kafka概述
kafka概述
Apache Kafka是一个开源 消息 系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
Kafka最初是由LinkedIn开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为 Producer ,消息接受者称为 Consumer ,此外kafka集群有多个kafka实例组成,每个实例(server)称为 broker。
为什么需要消息队列
- 解耦
- 冗余
- 扩展性
- 灵活性 & 峰值处理能力
- 可恢复性
- 顺序保证
- 缓冲
- 异步通信
kafka内部实现原理

点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此
发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
Kafka架构
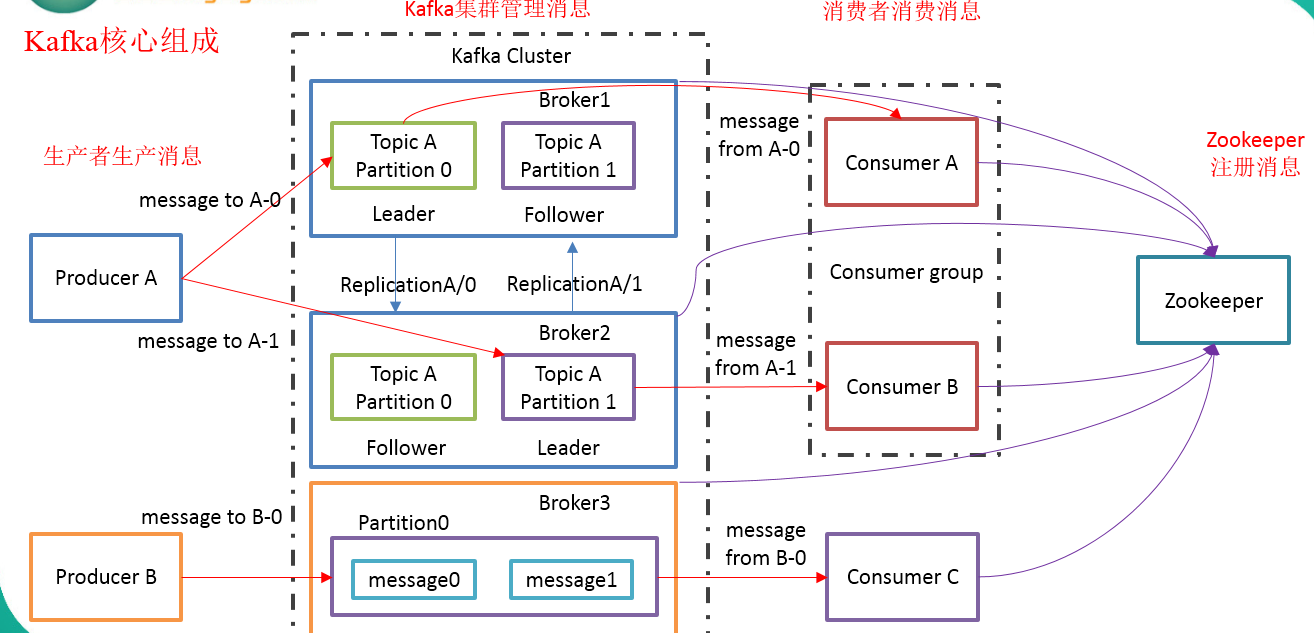
Producer :消息生产者,就是向kafka broker发消息的客户端。
Consumer :消息消费者,向kafka broker取消息的客户端
Topic :可以理解为一个队列。
Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
kafka特点
消息持久化:通过O(1)的磁盘数据结构提供数据的持久化(预读,后写,磁盘的顺序访问还快)
高吞吐量:每秒百万级的消息读写
分布式:扩展能力强
多客户端支持:java、 php、 python、 c++ ……
实时性:生产者生产的message立即被消费者可见
kafka基本组件
Broker:每一台机器叫一个Broker
Producer:日志消息生产者,用来写数据
Consumer:消息的消费者,用来读数据
Topic:不同消费者去指定的Topic中读,不同的生产者往不同的Topic中写(逻辑概念)
Partition:在Topic基础上做了进一步区分分层(物理实现,一文件夹的形式存在)
Producer
生产者可以发布数据到它指定的topic中,并可以指定在topic里哪些消息分配到哪些分区(比如简单的轮流分发各个分区或通过指定分区语义分配key到对应分区)
生产者直接把消息发送给对应分区的broker,而不需要任何路由层。
批处理发送,当message积累到一定数量或等待一定时间后进行发送
- 有两种方式:
- 同步模式:实时
- 异步模式:打到一定条件(时间、数据量)
Consumer
一种更抽象的消费方式:消费组(consumer group)
该方式包含了传统的queue和发布订阅方式
首先消费者标记自己一个消费组名。消息将投递到每个消费组中的某一个消费者实例上。
如果所有的消费者实例都有相同的消费组,这样就像传统的queue方式。
如果所有的消费者实例都有不同的消费组,这样就像传统的发布订阅方式。
