浅谈一致性哈希(My转)
一致性哈希(Consistent hashing)算法是由 MIT 的Karger 等人与1997年在一篇学术论文(《Consistent hashing and random trees: distributed caching protocols for relieving hot spots on the World Wide Web》)中提出来的,用于解决分布式缓存数据分布问题。在传统的哈希算法下,每条缓存数据落在那个节点是通过哈希算法和服务器节点数量计算出来的,一旦服务器节点数量发生增加或者介绍,哈希值需要重新计算,此时几乎所有的数据和服务器节点的对应关系也会随之发生变化,进而会造成绝大多数缓存的失效。一致性哈希算法通过环形结构和虚拟节点的概念,确保了在缓存服务器节点数量发生变化时大部分数据保持原地不动,从而大幅提高了缓存的有效性。下面我们通过例子来解释一致性哈希的原理。
比如有 n 个节点,对于缓存 数据(k,v)具体存在哪个节点往往 hash(k) % n 来计算处理,举一个例子如下表所示,一共有个3个节点,hash函数采用 md5 。
| 缓存key | hash(k) % n | 服务器节点 |
|---|---|---|
| user_nick_rommel | 1 | 192.168.56.101 |
| user_nick_pandy | 0 | 192.168.56.100 |
| user_nick_sam | 2 | 192.168.56.102 |
Md5 的计算结果一般是一串32位的16进制字符串,做取模运算时原始数字较长,实际使用时,可以只截取最后4位或者8位使用,因为hash函数具有随机性,当数据量足球大时,截取部分数据也能保证数据的均匀分布。比如 md5('user_nick_rommel'),对应字符串为 29e4fd2a0f05bd63343ae2276ca5038e,取最后4位
038e转成10进制整数在进行取模运算,038e 对应的10进制数为 910,取模计算得 1 (9102 % 3 = 1)。
如果此时对缓存服务器进行扩容,添加一个新节点如 192.168.56.103,那么按照上面的计算方式,n 变为4, 得到的结果如下:
| 缓存key | hash(k) % n | 服务器节点 |
|---|---|---|
| user_nick_rommel | 2 | 192.168.56.102 |
| user_nick_pandy | 2 | 192.168.56.102 |
| user_nick_sam | 3 | 192.168.56.103 |
