24-[模块]-re
1、引入re
请从以下文件里取出所有的手机号
姓名 地区 身高 体重 电话
况咏蜜 北京 171 48 13651054608
王心颜 上海 169 46 13813234424
马纤羽 深圳 173 50 13744234523
乔亦菲 广州 172 52 15823423525
罗梦竹 北京 175 49 18623423421
刘诺涵 北京 170 48 18623423765
岳妮妮 深圳 177 54 18835324553
贺婉萱 深圳 174 52 18933434452
叶梓萱 上海 171 49 18042432324
杜姗姗 北京 167 49 13324523342
(1)普通版本
# -*- coding:utf-8 -*-
phone = []
with open('phone', 'r',encoding='utf-8') as f:
for line in f:
line1 = line.split()
for i in line1:
if i.startswith('') and len(i) == 11:
phone.append(i)
print(phone)
(2)文艺版本
# 拆包
# -*- coding:utf-8 -*-
phone_list = []
with open('phone', 'r',encoding='utf-8') as f:
for line in f:
# 拆包
name,city,height,weight,phone = line.split()
if phone.startswith('') and len(phone) == 11:
phone_list.append(phone)
print(phone_list)
(3)装B版本
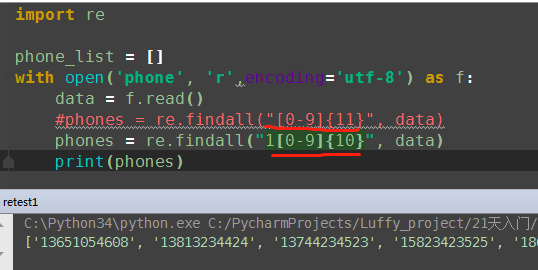
2.正则表达式
- 正则表达式本质上是一门语言,它不从属与Python!Python只是将他人写好的正则引擎集成到了语言内部,大多数编程语言都是这么干的!
- 正则表达式诞生的时间很长,应用非常广泛,是业界公认的字符串匹配工具。虽然有不同版本的内部引擎,但基本通用,也就是说,你在Python内写的正则表达式,可以移植到Linux的shell,Java语言等任何支持正则的场景中去。
- 正则表达式默认从左往右匹配。
- 正则表达式默认是贪婪模式。
- 正则表达式默认在匹配到了内容后,则终止匹配,不继续匹配。
- 对同一个问题,编写的正则表达式不是唯一的!
3.常用正则表达式
(1)校验数字的相关表达式:
| 功能 | 表达式 |
|---|---|
| 数字 | ^[0-9]*$ |
| n位的数字 | ^\d{n}$ |
| 至少n位的数字 | ^\d{n,}$ |
| m-n位的数字 | ^\d{m,n}$ |
| 零和非零开头的数字 | ^(0|[1-9][0-9]*)$ |
| 非零开头的最多带两位小数的数字 | ^([1-9][0-9]*)+(.[0-9]{1,2})?$ |
| 带1-2位小数的正数或负数 | ^(\-)?\d+(\.\d{1,2})?$ |
| 正数、负数、和小数 | ^(\-|\+)?\d+(\.\d+)?$ |
| 有两位小数的正实数 | ^[0-9]+(.[0-9]{2})?$ |
| 有1~3位小数的正实数 | ^[0-9]+(.[0-9]{1,3})?$ |
| 非零的正整数 | ^[1-9]\d*$ |
| 非零的负整数 | ^-[1-9]\d*$ |
| 非负整数 | ^\d+$ |
| 非正整数 | ^-[1-9]\d*|0$ |
| 非负浮点数 | ^\d+(\.\d+)?$ |
| 非正浮点数 | ^((-\d+(\.\d+)?)|(0+(\.0+)?))$ |
| 正浮点数 | ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ |
| 负浮点数 | ^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ |
| 浮点数 | ^(-?\d+)(\.\d+)?$ |
(2)校验字符的相关表达式:
| 功能 | 表达式 |
|---|---|
| 汉字 | ^[\u4e00-\u9fa5]{0,}$ |
| 英文和数字 | ^[A-Za-z0-9]+$ |
| 长度为3-20的所有字符 | ^.{3,20}$ |
| 由26个英文字母组成的字符串 | ^[A-Za-z]+$ |
| 由26个大写英文字母组成的字符串 | ^[A-Z]+$ |
| 由26个小写英文字母组成的字符串 | ^[a-z]+$ |
| 由数字和26个英文字母组成的字符串 | ^[A-Za-z0-9]+$ |
| 由数字、26个英文字母或者下划线组成的字符串 | ^\w+$ |
| 中文、英文、数字包括下划线 | ^[\u4E00-\u9FA5A-Za-z0-9_]+$ |
| 中文、英文、数字但不包括下划线等符号 | ^[\u4E00-\u9FA5A-Za-z0-9]+$ |
可以输入含有^%&’,;=?$\”等字符 |
[^%&’,;=?$\x22]+ |
禁止输入含有~的字符 |
[^~\x22]+ |
(3)特殊场景的表达式:
| 功能 | 表达式 |
|---|---|
| Email地址 | ^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$ |
| 域名 | [a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.? |
| InternetURL | [a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$ |
| 手机号码 | ^(13[0-9]|14[5|7]|15[0|1|2|3|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$ |
| 国内电话号码 | \d{3}-\d{8}|\d{4}-\d{7}(0511-4405222、021-87888822) |
