mysql千万级表关联优化(2)
概述:
交代一下背景,这算是一次项目经验吧,属于公司一个已上线平台的功能,这算是离职人员挖下的坑,随着数据越来越多,原本的SQL查询变得越来越慢,用户体验特别差,因此SQL优化任务交到了我手上。
这个SQL查询关联两个数据表,一个是攻击IP用户表主要是记录IP的信息,如第一次攻击时间,地址,IP等等,一个是IP攻击次数表主要是记录每天IP攻击次数。而需求是获取某天攻击IP信息和次数。(以下SQL语句测试均在测试服务器上上,正式服务器的性能好,查询时间快不少。)
准备:
查看表的行数: 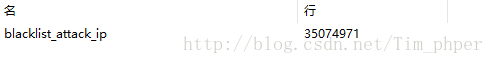

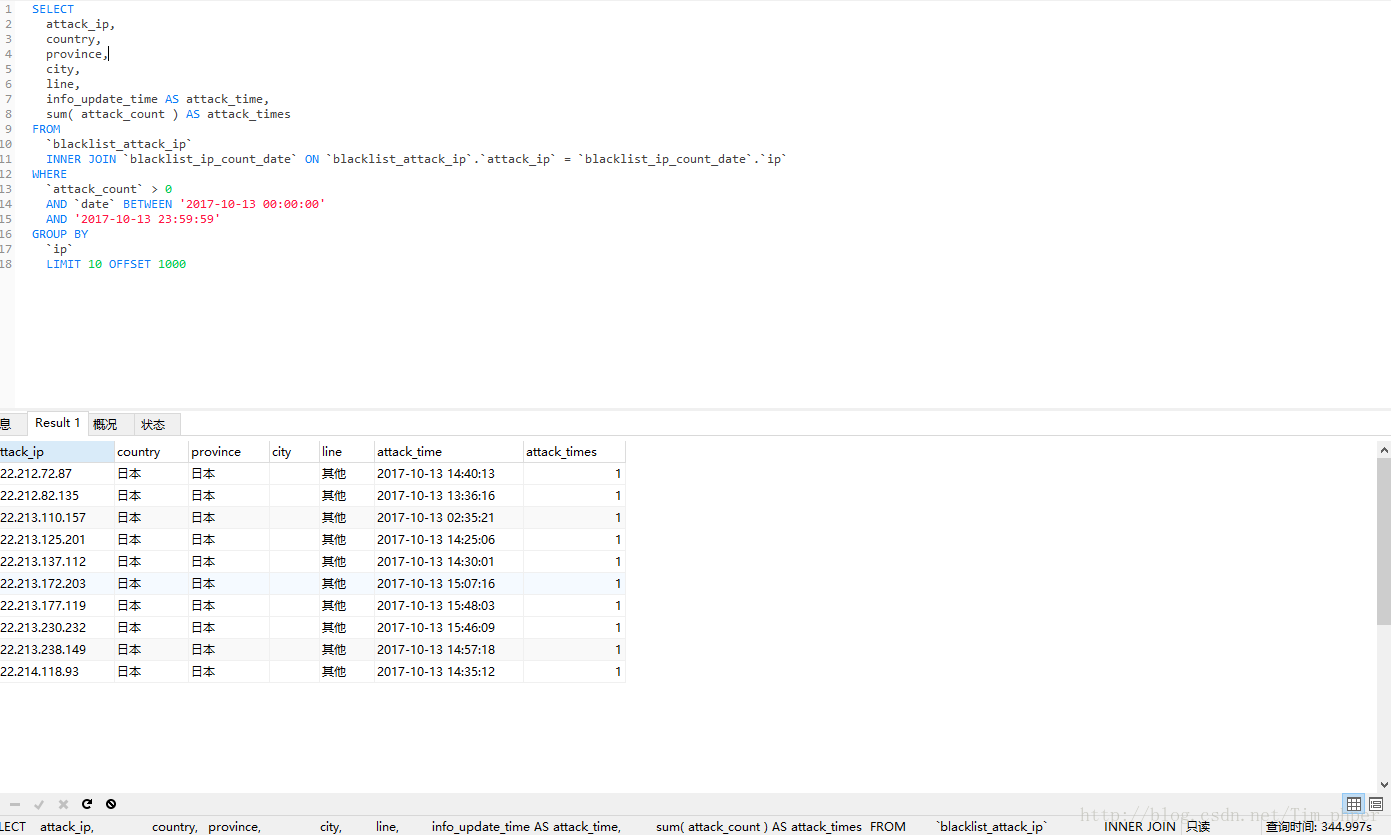
未优化前SQL语句为:
SELECT
attack_ip,
country,
province,
city,
line,
info_update_time AS attack_time,
sum( attack_count ) AS attack_times
FROM
`blacklist_attack_ip`