从结果中可见,缓存对应关系完全发生改变,比如 user_nick_rommel 这个可以,添加节点钱可以从 192.168.56.101 中读到,添加节点后却读不到了,。一般缓存失效时应用程序都会重新从后端服务加载数据(比如数据库),以这种这种方式分配缓存,当缓节点数量发生改变时,会造成大面积的缓存失效,这回造成后端服务瞬间压力上升,压力过大会造成服务不可以用,如果服务出于关键节点,甚至还会引发雪崩效应(TODO)。
在实际应用中,缓存节点由于故障挂掉,或者空间不足而进行扩容,缓存节点的增减是比较常见的事情,但上面传统方式会使服务的不可靠,下面看下一致性哈希是如何解决这个问题的。
在一致性哈希算法中,首先将哈希空间映射到一个虚拟的环上,环上的数值分从 0 到 2^32-1(哈希值的范围),如下图:
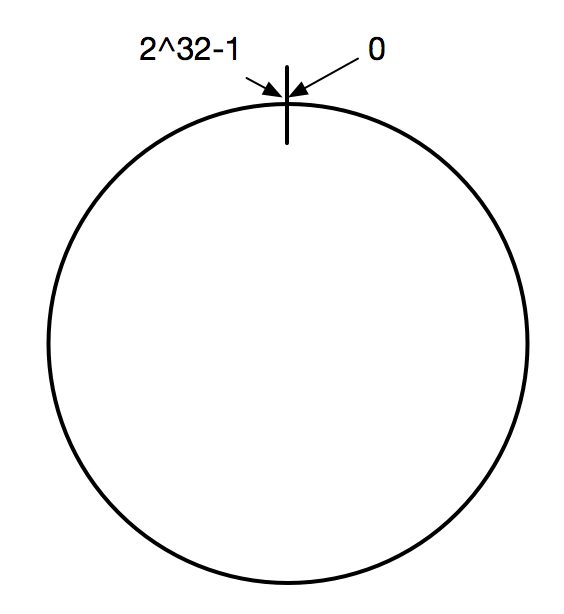
在一致性哈希算法刚提出来的时候,32位系统还是主流,2^32-1 相当于最大Integer,现在的应用服务器普遍都是64位系统,在使用使用一致性哈希算法时可以根据实际情况适当变通,比如将哈希值空间放大到 2^64-1。
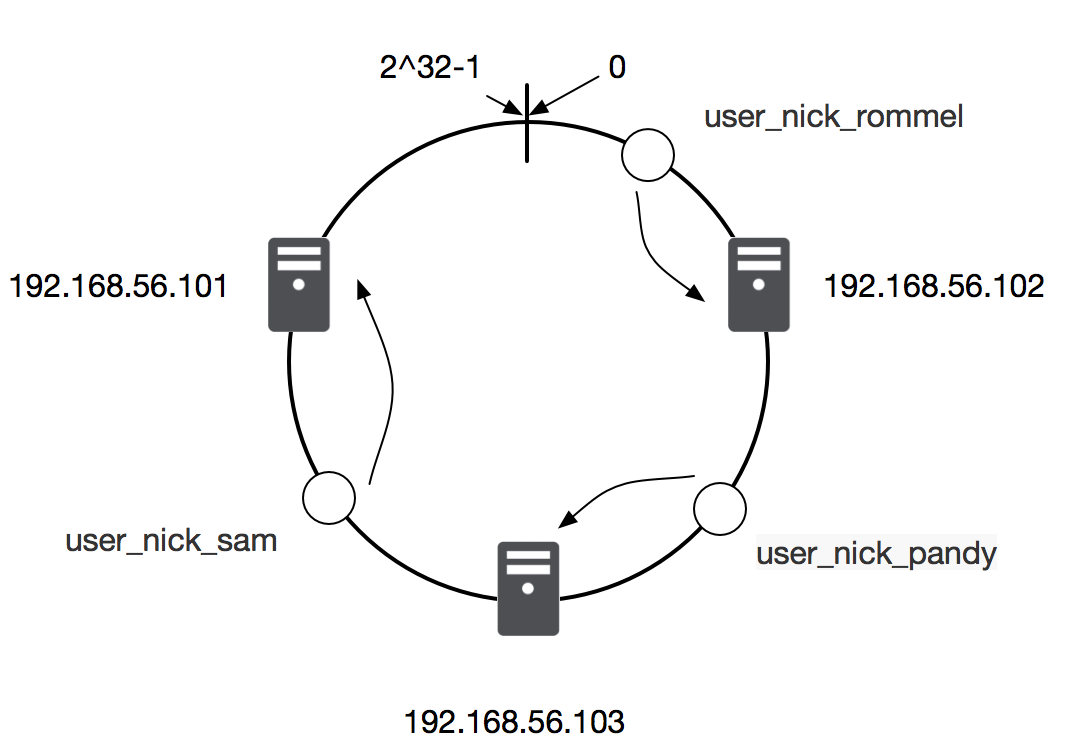
然后使用同样的哈希算法将缓存服务节点(通常通过服务器IP+端口作为节点的key)和数据键映射到环上的位置。再决定数据落在那台服务器上时,使用一致的方向(比如顺时针方向)沿环查找,遇到的第一个有效服务器就是缓存保存的地方,如图:
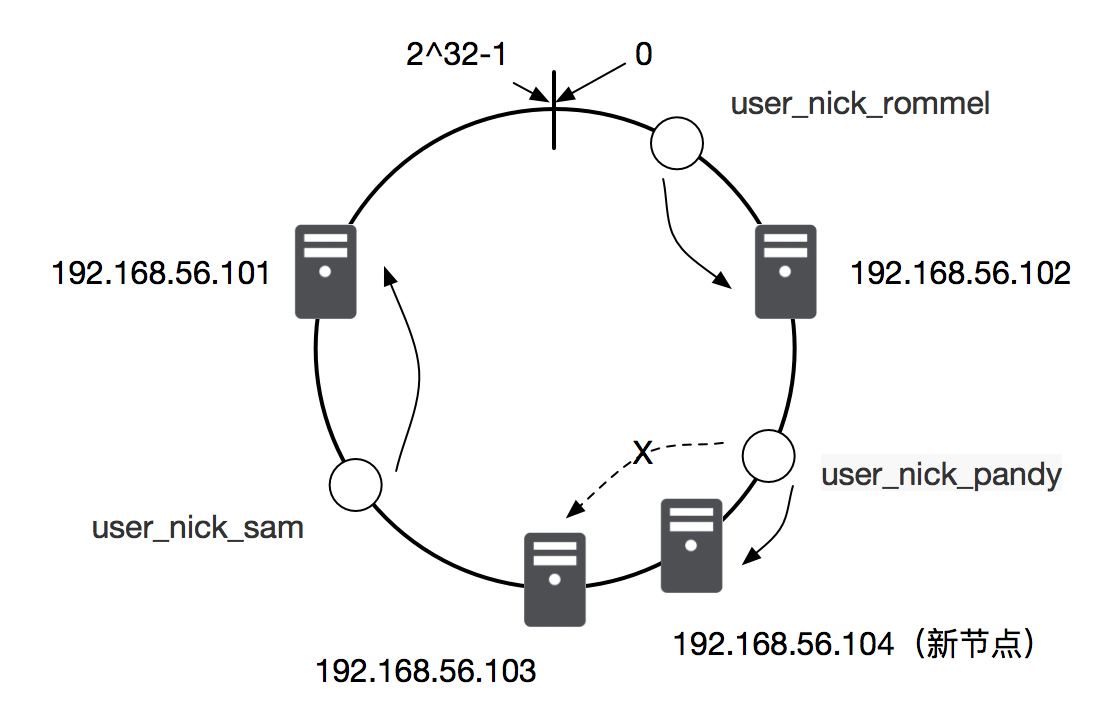
当有新的服务器节点加入时,按照同样的哈希算法将新节点映射到环上的某处位置,和新节点相邻的数据逆时针节点会进行迁移,其他节点保持不变。如下图,当新加入一台新服务器 192.168.56.104 时,user_nick_pandy 这条缓存数据的请求根据算法会落在192.168.56.104 这台及其上,其他节点不受任何影响。
另外,由于哈希计算的记过通常都比较随机,如果缓存服务器比较少的话,可能会出现数据分配冷热不均的问题,如下图所示,大部分数据都会存储在 node3 节点上。
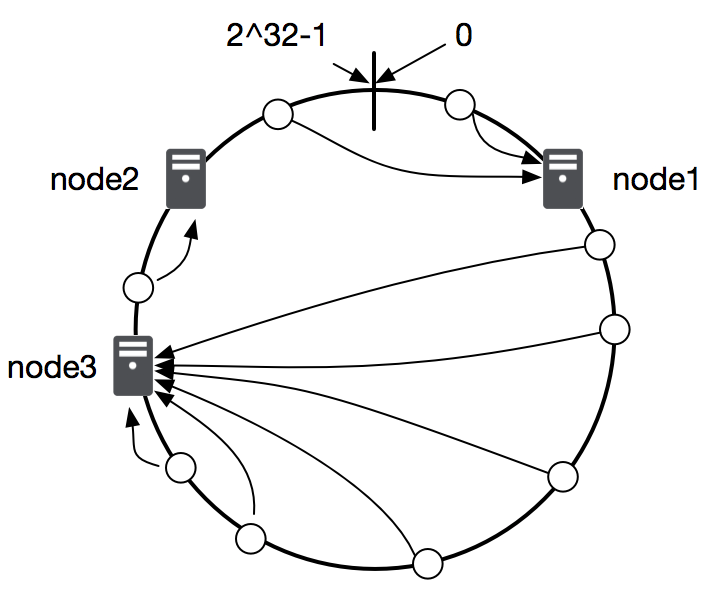
为了解决这个问题,我们引入虚拟节点的概念,在实体服务器不增加的情况下,用多个虚拟节点替代原来的单个实体节点,一台服务服务器在环上就对应多个位置,这样可以让数据存储更加均匀,各服务器的负载页更加平衡,如图:

使用 Java 代码实现一致性哈希的例子如下:
import java.util.SortedMap;import java.util.TreeMap;import org.apache.commons.codec.digest.DigestUtils;public class ConsistentHashingTest {// 真实缓存地址private final String[] cacheServers = { "192.168.56.101:11211", "192.168.56.102:11211", "192.168.56.103:11211" };// 保存虚拟节点private final SortedMap<Long, String> nodes = new TreeMap<Long, String>();// 每个虚拟节点的数量private final int VIRTUAL_NODE_NUM = 3;public ConsistentHashingTest(){//初始化for(String eachServer : cacheServers) {this.addNode(eachServer);}}// 创建虚拟节点public void addNode(String nodeKey) {//为每一个实体节点创建3个虚拟节点for (int i = 0; i < VIRTUAL_NODE_NUM; i++) {long eachHashCode = this.hash(nodeKey + ":" + i);nodes.put(eachHashCode, nodeKey);}}// hash 函数 可以使用 md5, sha-1, sha-256 等// 虽然 md5, sha-1 哈希算法在签名领域已经不再安全,但运算速度比较快,在非安全领域是可以使用的。// DigestUtils 是来自于 apache 中的 org.apache.commons.codec.digest 中的工具类private long hash(String key) {Stringmd5key = DigestUtils.md5Hex(key);return Long.parseLong(md5key.substring(0, 15), 16) % ((long) Math.pow(2, 32));}//按照同一个方向寻找public String getRealServer(String key) {long hashCode = this.hash(key);SortedMap<Long,String> tailMap =nodes.tailMap(hashCode);long serverKey = tailMap.isEmpty() ? nodes.firstKey() : tailMap.firstKey();return nodes.get(serverKey);}public static void main(String[] args) {ConsistentHashingTestt = new ConsistentHashingTest();System.out.println(t.getRealServer("my-cache-key"));}}
