HDFS的介绍
设计思想
- 分而治之:将大文件、大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析;
- 在大数据系统中作用:为各类分布式运算框架(如:mapreduce,spark,tez,……)提供数据存储服务
- 重点概念:文件切块,副本存放,元数据
HDSF的重要特性
首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件
其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色;
重要特性如下:
(1)HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
(2)HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
(3)目录结构及文件分块信息(元数据)的管理由namenode节点承担
——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
(4)文件的各个block的存储管理由datanode节点承担
---- datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
(5)HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
(注:适合用来做数据分析,并不适合用来做网盘应用,因为,不便修改,延迟大,网络开销大,成本太高)
HDFS基本操作
HDFS提供shell命令行客户端,使用方法如下:
hadoop fs -ls /
HDFS客户端支持的命令参数
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] <path> ...]
[-cp [-f] [-p] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-usage [cmd ...]]
常用命令参数介绍
|
-help 功能:输出这个命令参数手册 |
|
-ls 功能:显示目录信息 示例: hadoop fs -ls hdfs://hadoop-server01:9000/ 备注:这些参数中,所有的hdfs路径都可以简写 -->hadoop fs -ls / 等同于上一条命令的效果 |
|
-mkdir 功能:在hdfs上创建目录 示例:hadoop fs -mkdir -p /aaa/bbb/cc/dd |
|
-moveFromLocal 功能:从本地剪切粘贴到hdfs 示例:hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd -moveToLocal 功能:从hdfs剪切粘贴到本地 示例:hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt |
|
--appendToFile 功能:追加一个文件到已经存在的文件末尾 示例:hadoop fs -appendToFile ./hello.txt hdfs://hadoop-server01:9000/hello.txt 可以简写为: Hadoop fs -appendToFile ./hello.txt /hello.txt |
|
-cat 功能:显示文件内容 示例:hadoop fs -cat /hello.txt -tail 功能:显示一个文件的末尾 示例:hadoop fs -tail /weblog/access_log.1 -text 功能:以字符形式打印一个文件的内容 示例:hadoop fs -text /weblog/access_log.1 |
|
-chgrp -chmod -chown 功能:linux文件系统中的用法一样,对文件所属权限 示例: hadoop fs -chmod 666 /hello.txt hadoop fs -chown someuser:somegrp /hello.txt |
|
-copyFromLocal 功能:从本地文件系统中拷贝文件到hdfs路径去 示例:hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/ -copyToLocal 功能:从hdfs拷贝到本地 示例:hadoop fs -copyToLocal /aaa/jdk.tar.gz |
|
-cp 功能:从hdfs的一个路径拷贝hdfs的另一个路径 示例: hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2 -mv 功能:在hdfs目录中移动文件 示例: hadoop fs -mv /aaa/jdk.tar.gz / |
|
-get 功能:等同于copyToLocal,就是从hdfs下载文件到本地 示例:hadoop fs -get /aaa/jdk.tar.gz -getmerge 功能:合并下载多个文件 示例:比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,... hadoop fs -getmerge /aaa/log.* ./log.sum |
|
-put 功能:等同于copyFromLocal 示例:hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2 |
|
-rm 功能:删除文件或文件夹 示例:hadoop fs -rm -r /aaa/bbb/ -rmdir 功能:删除空目录 示例:hadoop fs -rmdir /aaa/bbb/ccc |
|
-df 功能:统计文件系统的可用空间信息 示例:hadoop fs -df -h / -du 功能:统计文件夹的大小信息 示例: hadoop fs -du -s -h /aaa/* |
|
-count 功能:统计一个指定目录下的文件节点数量 示例:hadoop fs -count /aaa/ |
|
-setrep 功能:设置hdfs中文件的副本数量 示例:hadoop fs -setrep 3 /aaa/jdk.tar.gz |
