机器学习--集成学习(Ensemble Learning)
一、集成学习法
在机器学习的有监督学习算法中,我们的目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到多个有偏好的模型(弱监督模型,在某些方面表现的比较好)。集成学习就是组合这里的多个弱监督模型以期得到一个更好更全面的强监督模型,集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。
集成方法是将几种机器学习技术组合成一个预测模型的元算法,以达到减小方差(bagging)、偏差(boosting)或改进预测(stacking)的效果。
集成学习在各个规模的数据集上都有很好的策略。
数据集大:划分成多个小数据集,学习多个模型进行组合
数据集小:利用Bootstrap方法进行抽样,得到多个数据集,分别训练多个模型再进行组合
集合方法可分为两类:
- 序列集成方法,其中参与训练的基础学习器按照顺序生成(例如 AdaBoost)。序列方法的原理是利用基础学习器之间的依赖关系。通过对之前训练中错误标记的样本赋值较高的权重,可以提高整体的预测效果。
- 并行集成方法,其中参与训练的基础学习器并行生成(例如 Random Forest)。并行方法的原理是利用基础学习器之间的独立性,通过平均可以显著降低错误。
总结一下,集成学习法的特点:
① 将多个分类方法聚集在一起,以提高分类的准确率。
(这些算法可以是不同的算法,也可以是相同的算法。)
② 集成学习法由训练数据构建一组基分类器,然后通过对每个基分类器的预测进行投票来进行分类
③ 严格来说,集成学习并不算是一种分类器,而是一种分类器结合的方法。
④ 通常一个集成分类器的分类性能会好于单个分类器
⑤ 如果把单个分类器比作一个决策者的话,集成学习的方法就相当于多个决策者共同进行一项决策。
自然地,就产生两个问题:
1)怎么训练每个算法?
2)怎么融合每个算法?
这篇博客介绍一下集成学习的几个方法:Bagging,Boosting以及Stacking。
1、Bagging(bootstrap aggregating,装袋)
Bagging即套袋法,先说一下bootstrap,bootstrap也称为自助法,它是一种有放回的抽样方法,目的为了得到统计量的分布以及置信区间,其算法过程如下:
A)从原始样本集中抽取训练集。每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中)。共进行k轮抽取,得到k个训练集。(k个训练集之间是相互独立的)
