Avro之一:Avro简介
一、引言
1、 简介
Avro是Hadoop中的一个子项目,也是Apache中一个独立的项目,Avro是一个基于二进制数据传输高性能的中间件。在Hadoop的其他项目中例如HBase(Ref)和Hive(Ref)的Client端与服务端的数据传输也采用了这个工具。Avro是一个数据序列化的系统。Avro 可以将数据结构或对象转化成便于存储或传输的格式。Avro设计之初就用来支持数据密集型应用,适合于远程或本地大规模数据的存储和交换。
2、 特点
Ø 丰富的数据结构类型;
Ø 快速可压缩的二进制数据形式,对数据二进制序列化后可以节约数据存储空间和网络传输带宽;
Ø 存储持久数据的文件容器;
Ø 可以实现远程过程调用RPC;
Ø 简单的动态语言结合功能。
avro支持跨编程语言实现(C, C++, C#,Java, Python, Ruby, PHP),类似于Thrift,但是avro的显著特征是:avro依赖于模式,动态加载相关数据的模式,Avro数据的读写操作很频繁,而这些操作使用的都是模式,这样就减少写入每个数据文件的开销,使得序列化快速而又轻巧。这种数据及其模式的自我描述方便了动态脚本语言的使用。当Avro数据存储到文件中时,它的模式也随之存储,这样任何程序都可以对文件进行处理。如果读取数据时使用的模式与写入数据时使用的模式不同,也很容易解决,因为读取和写入的模式都是已知的。
|
New schema |
Writer |
Reader |
Action |
|
Added field |
Old |
New |
The reader uses the default value of the new field, since it is not written by the writer. |
|
New |
Old |
The reader does not know about the new field written by the writer, so it is ignored (projection). |
|
|
Removed field |
Old |
New |
The reader ignores the removed field (projection). |
|
New |
Old |
The removed field is not written by the writer. If the old schema had a default defined for the field, the reader uses this; otherwise, it gets an error. In this case, it is best to update the reader’s schema, either at the same time as or before the writer’s. |
Avro和动态语言结合后,读/写数据文件和使用RPC协议都不需要生成代码,而代码生成作为一种可选的优化只需要在静态类型语言中实现。
Avro依赖于模式(Schema)。通过模式定义各种数据结构,只有确定了模式才能对数据进行解释,所以在数据的序列化和反序列化之前,必须先确定模式的结构。正是模式的引入,使得数据具有了自描述的功能,同时能够实现动态加载,另外与其他的数据序列化系统如Thrift相比,数据之间不存在其他的任何标识,有利于提高数据处理的效率。
二、技术要领
1、 类型
数据类型标准化的意义:一方面使不同系统对相同的数据能够正确解析,另一方面,数据类型的标准定义有利于数据序列化/反序列化。
简单的数据类型:Avro定义了几种简单数据类型,下表是其简单说明:
|
类型 |
说明 |
|
null |
no value |
|
boolean |
a binary value |
|
int |
32-bit signed integer |
|
long |
64-bit signed integer |
|
float |
single precision (32-bit) IEEE 754 floating-point number |
|
double |
double precision (64-bit) IEEE 754 floating-point number |
|
bytes |
sequence of 8-bit unsigned bytes |
|
string |
unicode character sequence |
简单数据类型由类型名称定义,不包含属性信息,例如字符串定义如下:
{"type": "string"}
复杂数据类型:Avro定义了六种复杂数据类型,每一种复杂数据类型都具有独特的属性,下表就每一种复杂数据类型进行说明。
|
类型 |
属性 |
说明 |
|
Records |
type name |
record |
|
name |
a JSON string providing the name of the record (required). |
|
|
namespace |
a JSON string that qualifies the name(optional). |
|
|
doc |
a JSON string providing documentation to the user of this schema (optional). |
|
|
aliases |