消费组就好比是个逻辑的订阅者,每个订阅者由许多消费者实例构成(用于扩展或容错)。
- 如图:

相对于传统的消息系统,kafka拥有更强壮的顺序保证。
由于topic采用了分区,可在多Consumer进程操作时保证顺序性和负载均衡。
Topic
一个Topic是一个用于发布消息的分类或feed名,kafka集群使用分区的日志,每个分区都是有顺序且不变的消息序列
commit的log可以不断追加,消息在每个分区中都分配一个叫offset的id序列来唯一识别分区中的消息
如图:
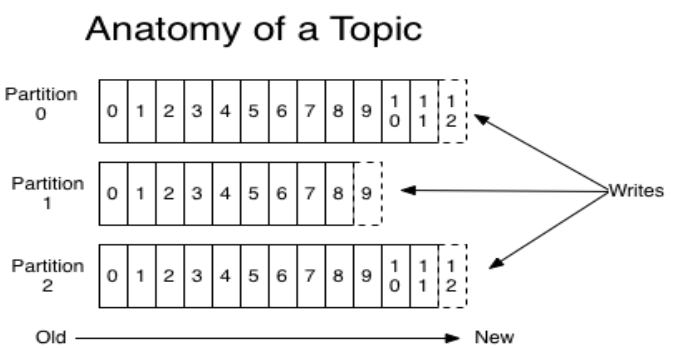
无论发布的消息是否被消费,kafka都会持久化一定时间(可配置)
在每个消费者都持久化这个offset在日志中。通常消费者读消息时会使offset值线性的增长,但实际上其位置是由消费者控制,它可以按任意顺序来消费消息。比如复位到老的offset来重新处理
每个分区代表一个并行单元
各组件之间的关系
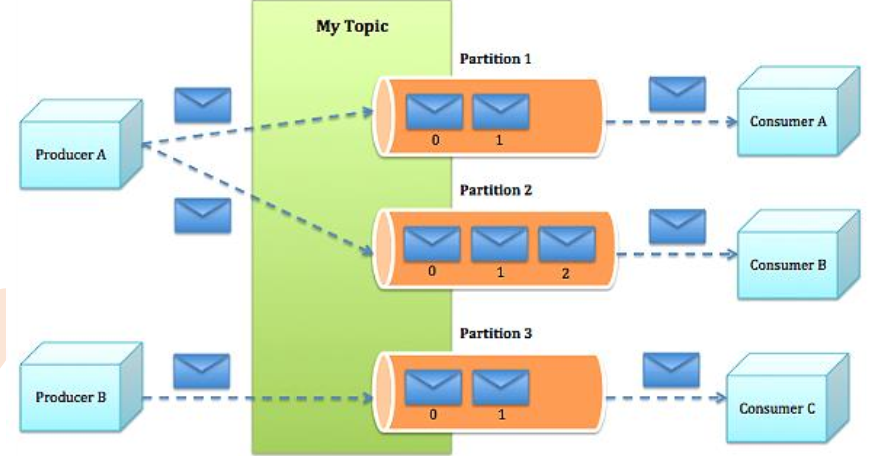
Kafka内部是分布式的、一个Kafka集群通常包括多个Broker
负载均衡:将Topic分成多个分区,每个Broker存储一个或多个Partition(hash)
多个Producer和Consumer同时生产和消费消息
Producer和Broker之间:push模式;Consumer和Broker之间:pull模式;
当一个consumer在读取一个partition时,其他的consumer不允许同时对同一个partition读取数据
kafka依赖zookeeper
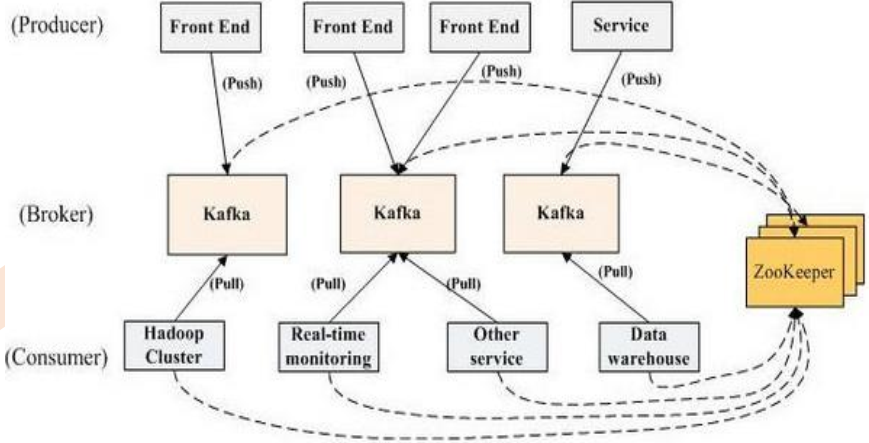
- kafka中只有Broker组件和Consumer组件与zk建立关系,因为Producer在做消息生产时可以自主制定往哪个Broker中写的
kafka消息基本单位:messag
message(消息)是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。如果consumer订阅了这个主题,那么新发布的消息就会广播给这些consumer。
message format:
– message length : 4 bytes (value: 1+4+n)
– "magic" value : 1 byte
– crc : 4 bytes
– payload : n bytes单条消息最大不超过(1M),通过配置(message.max.bytes=1000000B), broker可复制消息的最大字节数--replica.fetch.max.bytes(默认1M),
kafka概述的更多相关文章
- Kafka概述及安装部署
一.Kafka概述 1.Kafka是一个分布式流媒体平台,它有三个关键功能: (1)发布和订阅记录流,类似于消息队列或企业消息传递系统: (2)以容错的持久方式存储记录流: (3)记录发送时处理流. ...
