Python编程-数据类型方法
一、进制简介
进制也就是进位制,是人们规定的一种进位方法。对于任何一种进制---X进制,就表示某一位置上的数运算时是逢X进一位。十进制是逢十进一,十六进制是逢十六进一,二进制就是逢二进一,以此类推,x进制就是逢x进位。
1.位和字节
位(bit)表示二进制位。位是计算机内部数据储存的最小单位,11010100是一个8位二进制数。
字节(byte)习惯上用大写的“B”表示。字节是计算机中数据处理的基本单位。计算机中以字节为单位存储和解释信息,规定一个字节由八个二进制位构成,即1个字节等于8个比特(1Byte=8bit)。
八位二进制数最小为00000000,最大为11111111;通常1个字节可以存入一个ASCII码,2个字节可以存放一个汉字国标码。
(1) bit:位
一个二进制数据0或1,是1bit;
(2) byte:字节
1 byte = 8 bit
(3) 一个英文字符占一个字节;
1 字母 = 1 byte = 8 bit
(4) 一个汉字占2个字节;
1 汉字 = 2 byte = 16 bit
GBK:一个汉字占用两个字节,GB18030编码向下兼容GBK和GB2312。
UTF-8:一个汉字占用3个字节
每种编码都有自己的码表,因此编码规则是不一样的。
2.二进制
二进制是计算技术中广泛采用的一种数制。二进制数据是用0和1两个数码来表示的数。它的基数为2,进位规则是“逢二进一”。
数据在计算机中主要是以补码的形式存储的。计算机中的二进制则是一个非常微小的开关,用“开”来表示1,“关”来表示0。
二进制就是等于2时就要进位。
0=00000000
1=00000001
2=00000010
3=00000011
4=00000100
5=00000101
6=00000110
7=00000111
8=00001000
9=00001001
10=00001010
3.十进制
十进制基于位进制和十进位两条原则,即所有的数字都用10个基本的符号表示,满十进一,同时同一个符号在不同位置上所表示的数值不同,符号的位置非常重要。基本符号是0到9十个数字。
0 1 2 3 4 5 6 7 8 9
4.十六进制
十六进制是计算机中数据的一种表示方法。同我们日常生活中的表示法不一样。它由0-9,A-F组成,字母不区分大小写。与10进制的对应关系是:0-9对应0-9;A-F对应10-15。
0 1 2 3 4 5 6 7 8 9 A B C D E F
5.各进制对照表
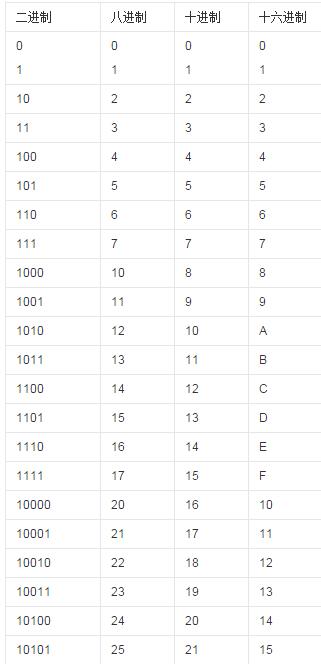
二、字符串str
1.类和对象
在python中,一个对象的特征也称为属性(attribute)。它所具有的行为也称为方法(method)
结论:对象=属性+方法
在python中,把具有相同属性和方法的对象归为一个类(class)。
类是对象的抽象化,对象是类的实例化。类不代表具体的事物,而对象表示具体的事物。
类是抽象的,不占用内存,而对象是具体的,占用存储空间。类是用于创建对象的蓝图,它是一个包括在特定类型的对象中的方法和变量的模板。
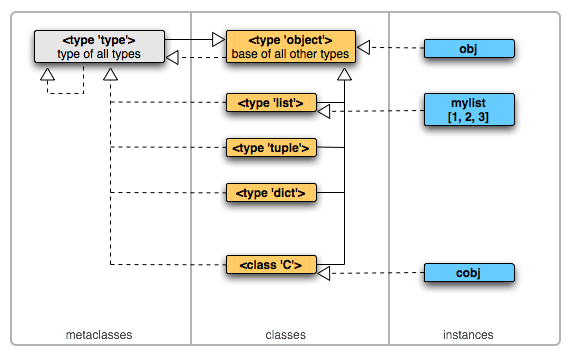
打个比方:
智能手机就是一个类(class),它是某类对象的统称,而你手上的这部iPhone7就是从属于智能手机这个类的一个具体实例/对象(object)。智能手机都会有个电池容量的参数(智能手机这个类的域或类变量),智能手机的电池容量除以充电功率可得充满电需要的时长(这一行为称为智能手机这个类的方法)具体到你的这部iPhone7也有它对应的电池容量(对象的域或实例变量),相应的:这部iPhone7的电池容量除以它的充电器功率也就得到它充满电需要的时间(对象可调用从属的那个类的方法)再具体到张三的那部sumsung S7,同样可以调用智能手机这个类的域和方法,得到那部S7的目标值。
