time、random以及序列化模块
一、 time模块
在Python中,通常有这几种方式来表示时间:
- 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串(Format String)
- 结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时),可以通过点来调用具体里面的值。
import time
#--------------------------我们先以当前时间为准,让大家快速认识三种形式的时间
print(time.time()) # 时间戳:1487130156.419527
f = time.localtime(time.time() - 86000 * 3) # 150000000 秒 86000,三天前的结构化时间
print(time.strftime("%Y-%m-%d %X")) #格式化的时间字符串:'2017-02-15 11:40:53',当前字符串时间,
print(time.strftime('%Y-%m-%d %H:%M:%S',f)) # f是结构化时间 将结构化时间转化为字符串时间 print(time.localtime()) #本地时区的struct_time
print(time.gmtime()) #UTC时区的struct_time%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称相应参数
其中计算机认识的时间只能是'时间戳'格式,而程序员可处理的或者说人类能看懂的时间有: '格式化的时间字符串','结构化的时间' ,于是有了下图的转换关系
- 结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时),可以通过点来调用具体里面的值。
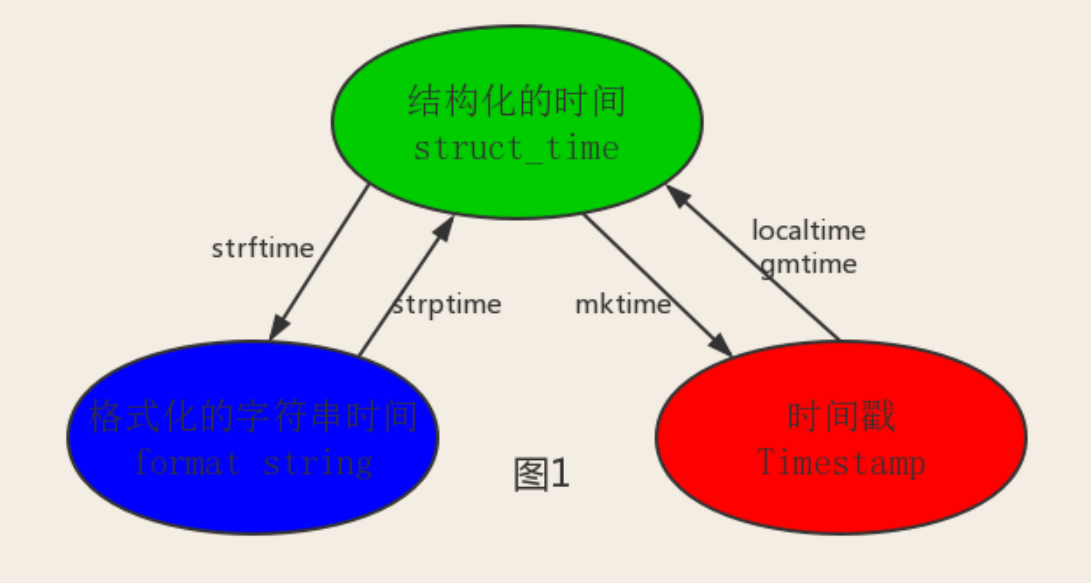
结合上图可得:
#--------------------------按图1转换时间
、localtime([secs])将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
time.localtime() # time.struct_time(tm_year=2018, tm_mon=9, tm_mday=6, tm_hour=20, tm_min=56, tm_sec=16, tm_wday=3, tm_yday=249, tm_isdst=0) 当前时间
time.localtime(1473525444.037215) # time.struct_time(tm_year=2016, tm_mon=9, tm_mday=11, tm_hour=0, tm_min=37, tm_sec=24, tm_wday=6, tm_yday=255, tm_isdst=0) 给定时间的格式化时间 、gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。
time.gmtime() # 结果 time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=6, tm_min=19,tm_sec=48, tm_wday=3, tm_yday=125, tm_isdst=0)
3、mktime(t) : 将一个struct_time转化为时间戳。
print(time.mktime(time.localtime())) #1473525749.0
4、strftime(format[, t]) : 把一个代表时间的元组或者struct_time(如由time.localtime()和time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。
#如果元组中任何一个元素越界,ValueError的错误将会被抛出。
print(time.strftime("%Y-%m-%d %X", time.localtime())) #2016-09-11 00:49:56
print(time.strftime('%Y--%m--%d %X',)) #2018--09--06 21:04:16
# 5、time.strptime(string[, format]) # 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X')) #time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6, # tm_wday=3, tm_yday=125, tm_isdst=-1)
#在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。
总结:
time是datetime的底层模块
时间戳时间-localtime/gmtime-> 结构化时间 -strftime-> 格式化时间
时间戳时间<-mktime- 结构化时间 <-strptime- 格式化时间
time.time() # 获取时间戳
时间戳 --localtime('时间戳')--> 结构化时间
结构化时间--mktime('结构化时间')--> 时间戳
结构化时间--strftime('格式','结构化时间')--> 结构化的字符串 # 可以格式自定义,
结构化字符串时间 --strptime('结构化时间','格式')--> 结构化时间 # 必须参数一一对应
1、当前年月日的凌晨12点对应的时间戳时间是多少
today =time.strftime('%Y-%m-%d') # 格式化时间
locals_time=time.strptime(today,'%Y-%m-%d') # 获取到结构化时间,默认返回凌晨时间
print(time.mktime(locals_time)) # 获取时间戳
today =time.strftime('%Y-%m-%d %X') # 格式化时间
locals_time=time.strptime(today,'%Y-%m-%d %X') # 获取到结构化时间,默认返回当前时间
print(time.mktime(locals_time)) # 获取时间戳
print(time.time())
公司内的时间操作
例题:
1、将s时间往前推30天
import time
s = '2019-03-20 10:40:00'
local_time = time.strptime(s,'%Y-%m-%d %X') # 转化成结构化时间
print(local_time) #time.struct_time(tm_year=2019, tm_mon=3, tm_mday=20, tm_hour=10, tm_min=40, tm_sec=0, tm_wday =2, tm_yday=79, tm_isdst=-1)
