2022-6.824-Lab1:Map&Reduce
1. 介绍
准备工作
阅读 MapReduce
做什么
实现一个分布式的 Map - Reduce 结构,在原先的代码结构中 6.824/src/main/mrsequential.go 实现了单机版的 Map - Reduce ,我们需要将其改造为多进程版本的 Map - Reduce 。一个经典的 Map - Reduce 结构如下
2. 思路
该 lab 中,主要的进程分为 Worker 和 Coordinator,Coordinator 主要负责分发任务,Worker 负责执行任务。
Coordinator
Coordinator 负责管理协调任务,本身具有状态(Map phase 和 Reduce phase),根据不同的 phase 分发不同的任务。
其结构设计如下:
type Coordinator struct {
// Your definitions here.
phase CoordinatorPhase // 当前处于哪个阶段 (Map or Reduce)
MRTasks []MRTask // 记录当前阶段所有任务
lock sync.Mutex
RunningTasks chan MRTask // channel, 用来做任务队列
nReduce int // reduce 任务的数量
nMap int // map 任务的数量
}
Coordinator 默认执行流程如下,只是一个简单的 For Loop,worker 通过 rpc 来请求获取任务: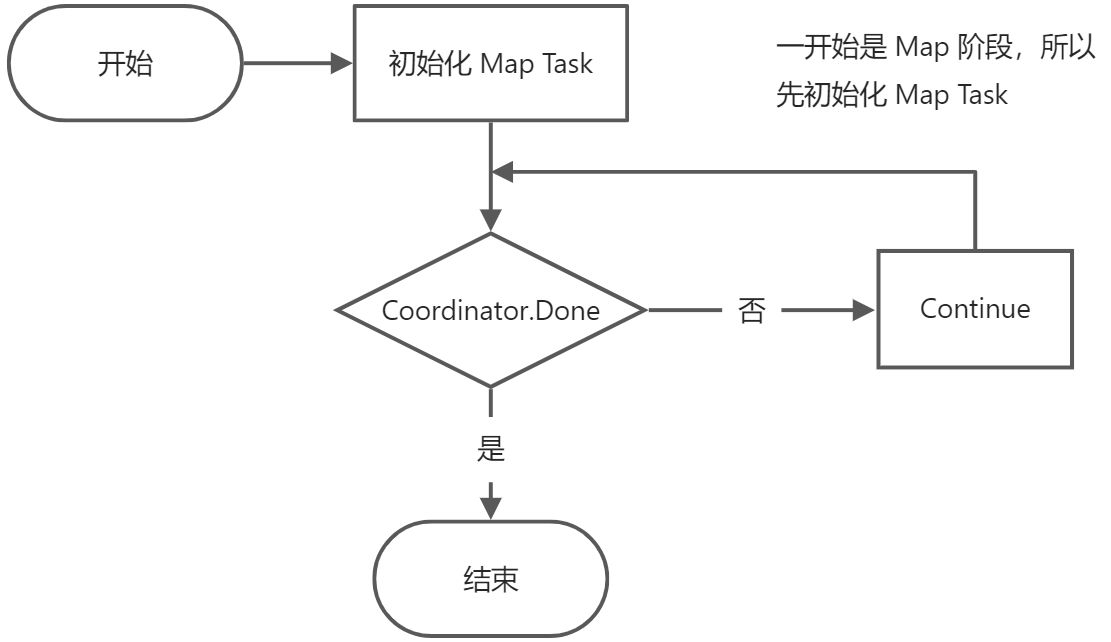
Coordinator 需要提供两个 RPC 调用,RequestTask 和 RequestTaskDone ,分别用来处理请求任务和提交任务,下图为 RequestTask 的处理流程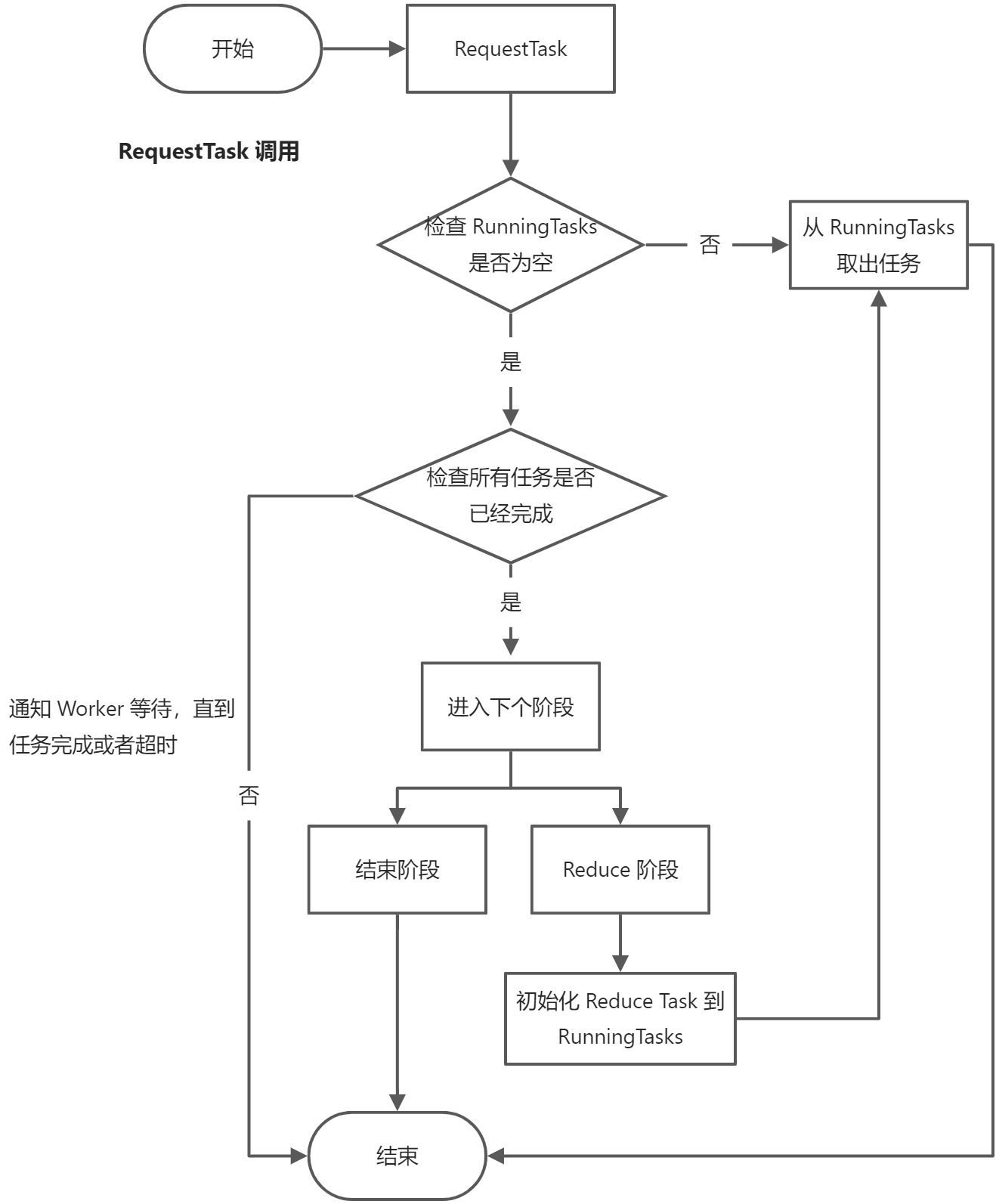
RequestTaskDone 主要在 Worker 执行完 Task 后向 Coordinator 汇报其工作完成了,由 Coordinator 进行最后的确认,将中间文件 Rename 为目标结果文件。
