python中常用模块详解一
1.time 模块
- import time
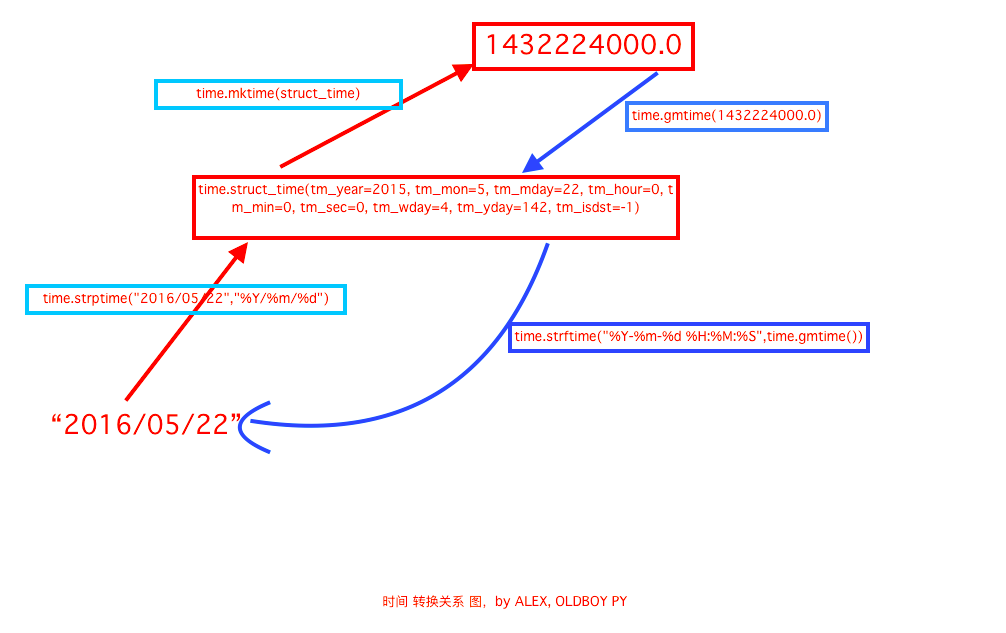
- s = time.localtime() # 把时间转化成格式化的时间,通过. 取得里面的年月日等 struct_time 格式
- time.struct_time(tm_year=2018, tm_mon=3, tm_mday=11, tm_hour=19, tm_min=53, tm_sec=31, tm_wday=6, tm_yday=70, tm_isdst=0)
- s=time.gmtime() #UTC 时区
- s=time.time() # 返回当前时间戳
- print(time.asctime()) #接收struct_time 转化成Sun Mar 11 19:46:08 2018 不传默认当前的时间
- print(time.ctime(0)) #返回当前的时间Sun Mar 11 19:46:08 2018 默认当前时间
- 传入时间戳格式数字的话 转化成时间戳日期Thu Jan 1 08:00:00 1970
- print(time.strftime("%Y-%m-%d", time.localtime())) # 传入的是struct_time 格式的时间格式 转换成自己定义的时间格式
- print(time.strptime("2017-12-12", "%Y-%m-%d")) # 把字符串格式转化成struct_time格式
2.datetime模块
- import datetime
- s=datetime.datetime.now() #(2018-03-11 20:19:10.993661)
- s下面好多方法 year mouth day date()=2018-03-11 ctime()=Sun Mar 11 19:46:08 2018 strftime("%Y-%m-%d")
- print(datetime.date.fromtimestamp(time.time())) # 把一个时间戳转换成2018-03-11
- # ############
- # 主要是时间的运算
- s = datetime.datetime.now()
- print(s.timetuple()) # time.struct_time(tm_year=2018, tm_mon=3, tm_mday=11, tm_hour=20,
- # tm_min=19, tm_sec=9, tm_wday=6, tm_yday=70, tm_isdst=-1)
- print(s + datetime.timedelta(seconds=1)) # 实现运算的作用 后面跟 day hours seconds
- d = datetime.datetime.now()
- t = d.replace(year=2016) #修改时间并且返回修改后的时间 ,被修改的时间不变
- print(t)
3.random模块的使用
- import random
- print(random.randint(1, 200)) # 随机 生成1-200之间的数字 包含200
- print(random.randrange(1, 200, 2)) # 随机生成1-200(偶数) 不包含200
- print(random.random()) # 0-1 的小数
- print(random.choice("dasdadsasdad")) # 随机挑选一个字符串的字符
- print(random.sample("adasdasdasdad",5)) #在字符串中随机挑选5个字符组成列表
- #实现验证码
- import string
- print(string.ascii_letters) #大小写包含
- print(string.hexdigits) #十六位进制
- print(string.digits)#十进制
- s_list=random.sample(string.ascii_letters + string.digits,4)
- s=''.join(s_list)
- print(s)
- list_all=[i for i in range(80)] # # a='dasdasdasd' #不能是字符串 # random.shuffle(list_all) # 重新洗牌 使在原来的列表中生效 # print(list_all)
- os 模块提供了很多允许你的程序与操作系统直接交互的功能
- # os 模块提供了很多允许你的程序与操作系统直接交互的功能
- import os
- BASE_DIR = os.path.abspath(__file__) # 返回文件的据对路径
- os.listdir(".") # 列出指定文件夹下的目录
- os.path.join('aaa', 'aaa') # 把路径拼接
- os.path.dirname(BASE_DIR) # 返回目录路径不包含文件
- os.path.split(BASE_DIR) # 返回文件名和路径组成的列表