x=time.mktime(local_time)+30 * 86000 # 转化成时间戳
new_time = time.localtime(x) #将时间戳转化为结构化时间
print(new_time)
new_time_local =time.strftime('%Y-%m-%d %X',new_time) # 将结构化时间转化为字符串格式
print(new_time_local) #准确答案
import datetime
#将当前时间推前30天
print(datetime.datetime.now()-datetime.timedelta(30))
当前推后30天
含有月份周期的时间表示:
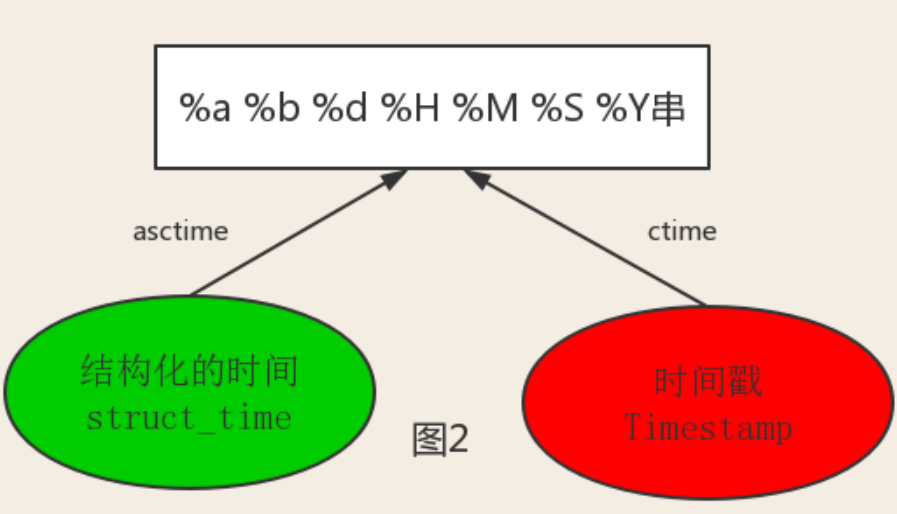
结合上图可得:
#--------------------------按图2转换时间
# asctime([t]) : 把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。
# 如果没有参数,将会将time.localtime()作为参数传入。
print(time.asctime())#Sun Sep 11 00:43:43 2016 # ctime([secs]) : 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为
# None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。
print(time.ctime()) # Sun Sep 11 00:46:38 2016
print(time.ctime(time.time())) # Sun Sep 11 00:46:38 2016
输入某年某月某日,判断是这一年中的第几天?(用内置模块实现) import time
input_ = input('请输入年月日:')
time_local = time.strptime(input_,'%Y-%m-%d %X')
print(time_local.tm_yday) # 结构化时间调用里面的参数
结构化时间点功能
补充:
1、time.clock():这个需要注意,在不同的系统上含义不同。在UNIX系统上,它返回的是“进程时间”,它是用秒表示的浮点数(时间戳)。而在WINDOWS中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用是自第一次调用以后到现在的运行时间。(实际上是以WIN32上QueryPerformanceCounter()为基础,它比毫秒表示更为精确)也就是CPU工作时间。
2、time.sleep(secs):线程推迟指定的时间运行。单位为秒
二、datetime模块
#时间加减
import datetime # print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925,返回当前时间
# print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19
# print(datetime.datetime.now() )
# print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
# print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
# print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
# print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 # c_time = datetime.datetime.now()
# print(c_time.replace(minute=3,hour=2)) #时间替换 2018-09-07 02:03:37.591115 其实就是修改时间
import datetime
t = datetime.datetime.now() # 时间操作符获取对象
print(t.date()) # 就可以访问具体的天数
print(t.time())
print(t.timestamp()) #时间戳
print(t.day)
print(t.month)
from datetime import datetime,timedelta # 从xx导入 建议
print(datetime.now() - timedelta(3)) # 进行加减天数
timedelta功能
三、random模块
import random
print(random.random()) #(,)----float 大于0且小于1之间的小数
print(random.randint(,)) #[,] 大于等于1且小于等于3之间的整数
print(random.randrange(,)) #[,) 大于等于1且小于3之间的整数
print(random.choice([,'',[,]])) #1或者23或者[,],这里可以填字符串,在字符串中随机一个字母
print(random.choices([1,'23',[4,5],'3','4'],k=3)) #['4', '23', '23'],随机3个
print(random.sample([,'',[,]],)) #列表元素任意2个组合 print(random.uniform(,)) #大于1小于3的小数,如1. item=[,,,,] random.shuffle(item) #打乱item的顺序,相当于"洗牌" print(item)
例: 验证码生成器:
import random
def make_code(n):
res = ''
for i in range(n):
s1 = chr(random.randint(65,90)) # 生成字母chr
s2 = str(random.randint(0,9))
res += random.choice([s1,s2])
return res
print(make_code(9)) # H53FVG8K4
四、os模块
os模块是与操作系统交互的一个接口
import os
print(os.getcwd()) # 获取当前工作目录,即当前python脚本工作的目录路径 D:\pycharm code\离校\时间模块 os.chdir("D:\pycharm code\day2") # 改变当前脚本工作目录;相当于shell下cd
print(os.getcwd()) # D:\pycharm code\day2 当再一次判断位置时,发生了变化 # print(os.curdir) # .