HDFS的工作原理
概要
1. HDFS集群分为两大角色:NameNode、DataNode (Secondary Namenode)
2. NameNode负责管理整个文件系统的元数据
3. DataNode 负责管理用户的文件数据块
4. 文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上
5. 每一个文件块可以有多个副本,并存放在不同的datanode上
6. Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
7. HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
HDFS写数据流程
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode,
并由接收到block的datanode负责向其他datanode复制block的副本
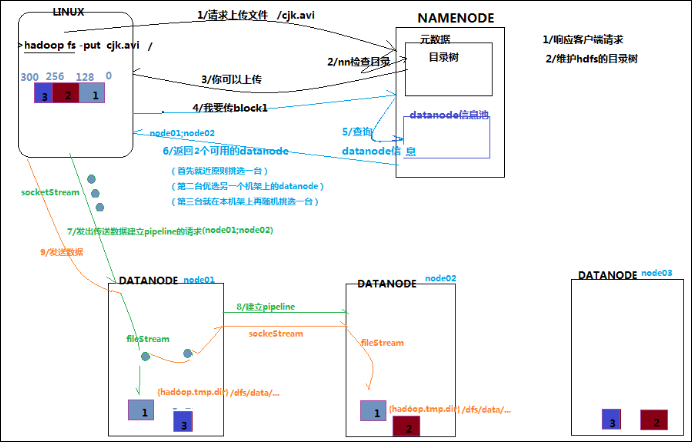
详细步骤解析
1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
HDFS读数据流程
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,
客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件
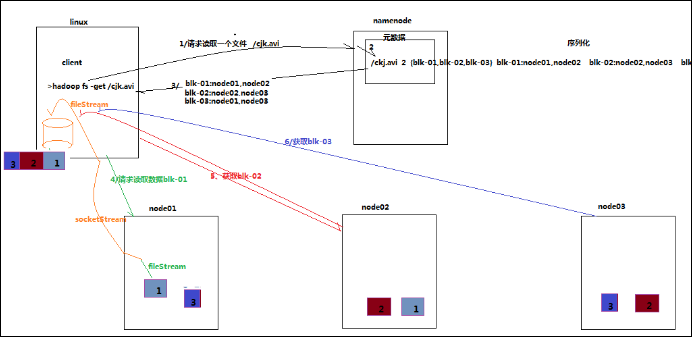
1、跟namenode通信查询元数据,找到文件块所在的datanode服务器
2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4、客户端以packet为单位接收,现在本地缓存,然后写入目标文件
NAMENODE工作机制
问题场景:
1、集群启动后,可以查看文件,但是上传文件时报错,打开web页面可看到namenode正处于safemode状态,怎么处理?
2、Namenode服务器的磁盘故障导致namenode宕机,如何挽救集群及数据?
3、Namenode是否可以有多个?namenode内存要配置多大?namenode跟集群数据存储能力有关系吗?
4、文件的blocksize究竟调大好还是调小好?
……
诸如此类问题的回答,都需要基于对namenode自身的工作原理的深刻理解
NAMENODE职责:
负责客户端请求的响应
元数据的管理(查询,修改)
元数据管理
namenode对数据的管理采用了三种存储形式:
内存元数据(NameSystem)
磁盘元数据镜像文件
数据操作日志文件(可通过日志运算出元数据)
元数据存储机制
A、内存中有一份完整的元数据(内存meta data)
B、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)
C、用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edits文件)注:当客户端对hdfs中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存meta.data中
元数据的checkpoint
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)
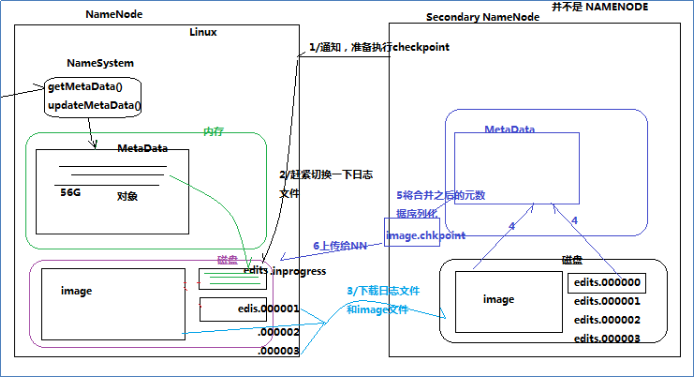
checkpoint操作的触发条件配置参数
dfs.namenode.checkpoint.check.period=60 #检查触发条件是否满足的频率,60秒
dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary
#以上两个参数做checkpoint操作时,secondary namenode的本地工作目录
dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir}
dfs.namenode.checkpoint.max-retries=3 #最大重试次数
dfs.namenode.checkpoint.period=3600 #两次checkpoint之间的时间间隔3600秒
dfs.namenode.checkpoint.txns=1000000 #两次checkpoint之间最大的操作记录
checkpoint的附带作用
namenode和secondary namenode的工作目录存储结构完全相同,所以,当namenode故障退出需要重新恢复时,
可以从secondary namenode的工作目录中将fsimage拷贝到namenode的工作目录,以恢复namenode的元数据
元数据目录说明
在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘:
|
$HADOOP_HOME/bin/hdfs namenode -format |
格式化完成之后,将会在$dfs.namenode.name.dir/current目录下如下的文件结构
|
current/ |-- VERSION |-- edits_* |-- fsimage_0000000000008547077 |-- fsimage_0000000000008547077.md5 `-- seen_txid |
其中的dfs.name.dir是在hdfs-site.xml文件中配置的,默认值如下:
|
<property> <name>dfs.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value> </property> hadoop.tmp.dir是在core-site.xml中配置的,默认值如下 <property> <name>hadoop.tmp.dir</name> <value>/tmp/hadoop-${user.name}</value> <description>A base for other temporary directories.</description> </property> |