- os.path.exists(BASE_DIR) # 判断path是否存在
- os.path.isfile(BASE_DIR) # 判断文件是否存在
- os.path.isdir(BASE_DIR) # 判断是否是一个目录
- os.path.splitext(BASE_DIR)
- os.path.basename(BASE_DIR) # 获取文件名
- os.path.getsize(BASE_DIR) # 获取文件大小 ********常用
- 5.SYS模块的使用
- sys.argv 命令行参数List,第一个元素是程序本身路径
- sys.exit(n) 退出程序,正常退出时exit(0)
- sys.version 获取Python解释程序的版本信息
- sys.maxint 最大的Int值
- sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
- sys.platform 返回操作系统平台名称
- sys.stdout.write('please:') #标准输出 , 引出进度条的例子, 注,在py3上不行,可以用print代替
- val = sys.stdin.readline()[:-1] #标准输入
- sys.getrecursionlimit() #获取最大递归层数
- sys.setrecursionlimit(1200) #设置最大递归层数
- sys.getdefaultencoding() #获取解释器默认编码
- sys.getfilesystemencoding #获取内存数据存到文件里的默认编码
json & pickle 模块 python 的序列化与反序列化的模块,用于程序之间的交互。
- json 的有点就是跨平台 不同语言都支持json 确定就是支持的种类不多str int list tuple dict
json.loads()传可被json的文件类型json转化成字符串 json.load() json.dumps() json.dump()
pickle只可以在python里面使用 支持python的数据类型 ,占用体积比较大
- import json
- import pickle
- # json 的有点就是跨平台 不同语言都支持json 确定就是支持的种类不多str int list tuple dict
- # json.loads()传可被json的文件类型json转化成字符串 json.load() json.dumps() json.dump()
- # pickle只可以在python里面使用 支持python的数据类型 ,占用体积比较大
- d = {1: 2, 3: 4}
- l = ["name", "age"]
- s = json.dumps(d) # 把字典等格式转化成字符串
- print(s)
- d1 = json.loads(s) # 把字符串转换成字典形式
- print(d1)
- f = open("test.json", 'w') # 把字典等形式存在文件的变成字符串转换成字符
- json.dump(d, f)
- f.close()
- f = open("test.json", 'r') # 从文件里读出来 转化成字符串
- d2 = json.load(f)
- # pickle 也是这样的形式 只是上传的时候文件储存的是以pickle的形式保存在文件里
shutil模块 该模块用于文件的copy与压缩 ,主要用于文件的打包、移动、等功能。
- import shutil
- # 拷贝文件 前提是文件必须打开 传的是句柄
- shutil.copyfileobj(open("Log.py", "r"), open("Log_new.py", "w"))
- # 拷贝文件 封装了打开文件 只需要传文件名(不是目录名)
- shutil.copyfile("Log.py", "log_new.py")
- shutil.copymode("Log.py", "lll.py") # 仅拷贝权限,目标文件必须存在
- shutil.copy("Log.py", "lll.py") # 拷贝文件和权限
- shutil.copy2("Log.py", "lll.py") # 拷贝文件和状态
- # 拷贝目录 必须是目录
- shutil.copytree("../FTP", "ftp", ignore=shutil.ignore_patterns("__init__.py"))
- # 递归的拷贝文件,有个参数ignore=shutil.ignore_patterns("__init__.py")忽略的文件
- shutil.rmtree("log_new.y") # 删除目录 文件不行的
- shutil.move("log_new.y", "ll.py") # 移动文件,或者重命名
- shutil.make_archive(base_name="log_l", format="zip", root_dir="../FTP") # 压缩文件
- # base_name 指定压缩的路径 最后面跟压缩文件名,format= 压缩格式"zip", "tar", "bztar","gztar"
- # root_dir 要压缩的文件路径(目录) owner 用户名 group 组名
模块xlrd,读取excel表格的模块xlrd 外部模块 需要pip 安装 只可以读取excle
其他Excel写入修改模块请链接 http://blog.csdn.net/yankaiwei120/article/details/52204427
- import xlrd
- # 解析xls表格文件的模块 用xlrd 写入用xlwd
- Book = xlrd.open_workbook(r"C:\Users\zhuangjie23261\Desktop\风控文档.xls") # 打开文件返回一个book对象
- sheet = Book.sheets() # 返回指定的sheet的对象形成一个列表
- num = Book.nsheets # 返回文件的sheet的 个数
- Book.sheet_by_index(1) # 返回指定的索引值的sheet 页的名称
- Book.sheet_names() # 返回所有sheet页的名称
- Book.sheet_by_name() # 根据名称返回sheet页对象
- Book.sheet_loaded() # 根据指定的索引或者名称 来判断是否有 没有则报错
- sheet.name # 返回sheet的名称
- sheet.nrows # 返回sheet页的行数 -----行
- sheet.ncols # 返回sheet页的列数 | 列
- sheet.row(
- 1) # 获取指定的行 组成一个Cell_lisy列表[number:20100805.0, text:'O32_20100430sp2', text:'E类风控资产类别', text:'添加N-网下申购预估中签资产(公开发行)', empty:'', text:'胡育东']
- sheet.row_values(1) # 指定行的列表 [20100805.0, 'O32_20100430sp2', 'E类风控资产类别', '添加N-网下申购预估中签资产(公开发行)', '', '胡育东']
- sheet.col(1) # 获取指定的列 的cell_list
- sheet.col_values(1) # 指定列的list
- cell = sheet.cell(1, 2) # 根据位置获取Cell对象。
- sheet.cell_value(1, 2) # 根据位置获取Cell对象的值。
- print(cell.value) # 获取cell 的值
- # 打印每张表的第一列
- for s in sheet:
- print(s.name) # 获取每个sheet页
- for i in range(s.nrows): # s.nrows 每个sheet页 有多少行 s.row(i) 这个是返回每一行的一个列表-1 代表最后一个 value代表文本值
- print(s.row(i)[0].value)
解析xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
- import xml.etree.ElementTree as ET
- tree = ET.parse("test.xml")
- root = tree.getroot()
- print(root.tag) # tag > <data>这种属性的表头
- for child in root:
- print(child.tag, child.attrib) # attrib <>里面的属性 组成一个字典
- for i in child:
- print(i.tag, i.text) # <>text<> 文本内容
- for year in root.iter("year"): # iter()相当于一个筛选器 筛选 <>里面的属性
- print(year.text)
- # *****************************************
- # 对xml 修改
- for year in root.iter("year"):
- new_year = int(year.text) + 1
- year.text = str(new_year) # 转换成字符串的格式 写入
- year.set("updated", "yes") # set格式类型 updated yes 说明 更新
- tree.write("test.xml")
- #对xml 节点的删除
- for country in root.findall("country"): # 节点就是node 遍历查找root 下面全部country的节点
- rank = country.find("rank").text # 再查找到的每一个country下的rank 节点打印text
- rank = int(rank) # 把str转化成int
- if rank < 60:
- country.remove(country.find("rank")) # 这样是移除country 下的节点rank 也可以直接remove这个country 这个大的节点
- tree.write("new_test.xml") #把生成的写入新文件
- # ***************************************
- new_xml = ET.Element("namelist") # 生成一个xml的根节点最外层节点
- name = ET.SubElement(new_xml, "name", attrib={"data": "2017-11"}) # 生成最外层节点之下的一个节点name
- age = ET.SubElement(name, "age") # 在name 这个节点之下再生成两个节点 age,sex
- sex = ET.SubElement(name, "sex") # sex
- age.text = "33"
- sex.text = "男"
- # 给 age设置数字必须是字符
- # 这里还可以加多个节点
- name2 = ET.SubElement(new_xml, "name", attrib={"data": "2018-11"}) # 生成最外层节点之下的一个节点name
- age = ET.SubElement(name2, "age") # 在name 这个节点之下再生成两个节点 age,sex
- sex = ET.SubElement(name2, "sex") # 如果没有设置text 则会显示一个标签
- age.text = "33"
- #*********************************************
- et = ET.ElementTree(new_xml) # 这一步是把上面的设置好的格式转化成xml的文档
- et.write("new_xml.xml", encoding="utf8", xml_declaration=True) # 写入 文件
- ET.dump(new_xml) # 打印写入的文件格式
configparser读取配置文件与对配置文件修改
- import configparser
- """
- [DEFAULT]
- ServerAliveInterval = 45
- Compression = yes
- CompressionLevel = 9
- ForwardX11 = yes
- [bitbucket.org]
- User = hg
- [topsecret.server.com]
- Port = 50022
- ForwardX11 = no
- ***************
- [group2]
- k1 = v1
- [group3]
- k1 = v1
- """
- # 解析
- conf = configparser.ConfigParser()
- conf.read("conf_new.ini") # 打开配置文件
- sec_list = conf.sections() # 获取文件的sections ["DEFAULT"] 不打印
- s = conf["bitbucket.org"]["User"] # 打印节点section下的User 的文本
- for v in conf["topsecret.server.com"]:
- print(v) # 打印 topsecret.server.com 下的节点名称 默认也打印default下的节点
- # 查询
- opt = conf.options("bitbucket.org") # 查找指定节点下的对用的key值
- print(opt)
- item = conf.items("bitbucket.org") # 返回 key value 对应的元祖
- print(item)
- val = conf.get("bitbucket.org", "compression") # group>[] key>k1:v1
- val=conf.getint("topsecret.server.com", "Port") # 获得的值是int值
- print(val)
- # 增删
- conf.read("conf_new.ini") # 打开配置文件
- conf.remove_section("group1") # 删除节点group1
- conf.add_section("group3") # 添加节点group3
- conf.remove_option("group3", "k1") # 删除 option 先写组[] 然后填key
- print(conf.has_section("group1")) # 判断有没有这个组
- conf.set("group3", "k1", "v1") # 设置配置
- conf.write(open("conf_new.ini", 'w')) # 写入文件必须是打开的文件 说白了就是传入文件句柄
python中常用模块详解一的更多相关文章
- python中常用模块详解二
log模块的讲解 Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适: logger提供了应用程序可以直接使用的接口API: handler将(logger创建的 ...