# print(os.pardir) # .. # os.makedirs('abc\\alex') # 在day2(当前工作目录)下生成abc文件,在abc下再生成alex文件
# os.makedirs('dirname1/dirname2') # 可生成多层递归目录 (已存在的文件名不能再一次生成) #os.removedirs('dirname1/dirname2') # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 # os.mkdir('dirname') # 生成单级目录;相当于shell中mkdir dirname
# os.rmdir('dirname') # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname #print(os.listdir('.')) # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印,['abc', '今日大纲', '作业讲解.py'] # os.remove('哈哈哈') # 删除一个文件
# os.rename("abc","newname") # 重命名文件/目录 旧名字,新名字 print(os.stat('./newname')) # 获取文件目录信息('path/filename') os.stat_result(st_mode=16895, st_ino=2533274790436658,
# st_dev=2092381065,st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1536304047, st_mtime=1536300456,st_ctime=1536300456)
s = os.stat('./newname')
print(s.st_size) # 可打印文件大小 print(os.sep) # 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
s=os.linesep # 输出当前平台使用的行终止符,win下为"\r\n",Linux下为"\n",Mac下为 '\r'
print('c,jjj%s'%s,end=' ')
print('哈哈') print(os.pathsep) # 输出用于分割文件路径的字符串 win下为;,Linux下为:
print(os.name) # 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' #os.system("ping www.baidu.com -t") # 运行shell命令,直接显示,cmd窗口
# print(os.environ) # 获取系统环境变量
# print(os.path.abspath('D:\BaiduNetdiskDownload')) # 返回path规范化的绝对路径 print(os.path.split('D:\BaiduNetdiskDownload')) # 将path分割成目录和文件名二元组返回 ('D:\\', 'BaiduNetdiskDownload')
print(os.path.dirname('D:\BaiduNetdiskDownload')) # 返回path的目录。其实就是os.path.split(path)的第一个元素 D:\
print(os.path.basename('D:\BaiduNetdiskDownload')) # 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。
# 即os.path.split(path)的第二个元素 BaiduNetdiskDownload print(os.path.exists('D:\BaiduNetdiskDownload')) # 如果path存在,返回True;如果path不存在,返回False True
print(os.path.isabs('D:\BaiduNetdiskDownload')) # 如果path是绝对路径,返回True True
print(os.path.isfile('D:\BaiduNetdiskDownload')) # 如果path是一个存在的文件,返回True。否则返回False False
print(os.path.isdir('D:\BaiduNetdiskDownload')) # 如果path是一个存在的目录,则返回True。否则返回False True #os.path.join(path1[, path2[, ...]]) # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
print(os.path.join('/my/','name/is/','vampire_techking')) # /my/name/is/vampire_techking,注意这里的第二个参数不能以/开头 print(os.path.getatime('D:\BaiduNetdiskDownload')) # 返回path所指向的文件或者目录的最后存取时间 1536305083.0908828
print(os.path.getmtime('D:\BaiduNetdiskDownload')) # 返回path所指向的文件或者目录的最后修改时间
print(os.path.getsize('D:\BaiduNetdiskDownload')) # 返回path的大小
简要总结:
os.path.abspath(path) #返回绝对路径
os.path.basename(path) #返回文件名
os.path.commonprefix(list) #返回list(多个路径)中,所有path共有的最长的路径。
os.path.dirname(path) #返回文件路径
os.path.exists(path) #路径存在则返回True,路径损坏返回False
os.path.expanduser(path) #把path中包含的"~"和"~user"转换成用户目录
os.path.expandvars(path) #根据环境变量的值替换path中包含的”$name”和”${name}”
os.path.getatime(path) #返回最后一次进入此path的时间。
os.path.getmtime(path) #返回在此path下最后一次修改的时间。
os.path.getctime(path) #返回path的大小
os.path.getsize(path) #返回文件大小,如果文件不存在就返回错误
os.path.isabs(path) #判断是否为绝对路径
os.path.isfile(path) #判断路径是否为文件
os.path.isdir(path) #判断路径是否为目录
os.path.islink(path) #判断路径是否为链接
os.path.ismount(path) #判断路径是否为挂载点()
os.path.join(path1[, path2[, ...]]) #把目录和文件名合成一个路径
os.path.normcase(path) #转换path的大小写和斜杠
os.path.normpath(path) #规范path字符串形式
os.path.realpath(path) #返回path的真实路径
os.path.relpath(path[, start]) #从start开始计算相对路径
os.path.samefile(path1, path2) #判断目录或文件是否相同
os.path.sameopenfile(fp1, fp2) #判断fp1和fp2是否指向同一文件
os.path.samestat(stat1, stat2) #判断stat tuple stat1和stat2是否指向同一个文件
os.path.split(path) #把路径分割成dirname和basename,返回一个元组
os.path.splitdrive(path) #一般用在windows下,返回驱动器名和路径组成的元组
os.path.splitext(path) #分割路径,返回路径名和文件扩展名的元组
os.path.splitunc(path) #把路径分割为加载点与文件
os.path.walk(path, visit, arg) #遍历path,进入每个目录都调用visit函数,visit函数必须有
3个参数(arg, dirname, names),dirname表示当前目录的目录名,names代表当前目录下的所有文件名,args则为walk的第三个参数
os.path.supports_unicode_filenames #设置是否支持unicode路径名 在Linux和Mac平台上,该函数会原样返回path,在windows平台上会将路径中所有字符转换为小写,并将所有斜杠转换为饭斜杠。
>>> os.path.normcase('c:/windows\\system32\\')
'c:\\windows\\system32\\' 规范化路径,如..和/
>>> os.path.normpath('c://windows\\System32\\../Temp/')
'c:\\windows\\Temp' >>> a='/Users/jieli/test1/\\\a1/\\\\aa.py/../..'