a JSON array of strings, providing alternate names for this record (optional). |
|
|
fields |
a JSON array, listing fields (required). |
|
|
name |
a JSON string. |
|
|
type |
a schema/a string of defined record. |
|
|
default |
a default value for field when lack. |
|
|
order |
ordering of this field. |
|
|
Enums |
type name |
enum |
|
name |
a JSON string providing the name of the enum (required). |
|
|
namespace |
a JSON string that qualifies the name. |
|
|
doc |
a JSON string providing documentation to the user of this schema (optional). |
|
|
aliases |
a JSON array of strings, providing alternate names for this enum (optional) |
|
|
symbols |
a JSON array, listing symbols, as JSON strings (required). All symbols in an enum must be unique. |
|
|
Arrays |
type name |
array |
|
items |
the schema of the array’s items. |
|
|
Maps |
type name |
map |
|
values |
the schema of the map’s values. |
|
|
Fixed |
type name |
fixed |
|
name |
a string naming this fixed (required). |
|
|
namespace |
a string that qualifies the name. |
|
|
aliases |
a JSON array of strings, providing alternate names for this enum (optional). |
|
|
size |
an integer, specifying the number of bytes per value (required). |
|
|
Unions |
a JSON arrays |
每一种复杂数据类型都含有各自的一些属性,其中部分属性是必需的,部分是可选的。
这里需要说明Record类型中field属性的默认值,当Record Schema实例数据中某个field属性没有提供实例数据时,则由默认值提供,具体值见下表。Union的field默认值由Union定义中的第一个Schema决定。
|
avro type |
json type |
example |
|
null |
null |
null |
|
boolean |
boolean |
true |
|
int,long |
integer |
1 |
|
float,double |
number |
1.1 |
|
bytes |
string |
"\u00FF" |
|
string |
string |
"foo" |
|
record |
object |
{"a": 1} |
|
enum |
string |
"FOO" |
|
array |
array |
[1] |
|
map |
object |
{"a": 1} |
|
fixed |
string |
"\u00ff" |
2、 序列化/反序列化
Avro指定两种数据序列化编码方式:binary encoding 和Json encoding。使用二进制编码会高效序列化,并且序列化后得到的结果会比较小;而JSON一般用于调试系统或是基于WEB的应用。
binary encoding规则如下:
1、 简单数据类型
|
Type |
Encoding |
Example |
|
null |
Zero bytes |
Null |
|
boolean |
A single byte |
{true:1, false:0} |
|
int/long |
variable-length zig-zag coding |
|
|
float |
4 bytes |
Java's floatToIntBits |
|
double |
8 bytes |
Java's doubleToLongBits |
|
bytes |
a long followed by that many bytes of data |
|
|
string |
a long followed by that many bytes of UTF-8 encoded character data |
“foo”:{3,f,o,o} 06 66 6f 6f |
2、 复杂数据类型
|
Type |
encoding |
|
Records |