| 身份证号 | ^\d{15}|\d{18}$(15位、18位数字) |
| 短身份证号码 | ^([0-9]){7,18}(x|X)?$ 或 ^\d{8,18}|[0-9x]{8,18}|[0-9X]{8,18}?$(数字、字母x结尾) |
| 帐号是否合法 | ^[a-zA-Z][a-zA-Z0-9_]{4,15}$(字母开头,允许5-16字节,允许字母数字下划线) |
| 密码 | ^[a-zA-Z]\w{5,17}$(以字母开头,长度在6~18之间,只能包含字母、数字和下划线) |
| 强密码 | ^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间) |
| 日期格式 | ^\d{4}-\d{1,2}-\d{1,2} |
| 一年的12个月(01~09和1~12) | ^(0?[1-9]|1[0-2])$ |
| 一个月的31天(01~09和1~31) | ^((0?[1-9])|((1|2)[0-9])|30|31)$ |
| xml文件 | ^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$ |
| 双字节字符 | [^\x00-\xff](包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)) |
| 空白行的正则表达式 | \n\s*\r (可以用来删除空白行) |
| HTML标记的正则表达式 | <(\S*?)[^>]*>.*?</\1>|<.*? />(对于复杂的嵌套标记依旧无能为力) |
| 首尾空白字符的正则表达式 | ^\s*|\s*$或(^\s*)|(\s*$)(可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等)) |
| 腾讯QQ号 | [1-9][0-9]{4,} (腾讯QQ号从10000开始) |
| 中国邮政编码 | [1-9]\d{5}(?!\d) (中国邮政编码为6位数字) |
| IP地址提取 | \d+\.\d+\.\d+\.\d+ (提取IP地址时有用) |
| IP地址合法性判断 | ((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)) |
4、re模块
正则表达式就是字符串的匹配规则,在多数编程语言里都有相应的支持,python里对应的模块是re
常用的表达式规则
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾, 若指定flags MULTILINE ,re.search('foo.$','foo1\nfoo2\n',re.MULTILINE).group() 会匹配到foo1
'*' 匹配*号前的字符0次或多次, re.search('a*','aaaabac') 结果'aaaa'
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次 ,re.search('b?','alex').group() 匹配b 0次
'{m}' 匹配前一个字符m次 ,re.search('b{3}','alexbbbs').group() 匹配到'bbb'
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配, re.search("(abc){2}a(123|45)", "abcabca456c").group() 结果为'abcabca45' '\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的,相当于re.match('abc',"alexabc") 或^
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
's' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t' '(?P<name>...)' 分组匹配
re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city")
结果{'province': '3714', 'city': '81', 'birthday': '1993'}
# . 匹配任意字符
>>> re.search('.','abc123')
<_sre.SRE_Match object; span=(, ), match='a'>
>>> re.search('..','1abc123')
<_sre.SRE_Match object; span=(, ), match='1a'> # ^a 匹配 以a开头
>>> re.search('^a','abc123')
<_sre.SRE_Match object; span=(, ), match='a'>
>>> re.search('^ab','abc123')
<_sre.SRE_Match object; span=(, ), match='ab'> # $ 匹配 以3结尾
>>> re.search('3$','abc123')
<_sre.SRE_Match object; span=(, ), match=''>
>>> re.search('2$','abc123')
>>> re.search('1.3$','abc123')
<_sre.SRE_Match object; span=(, ), match=''>
>>> re.search('.json$','1234.json')
<_sre.SRE_Match object; span=(, ), match='.json'> # + 匹配 b多次
>>> re.search('ab+','aaabbb')
<_sre.SRE_Match object; span=(, ), match='abbb'>
>>> re.search('.+','aaabbb')
<_sre.SRE_Match object; span=(, ), match='aaabbb'> # ? 匹配a一次或0次
