Hadoop HA 高可用集群的搭建
hadoop部署服务器
| 系统 | 主机名 | IP |
| centos6.9 | hadoop01 | 192.168.72.21 |
| centos6.9 | hadoop02 | 192.168.72.22 |
| centos6.9 | hadoop03 | 192.168.72.23 |
基础环境准备
1.修改Linux主机名
2.修改IP
3.修改主机名和IP的映射关系 /etc/hosts
4.关闭防火墙
5.ssh免登陆
6.安装JDK,配置环境变量等
7.注意集群时间要同步
8.安装zookeeper集群
部署节点规划
集群部署节点角色的规划(3节点)
server01 namenode resourcemanager zkfc nodemanager datanode zookeeper journal node
server02 namenode resourcemanager zkfc nodemanager datanode zookeeper journal node
server03 datanode nodemanager zookeeper journal node
安装部署
上传编译好的hadoop安装程序到服务器上并解压到指定目录
[root@hadoop01 soft]# tar zxvf spark-2.2.-bin-2.6.-cdh5.14.0.tgz -C /usr/local/
[root@hadoop01 soft]# cd /usr/local/
[root@hadoop01 soft]# mv hadoop-2.6.-cdh5.14.0 hadoop-HA
配置Hadoop环境变量,编辑/etc/profile添加Hadoop环境变量
[root@hadoop01 soft]# vim /etc/profile
############################HADOOP HA########################################
export HADOOP_HOME=/usr/local/hadoop-HA
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
修改Hadoop相关配置文件
修改hadoop-env.sh文件,配置HAVA_HOME如下
export JAVA_HOME=/usr/local/java/jdk1.8.0_201
修改core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property> <!-- 这里的路径默认是NameNode、DataNode、JournalNode等存放数据的公共目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-HA/tmp</value>
</property> <!-- ZooKeeper集群的地址和端口。注意,数量一定是奇数,且不少于三个节点-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
修改hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为cluster1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
<!-- cluster1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster1.nn1</name>
<value>hadoop01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.cluster1.nn1</name>
<value>hadoop1:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster1.nn2</name>
<value>hadoop02:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.cluster1.nn2</name>