>>> print(os.path.normpath(a))
/Users/jieli/test1
1、os.walk() 方法用于通过在目录树中游走输出在目录中的文件名,向上或者向下。
格式:os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]])
top -- 是你所要遍历的目录的地址, 返回的是一个三元组(root,dirs,files)。 root 所指的是当前正在遍历的这个文件夹的本身的地址
dirs 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录)
files 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
topdown --可选,为 True,则优先遍历 top 目录,否则优先遍历 top 的子目录 (默认为开启)。如果 topdown 参数为 True,walk 会遍历top文件夹,与top 文件夹中每一个子目录。
onerror -- 可选,需要一个 callable 对象,当 walk 需要异常时,会调用。
followlinks -- 可选,如果为 True,则会遍历目录下的快捷方式(linux 下是软连接 symbolic link )实际所指的目录(默认关闭),如果为 False,则优先遍历 top 的子目录。 import os
for root, dirs, files in os.walk(".", topdown=False):
for name in files:
print(os.path.join(root, name))
for name in dirs:
print(os.path.join(root, name)) 运行结果:
./.bash_logout
./amrood.tar.gz
./.emacs
./httpd.conf
./www.tar.gz
./mysql.tar.gz
./test.py
./.bashrc
./.bash_history
./.bash_profile
./tmp
./tmp/test.py
walk函数的使用
五、sys模块
sys是与Python解释器交互
1、sys.argv 命令行参数List,第一个元素是程序本身路径
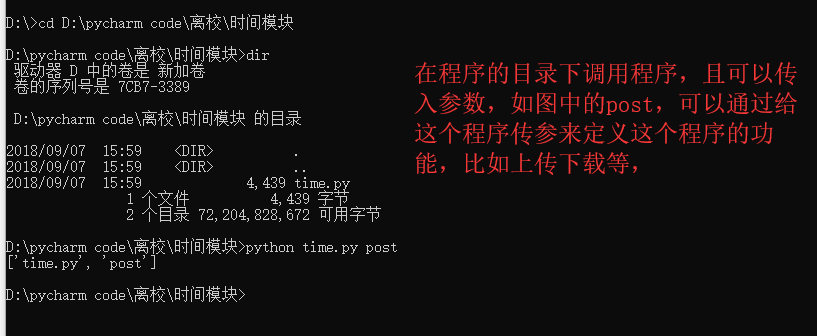
这个time.py文件的内容如下:
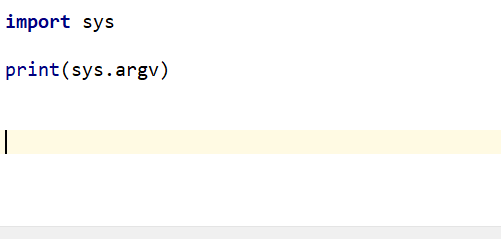
不难看出这个程序,把我们在外部传入的post传入在这个sys.argv中且是个列表,当然传入的参数个数任意多。
对其进行改进!
import sys # print(sys.argv) def updata():
print('上传!!!') def download():
print('download……') if sys.argv[1] == 'post':
updata()
elif sys.argv[1] =='download':
download()
结果:

import sys sys.argv # 命令行参数List,第一个元素是程序本身路径sys.exit(n) # 退出程序,正常退出时exit(0) n 为其他数时,都存在其他异常退出,显示1 print(sys.version) # 获取Python解释程序的版本信息
# sys.maxint # 最大的Int值 print(sys.path ) # 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 会查找环境变量,当然最开始是从就近的工作文件找sys.path.append() # 可以添加查找给出的绝对目录,添加到列表中
print(sys.platform) # 返回操作系统平台名称 # win32 或则 linux sys.stdout.write('#') # 向终端打印标准化输出 print就是用这个方法做出来的
sys.moudles # 是一个全局字典,该字典是python启动后就加载在内存中。每当程序员导入新的模块,sys.modules将自动记录该模块
进度条打印实例:
import sys
import time
import random def progress(percent, width=50):
if percent >= 1:
percent = 1 # 百分比保证100%
show_str = ('[%%-%ds]'%width)%(int(width*percent)*'#')
print('\r%s %d%%'%(show_str,int(100*percent)),file=sys.stdout,flush=True,end='') data_size = 1025
recv_size = 0
while recv_size < data_size:
s = random.random()
time.sleep(s) # 模拟数据的传输延迟
recv_size += 50 # 每次收1024 percent = recv_size/data_size # 接收的比例
progress(percent,width=70)import sys
import time
import random def progress(percent, width=50):
if percent >= 1:
percent = 1 # 百分比保证100%
show_str = ('[%%-%ds]'%width)%(int(width*percent)*'#')
print('\r%s %d%%'%(show_str,int(100*percent)),file=sys.stdout,flush=True,end='') data_size = 1025
recv_size = 0
while recv_size < data_size:
s = random.random()
time.sleep(s) # 模拟数据的传输延迟
recv_size += 50 # 每次收1024 percent = recv_size/data_size # 接收的比例
progress(percent,width=70)
补充print知识点:
print()函数的参数如下:
print(*values, sep=' ', end='\n', file=sys.stdout, flush=False) 1、 *values : 表示要打印的值
表示任何多个无名参数, 各个值之间用‘,’(逗号隔开),打印出来各个值之间用空格隔开 2、sep=’ ‘: 表示当输入多个打印的值时,各个值之间分割方式, 默认空格,可以自定义
例:print('a','m','c',sep='\n') # a m c 换行 3、 end=‘\n’**: 控制print中传入值输出完后结束符号,默认换行,这里可以设置为其他,如 ‘\t’, ’ ’ 等等, 可以自己定义
例:print('python', end=' ')