另外,前文提到的(TODO 章节)Guava Cache 框架支持一致性哈希,实例代码如下:
//实体缓存服务器String[]cacheServers = { "192.168.56.101:11211", "192.168.56.102:11211", "192.168.56.103:11211" };// 缓存数据的keyString key = "my-test-cache-key";// 计算缓存 key 对应的 hash 值,这里使用 MurmurHash 算法,MurmurHash 是一种高性能低碰撞的算法。此外,还支持 md5、sha1/sha256/sha512、orc32、adler32 等哈希算法。HashCode hashCode = Hashing.murmur3_32().newHasher().putString(key, Charsets.UTF_8).hash();// 通过一致性哈希方式计算,缓存key对应的服务器主机是那一台,bucket 的范围在 0 ~ cacheServers.length -1int bucket = Hashing.consistentHash(hashCode, cacheServers.length);
转载自 https://coderxing.gitbooks.io/architecture-evolution/di-san-pian-ff1a-bu-luo/631-yi-zhi-xing-ha-xi.html
浅谈一致性哈希(My转)的更多相关文章
- 浅谈一致性Hash原理及应用
在讲一致性Hash之前我们先来讨论一个问题. 问题:现在有亿级用户,每日产生千万级订单,如何将订单进行分片分表? 小A:我们可以按照手机号的尾数进行分片,同一个尾数的手机号写入同一片/同一表中. 大佬 ...
- 浅谈一致性hash
相信做过互联网应用的都知道,如何很好的做到横向扩展,其实是个蛮难的话题,缓存可横向扩展,如果采用简单的取模,余数方式的部署,基本是无法做到后期的扩展的,数据迁移及分布都是问题,举个例子: 假设采用取模 ...
- 浅谈字符串哈希 By cellur925
前言 蒟蒻最近在复习字符串算法...但正如之前所说,我OI太菜被关起来了,本蒟蒻只能从最简单的哈希入手了TAT.而别的dalao都在学习AC自动机/后缀数组等高到不知哪里去的算法qwq. 基本思想 映 ...
