Hadoop(14)-MapReduce框架原理-切片机制
1.FileInputFormat切片机制
切片机制

比如一个文件夹下有5个小文件,切片时会切5个片,而不是一个片
案例分析

2.FileInputFormat切片大小的参数配置
源码中计算切片大小的公式

切片大小设置

获取切片大小API

3. CombineTextInputFormat切片机制
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
1)应用场景
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
2)虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值
3)切片机制
生成切片过程包括:虚拟存储过程和切片过程二部分

(1)虚拟存储过程:
将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
例如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
(2)切片过程:
(a)判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。
(b)如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
(c)测试举例:有4个小文件大小分别为1.7M、5.1M、3.4M以及6.8M这四个小文件,则虚拟存储之后形成6个文件块,大小分别为:
1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M)
最终会形成3个切片,大小分别为:
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
4.CombineTextInputFormat案例实操
准备四个小文件,大小在1M左右,以之前的wordcount代码为基础
直接运行代码,观察console

在WcDriver.class中,增加如下代码
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class); //虚拟存储切片最大值设置4m
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
观察console
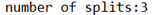
继续修改Wcdriver.class
//虚拟存储切片最大值设置20m
CombineTextInputFormat.setMaxInputSplitSize(job, 20971520)
观察console
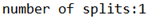
Hadoop(14)-MapReduce框架原理-切片机制的更多相关文章
- Hadoop(13)-MapReduce框架原理--Job提交源码和切片源码解析
1.MapReduce的数据流 1) Input -> Mapper阶段 这一阶段的主要分工就是将文件切片和把文件转成K,V对 输入源是一个文件,经过InputFormat之后,到了Mapper ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- Hadoop(16)-MapReduce框架原理-自定义FileInputFormat
1. 需求 将多个小文件合并成一个SequenceFile文件(SequenceFile文件是Hadoop用来存储二进制形式的key-value对的文件格式),SequenceFile里面存储着多个文 ...
- Hadoop(12)-MapReduce框架原理-Hadoop序列化和源码追踪
1.什么是序列化 2.为什么要序列化 3.为什么不用Java的序列化 4.自定义bean对象实现序列化接口(Writable) 在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop ...
- MapReduce框架原理--Shuffle机制
Shuffle机制 Mapreduce确保每个reducer的输入都是按键排序的.系统执行排序的过程(Map方法之后,Reduce方法之前的数据处理过程)称之为Shuffle. partition分区 ...
- Hadoop(18)-MapReduce框架原理-WritableComparable排序和GroupingComparator分组
1.排序概述 2.排序分类 3.WritableComparable案例 这个文件,是大数据-Hadoop生态(12)-Hadoop序列化和源码追踪的输出文件,可以看到,文件根据key,也就是手机号进 ...
- Hadoop(20)-MapReduce框架原理-OutputFormat
1.outputFormat接口实现类 2.自定义outputFormat 步骤: 1). 定义一个类继承FileOutputFormat 2). 定义一个类继承RecordWrite,重写write ...
- Hadoop(19)-MapReduce框架原理-Combiner合并
1. Combiner概述 2. 自定义Combiner实现步骤 1). 定义一个Combiner继承Reducer,重写reduce方法 public class WordcountCombiner ...
- Hadoop(15)-MapReduce框架原理-FileInputFormat的实现类
1. TextInputFormat 2.KeyValueTextInputFormat 3. NLineInputFormat
随机推荐
- matlab练习程序(演化策略ES)
还是这本书上的内容,不过我看演化计算这一章是倒着看的,这里练习的算法正好和书中介绍的顺序是相反的. 演化策略是最古老的的演化算法之一,和上一篇DE算法类似,都是基于种群的随机演化产生最优解的算法. 算 ...
- Mantis中的状态
在 Mantis中的 问题状态一共有以下几种 10:new,20:feedback,30:acknowledged,40:confirmed,50:assigned,80:resolved,90:cl ...
- MySQL Database on Azure 支持 5.7 版本啦!
MySQL Database on Azure 目前已经全面开放对 5.7 的支持.您可以通过管理门户,在 MySQL 数据库服务器创建时选择 5.7 版本进行体验.MySQL 5.7 版本目前是 M ...
- SqlServer50条常用查询语句
Student(S#,Sname,Sage,Ssex) 学生表 Course(C#,Cname,T#) 课程表 SC(S#,C#,score) 成绩表 Teacher(T#,Tname) 教师表 问题 ...
- ubuntu 18 下配置 WebStorm 编译 sass
ubuntu 18 下配置 WebStorm 编译 scss 标签(空格分隔): IDE 安装Ruby: sudo apt-get install ruby ruby -v ruby 2.5.1p57 ...
- oracle_great_integration_译文
website:https://www.oracle.com/corporate/features/great-integrations.html Great Integrations(伟大的整合) ...
- WAKE-WIN10-SOFT-软件-Matlab配置及工具箱
1Matlab 1,1Matlab下载,安装,配置,,, 1,2 2工具箱 2,1LibSVM 必应:https://www.bing.com/search?q=libsvm&qs=n& ...
- 对 Canal (增量数据订阅与消费)的理解
概述 canal是阿里巴巴旗下的一款开源项目,纯Java开发.基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB). 起源:早期,阿里巴巴B2B公司 ...
- NO.002-2018.02.07《越人歌》先秦:佚名
参考之后略有修改,疑问点“不訾诟耻”释义 越人歌原文.翻译及赏析_古诗文网 蒙羞被好兮不訾诟耻_释义_吴江诗词网 越人歌 先秦:佚名 今夕何夕兮,搴舟中流.今晚是怎样的晚上啊河中漫游.搴(qiān ...
- 在VMware上安装ubuntu——网络类型
安装虚拟机时,向导提示选择网络类型: 当使用仅主机模式网络时,虚拟机和物理机不能互相访问共享.