print('is good') # python is good 4、file=sys.stdout:设置输出设备,及把print中的值打印到什么地方,默认输出到准端,可以设置file= 文件储存对象,把内容存到该文件中
例:f = open(r'a.txt', 'w')
print('python is good', file=f)
f.close()
# 则把python is good保存到 a.txt 文件中 5、flush=False: 该参数主要是刷新, 默认False,不刷新,Ture时刷新,例如在上面 4 中print中设置: f = open(r'a.txt', 'w')
print('python is good', file=f, flush=True) # print到f中的内容先从到内存中,
当文件对象关闭时才把内容输出到 a.txt 中,当flush=True时它会立即把内容刷新存到 a.txt 中
六、序列化模块json、pickle、shelve简述
什么叫序列化——将由原来的字典、列表等内容转换成一个字符串的过程就叫做序列化,反序列化就是将字符串或则字节转化成原先的数据类型。
序列化的目的;
1、以某种存储形式使自定义对象持久化;
2、将对象从一个地方传递到另一个地方;
3、使程序更具有维护.
# a发送以一个数据给b,由于发送数据,必须是二进制。所以需要经历编码到解码的过程
dic = {'a':(1,2,3)}
s = str(dic).encode(encoding='utf-8') # 编码
ret = s.decode(encoding='utf-8') # 解码
print(ret) # 查看数据
print(type(ret)) # 查看类型
print(type(eval(ret))) # 还原为字典 eval将字符串转换为字典
# 结果:
{'a': (1, 2, 3)}
<class 'str'>
<class 'dict'>
使用eval不安全,有可能是病毒,接收方,啪的一些,就执行了。
这个时候,就需要用到序列化了

如上图,可知:
dic --> 字符串 序列化
字符串 --> dic 反序列化
序列化 == 创造一个序列 ==》 创造一个字符串
实例化 == 创造一个实例
在Python中的序列化模块:
json 所有的编程语言都通用的序列化格式
它支持的数据类型非常有限 数字 字符串 列表 字典。
pickle 只能在python语言的程序之间传递数据用的
pickle支持python中所有的数据类型。
shelve python3.* 之后才有的,可以把它当作字典处理。
七、Json模块
Json模块提供四个功能:dumps、dump、loads、load,除了可以序列化字典还可以序列化列表等。注意Json操作的是字符串,所以在打开读写文件的时候使用‘w'和’r‘模式。
序列化(dumps,dump)
import json # 导入模块
dic = {"慕容美雪":(170,60,'赏花')} # 键必须加双引号
ret = json.dumps(dic) # 序列化
print(type(dic),dic) # 查看原始数据类型
print(type(ret),ret) # 查看序列化后的数据 <class 'dict'> {'慕容美雪': (170, 60, '赏花')}
<class 'str'> {"\u6155\u5bb9\u7f8e\u96ea": [170, 60, "\u8d4f\u82b1"]} 从结果中,可以看出:
原始数据类型是字典,序列化之后,就是字符串类型。而且中文变成了看不懂的字符串。
这是因为json.dumps 序列化时对中文默认使用的ascii编码。
想输出真正的中文需要指定ensure_ascii=False import json # 导入模块
dic = {"慕容美雪":(170,60,'赏花')}
ret = json.dumps(dic,ensure_ascii=False) # 序列化时,不使用ascii码
print(type(dic),dic) # 查看原始数据类型
print(type(ret),ret) # 查看序列化后的数据 <class 'dict'> {'慕容美雪': (170, 60, '赏花')}
<class 'str'> {"慕容美雪": [170, 60, "赏花"]} 由于json不识别元组,json认为元组和列表是一回事,所以变成了列表。
在json中,引号,统一使用双引号
反序列化 (loads,load)
import json # 导入模块
dic = {"慕容美雪":(170,60,'赏花')}
ret = json.dumps(dic,ensure_ascii=False) # 序列化时,不使用ascii码
res = json.loads(ret) # 反序列化
print(type(res),res) # 查看反序列化后的数据 执行输出: <class 'dict'> {'慕容美雪': [170, 60, '赏花']} 从结果中,可以看出,原来的单引号由还原回来了。
反序列化,比eval要安全。所以eval尽量少用。
注意: dump和load是直接将对象序列化之后写入文件,且依赖一个文件句柄。而dumps和loads是直接在文件中进行操作,当然可以可以通过文件的‘w'模式写入。
dump 将序列化内容写入文件
import json # 导入模块
dic = {"慕容美雪":(170,60,'赏花')}
f = open('美雪','w',encoding='utf-8')
json.dump(dic,f) # 先接收要序列化的对象,再接收文件句柄
f.close() 执行程序,查看文件美雪内容为:
{"\u6155\u5bb9\u7f8e\u96ea": [170, 60, "\u8d4f\u82b1"]}
要想文件写入中文,可以加参数ensure_ascii=False import json # 导入模块
dic = {"慕容美雪":(170,60,'赏花')}
f = open('美雪','w',encoding='utf-8')
json.dump(dic,f,ensure_ascii=False) # 先接收要序列化的对象,再接收文件句柄
f.close() 执行程序,再次查看文件内容: {"慕容美雪": [170, 60, "赏花"]}
load 读取文件中的序列化内容 import json # 导入模块
dic = {"慕容美雪":(170,60,'赏花')}
f = open('美雪','r',encoding='utf-8')
ret = json.load(f) #接收文件句柄
print(ret) # 查看内容
print(type(ret)) # 查看变量类型
f.close() # 最后记得关闭文件句柄 执行输出: {'慕容美雪': [170, 60, '赏花']}
<class 'dict'>
其他参数:
import json
data = {'username':['李华','二愣子'],'sex':'male','age':16}
json_dic2 = json.dumps(data,sort_keys=True,indent=4,separators=(',',':'),ensure_ascii=False)
print(json_dic2) 执行输出:
{
"age":16,
"sex":"male",
"username":[
"李华",
"二愣子"
]
} 参数说明:
Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
ensure_ascii:,当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。)
indent:应该是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(',’,’:’);这表示dictionary内keys之间用","隔开,而KEY和value之间用":"隔开。
sort_keys:将数据根据keys的值进行排序。
写入多行
import json
dic1 = {"S":(170,60,'唱歌')}
dic2 = {"H":(170,60,'唱歌')}
dic3 = {"E":(170,60,'唱歌')}
f = open('she','a',encoding='utf-8')
f.write(json.dumps(dic1)+'\n') # 写入一行内容,注意,一定要加换行符
f.write(json.dumps(dic2)+'\n')
f.write(json.dumps(dic3)+'\n')
f.close() # 关闭文件句柄 执行程序,查看文件she内容: {"S": [170, 60, "\u5531\u6b4c"]}
{"H": [170, 60, "\u5531\u6b4c"]}
{"E": [170, 60, "\u5531\u6b4c"]}
读取多行
import json
f = open('she','r',encoding='utf-8')
for i in f:
print(json.loads(i.strip()))
f.close() 执行输出: {'S': [170, 60, '唱歌']}
{'H': [170, 60, '唱歌']}
{'E': [170, 60, '唱歌']}
总结:
dumps序列化 loads反序列化 只在内存中操作数据 主要用于网络传输 和多个数据与文件打交道
dump序列化 load反序列化 主要用于一个数据直接存在文件里—— 直接和文件打交道
八、Pickle模块
用于Python特有的类型和Python的数据类型间进行转换 。 pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load(不仅可以序列化字典、列表……还可以把Python中任意的数据类型序列化)
用法和json是一样的 : 注意的是Pickle模块是基于字节操作,所以在读写的时候要用’wb‘和’rb'
dumps序列化:
import pickle
dic = {(170,60,'唱歌'):"S"}
print(pickle.dumps(dic)) #执行结果:
b'\x80\x03}q\x00K\xaaK<X\x06\x00\x00\x00\xe5\x94\xb1\xe6\xad\x8cq\x01\x87q\x02X\x01\x00\x00\x00Sq\x03s.'
输出结果是bytes类型的,区别于json dump写入文件
文件模式必须是带b,因为它是bytes类型、 import pickle
dic = {(170,60,'唱歌'):"S"}
f = open('s','wb') #使用dump必须以+b的形式打开文件,编码不需要指定,因为是bytes类型
pickle.dump(dic,f)
f.close() # 注意要关闭文件句柄 #执行结果是一堆乱码
load 读取文件内容:
import pickle
f = open('s','rb') # bytes类型不需要指定编码
print(pickle.load(f))
f.close() # 注意要关闭文件句柄 执行结果:
{(170, 60, '唱歌'): 'S'}
dump写入多行内容和load读取文件内容:
import pickle
dic1 = {"张靓颖":(170,60,'唱歌')}
dic2 = {"张韶涵":(170,60,'唱歌')}
dic3 = {"梁静茹":(170,60,'唱歌')}
f = open('singer','wb')
pickle.dump(dic1,f)
pickle.dump(dic2,f)
pickle.dump(dic3,f)
f.close() #执行结果是一堆乱码 load 读取文件内容
import pickle
f = open('singer','rb')
print(pickle.load(f))
print(pickle.load(f))
print(pickle.load(f))
print(pickle.load(f)) # 多读取一行,就会报错
f.close()
但是输出的结果如下
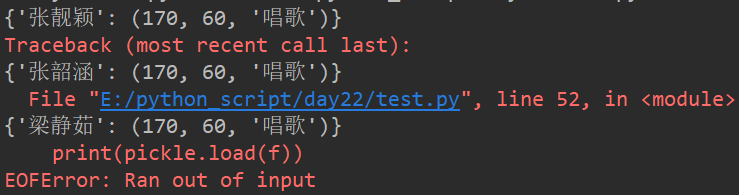
为了解决这个问题,需要用到while循环+try:
import pickle
f = open('singer','rb')
while True:
try:
print(pickle.load(f))
except Exception: # 接收一切错误
break # 跳出循环
f.close() 执行结果:
{'张靓颖': (170, 60, '唱歌')}
{'张韶涵': (170, 60, '唱歌')}
{'梁静茹': (170, 60, '唱歌')}
总结:
json 在写入多次dump的时候 不能对应执行多次load来取出数据,pickle可以
json 如果要写入多个元素 可以先将元素dumps序列化,f.write(序列化+'\n')写入文件
读出元素的时候,应该先按行读文件,在使用loads将读出来的字符串转换成对应的数据类型
注意:pickle还可以序列化一些类或者函数(json不能):
import pickle
class A:
def __init__(self,name,age):
self.name=name
self.age=age
a = A('alex',80)
ret = pickle.dumps(a) # 序列化对象
print(ret)
obj = pickle.loads(ret) # 反序列化
print(obj.__dict__) # 查看对象属性<br>f.close() 执行结果:
b'\x80\x03c__main__\nA\nq\x00)\x81q\x01}q\x02(X\x04\x00\x00\x00nameq\x03X\x04\x00\x00\x00alexq\x04X\x03\x00\x00\x00ageq\x05KPub.'