INNER JOIN `blacklist_ip_count_date` ON `blacklist_attack_ip`.`attack_ip` = `blacklist_ip_count_date`.`ip`
WHERE
`attack_count` > 0
AND `date` BETWEEN '2017-10-13 00:00:00'
AND '2017-10-13 23:59:59'
GROUP BY
`ip`
LIMIT 10 OFFSET 1000- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
先EXPLAIN分析一下:
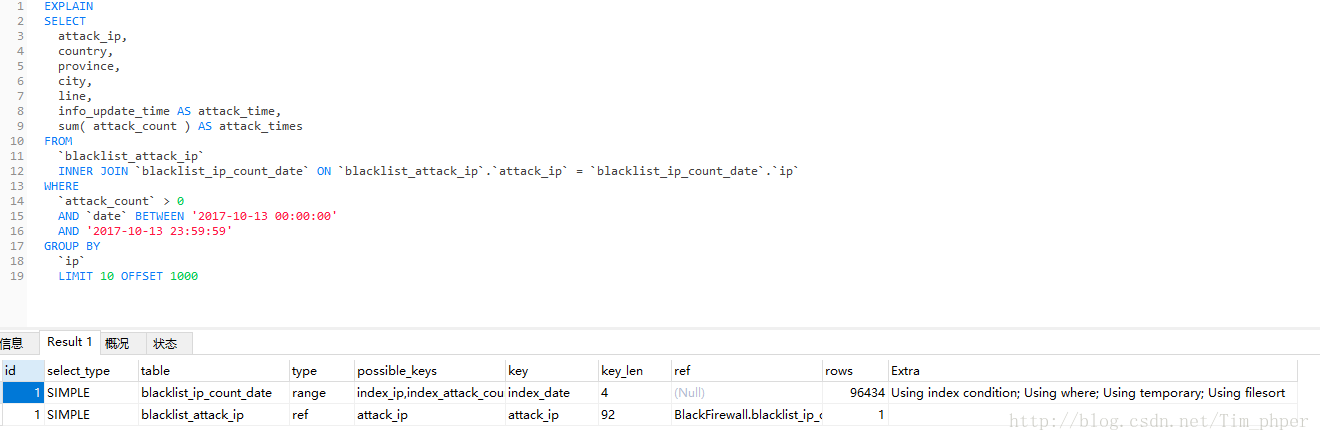
这里看到索引是有的,但是IP攻击次数表blacklist_ip_count_data也用上了临时表。那么这SQL不优化直接第一次执行需要多久(这里强调第一次是因为MYSQL带有缓存功能,执行过一次的同样SQL,第二次会快很多。)
实际查询时间为300+秒,这完全不能接受呀,这还是没有其他搜索条件下的。
那么我们怎么优化呢,这里用的是内联表查询,大家都是知道子查询完全是可以代替内联表查询的,只不过SQL语句复杂了不少,那么我们分析一下这SQL,两个表分表提供了什么?