参考了 Google MapReduce 的做法,Worker 在写出数据时可以先写出到临时文件,最终确认没有问题后再将其重命名为正式结果文件,区分开了 Write 和 Commit 的过程。Commit 的过程可以是 Coordinator 来执行,也可以是 Worker 来执行:
- Coordinator Commit:Worker 向 Coordinator 汇报 Task 完成,Coordinator 确认该 Task 是否仍属于该 Worker,是则进行结果文件 Commit,否则直接忽略
- Worker Commit:Worker 向 Coordinator 汇报 Task 完成,Coordinator 确认该 Task 是否仍属于该 Worker 并响应 Worker,是则 Worker 进行结果文件 Commit,再向 Coordinator 汇报 Commit 完成
这里两种方案都是可行的,各有利弊。
Worker
Worker 的逻辑比较简单,主要根据 RPC 返回的任务类型,进行 Map/Reduce 任务,并将中间结果输出到文件中,再通过 RPC 向 Coordinator 通知任务完成。
Worker 本身无限循环,一直请求 Map/Reduce 任务,其退出的条件是请求任务时,收到的消息中 phase 已经切换为结束。
两种 RPC 的结构如下:
// 通知任务完成
type NotifyArgs struct {
TaskID int
TaskType CoordinatorPhase
WorkerID int
}
type NotifyReplyArgs struct {
Confirm bool
}
// 请求任务
type RequestArgs struct {
}
type ReplyArgs struct {
FileName string // map task
TaskID int
TaskType CoordinatorPhase
ReduceNum int
MapNum int
}
3. 实现
Coordinator 初始化
//
// create a Coordinator.