>>> re.search('a?','aaabbb')
<_sre.SRE_Match object; span=(, ), match='a'>
>>> re.search('a?','bbb')
<_sre.SRE_Match object; span=(, ), match=''> # {} 匹配a 2次
>>> re.search('a{2}','aaabbb')
<_sre.SRE_Match object; span=(, ), match='aa'>
>>> re.search('a{3}','aaabbb')
<_sre.SRE_Match object; span=(, ), match='aaa'> #匹配数字0- 多次
>>> re.search('[0-9]{2}','aaabbb')
>>> re.search('[0-9]{2}','abc123')
<_sre.SRE_Match object; span=(, ), match=''> #匹配字母a-z 多次
>>> re.search('[a-z]{2}','aaabbb')
<_sre.SRE_Match object; span=(, ), match='aa'> >>> re.search('[A-Z]{2}','aaabbb')
>>> re.search('[A-Z]{2}','AAAbbb')
<_sre.SRE_Match object; span=(, ), match='AA'> #匹配字母a-z -10次
>>> re.search('[A-Z]{1,10}','AAAbbb')
<_sre.SRE_Match object; span=(, ), match='AAA'>
>>> re.search('[A-Z]{1,10}','AAABBB')
<_sre.SRE_Match object; span=(, ), match='AAABBB'> # 匹配A或者AA,先匹配左边
>>> re.search('A|AA','AAABBB')
<_sre.SRE_Match object; span=(, ), match='A'>
>>> re.search('A|B','AAABBB')
<_sre.SRE_Match object; span=(, ), match='A'>
>>> re.search('Aa|B','AAABBB')
<_sre.SRE_Match object; span=(, ), match='B'>
>>>
>>> re.search('[a|A]lex','alex')
<_sre.SRE_Match object; span=(, ), match='alex'>
>>> re.search('[a|A]lex','Alex')
<_sre.SRE_Match object; span=(, ), match='Alex'> # 匹配多次
>>> re.search('[0-9]+[a-z]+','abc123')
>>> re.search('[0-9]+[a-z]+','123abc')
<_sre.SRE_Match object; span=(, ), match='123abc'>
>>>

# [-]
>>> re.search('\d','123abc')
<_sre.SRE_Match object; span=(, ), match=''> >>> re.search('\d+','123abc')
<_sre.SRE_Match object; span=(, ), match=''>
>>>
>>> re.search('\d+','123abc456')
<_sre.SRE_Match object; span=(, ), match=''> #匹配非数字
>>> re.search('\D+','123abc456%^&^')
<_sre.SRE_Match object; span=(, ), match='abc'>
>>> re.search('\D+','123abcW@#$#456')
<_sre.SRE_Match object; span=(, ), match='abcW@#$#'> # 匹配[A-Za-z0-]
>>> re.search('\w+','123abcW@#$#456')
<_sre.SRE_Match object; span=(, ), match='123abcW'> #匹配非[A-Za-z0-]
>>> re.search('\W+','123abcW@#$#456')
<_sre.SRE_Match object; span=(, ), match='@#$#'>
>>> # 匹配空白字符、\t、\n、\r
>>> re.search('\s','123\nabc')
<_sre.SRE_Match object; span=(, ), match='\n'> >>> re.search('\s+','123\nabc\t')
<_sre.SRE_Match object; span=(, ), match='\n'> >>> re.findall('\s','123\nabc\t')
['\n', '\t']
分组匹配
>>> re.search('()()()','199408310555')
>>> re.search('(?P<year>[0-9]{4})(?P<month>[0-9]{2})(?P<day>[0-9]{2})','199408310555')
<_sre.SRE_Match object; span=(0, 8), match='19940831'>
>>> re.search('(?P<year>[0-9]{4})(?P<month>[0-9]{2})(?P<day>[0-9]{2})','199408310555').groups()
('1994', '08', '31')
>>> re.search('(?P<year>[0-9]{4})(?P<month>[0-9]{2})(?P<day>[0-9]{2})','199408310555').groupdict('')
{'year': '1994', 'day': '31', 'month': '08'}