<value>hadoop02:50070</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/cluster1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop-HA/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 指定该集群出故障时,哪个实现类负责执行故障切换 -->
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
修改mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property> <!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property> <!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property> <!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop01</value>
</property> <property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop02</value>
</property> <!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> </configuration>
修改slaves(slaves是指定子节点的位置,因为要在hadoop01上启动HDFS、在hadoop03启动yarn,所以hadoop01上的slaves文件指定的是datanode的位置,hadoop03上的slaves文件指定的是nodemanager的位置)
hadoop01
hadoop02
hadoop03
Hadoop集群启动
启动zookeeper集群(分别在hadoop01、hadoop02、hadoop03上启动zk)
bin/zkServer.sh start
#查看状态:一个leader,两个follower
bin/zkServer.sh status
手动启动journalnode(分别在hadoop01、hadoop02、hadoop03上执行)
hadoop-daemon.sh start journalnode #运行jps命令检验,hadoop01、hadoop02、hadoop03上多了JournalNode进程
格式化namenode
在hadoop00上执行命令:
hdfs namenode -format #格式化后会在根据core-site.xml中的hadoop.tmp.dir配置的目录下生成个hdfs初始化文件
把hadoop.tmp.dir配置的目录下所有文件拷贝到另一台namenode节点所在的机器
scp -r hadoop-HA root@hadoop02:$PWD
##也可以这样,建议hdfs namenode -bootstrapStandby
格式化ZKFC(在active上执行即可)
hdfs zkfc -formatZK
启动HDFS(在hadoop00上执行)
start-dfs.sh
启动YARN
start-yarn.sh
还需要手动在standby上手动启动备份的 resourcemanager
yarn-daemon.sh start resourcemanager
JPS查看启动进程
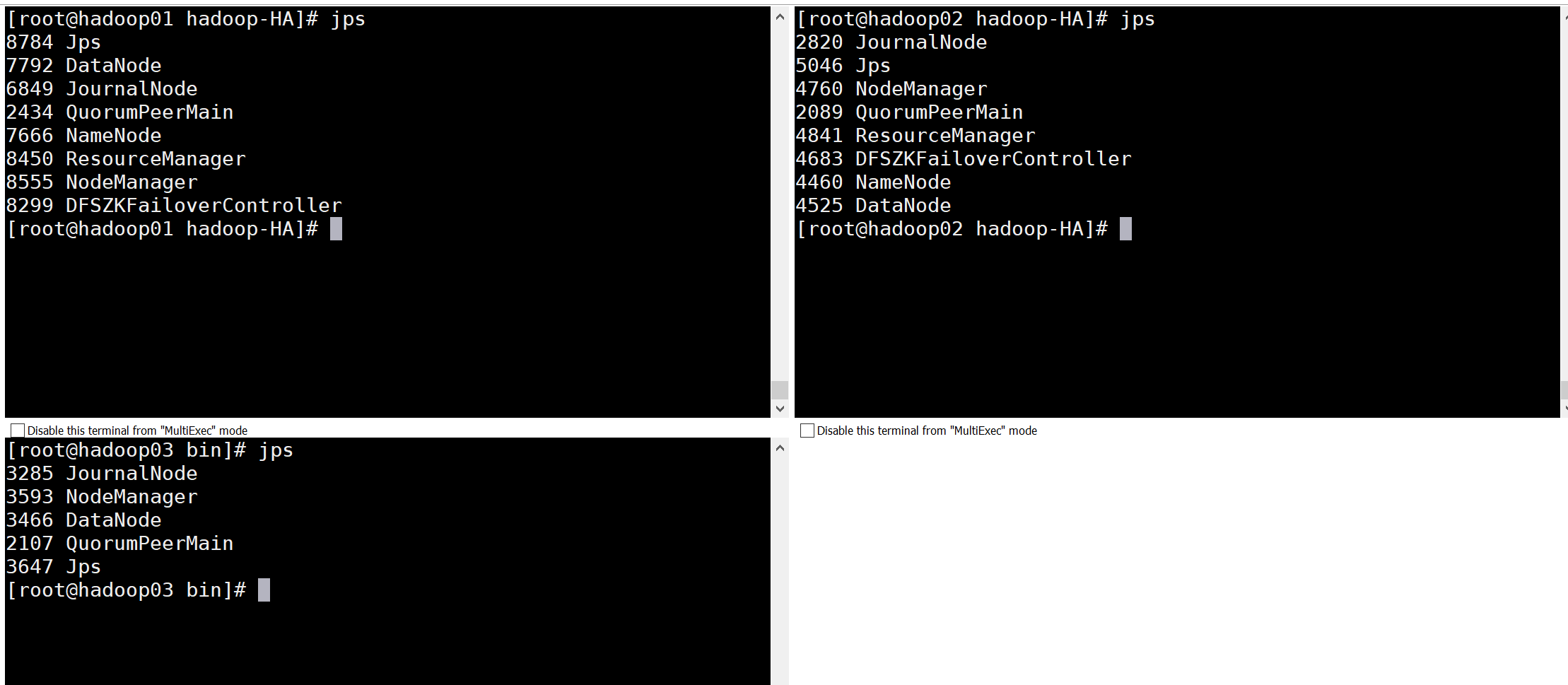
集群验证
到此,hadoop-2.6.4配置完毕,可以统计浏览器访问:
NameNode 'hadoop01:9000' (active)
NameNode 'hadoop02:9000' (standby)
验证HDFS HA
首先向hdfs上传一个文件
hadoop fs -put /etc/profile /profile
hadoop fs -ls /
然后再kill掉active的NameNode
kill -9 <pid of NN>
通过浏览器访问:http://192.168.1.202:50070
NameNode 'hadoop02:9000' (active)
这个时候hadoop02上的NameNode变成了active
在执行命令:
hadoop fs -ls /
-rw-r--r-- 3 root supergroup 1926 2014-02-06 15:36 /profile
刚才上传的文件依然存在!!!