1、IP攻击次数表blacklist_ip_count_data主要提供的指定时间条件查询,攻击次数条件查询后的IP和每个IP符合条件下的具体攻击次数。
2、攻击IP用户表blacklist_attack_ip主要是具体IP的信息,如第一次攻击时间,地址,IP等等。
那么我们一步步来:
1、IP攻击次数表blacklist_ip_count_data获取符合时间条件和攻击次数的IP并且以IP分组: 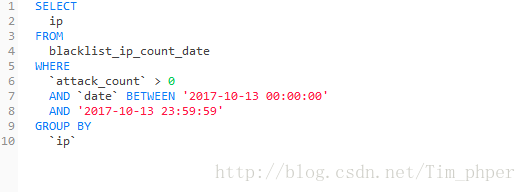
2、攻击IP用户表blacklist_attack_ip指定具体的IP获取信息: 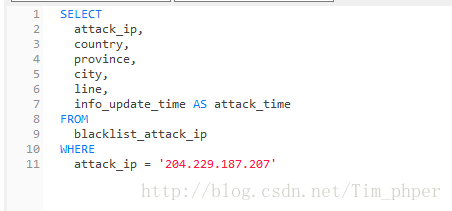
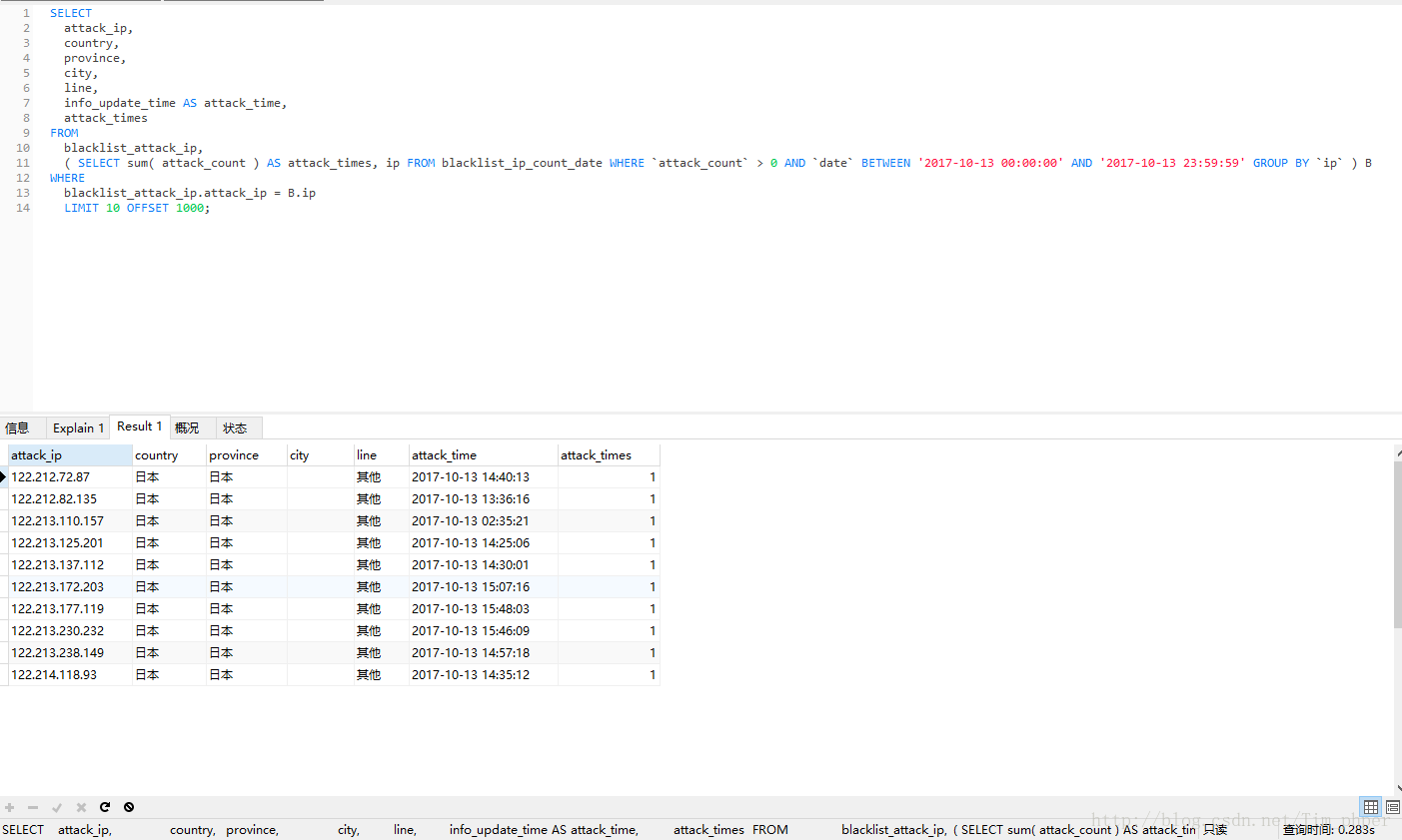
然后结合在一起:
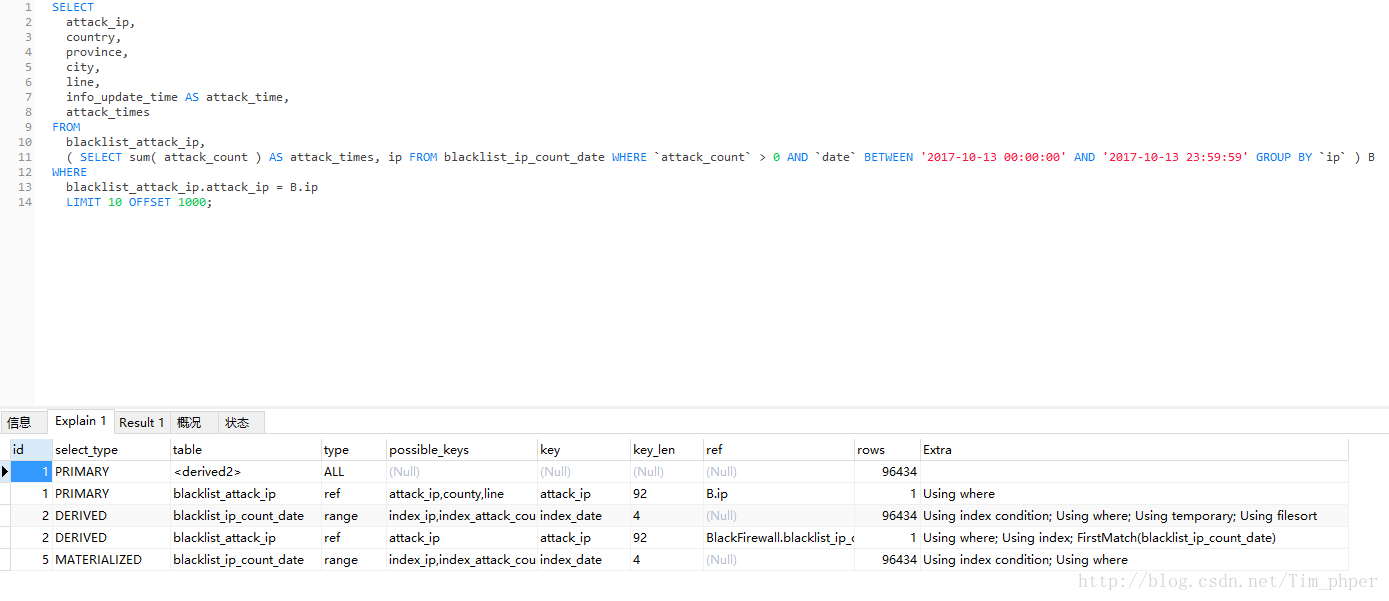
可见,取出来的数据完全一模一样,可是优化后效率从原来的330秒变成了0.28秒,这里足足提升了1000多倍的速度。这也基本满足了我们的优化需求。
我们EXPLAIN了解一下情况:
mysql千万级表关联优化(2)的更多相关文章
- mysql千万级表关联优化
MYSQL一次千万级连表查询优化(一) 概述: 交代一下背景,这算是一次项目经验吧,属于公司一个已上线平台的功能,这算是离职人员挖下的坑,随着数据越来越多,原本的SQL查询变得越来越慢,用户体验特别差 ...