dfs.namenode.name.dir属性可以配置多个目录,
如/data1/dfs/name,/data2/dfs/name,/data3/dfs/name,....。各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到Hadoop的元数据,特别是当其中一个目录是NFS(网络文件系统Network File System,NFS)之上,即使你这台机器损坏了,元数据也得到保存。
下面对$dfs.namenode.name.dir/current/目录下的文件进行解释。
1、VERSION文件是Java属性文件,内容大致如下:
|
#Fri Nov 15 19:47:46 CST 2013 namespaceID=934548976 clusterID=CID-cdff7d73-93cd-4783-9399-0a22e6dce196 cTime=0 storageType=NAME_NODE blockpoolID=BP-893790215-192.168.24.72-1383809616115 layoutVersion=-47 |
其中
(1)、namespaceID是文件系统的唯一标识符,在文件系统首次格式化之后生成的;
(2)、storageType说明这个文件存储的是什么进程的数据结构信息(如果是DataNode,storageType=DATA_NODE);
(3)、cTime表示NameNode存储时间的创建时间,由于我的NameNode没有更新过,所以这里的记录值为0,以后对NameNode升级之后,cTime将会记录更新时间戳;
(4)、layoutVersion表示HDFS永久性数据结构的版本信息, 只要数据结构变更,版本号也要递减,此时的HDFS也需要升级,否则磁盘仍旧是使用旧版本的数据结构,这会导致新版本的NameNode无法使用;
(5)、clusterID是系统生成或手动指定的集群ID,在-clusterid选项中可以使用它;如下说明
a、使用如下命令格式化一个Namenode:
$HADOOP_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]
选择一个唯一的cluster_id,并且这个cluster_id不能与环境中其他集群有冲突。如果没有提供cluster_id,则会自动生成一个唯一的ClusterID。
b、使用如下命令格式化其他Namenode:
$HADOOP_HOME/bin/hdfs namenode -format -clusterId <cluster_id>
c、升级集群至最新版本。在升级过程中需要提供一个ClusterID,例如:
$HADOOP_PREFIX_HOME/bin/hdfs start namenode --config $HADOOP_CONF_DIR -upgrade -clusterId <cluster_ID>
如果没有提供ClusterID,则会自动生成一个ClusterID。
(6)、blockpoolID:是针对每一个Namespace所对应的blockpool的ID,上面的这个BP-893790215-192.168.24.72-1383809616115就是在我的ns1的namespace下的存储块池的ID,这个ID包括了其对应的NameNode节点的ip地址。
2、$dfs.namenode.name.dir/current/seen_txid非常重要,是存放transactionId的文件,format之后是0,它代表的是namenode里面的edits_*文件的尾数,namenode重启的时候,会按照seen_txid的数字,循序从头跑edits_0000001~到seen_txid的数字。所以当你的hdfs发生异常重启的时候,一定要比对seen_txid内的数字是不是你edits最后的尾数,不然会发生建置namenode时metaData的资料有缺少,导致误删Datanode上多余Block的资讯。
3、$dfs.namenode.name.dir/current目录下在format的同时也会生成fsimage和edits文件,及其对应的md5校验文件。
补充:seen_txid
文件中记录的是edits滚动的序号,每次重启namenode时,namenode就知道要将哪些edits进行加载edits
DATANODE的工作机制
问题场景:
1、集群容量不够,怎么扩容?
2、如果有一些datanode宕机,该怎么办?
3、datanode明明已启动,但是集群中的可用datanode列表中就是没有,怎么办?
以上这类问题的解答,有赖于对datanode工作机制的深刻理解
Datanode工作职责:
存储管理用户的文件块数据
定期向namenode汇报自身所持有的block信息(通过心跳信息上报)
(这点很重要,因为,当集群中发生某些block副本失效时,集群如何恢复block初始副本数量的问题)
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>3600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
2、Datanode掉线判断时限参数
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。
|
观察验证DATANODE功能
上传一个文件,观察文件的block具体的物理存放情况:
在每一台datanode机器上的这个目录中能找到文件的切块:
/home/hadoop/app/hadoop-2.4.1/tmp/dfs/data/current/BP-193442119-192.168.2.120-1432457733977/current/finalized
HDFS的介绍的更多相关文章
- HDFS Federation(转HDFS Federation(HDFS 联盟)介绍 CSDN)
转载地址:http://blog.csdn.net/strongerbit/article/details/7013221 HDFS Federation(HDFS 联盟)介绍 1. 当前HDFS架构 ...