>>> re.search('(?P<year>[0-9]{4})(?P<month>[0-9]{2})(?P<day>[0-9]{2})','199408310555').groupdict()['year']
'1994'
5.re的匹配语法
re的匹配语法有以下几种
- re.match 从头开始匹配
- re.search 匹配包含
- re.findall 把所有匹配到的字符放到以列表中的元素返回
- re.split 以匹配到的字符当做列表分隔符
- re.sub 匹配字符并替换
- re.fullmatch 全部匹配
(1)re.match(pattern, string, flags=0)
match()方法会在给定字符串的开头进行匹配,如果匹配不成功则返回None,匹配成功返回一个匹配对象,这个对象有个group()方法,可以将匹配到的字符串给出。
- pattern 正则表达式
- string 要匹配的字符串
- flags 标志位,用于控制正则表达式的匹配方式
In [21]: re.match('\d+', 'uu12asf')
In [22]: re.match('\d+', '12uuasf') # 从头匹配
Out[22]: <_sre.SRE_Match object; span=(0, 2), match='12'>
In [12]: import re
In [13]: obj = re.match('\d+', '123uufe')
In [14]: obj.group() #打印结果
Out[14]: '123'
import re
obj = re.match('\d+', '123uuasf')
if obj:
print obj.group() #拿到匹配值
(2)re.search(pattern, string, flags=0)
根据模型去字符串中匹配指定内容,匹配单个,全局匹配
In [24]: re.search('\d+', '12uuasf')
Out[24]: <_sre.SRE_Match object; span=(0, 2), match='12'>
In [25]: obj = re.search('\d+', '12uuasf')
In [26]: obj.group()
Out[26]: '12'
(3)re.findall(pattern, string, flags=0)
match and search均用于匹配单值,即:只能匹配字符串中的一个,如果想要匹配到字符串中所有符合条件的元素,则需要使用 findall。
In [29]: re.findall('\d+', '12uuasf')
Out[29]: ['12']
In [27]: obj = re.findall('\d+', '12uuasf')
In [28]: obj
Out[28]: ['12']
(4)re.fullmatch(pattern, string, flags=0)
整个字符串匹配成功就返回re object, 否则返回None
>>> re.fullmatch('[a-z]+@[a-z]+.com','alex@outlook.com')
<_sre.SRE_Match object; span=(0, 16), match='alex@outlook.com'>
>>> re.fullmatch('\w+@\w+.com|cn|edu','alex@outlook.com')
<_sre.SRE_Match object; span=(0, 16), match='alex@outlook.com'>
>>> re.fullmatch('\w+@\w+.com|cn|edu','alex@outlook.cn')
>>> re.fullmatch('\w+@\w+.(com|cn|edu)','alex@outlook.cn')
<_sre.SRE_Match object; span=(0, 15), match='alex@outlook.cn'>
(5)re.split(pattern, string, maxsplit=0, flags=0)
>>>s='9-2*5/3+7/3*99/4*2998+10*568/14'
>>>re.split('[\*\-\/\+]',s)
['9', '2', '5', '3', '7', '3', '99', '4', '2998', '10', '568', '14'] >>> re.split('[\*\-\/\+]',s,3)
['9', '2', '5', '3+7/3*99/4*2998+10*568/14']
# 数字分割
>>> s = 'alex123jack456tom789'
>>> re.split('\d',s)
['alex', '', '', 'jack', '', '', 'tom', '', '', '']
>>>
>>> re.split('\d+',s)
['alex', 'jack', 'tom', '']
>>>
>>> re.findall('\d+',s)
['', '', ''] # 特殊字符分割
>>> s = 'alex123ja#$ck456t#om-789'
>>> re.split('\d+|#|-',s)
['alex', 'ja', '$ck', 't', 'om', '', '']
>>> s = 'alex123#jack456#tom-789'
>>> re.split('\d+|#|-',s)
['alex', '', 'jack', '', 'tom', '', ''] # | 分割
>>> s = 'alex|jack'
>>> re.split('|',s)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.5/re.py", line 203, in split
return _compile(pattern, flags).split(string, maxsplit)
ValueError: split() requires a non-empty pattern match.