{'name': 'alex', 'age': 80} 将对象a写入文件:
import pickle
class A:
def __init__(self,name,age):
self.name=name
self.age=age
a = A('alex',80)
f = open('a','wb')
obj = pickle.dump(a,f)
f.close() 执行结果:
也是一堆乱码
假设是一款Python游戏,就可以将人物的属性,写入文件。再次登陆时,就可以重新加载了,用pickle就比较方便了。
当删除一个类的时候(注释代码),再次读取文件,就会报错
import pickle
# class A:
# def __init__(self,name,age):
# self.name=name
# self.age=age
# a = A('alex',80)
f = open('a','rb')
obj = pickle.load(f)
print(obj.__dict__)
f.close() 执行报错 AttributeError: Can't get attribute 'A' on <module '__main__' from 'E:/python_script/day25/test.py'>
提示找不到类A
将对象反序列时,必须保证该对象的类必须存在,否则读取报错
再次打开注释,执行以下,就正常了
九、shelve模块
Shelve是对象持久化保存方法,将对象保存到文件里面,缺省(即默认)的数据存储文件是二进制的。可以作为一个简单的数据存储方案。
注意shelve模块中的key键必须是字符串形式,value可以是任意值。会同时打开三个文件。
使用方法:
1、shelve.open(filename, flag=’c’, protocol=None, writeback=False): 创建或打开一个shelve对象。shelve默认打开方式支持同时读写操作。
filename是关联的文件路径。
可选参数flag:
1、默认为‘c’:如果数据文件不存在,就创建,允许读写;可以是: ‘r’: 只读;’w’: 可读写;
2、可以为‘n’: 每次调用open()都重新创建一个空的文件,可读写。
protocol:是序列化模式,默认值为None。具体还没有尝试过,从pickle的资料中查到以下信息【protocol的值可以是1或2,表示以二进制的形式序列化】
2、shelve.close() # 同步并关闭shelve对象,注意每次使用完毕后都要关闭shelve对象,同样可以使用with语句。
with shelve.open('spam') as db:
db['eggs'] = 'eggs'
with语句
3、writeback:默认为False。当设置为True以后,shelf将会将所有从DB中读取的对象存放到一个内存缓存。
当我们close()打开的shelf的时候,缓存中所有的对象会被重新写入DB。writeback方式有优点也有缺点(减少出错率,但是会增加内存开销)。
代码示范:
# 1.创建一个shelf对象,直接使用open函数即可 import shelve
s = shelve.open('test_shelf.db') #
try:
s['kk'] = {'int': 10, 'float': 9.5, 'String': 'Sample data'}
s['MM'] = [1, 2, 3]
finally:
s.close() # 2.如果想要再次访问这个shelf,只需要再次shelve.open()就可以了,然后我们可以像使用字典一样来使用这个shelf import shelve
try:
s = shelve.open('test_shelf.db')
value = s['kk']
print(value)
finally:
s.close() # 3.对shelf对象,增、删、改操作 import shelve
s = shelve.open('test_shelf.db', flag='w', writeback=True)
try:
# 增加
s['QQQ'] = 2333
# 删除
del s['MM']
# 修改
s['kk'] = {'String': 'day day up'}
finally:
s.close() # 注意:flag设置为‘r’-只读模式,当程序试图去修改一个以只读方式打开的DB时,将会抛一个访问错误的异常。异常的具体类型取决于anydbm这个模块在创建DB时所选用的DB。异常举例:anydbm.error: need ‘c’ or ‘n’ flag to open new db # 4.循环遍历shelf对象 import shelve
s = shelve.open('test_shelf.db')
try:
# 方法一:
for item in s.items():
print ('键[{}] = 值[{}]'.format(item[0], s[item[0]]))
# 方法二:
for key, value in s.items():
print(key, value)
finally:
s.close() # 5.备注一个错误:
# open中的参数filename,起初认为需要手动新建一个.db,或者.dat的文件,目前电脑中无任何真正的数据库文件,所以采用了新建txt文件,修改后缀的方法创建.db,或者.dat的文件。
# 解释器报错,提示内容为:"anydbm.error: db type could not be determined",
# 原因是是filename已经存在,并且格式与shelve不符,所以提示 “db type could not be determined”。
# 解决方法是,删除该文件。首次运行后会自动生成该filename文件。
# 6.稍微复杂些的案例,实现一个简单提问式的数据库
shelve模块代码示例
总结:
1、shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;
2、key必须为字符串,而值可以是python所支持的数据类型
3、shelve模块(**)------可以当做数据库用,以后基本不会用,(可以很方面的往文件中写数据类型和读)
import shelve #存取很方便(可以做一个简单的数据存储方案)
f=shelve.open(r'sheve.txt')
f['stu1_info']={'name':'egon','age':18,'hobby':['piao','smoking','drinking']} #存
f['stu2_info']={'name':'gangdan','age':53}
f['school_info']={'website':'http://www.pypy.org','city':'beijing'}
print(f['stu1_info']['hobby'])
f.close() import shelve
d=shelve.open(r'a.txt') #生成三个文件分别是:a.txt.bak\a.txt.dat\a.txt.dir
d['tom']={'age':18,'sex':'male'} #存的时候会生成三个文件,不用管,是python的一种处理机制
print(d['tom']['sex']) #可以取出字典中的key对应的value
print(d['tom']) #取出tom对应的字典
d.close() import shelve
d=shelve.open(r'a.txt',writeback=True) #writeback=True,对子字典修改完后要写回,否则不会看到修改后的结果
d['egon']={'age':18,'sex':'male'} #存的时候会生成三个文件,不用管,是python的一种处理机制
d['egon']['age']=20 #将年龄修改为20
print(d['egon']['age']) #此时拿到的是修改后的年龄
print(d['egon']['sex'])
d.close()