- kafka学习汇总系列(一)kafka概述
一.kafka概述 在流式计算中,kafka是用来缓存数据的,storm通过消费kafka的数据进行计算.kafka的初心是,为处理实时数据提供一个统一.高通量.低等待的平台: 1.kafka是一个分 ...
- Kafka概述与设计原理
kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性: 1. 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能. 2 .高吞吐量:即使是 ...
- Kafka概述(一)
一.消息队列 客户端A给客户端B发送数据,若是直接发的话,客户端A给客户端B需要同步. 例如, 1) A在给B发送数据的时候,B挂掉了,此时的A是没有办法给B发送数据的: 2) A发送10M/s, ...
- Apache Kafka 概述
kafka教程,完全参照w3school: https://www.w3cschool.cn/apache_kafka/apache_kafka-dac11yot.html 以下是入门学习过程中摘录的 ...
- kafka概述与下一代消息队列
常用的消息中间件 消息中间件是当前处理大数据的一个非常重要的组件,用来解决应用解耦.异步通信.流量控制等问题,从而构建一个高效.灵活.消息同步和异步传输处理.存储转发.可伸缩和最终一致性的稳定系统.目 ...
- 1、kafka概述
一.关于消息队列 消息队列是一种应用间的通信方式,消息就是是指在应用之间传送的数据,它也是进程通信的一种重要的方式. 1.消息队列的基本架构 producer:消息生产者. broker:消息处理中心 ...
- Kafka 概述
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时处理领域. Kafka 中,客户端和服务器之间的通信是通过 TCP 协议完成的. 一.传统消息 ...
- Kafka(一)【概述、入门、架构原理】
目录 一.Kafka概述 1.1 定义 二.Kafka快速入门 2.1 安装部署 2.2 配置文件解析 2.3Kafka群起脚本 2.4 topic(增删改查) 2.5 生产和消费者命令行操作 三.K ...
随机推荐
- Mirco F-measure and Macro F-measure
- git clone 指定的单个目录或文件夹
git clone 指定的单个目录或文件夹 针对自己的项目 方法一 基于sparse clone变通方法 创建一个空仓库 拉取远程仓库信息 开启 sparse clone 设置过滤 更新仓库 创建空仓 ...
- 关于Cookie 的HttpOnly属性(java/web操作cookie+Tomcat操作jsessionid)
关于Cookie的其它只是不在累述.本文主要讲讲自己在项目中遇到的cookie的HttpOnly属性问题 Cookie的HttpOnly属性说明 cookie的两个新的属性secure和Httponl ...
- 启动PyCharm cannot start under Java 1.7 : Java 1.8 or later is required 解决方案
1.安装jdk8 2.配置环境变量 JAVA_HOME : C:\Program Files (x86)\Java\jre1.8.0_144 java原本的环境变量配置不变,只修改JAVA_HOME
- 基于CAS的SSO单点登录-实现ajax跨域访问的自动登录(也相当于超时重连)
先补课,以下网址可以把CAS环境搭起来. [JA-SIG CAS服务环境搭建]http://linliangyi2007.iteye.com/blog/165307 [JA-SIG CAS业务架构介绍 ...
- js常用函数汇总(不定期更新)
1.图片按比例压缩 function setImgSize(){ var outbox_w=imgbox.width(), outbox_h=imgbox.height(); imgbox.find( ...
- git相关操作(githug)
Level 15 restructure 关卡描述 你添加了一些文件到你的仓库,但现在知道你的项目需要进行调整.创建一个新的文件夹命名为“src”,使用git将所有的".html" ...
- YouTube 1080P高清视频下载方法
在国内在线视频网站还停留在1080P蓝光的时候,YouTube早已经支持4K和8K分辨率的极清视频.虽然4K和8K的清晰度比1080P高了许多档次,但是大部分人的电脑播放4K视频还是很卡的,所以目前来 ...
- libevent将信号封装为socket通知的核心代码
#include"stdafx.h" #include"iostream" #include "algorithm" #include&qu ...
- PowerDesigner如何设计表之间的关联
PowerDesigner如何设计表之间的关联 步骤/方法 在工具箱中找到参照关系工具: 由地区表到省份表之间拉参照关系,箭头指向父表,然后双击参照关系线,打开参照关系的属性: 在这里检查 ...