PriorityQueue源码分析
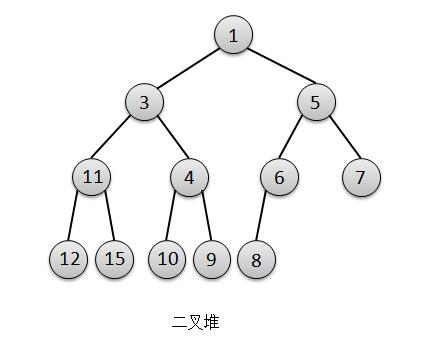
(2)堆总是一棵完全树。
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {
1 // 默认初始化大小
2 privatestaticfinalintDEFAULT_INITIAL_CAPACITY = 11;
3
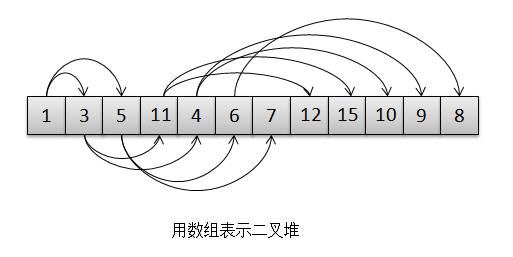
4 // 用数组实现的二叉堆,下面的英文注释确认了我们前面的说法。
5 /**
6 * Priority queue represented as a balanced binary heap: the two
7 * children of queue[n] are queue[2*n+1] and queue[2*(n+1)]. The
8 * priority queue is ordered by comparator, or by the elements'
9 * natural ordering, if comparator is null: For each node n in the
10 * heap and each descendant d of n, n <= d. The element with the
11 * lowest value is in queue[0], assuming the queue is nonempty.
12 */
13 private transient Object[] queue ;
14
15 // 队列的元素数量
16 private int size = 0;
17
18 // 比较器
19 private final Comparator<? super E> comparator;
20
21 // 修改版本
22 private transient int modCount = 0;
1 /**
2 * 默认构造方法,使用默认的初始大小来构造一个优先队列,比较器comparator为空,这里要求入队的元素必须实现Comparator接口
3 */
4 public PriorityQueue() {
5 this(DEFAULT_INITIAL_CAPACITY, null);
6 }
7
8 /**
9 * 使用指定的初始大小来构造一个优先队列,比较器comparator为空,这里要求入队的元素必须实现Comparator接口
10 */
11 public PriorityQueue( int initialCapacity) {
12 this(initialCapacity, null);
13 }
14
15 /**
16 * 使用指定的初始大小和比较器来构造一个优先队列
17 */
18 public PriorityQueue( int initialCapacity,
19 Comparator<? super E> comparator) {
20 // Note: This restriction of at least one is not actually needed,
21 // but continues for 1.5 compatibility
22 // 初始大小不允许小于1
23 if (initialCapacity < 1)
24 throw new IllegalArgumentException();
25 // 使用指定初始大小创建数组
26 this.queue = new Object[initialCapacity];
27 // 初始化比较器
28 this.comparator = comparator;
29 }
30
31 /**
32 * 构造一个指定Collection集合参数的优先队列
33 */
34 public PriorityQueue(Collection<? extends E> c) {
35 // 从集合c中初始化数据到队列
36 initFromCollection(c);
37 // 如果集合c是包含比较器Comparator的(SortedSet/PriorityQueue),则使用集合c的比较器来初始化队列的Comparator
38 if (c instanceof SortedSet)
39 comparator = (Comparator<? super E>)
40 ((SortedSet<? extends E>)c).comparator();
41 else if (c instanceof PriorityQueue)
42 comparator = (Comparator<? super E>)
43 ((PriorityQueue<? extends E>)c).comparator();
44 // 如果集合c没有包含比较器,则默认比较器Comparator为空
45 else {
46 comparator = null;
47 // 调用heapify方法重新将数据调整为一个二叉堆
48 heapify();
49 }
50 }
51
52 /**
53 * 构造一个指定PriorityQueue参数的优先队列
54 */
55 public PriorityQueue(PriorityQueue<? extends E> c) {
56 comparator = (Comparator<? super E>)c.comparator();
57 initFromCollection(c);
58 }
59
60 /**
61 * 构造一个指定SortedSet参数的优先队列
62 */
63 public PriorityQueue(SortedSet<? extends E> c) {
64 comparator = (Comparator<? super E>)c.comparator();
65 initFromCollection(c);
66 }
67
68 /**
69 * 从集合中初始化数据到队列
70 */
71 private void initFromCollection(Collection<? extends E> c) {
72 // 将集合Collection转换为数组a
73 Object[] a = c.toArray();
74 // If c.toArray incorrectly doesn't return Object[], copy it.
75 // 如果转换后的数组a类型不是Object数组,则转换为Object数组
76 if (a.getClass() != Object[].class)
77 a = Arrays. copyOf(a, a.length, Object[]. class);
78 // 将数组a赋值给队列的底层数组queue
79 queue = a;
80 // 将队列的元素个数设置为数组a的长度
81 size = a.length ;
82 }
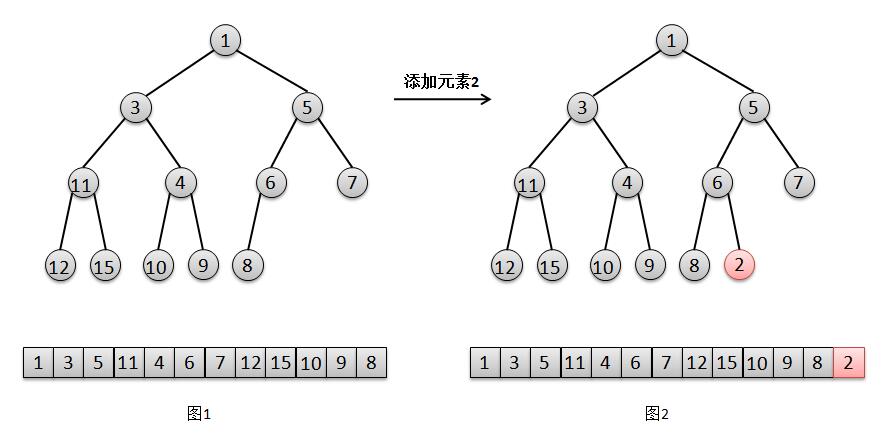
1 /**
2 * 添加一个元素
3 */
4 public boolean add(E e) {
5 return offer(e);
6 }
7
8 /**
9 * 入队
10 */
11 public boolean offer(E e) {
12 // 如果元素e为空,则排除空指针异常
13 if (e == null)
14 throw new NullPointerException();
15 // 修改版本+1
16 modCount++;
17 // 记录当前队列中元素的个数
18 int i = size ;
19 // 如果当前元素个数大于等于队列底层数组的长度,则进行扩容
20 if (i >= queue .length)
21 grow(i + 1);
22 // 元素个数+1
23 size = i + 1;
24 // 如果队列中没有元素,则将元素e直接添加至根(数组小标0的位置)
25 if (i == 0)
26 queue[0] = e;
27 // 否则调用siftUp方法,将元素添加到尾部,进行上移判断
28 else
29 siftUp(i, e);
30 return true;
31 }
1 /**
2 * 数组扩容
3 */
4 private void grow(int minCapacity) {
5 // 如果最小需要的容量大小minCapacity小于0,则说明此时已经超出int的范围,则抛出OutOfMemoryError异常
6 if (minCapacity < 0) // overflow
7 throw new OutOfMemoryError();
8 // 记录当前队列的长度
9 int oldCapacity = queue .length;
10 // Double size if small; else grow by 50%
11 // 如果当前队列长度小于64则扩容2倍,否则扩容1.5倍
12 int newCapacity = ((oldCapacity < 64)?