// main/mrcoordinator.go calls this function.
// nReduce is the number of reduce tasks to use.
//
func MakeCoordinator(files []string, nReduce int) *Coordinator {
c := Coordinator{}
c.nReduce = nReduce
// Your code here.
c.phase = PHASE_MAP
c.RunningTasks = make(chan MRTask, len(files)+1)
c.nMap = len(files)
fmt.Printf("start make coordinator ... file count=%d\n", len(files))
for index, fileName := range files {
task := MRTask{
fileName: fileName, // task file
taskID: index, // task id
status: INIT,
taskType: PHASE_MAP,
}
c.MRTasks = append(c.MRTasks, task)
fmt.Printf("[PHASE_MAP]Add Task %v %v\n", fileName, index)
c.RunningTasks <- task
}
c.server()
return &c
}
Coordinator 任务超时机制
lab 中要求任务有一定超时时间,当 worker 超过 10s 没有上报任务成功,则将任务重新放回 RunningTasks 队列
// 任务超时检查
func (c *Coordinator) CheckTimeoutTask() bool {
/*
1. 如果没有超时,则直接 return,等待任务完成 or 超时
2. 有超时,则直接分配该任务给 worker
*/
TaskTimeout := false
now := time.Now().Unix()
for _, task := range c.MRTasks {
if (now-task.startTime) > 10 && task.status != DONE {
fmt.Printf("now=%d,task.startTime=%d\n", now, task.startTime)
c.RunningTasks <- task
TaskTimeout = true
}
}
return TaskTimeout
}
Coordnator 处理请求任务 RPC
由于设计了只要存在 worker,就会一直请求任务,因此将超时检查放在申请任务的前置检查中。
// Your code here -- RPC handlers for the worker to call.
// worker 申请 task
func (c *Coordinator) RequestTask(args *RequestArgs, reply *ReplyArgs) error {
if len(c.RunningTasks) == 0 {
fmt.Printf("not running task ...\n")
// 先检查是否所有任务都已完成
if c.AllTaskDone() {
fmt.Printf("All Task Done ... \n")
c.TransitPhase() // 任务结束,则切换状态
} else if !c.CheckTimeoutTask() { // 检查是否有任务超时
// 没有任务超时,则返回当前状态, 让 worker 等待所有任务完成
fmt.Printf("waiting task finish ... \n")
reply.TaskType = PHASE_WAITTING
return nil
}
}
if c.phase == PHASE_FINISH {
fmt.Printf("all mr task finish ... close coordinator\n")
reply.TaskType = PHASE_FINISH
return nil
}
task, ok := <-c.RunningTasks
if !ok {
fmt.Printf("task queue empty ...\n")
return nil
}
c.lock.Lock()
defer c.lock.Unlock()
c.setupTaskById(task.taskID)
reply.FileName = task.fileName
reply.TaskID = task.taskID
reply.TaskType = c.phase
reply.ReduceNum = c.nReduce
reply.MapNum = c.nMap
return nil
}
Coordnator 处理阶段流转
阶段流转只存在两种情况:
- map 阶段切换到 reduce 阶段
- reduce 阶段切换到结束
主要关注第一种情况,当 map 阶段切换到 reduce 阶段时,清空记录的任务列表 Coordinator.MRTask ,resize RunningTasks channel,因为 reduce 任务数量可能比 map 任务数量要多,需要重新 resize,否则 channel 可能会阻塞。
// 阶段流转
func (c *Coordinator) TransitPhase() {
// 生成对应阶段 task
c.lock.Lock()
newPhase := c.phase
switch c.phase {
case PHASE_MAP:
fmt.Printf("TransitPhase: PHASE_MAP -> PHASE_REDUCE\n")
newPhase = PHASE_REDUCE
c.MRTasks = []MRTask{} // 清空 map task
c.RunningTasks = make(chan MRTask, c.nReduce+1) // resize
for i := 0; i < c.nReduce; i++ {
task := MRTask{
taskID: i, // task id
status: INIT,
taskType: PHASE_REDUCE,
}
c.MRTasks = append(c.MRTasks, task)
fmt.Printf("[PHASE_REDUCE]Add Task %v\n", task)
c.RunningTasks <- task
}
case PHASE_REDUCE:
fmt.Printf("TransitPhase: PHASE_REDUCE -> PHASE_FINISH\n")
newPhase = PHASE_FINISH
}
c.phase = newPhase
c.lock.Unlock()
}
Coordnator 处理提交任务 RPC
主要根据当前阶段,对任务的中间输出结果进行确认(即把 tmp file rename 为 final file)
func (c *Coordinator) CommitTask(args *NotifyArgs) {
switch c.phase {
case PHASE_MAP:
fmt.Printf("[PHASE_MAP] Commit Task %v\n", args)
for i := 0; i < c.nReduce; i++ {
err := os.Rename(tmpMapOutFile(args.WorkerID, args.TaskID, i),
finalMapOutFile(args.TaskID, i))
if err != nil {
fmt.Printf("os.Rename failed ... err=%v\n", err)
return
}
}
case PHASE_REDUCE:
fmt.Printf("[PHASE_REDUCE] Commit Task %v\n", args)
err := os.Rename(tmpReduceOutFile(args.WorkerID, args.TaskID),
finalReduceOutFile(args.TaskID))
if err != nil {
fmt.Printf("os.Rename failed ... err=%v\n", err)
return
}
}
}
func (c *Coordinator) RequestTaskDone(args *NotifyArgs, reply *NotifyReplyArgs) error {
for idx := range c.MRTasks {
task := &c.MRTasks[idx]
if task.taskID == args.TaskID {
task.status = DONE
c.CommitTask(args)
break
}
}
return nil
}
Worker 初始化
根据请求的任务类型(MAP,REDUCE,FINISH,WAITING),做不同处理
- MAP :执行 Map 任务
- REDUCE : 执行 Reduce 任务
- WAITTING :等待,这种情况意味 Coordinator 没有空闲任务,也没有完成所有任务,有任务还在运行当中
- FINISH :表示所有任务已经完成,可以退出
Worker
//
// main/mrworker.go calls this function.
//
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
// Your worker implementation here.
for {
args := RequestArgs{}
reply := ReplyArgs{}
ok := call("Coordinator.RequestTask", &args, &reply)
if !ok {
fmt.Printf("call request task failed ...\n")
return
}
fmt.Printf("call finish ... file name %v\n", reply)
switch reply.TaskType {
case PHASE_MAP:
DoMapTask(reply, mapf)
case PHASE_REDUCE:
DoReduceTask(reply, reducef)
case PHASE_WAITTING: // 当前 coordinator 任务已经分配完了,worker 等待一会再试
time.Sleep(5 * time.Second)
case PHASE_FINISH:
fmt.Printf("coordinator all task finish ... close worker")
return
}
}
}
Worker 处理 Map
参考 6.824/src/main/mrsequential.go
func DoMapTask(Task ReplyArgs, mapf func(string, string) []KeyValue) bool {
fmt.Printf("starting do map task ...\n")
file, err := os.Open(Task.FileName)
if err != nil {
fmt.Printf("Open File Failed %s\n", Task.FileName)
return false
}
content, err := ioutil.ReadAll(file)
if err != nil {
fmt.Printf("ReadAll file Failed %s\n", Task.FileName)
return false
}
file.Close()
fmt.Printf("starting map %s \n", Task.FileName)
kva := mapf(Task.FileName, string(content))
hashedKva := make(map[int][]KeyValue)
for _, kv := range kva {
hashed := ihash(kv.Key) % Task.ReduceNum
hashedKva[hashed] = append(hashedKva[hashed], kv)
}
for i := 0; i < Task.ReduceNum; i++ {
outFile, _ := os.Create(tmpMapOutFile(os.Getpid(), Task.TaskID, i))
for _, kv := range hashedKva[i] {
fmt.Fprintf(outFile, "%v\t%v\n", kv.Key, kv.Value)
}
outFile.Close()
}
NotifiyTaskDone(Task.TaskID, Task.TaskType)
return true
}
Worker 处理 Reduce
参考 6.824/src/main/mrsequential.go
func DoReduceTask(Task ReplyArgs, reducef func(string, []string) string) bool {
/*
1. 先获取所有 tmp-{mapid}-{reduceid} 中 reduce id 相同的 task
*/
fmt.Printf("starting do reduce task ...\n")
var lines []string
for i := 0; i < Task.MapNum; i++ {
filename := finalMapOutFile(i, Task.TaskID)
file, err := os.Open(filename)
if err != nil {
log.Fatalf("cannot open %v", filename)
}
content, err := ioutil.ReadAll(file)
if err != nil {
log.Fatalf("cannot read %v", filename)
}
/*
2. 将所有文件的内容读取出来,合并到一个数组中
*/
lines = append(lines, strings.Split(string(content), "\n")...)
}
/*
3. 过滤数据,将每行字符串转成 KeyValue, 归并到数组
*/
var kva []KeyValue
for _, line := range lines {
if strings.TrimSpace(line) == "" {
continue
}
split := strings.Split(line, "\t")
kva = append(kva, KeyValue{
Key: split[0],
Value: split[1],
})
}
/*
4. 模仿 mrsequential.go 的 reduce 操作,将结果写入到文件,并 commit
*/
sort.Sort(ByKey(kva))
outFile, _ := os.Create(tmpReduceOutFile(os.Getpid(), Task.TaskID))
i := 0
for i < len(kva) {
j := i + 1
for j < len(kva) && kva[j].Key == kva[i].Key {
j++
}
var values []string
for k := i; k < j; k++ {
values = append(values, kva[k].Value)
}
output := reducef(kva[i].Key, values)
fmt.Fprintf(outFile, "%v %v\n", kva[i].Key, output)
i = j
}
outFile.Close()
NotifiyTaskDone(Task.TaskID, Task.TaskType)
return true
}
Worker 通知任务完成
func NotifiyTaskDone(taskId int, taskType CoordinatorPhase) {
args := NotifyArgs{}
reply := NotifyReplyArgs{}
args.TaskID = taskId
args.TaskType = taskType
args.WorkerID = os.Getpid()
ok := call("Coordinator.RequestTaskDone", &args, &reply)
if !ok {
fmt.Printf("Call Coordinator.RequestTaskDone failed ...")
return
}
if reply.Confirm {
fmt.Printf("Task %d Success, Continue Next Task ...", taskId)
}
}
4. 各种异常情况
- worker crash 处理
coordinator 有超时机制,只有 worker 完成并且成功 commit ,才会标记任务结束,因此 crash 之后,当前处理中的任务最后会重新返回到 task channel 中
- rpc call 需要参数名首字符大写,否则可能无法正确传输
2022-6.824-Lab1:Map&Reduce的更多相关文章
- MIT 6.824 lab1:mapreduce
这是 MIT 6.824 课程 lab1 的学习总结,记录我在学习过程中的收获和踩的坑. 我的实验环境是 windows 10,所以对lab的code 做了一些环境上的修改,如果你仅仅对code 感兴 ...
- MapReduce剖析笔记之三:Job的Map/Reduce Task初始化
上一节分析了Job由JobClient提交到JobTracker的流程,利用RPC机制,JobTracker接收到Job ID和Job所在HDFS的目录,够早了JobInProgress对象,丢入队列 ...
- python--函数式编程 (高阶函数(map , reduce ,filter,sorted),匿名函数(lambda))
1.1函数式编程 面向过程编程:我们通过把大段代码拆成函数,通过一层一层的函数,可以把复杂的任务分解成简单的任务,这种一步一步的分解可以称之为面向过程的程序设计.函数就是面向过程的程序设计的基本单元. ...