- 如何优化MySQL千万级大表
很好的一篇博客,转载 如何优化MySQL千万级大表 原文链接::https://blog.csdn.net/yangjianrong1985/article/details/102675334 千万级 ...
- Mysql千万级大表优化
Mysql的单张表的最大数据存储量尚没有定论,一般情况下mysql单表记录超过千万以后性能会变得很差.因此,总结一些相关的Mysql千万级大表的优化策略. 1.优化sql以及索引 1.1优化sql 1 ...
- MySQL千万级大表优化解决方案
MySQL千万级大表优化解决方案 非原创,纯属记录一下. 背景 无意间看到了这篇文章,作者写的很棒,于是乎,本人自私一把,把干货保存下来.:-) 问题概述 使用阿里云rds for MySQL数据库( ...
- MySQL 百万级分页优化(Mysql千万级快速分页)(转)
http://www.jb51.net/article/31868.htm 以下分享一点我的经验 一般刚开始学SQL的时候,会这样写 复制代码 代码如下: SELECT * FROM table OR ...
- MySQL 百万级分页优化(Mysql千万级快速分页)
以下分享一点我的经验 一般刚开始学SQL的时候,会这样写 : SELECT * FROM table ORDER BY id LIMIT 1000, 10; 但在数据达到百万级的时候,这样写会慢死 : ...
- 如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案
如何优化Mysql千万级快速分页,limit优化快速分页,MySQL处理千万级数据查询的优化方案
- mysql千万级数据库插入速度和读取速度的调整记录
一般情况下mysql上百万数据读取和插入更新是没什么问题了,但到了上千万级就会出现很慢,下面我们来看mysql千万级数据库插入速度和读取速度的调整记录吧. 1)提高数据库插入性能中心思想:尽量将数据一 ...
- 如何对MySQL 对于大表(千万级)进行优化
如何对Mysql中的大型表进行优化 @(mysql 笔记) 收集信息 1.数据的容量:1-3年内会大概多少条数据,每条数据大概多少字节: 2.数据项:是否有大字段,那些字段的值是否经常被更新: 3.数 ...
随机推荐
- R kernel for Jupyter Notebook 支持r
1/2) Installing via supplied binary packages(default on Windows + Mac OS X) You can install all pack ...
- Navicat数据备份
备份:点击数据库---数据传输 目标:备份地点,数据会传送到yaozh_backup 数据传输成功
- Hadoop生态圈-phoenix的视图(view)管理
Hadoop生态圈-phoenix的视图(view)管理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任.
- hadoop基础-SequenceFile详解
hadoop基础-SequenceFile详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.SequenceFile简介 1>.什么是SequenceFile 序列文件 ...
- memset函数使用详解
1.void *memset(void *s,int c,size_t n) 总的作用:将已开辟内存空间 s 的首 n 个字节的值设为值 c. 2.例子#include void main(){cha ...
- Java锁及AbstractQueuedSynchronizer源码分析
一,Lock 二,关于锁的几个概念 三,ReentrantLock类图 四,几个重要的类 五,公平锁获取 5.1 lock 5.2 acquire 5.3 tryAcquire 5.3.1 hasQu ...
- spring boot(三):spring data jpa的使用
@RequestMapping("/queryUserListByPageNativeQuery") public String queryUserListByPageNative ...
- 20155331 2016-2017-2 《Java程序设计》第5周学习总结
20155331 2016-2017-2 <Java程序设计>第5周学习总结 教材学习内容总结 一.Java异常的基础知识 异常是程序中的一些错误,但并不是所有的错误都是异常,并且错误有时 ...
- 用代码从文件中导入数据到SQL Server
引言 导入数据到SQL Server 是常见的需求,特别是定期导入这种需求. 对于定期导入主要有以下几种方式可选择: Bulk Insert Bcp Utility OpenRowSet 写程序导入( ...
- mnist 手写数字识别
mnist 手写数字识别三大步骤 1.定义分类模型2.训练模型3.评价模型 import tensorflow as tfimport input_datamnist = input_data.rea ...