>>>
>>> re.split('\',s)
File "<stdin>", line 1
re.split('\',s)
^
SyntaxError: EOL while scanning string literal
>>> re.split('\|',s)
['alex', 'jack']
>>>
>>> s = 'alex|jack'
(6)re.sub(pattern, repl, string, count=0, flags=0)
用于替换匹配的字符串
>>> re.sub('[a-z]+','sb','武配齐是abc123',)
'武配齐是sb123'
>>> re.sub('\d+','|', 'alex22wupeiqi33oldboy55',count=2)
'alex|wupeiqi|oldboy55'
相比于str.replace功能更加强大
(7)Flags标志符
- re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
- M(MULTILINE): 多行模式,改变'^'和'$'的行为
- S(DOTALL): 改变'.'的行为,make the '.' special character match any character at all, including a newline; without this flag, '.' will match anything except a newline.
- X(re.VERBOSE) 可以给你的表达式写注释,使其更可读,下面这2个意思一样
a = re.compile(r"""\d + # the integral part
\. # the decimal point
\d * # some fractional digits""",
re.X) b = re.compile(r"\d+\.\d*")
# 大小写忽略
>>> re.search('a','Alex')
>>> re.search('a','Alex',re.I)
<_sre.SRE_Match object; span=(0, 1), match='A'> #M 多行模式
>>> re.search('foo.$','foo1\nfoo2\n')
<_sre.SRE_Match object; span=(5, 9), match='foo2'>
>>>
>>> re.search('foo.$','foo1\nfoo2\n',re.M)
<_sre.SRE_Match object; span=(0, 4), match='foo1'> # 改变. 的行为
>>> re.search('.','\n')
>>> re.search('.','\n',re.S)
<_sre.SRE_Match object; span=(0, 1), match='\n'> # re.X 注释
>>> re.search('. #test','alex')
>>> re.search('. #test','alex',re.X)
<_sre.SRE_Match object; span=(0, 1), match='a'>
>>>
(8)re.compile(pattern, flags=0)
Compile a regular expression pattern into a regular expression object, which can be used for matching using its match(), search() and other methods, described below.
The sequence
prog = re.compile(pattern)
result = prog.match(string)
is equivalent to
result = re.match(pattern, string)
but using re.compile() and saving the resulting regular expression object for reuse is more efficient when the expression will be used several times in a single program.
这个方法是re模块的工厂方法,用于将字符串形式的正则表达式编译为Pattern模式对象,可以实现更高效率的匹配。第二个参数flag是匹配模式。
使用compile()完成一次转换后,再次使用该匹配模式的时候就不用进行转换了。经过compile()转换的正则表达式对象也能使用普通的re方法。其用法如下:
>>> pat = re.compile(r'abc') # 相当于数据库中的索引
>>> pat.match('abc123')
<_sre.SRE_Match object; span=(0, 3), match='abc'>
>>> pat.match('')
>>> pat.match('abc123').group()
'abc' >>> re.match('abc','abc123')
<_sre.SRE_Match object; span=(0, 3), match='abc'>
那么是使用compile()还是直接使用re.match()呢?看场景!如果你只是简单的匹配一下后就不用了,那么re.match()这种简便的调用方式无疑来得更简单快捷。如果你有个模式需要进行大量次数的匹配,那么先compile编译一下再匹配的方式,效率会高很多。
6.练习:
1.验证手机号是否合法
2.验证邮箱是否合法
3.开发一个简单的python计算器,实现加减乘除及拓号优先级解析
- 用户输入 1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )等类似公式后,必须自己解析里面的(),+,-,*,/符号和公式(不能调用eval等类似功能偷懒实现),运算后得出结果,结果必须与真实的计算器所得出的结果一致
hint:
re.search(r'\([^()]+\)',s).group()#可拿到最里层的括号中的值 '(-40/5)'


24-[模块]-re的更多相关文章
- 使用OLAMISDK实现一个语音输入数字进行24点计算的iOS程序
前言 在目前的软件应用中,输入方式还是以文字输入方式为主,但是语音输入的方式目前应用的越来越广泛.这是一个利用 Olami SDK 编写的一个24点iOS程序,是通过语音进行输入. Olami SDK ...