B)每次使用一个训练集得到一个模型,k个训练集共得到k个模型。(注:这里并没有具体的分类算法或回归方法,我们可以根据具体问题采用不同的分类或回归方法,如决策树、感知器等)
C)对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。(所有模型的重要性相同)
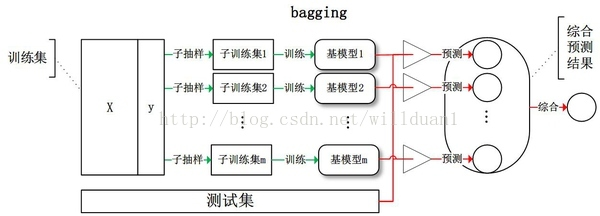
为了让更好地理解bagging方法,这里提供一个例子。
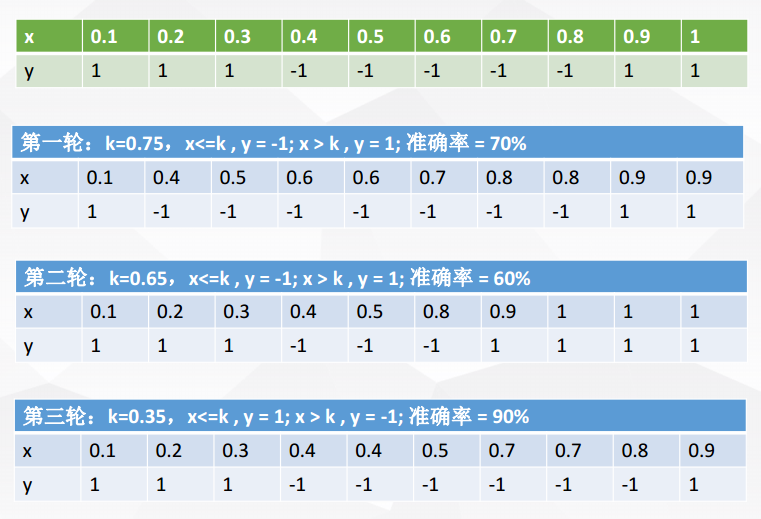
X 表示一维属性,Y 表示类标号(1或-1)测试条件:当x<=k时,y=?;当x>k时,y=?;k为最佳分裂点
下表为属性x对应的唯一正确的y类别
现在进行5轮随机抽样,结果如下
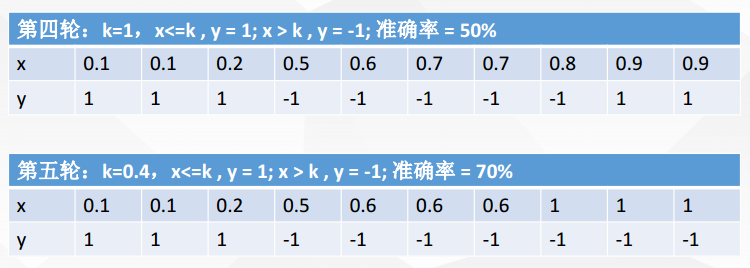
每一轮随机抽样后,都生成一个分类器
然后再将五轮分类融合
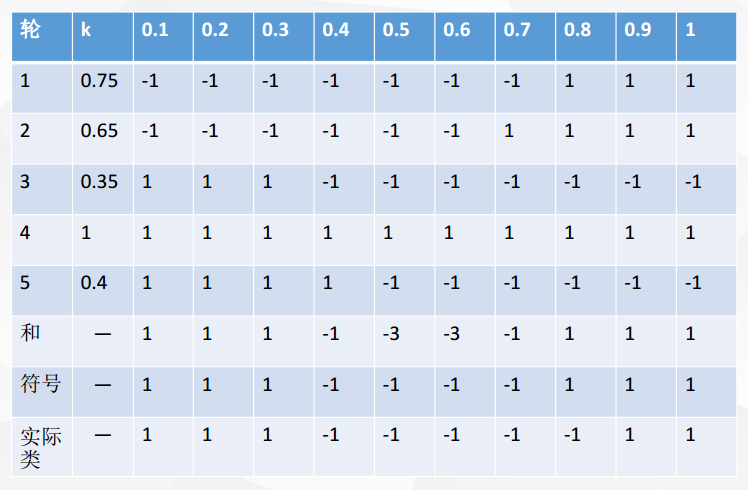
对比符号和实际类,我们可以发现:在该例子中,Bagging使得准确率可达90%
由此,总结一下bagging方法:
① Bagging通过降低基分类器的方差,改善了泛化误差
② 其性能依赖于基分类器的稳定性;如果基分类器不稳定,bagging有助于降低训练数据的随机波动导致的误差;如果稳定,则集成分类器的误差主要由基分类器的偏倚引起
③ 由于每个样本被选中的概率相同,因此bagging并不侧重于训练数据集中的任何特定实例
常用的集成算法类是随机森林。
在随机森林中,集成中的每棵树都是由从训练集中抽取的样本(即 bootstrap 样本)构建的。另外,与使用所有特征不同,这里随机选择特征子集,从而进一步达到对树的随机化目的。
因此,随机森林产生的偏差略有增加,但是由于对相关性较小的树计算平均值,估计方差减小了,导致模型的整体效果更好。

2、Boosting
其主要思想是将弱分类器组装成一个强分类器。在PAC(probably approximately correct,概率近似正确)学习框架下,则一定可以将弱分类器组装成一个强分类器。
关于Boosting的两个核心问题:
1)在每一轮如何改变训练数据的权值或概率分布?
通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样例的权值,来使得分类器对误分的数据有较好的效果。
2)通过什么方式来组合弱分类器?