- 一致性哈希算法(Consistent Hashing Algorithm)
一致性哈希算法(Consistent Hashing Algorithm) 浅谈一致性Hash原理及应用 在讲一致性Hash之前我们先来讨论一个问题. 问题:现在有亿级用户,每日产生千万级订单,如 ...
- [转帖]浅谈分布式一致性与CAP/BASE/ACID理论
浅谈分布式一致性与CAP/BASE/ACID理论 https://www.cnblogs.com/zhang-qc/p/6783657.html ##转载请注明 CAP理论(98年秋提出,99年正式发 ...
- 【架构】浅谈web网站架构演变过程
浅谈web网站架构演变过程 前言 我们以javaweb为例,来搭建一个简单的电商系统,看看这个系统可以如何一步步演变. 该系统具备的功能: 用户模块:用户注册和管理 商品模块:商品展示和管 ...
- 【转】浅谈Java中的hashcode方法(这个demo可以多看看)
浅谈Java中的hashcode方法 哈希表这个数据结构想必大多数人都不陌生,而且在很多地方都会利用到hash表来提高查找效率.在Java的Object类中有一个方法: public native i ...
- 【转】浅谈Java中的hashcode方法
哈希表这个数据结构想必大多数人都不陌生,而且在很多地方都会利用到hash表来提高查找效率.在Java的Object类中有一个方法: public native int hashCode(); 根据这个 ...
- 铁乐学Python_day07_集合and浅谈深浅copy
1.[List补充] 在循环一个列表时,最好不要使用元素和索引进行删除操作,一旦删除,索引会随之改变,容易出错. 如果想不出错,可以采用倒着删除的方法,因为倒着删除进行的话,只是后面元素的位置发生了变 ...
随机推荐
- jQuery基础笔记(1)
day54 参考:https://www.cnblogs.com/liwenzhou/p/8178806.html 1. 为什么要学jQuery? MySQL Python ...
- 关于Kafka部署优化的一点建议
网络和IO线程配置优化 配置参数 num.network.threads:Broker处理消息的最大线程数 num.io.threads:Broker处理磁盘IO的线程数 优化建议 一般num.net ...
- 六:MyBatis学习总结(六)——调用存储过程
一.提出需求 查询得到男性或女性的数量, 如果传入的是0就女性否则是男性 二.准备数据库表和存储过程 create table p_user( id int primary key auto_incr ...
- C#之初识单例模式
当我们使用QQ的时候就会发现,他可以启动多个QQ,但是有时候,我们不想这样做,这时候我们就需要使用到单例模式. 1.将Form2的构造函数转为私有 using System.Windows.Forms ...
- Web应用三种部署方式的优缺点
方式一:修改server.xml文件 优点: 配置速度快,只需要在server.xml文件中添加<Context>标签,在其中分别配置path虚拟路径和docBase真实路径然后启动Tom ...
- 【xsy3423】党² 线段树+李超线段树or动态半平面交
本来并不打算出原创题的,此题集CF542A和sk的灵感而成,算个半原创吧. 题目大意: 给定有$n$个元素的集合$P$,其中第$i$个元素中包含$L_i,R_i,V_i$三个值. 给定另一个有$n$个 ...
- 【BZOJ3143】【HNOI2013】游走 高斯消元
题目传送门:http://www.lydsy.com/JudgeOnline/problem.php?id=3143 我们令$P_i$表示从第i号点出发的期望次数.则$P_n$显然为$0$. 对于$P ...
- iOS设置圆角的三种方式
第一种方法:通过设置layer的属性 最简单的一种,但是很影响性能,一般在正常的开发中使用很少. ? 1 2 3 4 5 6 7 UIImageView *imageView = [[UIImageV ...
- To be learned
1.web性能测试工具:LoadRunner:2.web自动化测试工具:selenium QTP:3.安全性测试工具:AppScan4.缺陷管理工具:TestLink+Mantisbt5..抓包工具: ...
- HashMap、HashSet、LinkedHashSet、TreeSet的关系
类图及说明如下: