大数据中Linux集群搭建与配置
因测试需要,一共安装4台linux系统,在windows上用vm搭建。
对应4个IP为192.168.1.60、61、62、63,这里记录其中一台的搭建过程,其余的可以直接复制虚拟机,并修改相关配置即可。
软件版本选择:
虚拟机:VMware Workstation 12 Pro 版本:12.5.9 build-7535481
Linux:CentOS-7-x86_64-DVD-1804
FTP工具:FileZilla-3.37.4
安装CentOS虚拟机
首先安装虚拟机,成功后重启电脑
新建虚拟机, 配置直接用推荐的经典
选择CentOS的IOS光盘映像
剩下用默认设置,20G硬盘,1G内存,1核CPU
等待加载虚拟机,安装Linxu
语言选择中文
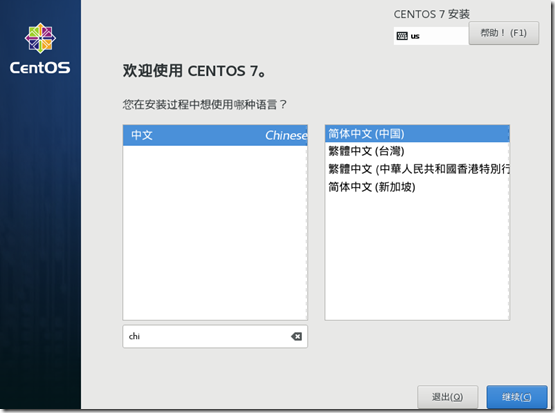
系统安装位置需要进入一次,可以自己分区,不过这里是测试,默认一个区,点击完成
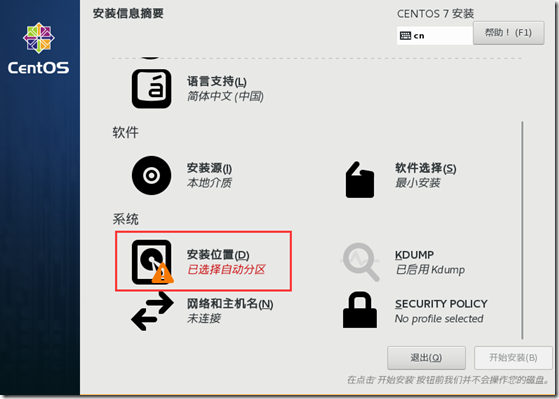
打开自动获取IP
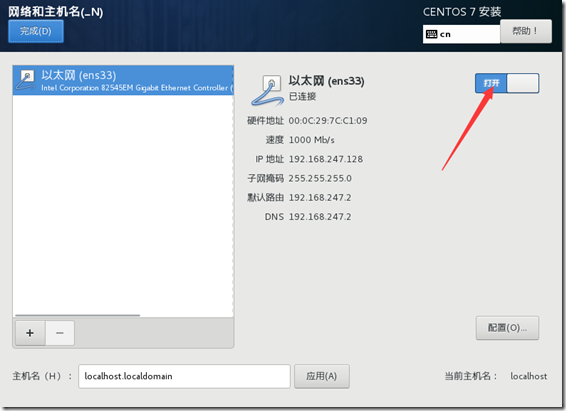
可以在软件选择中指定默认要安装的内容,不过这里因测试,且知道具体安装了什么软件,我这里选择最小安装
设置root账号的密码,输入完毕点击两次完成键,完成配置开始安装,安装完毕重置
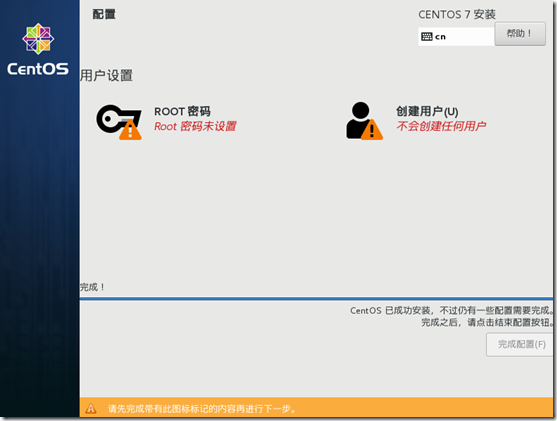
配置Linux环境
输入用户名root,输入密码,登录系统
vm上右键虚拟机,设置,修改网络适配器从NAT模式改为桥接模式
安装网络工具,用于配置IP,若报错无法访问,可能是windows服务没启动,启用VMware DHCP Service,VMware NAT Service两个服务
yum install net-tools -y
配置静态IP,最后ens33根据各自具体网卡名字来设置
vi /etc/sysconfig/network-scripts/ifcfg-ens33
按i切换到INSERT模式,修改配置文件如下,将BOOTPROTO的值从dhcp改为static,并且增加ip配置,修改完毕按esc,输入:wq保存退出
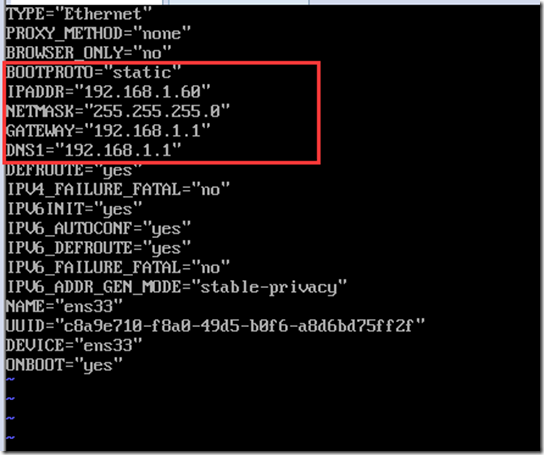
启用配置,重启网络服务
systemctl restart network
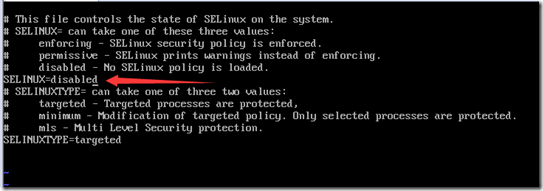
关闭selinux,打开selinux配置文件
vi /etc/selinux/config
修改SELINUX的值为disabled
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
安装vsftp用于上传各种文件
yum install vsftpd –y
启用ftp并添加ftp用户
systemctl enable vsftpd
systemctl start vsftpd
useradd ftpuser -s /sbin/nologin
passwd ftpuser
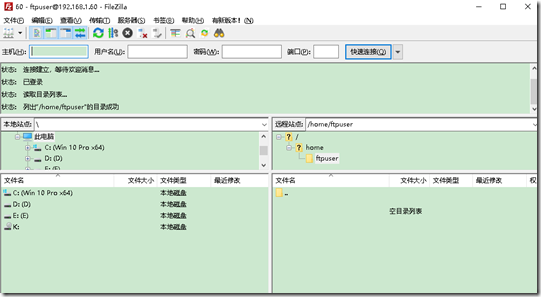
用FileZilla连接,使用普通FTP连接,输入刚创建的ftp用户名密码
配置ssh免密登录
ssh-keygen -t rsa -P ""
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
chmod 0600 authorized_keys
ssh localhost #首次需输入yes,退出登录logoutlogout至此Linux基础环境搭建完毕。
大数据中Linux集群搭建与配置的更多相关文章
- 大数据中Hadoop集群搭建与配置
前提环境是之前搭建的4台Linux虚拟机,详情参见 Linux集群搭建 该环境对应4台服务器,192.168.1.60.61.62.63,其中60为主机,其余为从机 软件版本选择: Java:JDK1 ...
- 大数据中HBase集群搭建与配置
hbase是分布式列式存储数据库,前提条件是需要搭建hadoop集群,需要Zookeeper集群提供znode锁机制,hadoop集群已经搭建,参考 Hadoop集群搭建 ,该文主要介绍Zookeep ...
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据平台Hadoop集群搭建
一.概念 Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce.HDFS是一个分布式文件系统,类似mogilef ...
- 大数据-HBase HA集群搭建
1.下载对应版本的Hbase,在我们搭建的集群环境中选用的是hbase-1.4.6 将下载完成的hbase压缩包放到对应的目录下,此处我们的目录为/opt/workspace/ 2.对已经有的压缩包进 ...
- 大数据:spark集群搭建
创建spark用户组,组ID1000 groupadd -g 1000 spark 在spark用户组下创建用户ID 2000的spark用户 获取视频中文档资料及完整视频的伙伴请加QQ群:9479 ...
- 大数据学习——Storm集群搭建
安装storm之前要安装zookeeper 一.安装storm步骤 1.下载安装包 2.解压安装包 .tar.gz storm 3.修改配置文件 mv /root/apps/storm/conf/st ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据-spark HA集群搭建
一.安装scala 我们安装的是scala-2.11.8 5台机器全部安装 下载需要的安装包,放到特定的目录下/opt/workspace/并进行解压 1.解压缩 [root@master1 ~]# ...
随机推荐
- 【Excel】坐下,VLOOKUP基本操作
坐下,VLOOKUP基本操作 VLOOKUP如何使用我就不在这里详细介绍了,简单说一下好了. 如上图,第一个填写你要查找的值,第二个空选取你查找的范围,第三个空填你要得到第几列的值,最后选 ...
- .net mvc HTTP 错误 403.14 - Forbidden Web 服务器被配置为不列出此目录的内容
1. 检查服务器上是否安装了“HTTP重定向”功能和“静态内容压缩”功能(在添加/删除程序或增加角色处安装).这是我所遇到的问题: 2. 应用程序池要被配置为“集成” 3. 把.net 4.0安装在i ...
- Sharepoint 2013 多服务器域的目录服务器和搜索服务的配置
一般而言,大部分的sharepoint的管理工作均可以通过Centrlal Admin完成,可惜这个操作不得不要用powershell. 假如Webfront服务器叫 WebServer 目录服务器叫 ...
- Hibernate入门步骤及概念
1.什么是Hibernate Hibernate是一个开发源代码的对象关系映射框架,它对JDBC进行非常轻量级的对象封装,使得程序员可以随心所欲地使用对象编程思维来操纵数据库.Hibernate可以应 ...
- swoole_table测试
public function test() { $count = []; $count[] = ['key' => 'name', 'type' => ...
- SSM框架之关于使用JSP作为视图展示问题解决方案
JSP作为视图层展示数据,已经有很长一段时间了,不管是在校学习还是企业工作,总会或多或少接触这个.特别是对于一些传统中小型或者一些几年前的企业而言,有很多使用JSP作为视图展示层. JSP本质是就是S ...
- 集合之HashTable
在java中与有两个类都提供了一个多种用途的hashTable机制,他们都可以将可以key和value结合起来构成键值对通过put(key,value)方法保存起来,然后通过get(key)方法获取相 ...
- 【转】Python数据处理(四舍五入、除法部分)
转自:https://www.cnblogs.com/junyiningyuan/p/5338378.html 关于除法 传统除法 对两个整数进行除的运算,同时结果会舍去小数部分,返回一个整数.但如果 ...
- TensorFlow Activation Function 1
部分转自:https://blog.csdn.net/caicaiatnbu/article/details/72745156 激活函数(Activation Function)运行时激活神经网络中某 ...
- 机器学习中的特征缩放(feature scaling)
参考:https://blog.csdn.net/iterate7/article/details/78881562 在运用一些机器学习算法的时候不可避免地要对数据进行特征缩放(feature sca ...