- python全栈开发 * 24 知识点汇总 * 180705
24 模块-------序列化一.什么是模块 模块:py文件就是一个模块.二.模块的分类:(1)内置模块 (登录模块,时间模块,sys模块,os模块)(2)扩展模块 (itchat 微信有关,爬虫,b ...
- TP控制器(Controller)
控制器的一些方法: Maincontroller.class.php文件: <?php namespace Home\Controller; use Think\Controller; clas ...
- Python 自省指南
原作者:Patrick K. O'Brien 什么是自省? 在日常生活中,自省(introspection)是一种自我检查行为.自省是指对某人自身思想.情绪.动机和行为的检查.伟大的哲学家苏格拉底将生 ...
- Python课程笔记(四)
1.模块的导入 相当于Java的包或C语言的头文件 (1) import math s = math.sqrt(25) print(s) (2) from math import sqrt s=mat ...
- 布客·ApacheCN 翻译/校对/笔记整理活动进度公告 2020.1
注意 请贡献者查看参与方式,然后直接在 ISSUE 中认领. 翻译/校对三个文档就可以申请当负责人,我们会把你拉进合伙人群.翻译/校对五个文档的贡献者,可以申请实习证明. 请私聊片刻(52981514 ...
- 布客·ApacheCN 翻译校对活动进度公告 2020.5
注意 请贡献者查看参与方式,然后直接在 ISSUE 中认领. 翻译/校对三个文档就可以申请当负责人,我们会把你拉进合伙人群.翻译/校对五个文档的贡献者,可以申请实习证明. 请私聊片刻(52981514 ...
- Java SE 9 新增特性
Java SE 9 新增特性 作者:Grey 原文地址: Java SE 9 新增特性 源码 源仓库: Github:java_new_features 镜像仓库: GitCode:java_new_ ...
- 编译boost python模块遇到的错误:../../libraries/boost_1_44_0/boost/python/detail/wrap_python.hpp:75:24: fatal error: patchlevel.h: No such file or directory
就是遇到类似标题上面的错误. 原因是没有安装对应python的python-dev依赖,不然编译到boost python模块的时候就会出错. 所以解决方案是sudo apt-get install ...
- python ---24 正则表达式 re模块
一.正则表达式 1.字符组 ① [abc] 匹配a或b或c ② [a-z] 匹配a到z之间的所有字⺟ [0-9]匹配所有阿拉伯数字 2.元字符 3.量词 4.重要搭配 ① .*? ② .*?x ...
随机推荐
- Oracle 启用归档
[applprod@erp10 ~]$ watch ps -fu applprod[applprod@erp10 ~]$ kill -9 82902 84923 [applprod@erp10 ~]$ ...
- Oracle EBS 报错 您不具有分配给您的清除MDS的权限
- cef开启摄像头和录音
参考资料:https://github.com/cztomczak/phpdesktop/wiki/Chrome-settings#command_line_switches CefSharp中文帮助 ...
- Windows 7 添加快速启动栏
1.右击任务栏空白处,选择 “工具栏” ,单击 “新建工具栏” 2.输入 以下路径: %userprofile%\AppData\Roaming\Microsoft\Internet Explorer ...
- jQuery: 刨根问底 attr and prop两个函数的区别
In this short post I will explain the difference between attributes and properties in HTML. The .pro ...
- ZT C语言实现字符串倒序
http://blog.chinaunix.net/uid-20788517-id-34777.html 分类: C/C++ 1 #include <stdio.h> 2 #includ ...
- 4-urllib库添加代理,添加请求头格式 模板
urllib 库设置代理的方法 案例如下:
- 【模块化】 RequireJS入门教程总结与推荐
之所以学习RequireJS,肯定对 模块化有一定的理解.这里有几篇学习 RequireJS的文章,推荐给大家去学习. Javascript模块化编程(一):模块的写法 Javascript模块化编程 ...
- QT 登录记住密码方法之一:Qt QSettings读写配置文件
不过本文写的是明文保存,最好还是加密一下,以防文件被非法读取 /**登录初始化的时候处理这部分操作*/ Settings cfg("user.ini",QSettings::Ini ...
- Python的unittest框架的断言总结
常用的断言方法如下: assertFalse:为假时返回True:self.assertFalse(表达式,“表达式为true时打印的message”) assertTrue:为真时返回True:se ...