- Python中time模块详解
Python中time模块详解 在平常的代码中,我们常常需要与时间打交道.在Python中,与时间处理有关的模块就包括:time,datetime以及calendar.这篇文章,主要讲解time模块. ...
- python中threading模块详解(一)
python中threading模块详解(一) 来源 http://blog.chinaunix.net/uid-27571599-id-3484048.html threading提供了一个比thr ...
- ansible中常用模块详解
ansible中常用的模块详解: file模块 ansible内置的可以查看模块用法的命令如下: [root@docker5 ~]# ansible-doc -s file - name: Sets ...
- python中socket模块详解
socket模块简介 网络上的两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一个socket.socket通常被叫做"套接字",用于描述IP地址和端口,是一个通信 ...
- Python中time模块详解(转)
在平常的代码中,我们常常需要与时间打交道.在Python中,与时间处理有关的模块就包括:time,datetime以及calendar.这篇文章,主要讲解time模块. 在开始之前,首先要说明这几点: ...
- Python中pymysql模块详解
安装 pip install pymysql 使用操作 执行SQL #!/usr/bin/env pytho # -*- coding:utf-8 -*- import pymysql # 创建连接 ...
- (转)python标准库中socket模块详解
python标准库中socket模块详解 socket模块简介 原文:http://www.lybbn.cn/data/datas.php?yw=71 网络上的两个程序通过一个双向的通信连接实现数据的 ...
- Python的logging模块详解
Python的logging模块详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.日志级别 日志级别指的是产生的日志的事件的严重程度. 设置一个级别后,严重程度 ...
随机推荐
- Python subplot 绘画
环境 Anaconda3 Python 3.6, Window 64bit 目的 利用 matplotlib 画图模块,汇至子图 # -*- coding: utf-8 -*- import matp ...
- spring3: Aspectj后置返回通知
Aspectj后置返回通知 接口: package chapter1.server; public interface IHelloService2 { public int sayAfterRetu ...
- RabbitMQ C# driver stops receiving messages
http://stackoverflow.com/questions/12499174/rabbitmq-c-sharp-driver-stops-receiving-messages
- java项目生成jar,并在cmd中执行jar
自己写的jar并使用:============Java项目============Jar包的打包在Eclipse中直接打包,具体步骤: 点击右键>export>jar file>取消 ...
- 百度之星2017初赛A-1005-今夕何夕
今夕何夕 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submis ...
- 【Java】final关键字
1.final数据 (1)基本类型 数值恒定不变 (2)对象引用 引用恒定不变,初始化的时候指向一个对象后,无法改变为另一个对象,但是对象本身可以修改 2.final方法 可以把方 ...
- shell编程学习2
1.shell中调用linux命令(1)直接执行(2)反引号括起来执行.有时候我们在shell中调用linux命令是为了得到这个命令的返回值(结果值),这时候就适合用一对反引号(键盘上ESC按键下面的 ...
- 条款25:考虑写出一个不抛出异常的swap函数
首先说下标准库的swap算法: namespace std{ template<typename T> void swap(T & a, T & b) { T tmp = ...
- 《锋利的jQuery》读书笔记(动画)
1.show()和hide() 实质就是改变当前DOM对象的display为block.none或inline-block(取决于之前的display),如下: $("element&quo ...
- Java IO流读写文件的几个注意点
平时写IO相关代码机会挺少的,但却都知道使用BufferedXXXX来读写效率高,没想到里面还有这么多陷阱,这两天突然被其中一个陷阱折腾一下:读一个文件,然后写到另外一个文件,前后两个文件居然不 ...