streaming App for Real-time Processing with Apache Kafka
Explore the configuration changes that Cigna’s Big Data Analytics team has made to optimize the perf ...
- Streaming SQL for Apache Kafka
KSQL是基于Kafka的Streams API进行构建的流式SQL引擎,KSQL降低了进入流处理的门槛,提供了一个简单的.完全交互式的SQL接口,用于处理Kafka的数据. KSQL是一套基于Apa ...
- 《KAFKA官方文档》入门指南(转)
1.入门指南 1.1简介 Apache的Kafka™是一个分布式流平台(a distributed streaming platform).这到底意味着什么? 我们认为,一个流处理平台应该具有三个关键 ...
随机推荐
- linux-0.11分析:init文件 main.c的第二个初始化函数trap_init() 第五篇随笔
2.第二个初始化函数,trap_init() 参考 [github这个博主的 厉害][ https://github.com/sunym1993/flash-linux0.11-talk ] kern ...
- WebGPU的计算着色器实现冒泡排序
大家好~本文使用WebGPU的计算着色器,实现了奇偶排序. 奇偶排序是冒泡排序的并行版本,在1996年由J Kornerup提出.它解除了每轮冒泡间的串行依赖以及每轮冒泡内部的串行依赖,使得冒泡操作可 ...
- 经典设计原则 - SOLID
SOLID 设计原则包含以下 5 种原则: 单一职责原则(Single Responsibility Principle, SRP) 开闭原则(Open Closed Principle, OCP) ...
- Excel 统计函数(六):RANK
[语法]RANK(number,ref,[order]) [参数] number:要找到其排位的数字. ref:数字列表的数组,对数字列表的引用.Ref 中的非数字值会被忽略. order:一个指定数 ...
- [CSharpTips]判断两条线段是否相交
判断两条线段是否相交 主要用到了通过向量积的正负判断两个向量位置关系 向量a×向量b(×为向量叉乘),若结果小于0,表示向量b在向量a的顺时针方向:若结果大于0,表示向量b在向量a的逆时针方向:若等于 ...
- LOJ6029「雅礼集训 2017 Day1」市场 (线段树)
题面 从前有一个学校,在 O n e I n D a r k \rm OneInDark OneInDark 到任之前风气都是非常良好的,自从他来了之后,发布了一系列奇怪的要求,挟制了整个学校,导致风 ...
- 简单创建一个SpringCloud2021.0.3项目(二)
目录 1. 项目说明 1. 版本 2. 用到组件 3. 功能 2. 上一篇教程 3. 创建公共模块Common 4. 网关Gateway 1. 创建Security 2. Security登陆配置 3 ...
- React报错之Rendered more hooks than during the previous render
正文从这开始~ 总览 当我们有条件地调用一个钩子或在所有钩子运行之前提前返回时,会产生"Rendered more hooks than during the previous render ...
- 如何结合整洁架构和MVP模式提升前端开发体验(二) - 代码实现篇
上一篇文章介绍了整体架构,接下来说说怎么按照上图的分层结构实现下面的增删改查的功能. 代码结构 vue userManage └── List ├── api.ts ├── EditModal │ ├ ...
- Go工程化 - 依赖注入
我们在微服务框架kratos v2的默认项目模板中kratos-layout使用了google/wire进行依赖注入,也建议开发者在维护项目时使用该工具. wire 乍看起来比较违反直觉,导致很多同学 ...