- HDFS简单介绍及用C语言訪问HDFS接口操作实践
一.概述 近年来,大数据技术如火如荼,怎样存储海量数据也成了当今的热点和难点问题,而HDFS分布式文件系统作为Hadoop项目的分布式存储基础,也为HBASE提供数据持久化功能,它在大数据项目中有很广 ...
- 【Hadoop离线基础总结】HDFS详细介绍
HDFS详细介绍 分布式文件系统设计思路 概述 只有一台机器时的文件查找:hello.txt /export/servers/hello.txt 如果有多台机器时的文件查找:hello.txt nod ...
- 【Hadoop离线基础总结】HDFS入门介绍
HDFS入门介绍 概述 HDFS全称为Hadoop Distribute File System,也就是Hadoop分布式文件系统,是Hadoop的核心组件之一. 分布式文件系统是横跨在多台计算机上的 ...
- HDFS原理介绍
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Googl ...
- 【转】HADOOP HDFS BALANCER介绍及经验总结
转自:http://www.aboutyun.com/thread-7354-1-1.html 集群平衡介绍 Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加 ...
- HADOOP HDFS BALANCER介绍及经验总结(转)
1.集群执行balancer命令,依旧不平衡的原因是什么?该如何解决? 2.尽量不在NameNode上执行start-balancer.sh的原因是什么? 集群平衡介绍 Hadoop的HDFS集群非常 ...
- Hadoop自学笔记(二)HDFS简单介绍
1. HDFS Architecture 一种Master-Slave结构.包括Name Node, Secondary Name Node,Data Node Job Tracker, Task T ...
- hdfs 安全模式介绍
1. hdfs在启动的时候现将映像载入内存,并执行edits中的各项操作,一旦在内存中建立元数据的映像,则闯进啊一个新的fsimage文件和空的编辑日志.此时namenode开始监听datanode请 ...
随机推荐
- DCGAN、WGAN、WGAN-GP、LSGAN、BEGAN原理总结及对比
DCGAN.WGAN.WGAN-GP.LSGAN.BEGAN原理总结及对比 from:https://blog.csdn.net/qq_25737169/article/details/7885778 ...
- LeetCode OJ:Best Time to Buy and Sell Stock II(股票买入卖出最佳实际II)
Say you have an array for which the ith element is the price of a given stock on day i. Design an al ...
- 什么是Activity,详细介绍Activity
首先,Activity是Android系统中的四大组件之一,可以用于显示View.Activity是一个与用记交互的系统模块,几乎所有的Activity都是和用户进行交互的,但是如果这样就能说Acti ...
- 一步一步写jQuery插件
转载自:http://www.cnblogs.com/joey0210/p/3408349.html 前言 如今做web开发,jquery 几乎是必不可少的,就连vs神器在2010版本开始将Jquer ...
- Delphi Xe4 游戏开发的技术选型.
asphyre 是支持 FireMonkey的. 利用Firemonkey的跨平台接口.实现 win,mac,ios. 其它方案估计就得靠 FPC 了. 好处是多了输出Andriod的可能. zeng ...
- 【转载】获取MAC地址方法大全
From:http://blog.csdn.net/han2814675/article/details/6223617 Windows平台下用C++代码取得机器的MAC地址并不是一件简单直接的事情. ...
- 【转载】 用 Windows API “GetAdaptersInfo” 获取 MAC 时遇到的问题
From:http://blog.csdn.net/weiyumingwww/article/details/17554461 前段时间有个项目需要获取客户端的 MAC 地址,用作统计去重的参考数据. ...
- Java [Leetcode 347]Top K Frequent Elements
题目描述: Given a non-empty array of integers, return the k most frequent elements. For example,Given [1 ...
- 分布式缓冲之memcache
1. memcache简介 memcache是danga.com的一个项目,它是一款开源的高性能的分布式内存对象缓存系统,,最早是给LiveJournal提供服务的,后来逐渐被越来越多的大型网站所采用 ...
- 如何将u盘、移动硬盘转化为活动分区--绝招
https://jingyan.baidu.com/article/e75057f2a6a18aebc91a893e.html