encoded just the concatenation of the encodings of its fields |
|
Enums |
a int representing the zero-based position of the symbol in the schema |
|
Arrays |
encoded as series of blocks. A block with count 0 indicates the end of the array. block:{long,items} |
|
Maps |
encoded as series of blocks. A block with count 0 indicates the end of the map. block:{long,key/value pairs}. |
|
Unions |
encoded by first writing a long value indicating the zero-based position within the union of the schema of its value. The value is then encoded per the indicated schema within the union. |
|
fixed |
encoded using number of bytes declared in the schema |
实例:
Ø records
{
"type":"record",
"name":"test",
"fields" : [
{"name": "a","type": "long"},
{"name": "b","type": "string"}
]
}
假设:a=27b=”foo” (encoding:36(27), 06(3), 66("f"), 6f("o"))
binary encoding:3606 66 6f 6f
Ø enums
{"type": "enum","name": "Foo", "symbols": ["A","B", "C", "D"] }
“D”(encoding: 06(3))
binary encoding: 06
Ø arrays
{"type": "array","items": "long"}
设:{3, 27 } (encoding:04(2), 06(3), 36(27) )
binary encoding:0406 36 00
Ø maps
设:{("a":1), ("b":2) } (encoding:61(“a”), 62(“b”), 02(1), 04(2))
binary encoding:0261 02 02 62 04
Ø unions
["string","null"]
设:(1)null; (2) “a”
binary encoding:
(1) 02;说明:02代表null在union定义中的位置1;
(2) 00 02 61;说明:00为string在union定义的位置,02 61为”a”的编码。
图1表示的是Avro本地序列化和反序列化的实例,它将用户定义的模式和具体的数据编码成二进制序列存储在对象容器文件中,例如用户定义了包含学号、姓名、院系和电话的学生模式,而Avro对其进行编码后存储在student.db文件中,其中存储数据的模式放在文件头的元数据中,这样读取的模式即使与写入的模式不同,也可以迅速地读出数据。假如另一个程序需要获取学生的姓名和电话,只需要定义包含姓名和电话的学生模式,然后用此模式去读取容器文件中的数据即可。

图表 1
3、 模式Schema
Schema通过JSON对象表示。Schema定义了简单数据类型和复杂数据类型,其中复杂数据类型包含不同属性。通过各种数据类型用户可以自定义丰富的数据结构。
Schema由下列JSON对象之一定义:
1. JSON字符串:命名
2. JSON对象:{“type”: “typeName” …attributes…}
3. JSON数组:Avro中Union的定义
举例:
{"namespace": "example.avro",
"type":"record",
"name":"User",
"fields": [
{"name":"name", "type": "string"},
{"name":"favorite_number", "type": ["int", "null"]},
{"name":"favorite_color", "type": ["string","null"]}
]
}
4、 排序
Avro为数据定义了一个标准的排列顺序。比较在很多时候是经常被使用到的对象之间的操作,标准定义可以进行方便有效的比较和排序。同时标准的定义可以方便对Avro的二进制编码数据直接进行排序而不需要反序列化。
只有当数据项包含相同的Schema的时候,数据之间的比较才有意义。数据的比较按照Schema深度优先,从左至右的顺序递归的进行。找到第一个不匹配即可终止比较。
两个拥有相同的模式的项的比较按照以下规则进行:
null:总是相等。
int,long,float:按照数值大小比较。
boolean:false在true之前。
string:按照字典序进行比较。
bytes,fixed:按照byte的字典序进行比较。
array:按照元素的字典序进行比较。
enum:按照符号在枚举中的位置比较。
record:按照域的字典序排序,如果指定了以下属性:
“ascending”,域值的顺序不变。
“descending”,域值的顺序颠倒。
“ignore”,排序的时候忽略域值。
map:不可进行比较。
5、 对象容器文件
Avro定义了一个简单的对象容器文件格式。一个文件对应一个模式,所有存储在文件中的对象都是根据模式写入的。对象按照块进行存储,块可以采用压缩的方式存储。为了在进行mapreduce处理的时候有效的切分文件,在块之间采用了同步记号。一个文件可以包含任意用户定义的元数据。
一个文件由两部分组成:文件头和一个或者多个文件数据块。
文件头:
Ø 四个字节,ASCII‘O’,‘b’,‘j’,1。
Ø 文件元数据,用于描述Schema。
Ø 16字节的文件同步记号。
Ø 其中,文件元数据的格式为:
i. 值为-1的长整型,表明这是一个元数据块。
ii. 标识块长度的长整型。
iii. 标识块中key/value对数目的长整型。
iv. 每一个key/value对的string key和bytesvalue。
v. 标识块中字节总数的4字节长的整数。
文件数据块:
数据是以块结构进行组织的,一个文件可以包含一个或者多个文件数据块。
Ø 表示文件中块中对象数目的长整型。
Ø 表示块中数据序列化后的字节数长度的长整型。
Ø 序列化的对象。
Ø 16字节的文件同步记号。
当数据块的长度为0时即为文件数据块的最后一个数据,此后的所有数据被自动忽略。
下图示对象容器文件的结构分解及说明:

一个存储文件由两部分组成:头信息(Header)和数据块(Data Block)。而头信息又由三部分构成:四个字节的前缀,文件Meta-data信息和随机生成的16字节同步标记符。Avro目前支持的Meta-data有两种:schema和codec。
codec表示对后面的文件数据块(File Data Block)采用何种压缩方式。Avro的实现都需要支持下面两种压缩方式:null(不压缩)和deflate(使用Deflate算法压缩数据块)。除了文档中认定的两种Meta-data,用户还可以自定义适用于自己的Meta-data。这里用long型来表示有多少个Meta-data数据对,也是让用户在实际应用中可以定义足够的Meta-data信息。对于每对Meta-data信息,都有一个string型的key(需要以“avro.” 为前缀)和二进制编码后的value。对于文件中头信息之后的每个数据块,有这样的结构:一个long值记录当前块有多少个对象,一个long值用于记录当前块经过压缩后的字节数,真正的序列化对象和16字节长度的同步标记符。由于对象可以组织成不同的块,使用时就可以不经过反序列化而对某个数据块进行操作。还可以由数据块数,对象数和同步标记符来定位损坏的块以确保数据完整性。
三、RPC实现
当在RPC中使用Avro时,服务器和客户端可以在握手连接时交换模式。服务器和客户端有彼此全部的模式,因此相同命名字段、缺失字段和多余字段等信息之间通信中需要处理的一致性问题就可以容易解决。如图2所示,协议中定义了用于传输的消息,消息使用框架后放入缓冲区中进行传输,由于传输的初始就交换了各自的协议定义,因此即使传输双方使用的协议不同所传输的数据也能够正确解析。

图表 2
Avro作为RPC框架来使用。客户端希望同服务器端交互时,就需要交换双方通信的协议,它类似于模式,需要双方来定义,在Avro中被称为消息(Message)。通信双方都必须保持这种协议,以便于解析从对方发送过来的数据,这也就是传说中的握手阶段。
消息从客户端发送到服务器端需要经过传输层(Transport Layer),它发送消息并接收服务器端的响应。到达传输层的数据就是二进制数据。通常以HTTP作为传输模型,数据以POST方式发送到对方去。在 Avro中,它的消息被封装成为一组缓冲区(Buffer),类似于下图的模型:

如上图,每个缓冲区以四个字节开头,中间是多个字节的缓冲数据,最后以一个空缓冲区结尾。这种机制的好处在于,发送端在发送数据时可以很方便地组装不同数据源的数据,接收方也可以将数据存入不同的存储区。还有,当往缓冲区中写数据时,大对象可以独占一个缓冲区,而不是与其它小对象混合存放,便于接收方方便地读取大对象。
对象容器文件是Avro的数据存储的具体实现,数据交换则由RPC服务提供,与对象容器文件类似,数据交换也完全依赖Schema,所以与Hadoop目前的RPC不同,Avro在数据交换之前需要通过握手过程先交换Schema。
1、 握手过程
握手的过程是确保Server和Client获得对方的Schema定义,从而使Server能够正确反序列化请求信息,Client能够正确反序列化响应信息。一般的,Server/Client会缓存最近使用到的一些协议格式,所以,大多数情况下,握手过程不需要交换整个Schema文本。
所有的RPC请求和响应处理都建立在已经完成握手的基础上。对于无状态的连接,所有的请求响应之前都附有一次握手过程;对于有状态的连接,一次握手完成,整个连接的生命期内都有效。
具体过程:
Client发起HandshakeRequest,其中含有Client本身SchemaHash值和对应Server端的Schema Hash值(clientHash!=null,clientProtocol=null, serverHash!=null)。如果本地缓存有serverHash值则直接填充,如果没有则通过猜测填充。
Server用如下之一HandshakeResponse响应Client请求:
(match=BOTH, serverProtocol=null,serverHash=null):当Client发送正确的serverHash值且Server缓存相应的clientHash。握手过程完成,之后的数据交换都遵守本次握手结果。
(match=CLIENT, serverProtocol!=null,serverHash!=null):当Server缓存有Client的Schema,但是Client请求中ServerHash值不正确。此时Server发送Server端的Schema数据和相应的Hash值,此次握手完成,之后的数据交换都遵守本次握手结果。
(match=NONE):当Client发送的ServerHash不正确且Server端没有Client Schema的缓存。这种情况下Client需要重新提交请求信息 (clientHash!=null,clientProtocol!=null, serverHash!=null),Server响应 (match=BOTH, serverProtocol=null,serverHash=null),此次握手过程完成,之后的数据交换都遵守本次握手结果。
握手过程使用的Schema结构如下示。
{
"type":"record",
"name":"HandshakeRequest","namespace":"org.apache.avro.ipc",
"fields":[
{"name":"clientHash", "type": {"type": "fixed","name": "MD5", "size": 16}},
{"name":"clientProtocol", "type": ["null","string"]},
{"name":"serverHash", "type": "MD5"},
{"name":"meta", "type": ["null", {"type":"map", "values": "bytes"}]}
]
}
{
"type":"record",
"name":"HandshakeResponse", "namespace":"org.apache.avro.ipc",
"fields":[
{"name":"match","type": {"type": "enum","name": "HandshakeMatch",
"symbols":["BOTH", "CLIENT", "NONE"]}},
{"name":"serverProtocol", "type": ["null","string"]},
{"name":"serverHash","type": ["null", {"type":"fixed", "name": "MD5", "size": 16}]},
{"name":"meta","type": ["null", {"type":"map", "values": "bytes"}]}
]
}
2、 消息帧格式
消息从客户端发送到服务器端需要经过传输层,它发送请求并接收服务器端的响应。到达传输层的数据就是二进制数据。通常以HTTP作为传输模型,数据以POST方式发送到对方去。在 Avro中消息首先分帧后被封装成为一组缓冲区(Buffer)。
数据帧的格式如下:
Ø 一系列Buffer:
1、4字节的Buffer长度
2、Buffer字节数据
Ø 长度为0的Buffer结束数据帧
3、 Call格式
一个调用由请求消息、结果响应消息或者错误消息组成。请求和响应包含可扩展的元数据,两种消息都按照之前提出的方法分帧。
调用的请求格式为:
Ø 请求元数据,一个类型值的映射。
Ø 消息名,一个Avro字符串。
Ø 消息参数。参数根据消息的请求定义序列化。
调用的响应格式为:
Ø 响应的元数据,一个类型值的映射。
Ø 一字节的错误标志位。
Ø 如果错误标志为false,响应消息,根据响应的模式序列化。
如果错误标志位true,错误消息,根据消息的错误联合模式序列化。
四、应用:
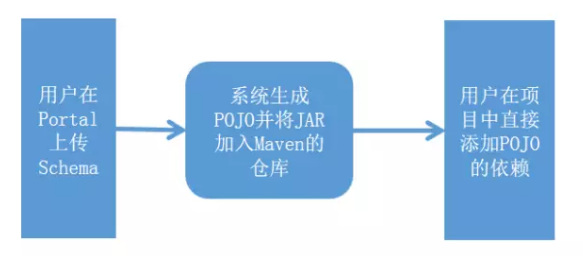
首先说说数据共享的问题,我们通常认为就是数据共享的前提是指用户要清晰的知道使用数据源的那个业务含义和其中数据的Schema,用户在一个集中的地方能够非常简单地看到这些信息;我们解决的方式是使用Avro的方式定义数据的Schema,并将这些信息放在一个统一的Portal站点上;数据的生产者创建Topic,然后上传Avro格式的Schema,系统会根据Avro的Schema生成Java类,并生成相应的JAR,把JAR加入Maven仓库;对于数据的使用者来说,他只需要在项目中直接加入依赖即可。
Avro之一:Avro简介的更多相关文章
- Hadoop基础-Apache Avro串行化的与反串行化
Hadoop基础-Apache Avro串行化的与反串行化 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Apache Avro简介 1>.Apache Avro的来源 ...
- Kafka Schema Registry | 学习Avro Schema
1.目标 在这个Kafka Schema Registry教程中,我们将了解Schema Registry是什么以及为什么我们应该将它与Apache Kafka一起使用.此外,我们将看到Avro架构演 ...
- Apache Avro:一个新的数据交换格式
原文: http://blog.cloudera.com/blog/2009/11/avro-a-new-format-for-data-interchange/ 注:由于个人英语能力有限,翻译不准确 ...
- Avro从入门到入土
avro官网 1.Avro历史 Avro是Hadoop的一个数据序列化系统,由Hadoop的创始人Doug Cutting(也是Lucene,Nutch等项目的创始人)开发,设计用于支持大批量数据交换 ...
- Avro介绍
Avro介绍 Apache Avro是一个数据序列化系统. Avro所提供的属性: 1.丰富的数据结构2.使用快速的压缩二进制数据格式3.提供容器文件用于持久化数据4.远程过程调用RPC5.简单的 ...
- Avro使用手册
1. Overview Data serialization is a technique of converting data into binary or text format. There a ...
- 一文解析Apache Avro数据
摘要:本文将演示如果序列化生成avro数据,并使用FlinkSQL进行解析. 本文分享自华为云社区<[技术分享]Apache Avro数据的序列化.反序列&&FlinkSQL解析 ...
- Apache Flume日志收集系统简介
Apache Flume是一个分布式.可靠.可用的系统,用于从大量不同的源有效地收集.聚合.移动大量日志数据进行集中式数据存储. Flume简介 Flume的核心是Agent,Agent中包含Sour ...
- Hive学习之路(一)—— Hive 简介及核心概念
一.简介 Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行. ...
- Hive 系列(一)—— Hive 简介及核心概念
一.简介 Hive 是一个构建在 Hadoop 之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类 SQL 查询功能,用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 ...
随机推荐
- JAR_给别人使用
1. http://zhidao.baidu.com/link?url=Ru2tGNV5iRsuRYlEdWzmKDRz88aYqHAqQBQy8sCaHWhjJpaJpbTGibEk-zyxegNJ ...
- 使用SpringMVC报错 Error creating bean with name 'conversionService' defined in class path resource [springmvc.xml]
使用SpringMVC报错 Error creating bean with name 'conversionService' defined in class path resource [spri ...
- css文本(教程)
1.text-transform --文本转换 定义文本的大小写状态,此属性对中文无意义 取值:capitalize | uppercase | lowercase | none | inherit ...
- Confluence 6 配置系统属性
在这个页面中描述 Confluence 启动时如何设置 Java 属性和其他选项. 请查看 How to fix out of memory errors by increasing availabl ...
- cf 814C 思维
http://codeforces.com/contest/814/problem/C 给定一个字符串s,长度小于1500,进行q次询问q<=20w,每次询问输入一个m和一个字符c,求将最多m个 ...
- day4-不同目录间模块的调用
1.前言 上文已经讲述了软件项目开发目录规范的若干事项,现在问题来了,我们遵循了项目目录设计规范,不同目录下设计了不同的函数和模块,怎么实现对这些模块的调用,使其为项目整体所用呢?本章节讲述的绝对路径 ...
- 【第13届景驰-埃森哲杯广东工业大学ACM程序设计大赛-F】等式(因子个数)
题目描述 给定n,求1/x + 1/y = 1/n (x<=y)的解数.(x.y.n均为正整数) 输入描述: 在第一行输入一个正整数T.接下来有T行,每行输入一个正整数n,请求出符合该方程要求的 ...
- Spring属性注入、构造方法注入、工厂注入以及注入参数(转)
Spring 是一个开源框架. Spring 为简化企业级应用开发而生(对比EJB2.0来说). 使用 Spring 可以使简单的 JavaBean 实现以前只有 EJB 才能实现的功能.Spring ...
- ZOJ 3211 Dream City(线性DP)
Dream City Time Limit: 1 Second Memory Limit: 32768 KB JAVAMAN is visiting Dream City and he se ...
- React typescript issue
多个输入框发生变化时,setState: this.setState({[e.target.name]: e.target.value} as componentState)