通过加法模型将弱分类器进行线性组合,比如:
AdaBoost(Adaptive boosting)算法:刚开始训练时对每一个训练例赋相等的权重,然后用该算法对训练集训练t轮,每次训练后,对训练失败的训练例赋以较大的权重,也就是让学习算法在每次学习以后更注意学错的样本,从而得到多个预测函数。通过拟合残差的方式逐步减小残差,将每一步生成的模型叠加得到最终模型。
GBDT(Gradient Boost Decision Tree),每一次的计算是为了减少上一次的残差,GBDT在残差减少(负梯度)的方向上建立一个新的模型。
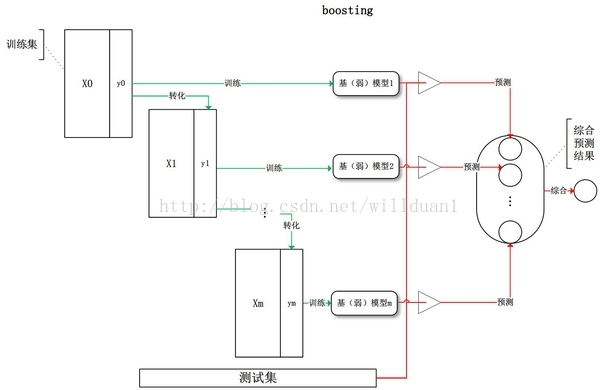
3、Stacking
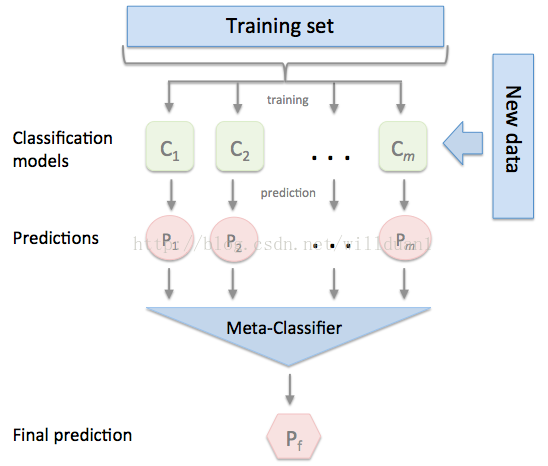
Stacking方法是指训练一个模型用于组合其他各个模型。首先我们先训练多个不同的模型,然后把之前训练的各个模型的输出为输入来训练一个模型,以得到一个最终的输出。理论上,Stacking可以表示上面提到的两种Ensemble方法,只要我们采用合适的模型组合策略即可。但在实际中,我们通常使用logistic回归作为组合策略。
如下图,先在整个训练数据集上通过bootstrap抽样得到各个训练集合,得到一系列分类模型,然后将输出用于训练第二层分类器。
二、Bagging,Boosting二者之间的区别
1、Bagging和Boosting的区别:
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
2、决策树与这些算法框架进行结合所得到的新的算法:
1)Bagging + 决策树 = 随机森林
2)AdaBoost + 决策树 = 提升树
3)Gradient Boosting + 决策树 = GBDT
参考博文:
【1】集成学习总结 & Stacking方法详解 https://blog.csdn.net/willduan1/article/details/73618677
【2】Bagging和Boosting 概念及区别 https://www.cnblogs.com/liuwu265/p/4690486.html
【3】集成学习法之bagging方法和boosting方法 https://blog.csdn.net/qq_30189255/article/details/51532442
【4】机器学习中的集成学习(Ensemble Learning) http://baijiahao.baidu.com/s?id=1590266955499942419&wfr=spider&for=pc
【5】简单易学的机器学习算法——集成方法(Ensemble Method) https://blog.csdn.net/google19890102/article/details/46507387
机器学习--集成学习(Ensemble Learning)的更多相关文章
- 【Supervised Learning】 集成学习Ensemble Learning & Boosting 算法(python实现)
零. Introduction 1.learn over a subset of data choose the subset uniformally randomly (均匀随机地选择子集) app ...