time、random以及序列化模块的更多相关文章
- random os 序列化 模块模块 随机选择
# 1 random 模块 随机选择# import random#随机取小数# ret = random.random() #空是0到1之间的小数字# print(ret)# # 0.0799728 ...
- python常用模块(模块和包的解释,time模块,sys模块,random模块,os模块,json和pickle序列化模块)
1.1模块 什么是模块: 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文 ...
- python常用模块: random模块, time模块, sys模块, os模块, 序列化模块
一. random模块 import random # 任意小数 print(random.random()) # 0到1的任意小数 print(random.uniform(-10, 10)) # ...
- 模块—— 序列化模块、random模块、os模块 、 sys模块、hashlib模块、collections模块
今天我们来说说Python中的模块: 第三方模块 可以下载/安装/使用 第一步:将pip.exe 所在的目录添加到环境变量中第二步:输入pip第三步:pip install 要安装的模块名称 #pi ...
- python time,random,os,sys,序列化模块
一.time模块 表示时间的三种方式 在Python中,通常有这三种方式来表示时间:时间戳.元组(struct_time).格式化的时间字符串: (1)时间戳(timestamp) :通常来说,时间戳 ...
- time,random,os,sys,序列化模块
一.time模块 表示时间的三种方式 在Python中,通常有这三种方式来表示时间:时间戳.元组(struct_time).格式化的时间字符串: (1)时间戳(timestamp) :通常来说,时间戳 ...
- Python之常用模块(re,时间,random,os,sys,序列化模块)(Day20)
一.时间模块 #常用方法 1.time.sleep(secs) (线程)推迟指定的时间运行.单位为秒. 2.time.time() 获取当前时间戳 在Python中表示时间的三种方式:时间戳,元组(s ...
- 常用模块random,time,os,sys,序列化模块
一丶random模块 取随机数的模块 #导入random模块 import random #取随机小数: r = random.random() #取大于零且小于一之间的小数 print(r) #0. ...
- 2019-7-18 collections,time,random,os,sys,序列化模块(json和pickle)应用
一.collections模块 1.具名元组:namedtuple(生成可以使用名字来访问元素的tuple) 表示坐标点x为1 y为2的坐标 注意:第二个参数可以传可迭代对象,也可以传字符串,但是字 ...
随机推荐
- 02-26C#三级省市区ajax联动控件,利用UpdatePanel,以及页面取值
第一步:设置界面 <%@ Control Language="C#" AutoEventWireup="true" CodeFile="PCAC ...
- Oracle11gr2_ADG管理之跳归档恢复dg实战
模拟故障 关闭备库 SQL> shutdown immediate; Database closed. Database dismounted. ORACLE instance shut dow ...
- Linux下zip格式文件的解压缩和压缩
Linux下zip格式文件的解压缩和压缩 Linux下的软件包很多都是压缩包,软件的安装就是解压缩对应的压缩包.所以,就需要熟练使用常用的压缩命令和解压缩命令.最常用的压缩格式有.tar.gz/tgz ...
- Java多线程-线程的同步(同步代码块)
对于同步,除了同步方法外,还可以使用同步代码块,有时候同步代码块会带来比同步方法更好的效果. 追其同步的根本的目的,是控制竞争资源的正确的访问,因此只要在访问竞争资源的时候保证同一时刻只能一个线程访问 ...
- 基于jquery 的插件,让IE支持placeholder属性
开发一个项目的时候为了美观和用户体验用到了input标签的placeholder属性,但是这个属性是html5中的,所以低版本的IE浏览器不支持.于是在百度找了一些解决方法,找了好几个都不是那么完美, ...
- 【转】http 缓存
原文地址:https://developers.google.com/web/fundamentals/performance/optimizing-content-efficiency/http-c ...
- linq to object 未完待续
1.linq to string string s2 = "abc"; var data2 = s2.Where(x => x.CompareTo('a') > 0). ...
- 第八课 ROS的空间描述和变换
1.tf的实际应用 1)在机器人的配置中 从上面可以看出激光雷达中心距离机器人底座的中心有20cm,激光雷达的中心距机器人底座中心有10cm,如果激光雷达在障碍物前面0.3米,那么机器人底座离障碍物多 ...
- 循环删除DataTable.Row中的多行问题
在C#中,如果要删除DataTable中的某一行,大约有以下几种办法: 1,使用DataTable.Rows.Remove(DataRow),或者DataTable.Rows.RemoveAt(ind ...
- C# 世界坐标 页面坐标 PageUnit PageScale
PageScale: 获取或设置此 Graphics 的世界单位和页单位之间的比例.PageUnit: 获取或设置用于此 Graphics 中的页坐标的度量单位. 话不多说,上代码: privat ...