手动启动那个挂掉的NameNode
hadoop-daemon.sh start namenode
通过浏览器访问:http://192.168.1.201:50070
NameNode 'hadoop01:9000' (standby)
验证YARN:
运行一下hadoop提供的demo中的WordCount程序:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar wordcount /profile /out
测试集群工作状态的一些指令 :
hdfs dfsadmin -report 查看hdfs的各节点状态信息
cluster1n/hdfs haadmin -getServiceState nn1 获取一个namenode节点的HA状态
scluster1n/hadoop-daemon.sh start namenode 单独启动一个namenode进程
./hadoop-daemon.sh start zkfc 单独启动一个zkfc进程
Hadoop HA 高可用集群的搭建的更多相关文章
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课
centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课 heartbeat是Linu ...
- Hadoop HA 高可用集群搭建
一.首先配置集群信息 vi /etc/hosts 二.安装zookeeper 1.解压至/usr/hadoop/下 .tar.gz -C /usr/hadoop/ 2.进入/usr/hadoop/zo ...
- Hadoop HA高可用集群搭建(2.7.2)
1.集群规划: 主机名 IP 安装的软件 执行的进程 drguo1 192.168.80.149 j ...
- Zookeeper(四)Hadoop HA高可用集群搭建
一.高可就集群搭建 1.集群规划 2.集群服务器准备 (1) 修改主机名(2) 修改 IP 地址(3) 添加主机名和 IP 映射(4) 同步服务器时间(5) 关闭防火墙(6) 配置免密登录(7) 安装 ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- 七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)
目录 前文 Hadoop3.3.1 HA 高可用集群的搭建 QJM 的 NameNode HA Hadoop HA模式搭建(高可用) 1.集群规划 2.Zookeeper集群搭建: 3.修改Hadoo ...
- linux -- 基于zookeeper搭建yarn的HA高可用集群
linux -- 基于zookeeper搭建yarn的HA高可用集群 实现方式:配置yarn-site.xml配置文件 <configuration> <property> & ...
- HA 高可用集群概述及其原理解析
HA 高可用集群概述及其原理解析 1. 概述 1)所谓HA(High Available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件 ...
随机推荐
- [POI 2014]RAJ-Rally
Description 题库链接 给定一个 \(N\) 个点 \(M\) 条边的有向无环图,每条边长度都是 \(1\).请找到一个点,使得删掉这个点后剩余的图中的最长路径最短. \(1\leq N\l ...
- [转]微信小程序之购物车 —— 微信小程序实战商城系列(5)
本文转自:http://blog.csdn.net/michael_ouyang/article/details/70755892 续上一篇的文章:微信小程序之商品属性分类 —— 微信小程序实战商城 ...
- PHP数组基本的操作方法
1.数组操作的基本函数 数组的键和值: array_values($arr);获得数组的值 array_keys($arr);获得数组的键名 array_flip($arr);数组中的值与键名互换(如 ...
- [PHP] 商品类型规格属性后台管理(代码流程备忘)
实现界面 涉及到四张表,type(商品类型表),type_spec(商品类型规格关联表),attribute(商品属性表),attribute_value(商品属性值表) 新建基控制器BaseCont ...
- google自定义广告系列
Part1:说明 向网址添加参数以标识引荐流量的广告系列. 通过向在广告系列中使用的目标网址添加广告系列参数,您可以收集这些广告系列整体效果的相关信息,还可以了解广告系列在何处投放时效果更好.例如,您 ...
- 装饰器模式(Decorator Pattern)
装饰器模式 一.什么是装饰器模式 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其结构.这种类型的设计模式属于结构型模式,它是作为现有的类的一个包装 ...
- spring boot 报错 Failed to read HTTP message
2008-12-13 15:06:03,930 WARN (DefaultHandlerExceptionResolver.java:384)- Failed to read HTTP message ...
- 微软正式开源Blazor,将.NET带回到浏览器
微软 ASP.NET 团队近日正式开源了Blazor,这是一个Web UI框架,可通过WebAssembly在任意浏览器中运行 .Net. Blazor旨在简化快速的单页面 .Net 浏览器应用的构建 ...
- RabbitMQ--学习资源汇
1.RabbitMQ 实战教程 文集(alibaba) 2.RabbitMQ从入门到精通(9篇系列博文 )(anzhsoft2008 ) 3. RabbitMQ目录(nick's blog) 使用 ...
- RequestAnimationFrame更好的实现Javascript动画
一直以来,JavaScript的动画都是通过定时器和间隔来实现的.虽然使用CSS transitions 和 animations使Web开发实现动画更加方便,但多年来以JavaScript为基础来实 ...