- 记一次MongoDB Map&Reduce入门操作
需求说明 用Map&Reduce计算几个班级中,每个班级10岁和20岁之间学生的数量: 需求分析 学生表的字段: db.students.insert({classid:1, age:14, ...
- filter,map,reduce,lambda(python3)
1.filter filter(function,sequence) 对sequence中的item依次执行function(item),将执行的结果为True(符合函数判断)的item组成一个lis ...
- map reduce
作者:Coldwings链接:https://www.zhihu.com/question/29936822/answer/48586327来源:知乎著作权归作者所有,转载请联系作者获得授权. 简单的 ...
- python基础——map/reduce
python基础——map/reduce Python内建了map()和reduce()函数. 如果你读过Google的那篇大名鼎鼎的论文“MapReduce: Simplified Data Pro ...
- Map/Reduce 工作机制分析 --- 作业的执行流程
前言 从运行我们的 Map/Reduce 程序,到结果的提交,Hadoop 平台其实做了很多事情. 那么 Hadoop 平台到底做了什么事情,让 Map/Reduce 程序可以如此 "轻易& ...
- Map/Reduce个人实战--生成数据测试集
背景: 在大数据领域, 由于各方面的原因. 有时需要自己来生成测试数据集, 由于测试数据集较大, 因此采用Map/Reduce的方式去生成. 在这小编(mumuxinfei)结合自身的一些实战经历, ...
- 用通俗易懂的大白话讲解Map/Reduce原理
Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Reduce,分布式文件系统HDFS,以及分布式数据库Hbase,同时Hadoop的相关项目也很丰 ...
随机推荐
- ELK 性能优化实践
文章转载自:https://mp.weixin.qq.com/s?__biz=MzI5MTU1MzM3MQ==&mid=2247489814&idx=1&sn=6916f8b7 ...
- 改善C#程序的方法-3 比较器和LINQ排序
一 创建对象时考虑实现比较器 假设有这样的场景,有一个40个人的学生列表,业务中需针对学生的成绩来进行排序. 可以考虑用IComparable接口和ICompare接口实现: class Progra ...
- Libgdx游戏开发(2)——接水滴游戏实现
原文:Libgdx游戏开发(2)--接水滴游戏实现 - Stars-One的杂货小窝 本文使用Kotlin语言开发 通过本文的学习可以初步了解以下基础知识的使用: Basic file access ...
- 文件管理工具“三剑客” #Everything #SpaceSniffer #Clover
前言: 本文收集了我日常使用的三个文件管理工具: 文件搜索神器--Everything 磁盘文件占用分析工具--SpaceSniffer 文件资源管理器--Clover 下面我从工具解决的痛点和使用技 ...
- 分布式存储系统之Ceph集群RBD基础使用
前文我们了解了Ceph集群cephx认证和授权相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/16748149.html:今天我们来聊一聊ceph集群的 ...
- 我用canvas带你看一场流星雨
前言 最近总是梦见一些小时候的故事,印象最深刻的就是夏天坐在屋顶上,看着满天的繁星,一颗,两颗,三颗...不由自主地开始了数星星的过程.不经意间,一颗流星划过夜间,虽然只是转瞬即逝,但它似乎比夜空中的 ...
- Condition介绍
Condition Condition是一种多线程通信工具,表示多线程下参与数据竞争的线程的一种状态,主要负责多线程环境下对线程的挂起和唤醒工作. 方法 // ========== 阻塞 ====== ...
- C语言两个升序递增链表逆序合并为一个降序递减链表,并去除重复元素
#include"stdafx.h" #include<stdlib.h> #define LEN sizeof(struct student) struct stud ...
- Linux软件安装方式 - Tarball&RPM&YUM
软件安装 简介 概念详解 # 概念详解 - 开放源码: 程序码, 写给人类看的程序语言, 但机器并不认识, 所以无法执行; - 编译器: 将程序码转译成为机器看的懂得语言, 就类似翻译者的角色; - ...
- Windows7下驱动开发与调试体系构建——2.R3与R0的通信示例
目录/参考资料:https://www.cnblogs.com/railgunRG/p/14412321.html 在阅读本节前,建议先阅读<Windows内核安全与驱动开发>第五章内容, ...