13 ((oldCapacity + 1) * 2):
14 ((oldCapacity / 2) * 3));
15 // 如果扩容后newCapacity超出int的范围,则将newCapacity赋值为Integer.Max_VALUE
16 if (newCapacity < 0) // overflow
17 newCapacity = Integer. MAX_VALUE;
18 // 如果扩容后,newCapacity小于最小需要的容量大小minCapacity,则按找minCapacity长度进行扩容
19 if (newCapacity < minCapacity)
20 newCapacity = minCapacity;
21 // 数组copy,进行扩容
22 queue = Arrays.copyOf( queue, newCapacity);
23 }
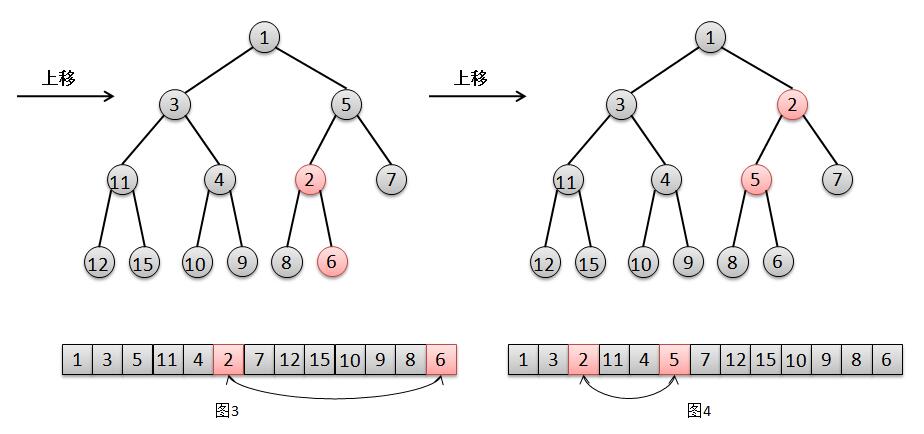
1 /**
2 * 上移,x表示新插入元素,k表示新插入元素在数组的位置
3 */
4 private void siftUp(int k, E x) {
5 // 如果比较器comparator不为空,则调用siftUpUsingComparator方法进行上移操作
6 if (comparator != null)
7 siftUpUsingComparator(k, x);
8 // 如果比较器comparator为空,则调用siftUpComparable方法进行上移操作
9 else
10 siftUpComparable(k, x);
11 }
12
13 private void siftUpComparable(int k, E x) {
14 // 比较器comparator为空,需要插入的元素实现Comparable接口,用于比较大小
15 Comparable<? super E> key = (Comparable<? super E>) x;
16 // k>0表示判断k不是根的情况下,也就是元素x有父节点
17 while (k > 0) {
18 // 计算元素x的父节点位置[(n-1)/2]
19 int parent = (k - 1) >>> 1;
20 // 取出x的父亲e
21 Object e = queue[parent];
22 // 如果新增的元素k比其父亲e大,则不需要"上移",跳出循环结束
23 if (key.compareTo((E) e) >= 0)
24 break;
25 // x比父亲小,则需要进行"上移"
26 // 交换元素x和父亲e的位置
27 queue[k] = e;
28 // 将新插入元素的位置k指向父亲的位置,进行下一层循环
29 k = parent;
30 }
31 // 找到新增元素x的合适位置k之后进行赋值
32 queue[k] = key;
33 }
34
35 // 这个方法和上面的操作一样,不多说了
36 private void siftUpUsingComparator(int k, E x) {
37 while (k > 0) {
38 int parent = (k - 1) >>> 1;
39 Object e = queue[parent];
40 if (comparator .compare(x, (E) e) >= 0)
41 break;
42 queue[k] = e;
43 k = parent;
44 }
45 queue[k] = x;
46 }
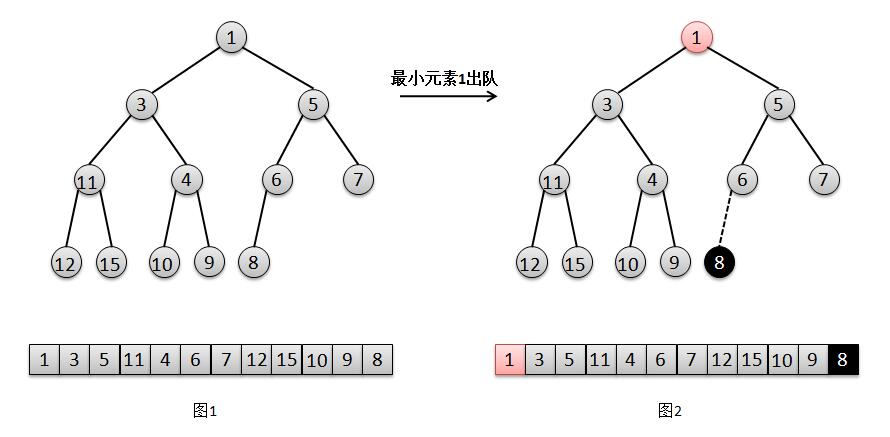

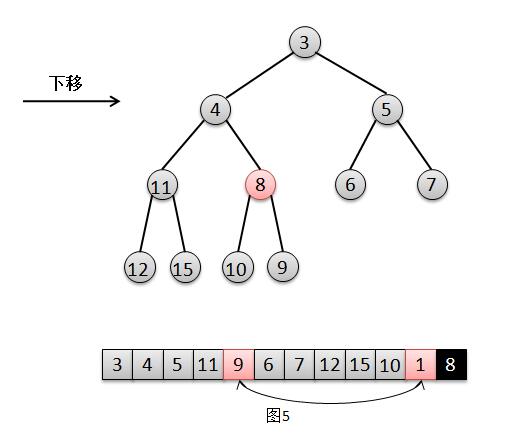
1 /**
2 * 删除并返回队头的元素,如果队列为空则抛出NoSuchElementException异常(该方法在AbstractQueue中)
3 */
4 public E remove() {
5 E x = poll();
6 if (x != null)
7 return x;
8 else
9 throw new NoSuchElementException();
10 }
11
12 /**
13 * 删除并返回队头的元素,如果队列为空则返回null
14 */
15 public E poll() {
16 // 队列为空,返回null
17 if (size == 0)
18 return null;
19 // 队列元素个数-1
20 int s = --size ;
21 // 修改版本+1
22 modCount++;
23 // 队头的元素
24 E result = (E) queue[0];
25 // 队尾的元素
26 E x = (E) queue[s];
27 // 先将队尾赋值为null
28 queue[s] = null;
29 // 如果队列中不止队尾一个元素,则调用siftDown方法进行"下移"操作
30 if (s != 0)
31 siftDown(0, x);
32 return result;
33 }
34
35 /**
36 * 上移,x表示队尾的元素,k表示被删除元素在数组的位置
37 */
38 private void siftDown(int k, E x) {
39 // 如果比较器comparator不为空,则调用siftDownUsingComparator方法进行下移操作
40 if (comparator != null)
41 siftDownUsingComparator(k, x);
42 // 比较器comparator为空,则调用siftDownComparable方法进行下移操作
43 else
44 siftDownComparable(k, x);
45 }
46
47 private void siftDownComparable(int k, E x) {
48 // 比较器comparator为空,需要插入的元素实现Comparable接口,用于比较大小
49 Comparable<? super E> key = (Comparable<? super E>)x;
50 // 通过size/2找到一个没有叶子节点的元素
51 int half = size >>> 1; // loop while a non-leaf
52 // 比较位置k和half,如果k小于half,则k位置的元素就不是叶子节点
53 while (k < half) {
54 // 找到根元素的左孩子的位置[2n+1]
55 int child = (k << 1) + 1; // assume left child is least
56 // 左孩子的元素
57 Object c = queue[child];
58 // 找到根元素的右孩子的位置[2(n+1)]
59 int right = child + 1;
60 // 如果左孩子大于右孩子,则将c复制为右孩子的值,这里也就是找出左右孩子哪个最小
61 if (right < size &&
62 ((Comparable<? super E>) c).compareTo((E) queue [right]) > 0)
63 c = queue[child = right];
64 // 如果队尾元素比根元素孩子都要小,则不需"下移",结束
65 if (key.compareTo((E) c) <= 0)
66 break;
67 // 队尾元素比根元素孩子都大,则需要"下移"
68 // 交换跟元素和孩子c的位置
69 queue[k] = c;
70 // 将根元素位置k指向最小孩子的位置,进入下层循环
71 k = child;
72 }
73 // 找到队尾元素x的合适位置k之后进行赋值
74 queue[k] = key;
75 }
76
77 // 这个方法和上面的操作一样,不多说了
78 private void siftDownUsingComparator(int k, E x) {
79 int half = size >>> 1;
80 while (k < half) {
81 int child = (k << 1) + 1;
82 Object c = queue[child];
83 int right = child + 1;
84 if (right < size &&
85 comparator.compare((E) c, (E) queue [right]) > 0)
86 c = queue[child = right];
87 if (comparator .compare(x, (E) c) <= 0)
88 break;
89 queue[k] = c;
90 k = child;
91 }
92 queue[k] = x;
93 }
1 /**
2 * Establishes the heap invariant (described above) in the entire tree,
3 * assuming nothing about the order of the elements prior to the call.
4 */
5 private void heapify() {
6 for (int i = (size >>> 1) - 1; i >= 0; i--)
7 siftDown(i, (E) queue[i]);
8 }
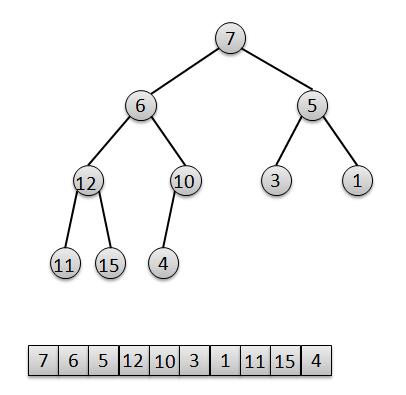
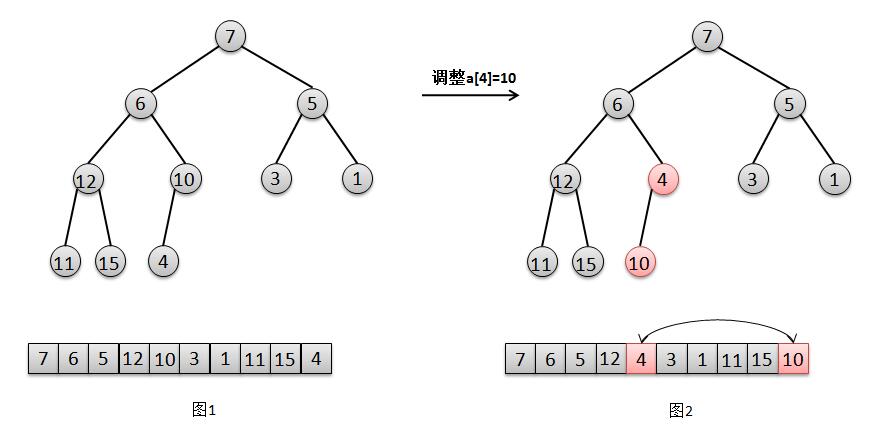
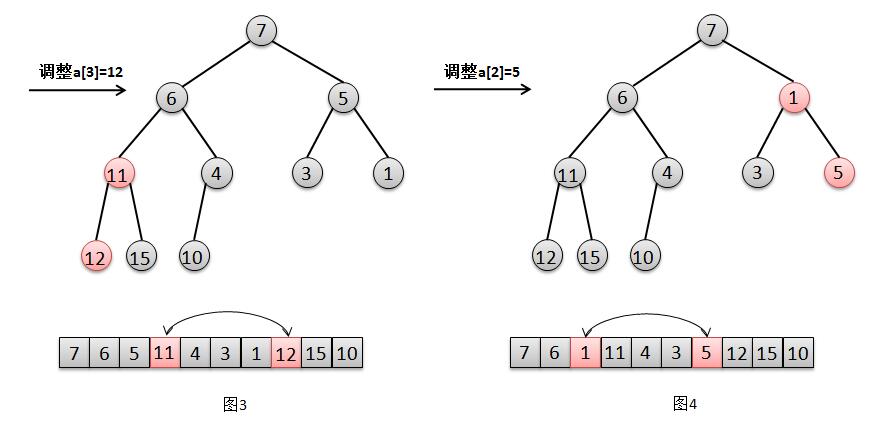
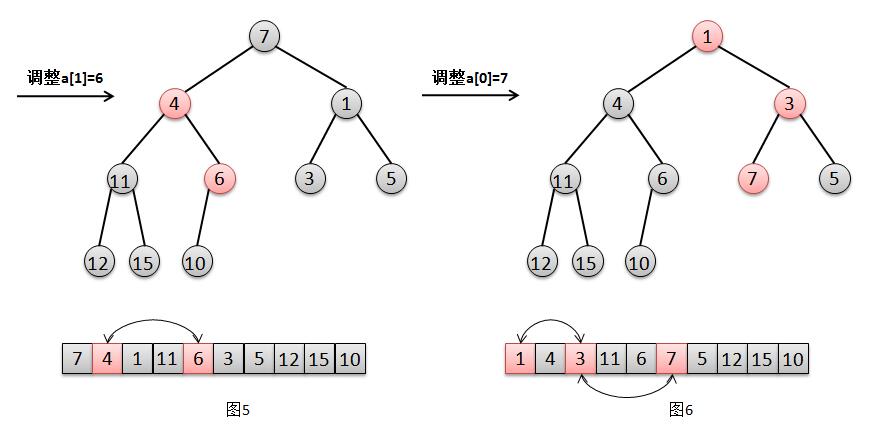
1 private void heapify() {
2 for (int i = (size >>> 1) - 1; i >= 0; i--)
3 siftDown(i, (E) queue[i]);
4 }
PriorityQueue源码分析的更多相关文章
- 死磕 java集合之PriorityQueue源码分析
问题 (1)什么是优先级队列? (2)怎么实现一个优先级队列? (3)PriorityQueue是线程安全的吗? (4)PriorityQueue就有序的吗? 简介 优先级队列,是0个或多个元素的集合 ...
- PriorityQueue 源码分析
public boolean hasNext() { return cursor < size || (forgetMeNot != null && !forgetMeNot.i ...
- 死磕 java集合之DelayQueue源码分析
问题 (1)DelayQueue是阻塞队列吗? (2)DelayQueue的实现方式? (3)DelayQueue主要用于什么场景? 简介 DelayQueue是java并发包下的延时阻塞队列,常用于 ...
- 死磕 java集合之PriorityBlockingQueue源码分析
问题 (1)PriorityBlockingQueue的实现方式? (2)PriorityBlockingQueue是否需要扩容? (3)PriorityBlockingQueue是怎么控制并发安全的 ...
- java读源码 之 queue源码分析(PriorityQueue,附图)
今天要介绍的是基础容器类(为了与并发容器类区分开来而命名的名字)中的另一个成员--PriorityQueue,它的大名叫做优先级队列,想必即使没有用过也该有所耳闻吧,什么?没..没听过?emmm... ...
- 介绍开源的.net通信框架NetworkComms框架 源码分析
原文网址: http://www.cnblogs.com/csdev Networkcomms 是一款C# 语言编写的TCP/UDP通信框架 作者是英国人 以前是收费的 售价249英镑 我曾经花了 ...
- Mahout源码分析:并行化FP-Growth算法
FP-Growth是一种常被用来进行关联分析,挖掘频繁项的算法.与Aprior算法相比,FP-Growth算法采用前缀树的形式来表征数据,减少了扫描事务数据库的次数,通过递归地生成条件FP-tree来 ...
- 细说并发5:Java 阻塞队列源码分析(下)
上一篇 细说并发4:Java 阻塞队列源码分析(上) 我们了解了 ArrayBlockingQueue, LinkedBlockingQueue 和 PriorityBlockingQueue,这篇文 ...
- HDFS源码分析EditLog之获取编辑日志输入流
在<HDFS源码分析之EditLogTailer>一文中,我们详细了解了编辑日志跟踪器EditLogTailer的实现,介绍了其内部编辑日志追踪线程EditLogTailerThread的 ...
随机推荐
- 迷你MVVM框架 avalonjs 1.3.7发布
又到每个月的15号了,现在avalon已经固定在每个月的15号发布新版本.这次发布又带来许多新特性,让大家写码更加轻松,借助于"操作数据即操作DOM"的核心理念与双向绑定机制,现在 ...
- maven tomcat7 远程热部署
在maven项目开发中,一般推荐使用jetty进行开发调试.但是在项目发布的时候要求使用tomcat7作为发布服务器,为此在maven中配置了tomcat7插件,以支持项目在外部tomcat7进行远程 ...
- mogodb查询
Find: {$and: [ {"MethodName":"CommLogin"} ,{"CreateTime":{$gte:"2 ...
- golang interface接口
package main import "fmt" type Shaper interface { Area() float32 } type Square struct { si ...
- spine
spine 英 [spʌɪn] 美 [spaɪn] n.脊柱;[动,植] 棘,刺(如刺猬和海胆的刺);鱼鳍的刺;植物上的刺
- Distributing Ballot Boxes
Distributing Ballot Boxes http://acm.hdu.edu.cn/showproblem.php?pid=4190 Time Limit: 20000/10000 MS ...
- 未能加载文件或程序集“AjaxControlToolkit”或它的某一个依赖项
对于这个问题,网上的解答都大同小异,最多的就是Bin文件夹下没有dll文件,引用路径问题.但我碰到的问题偏偏不是这个,而是没有一个人给出方法的问题.其实问题很简单,也很低级:IIS上发布网站的时候把整 ...
- 9-centos定时任务-不起作用- 没指明路径!!!
crond 是linux下用来周期性的执行某种任务或等待处理某些事件的一个守护进程,与windows下的计划任务类似,当安装完成操作系统后,默认会安装此服务 工具,并且会自动启动crond进程,cro ...
- 解决Pycharm添加虚拟解释器的报错问题
问题背景: 新添加一个virtualenv环境时,需要安装指定的django==1.9.8,但是在添加解释器时,总报一个fuck egg的问题!! 解决方式如下: 1. 2. 3.搞定
- linux下iptables防火墙设置
各位linux的爱好者或者工作跟linux相关的程序员,我们在工作中经常遇到应用服务器端口已经启动, 在网络正常的情况下,访问不到应用程序,这个跟防火墙设置有关 操作步骤 1.检查有没有启动防火墙 s ...