- 笔记︱集成学习Ensemble Learning与树模型、Bagging 和 Boosting
本杂记摘录自文章<开发 | 为什么说集成学习模型是金融风控新的杀手锏?> 基本内容与分类见上述思维导图. . . 一.机器学习元算法 随机森林:决策树+bagging=随机森林 梯度提升树 ...
- 机器学习:集成学习:随机森林.GBDT
集成学习(Ensemble Learning) 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测 ...
- 集成学习(Ensembling Learning)
集成学习(Ensembling Learning) 标签(空格分隔): 机器学习 Adabost 对于一些弱分类器来说,如何通过组合方法构成一个强分类器.一般的思路是:改变训练数据的概率分布(权值分布 ...
- [机器学习]集成学习--bagging、boosting、stacking
集成学习简介 集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务. 如何产生"好而不同"的个体学习器,是集成学习研究的核心. 集成学习的思路是通过 ...
- 吴裕雄 python 机器学习——集成学习梯度提升决策树GradientBoostingRegressor回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法回归模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 吴裕雄 python 机器学习——集成学习AdaBoost算法分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 机器学习——集成学习(Bagging、Boosting、Stacking)
1 前言 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测的分类器(errorrate < ...
随机推荐
- hdu1257 最少拦截系统(贪心) 2016-05-19 20:28 90人阅读 评论(0) 收藏
最少拦截系统 Problem Description 某国为了防御敌国的导弹袭击,发展出一种导弹拦截系统.但是这种导弹拦截系统有一个缺陷:虽然它的第一发炮弹能够到达任意的高度,但是以后每一发炮弹都不能 ...
- Hdu1969 Pie 2017-01-17 13:12 33人阅读 评论(0) 收藏
Pie Time Limit : 5000/1000ms (Java/Other) Memory Limit : 65536/32768K (Java/Other) Total Submissio ...
- codis服务部署前的操作及初始化
1.检查服务器ipv6模块是否打开,如果打开需要禁用ipv6,防止codis-dashbord连接zookeeper失败. 因为不确定codis-dashbord服务连接zookeeper使用ipv4 ...
- Team Foundation Server (TFS)集成Flyway,实现数据库的版本管理
1 概述 在系统开发过程中,我们对软件源代码的版本管理,已经有了比较成熟的解决方案.通过使用TFVC或GIT等源代码管理工具,可以非常方便的对软件代码实现回退.比较.分支合并等版本操作.对于软件依赖的 ...
- linux系统编程之进程(三):进程复制fork,孤儿进程,僵尸进程
本节目标: 复制进程映像 fork系统调用 孤儿进程.僵尸进程 写时复制 一,进程复制(或产生) 使用fork函数得到的子进程从父进程的继承了整个进程的地址空间,包括:进程上下文.进程堆栈. ...
- 《ASP.NET MVC 5 破境之道》:第一境 ASP.Net MVC5项目初探 — 第三节:View层简单改造
第一境 ASP.Net MVC5项目初探 — 第三节:View层简单改造 MVC默认模板的视觉设计从MVC1到MVC3都没有改变,比较陈旧了:在MVC4中做了升级,好看些,在不同的分辨率下,也能工作得 ...
- Day 14 列表推导式、表达器、内置函数
一. 列表推导式# l1 = []# for i in range(1,11):# l1.append(i)# print(l1)# #输出结果:[1, 2, 3, 4, 5, 6, 7, 8, 9, ...
- 程序猿的日常——Java基础之clone、序列化、字符串、数组
其实Java还有很多其他的基础知识,在日常工作技术撕逼中也是经常被讨论的问题. 深克隆与浅克隆 在Java中创建对象有两种方式: 一种是new操作符,它创建了一个新的对象,并把对应的各个字段初始化成默 ...
- apicloud 基础
时间成本 人力成本 很多人想开发app 又碍于时间和金钱成本 . 本色对app 要求不高的话. 混合app 开发是一种很好的方式. apicloud 就是一种很好的方式. apicloud ...
- Python 去除列表中重复的元素
Python 去除列表中重复的元素 来自比较容易记忆的是用内置的set l1 = ['b','c','d','b','c','a','a'] l2 = list(set(l1)) print l2 还 ...