2.字符串首字母大写,其他变成小写
string.capitalize()
自身不变,会生成一个新的值
name = 'toNg'
v = name.capitalize() # 自动找到name关联的str类,执行其中的capitalize技能
print(name)
print(v)
运行结果:
toNg
Tong
3.将所有大小写都变小写
string.casefold()
name = 'ToNg'
v = name.casefold()
print(name)
print(v)
运行结果:
ToNg
tong
string.lower()
效果与上面的一样。
只不过:
python 3.3引入了string.casefold方法,对Unicode(其他语言:德语...)的时候用casefold,lower() 只对 ASCII 也就是 'A-Z'有效,但是其它一些语言里面存在小写的情况就没办法了。
例如:德语中
s = 'ß'
a = s.lower() # 'ß'
b = s.casefold() # 'ss'
print(a)
print(b)
运行结果:
ß
ss
4.文本格式化
(1)文本居中
string.center(width, fillchar=None)
参数1: 表示总长度
参数2:空白处填充的字符(长度为1)
name = 'tong'
v = name.center(20)
print(v)
v = name.center(20,'行')
print(v)
运行结果:
tong
行行行行行行行行tong行行行行行行行行
(2)文本左对齐并填充右边部分(长度包含前面的值)
string.ljust(width, fillchar=None)
name = 'tong'
v = name.ljust(20)
print(v)
v = name.ljust(20,'*')
print(v)
运行结果:
tong
tong****************
(3)文本右对齐并填充左边部分(长度包含后面的值)
string.rjust(width, fillchar=None)
name = 'tong'
v = name.rjust(20)
print(v)
v = name.rjust(20,'*')
print(v)
运行结果:
tong
****************tong
5.表示传入值在字符串中出现的次数
string.count(sub, start=None, end=None)
参数1: 要查找的值(子序列)
参数2: 起始位置(索引)
参数3: 结束位置(索引)
name = "alexasdfdsafsdfasdfaaaaaaaa"
v = name.count('a')
print(v)
v = name.count('df',0,15)
print(v)
运行结果:
12
2
6.是否以xx开头或结尾
string.startswith(prefix, start=None, end=None)
string.endswith(suffix, start=None, end=None)
参数1:需要检查的字符串
参数2:设置字符串检测的起始位置
参数3:设置字符串检测的结束位置
name = 'tong'
v1 = name.startswith('to')
print(v1)
v2 = name.endswith('g')
print(v2)
v3 = name.startswith('c')
print(v3)
运行结果:
True
True
False
7.指定的编码格式编码字符串
string.encode(encoding='UTF-8',errors='strict')
参数1:要使用的编码,如"UTF-8、GBK"
参数2:设置不同错误的处理方案。默认为 'strict',意为编码错误引起一个UnicodeError。 其他可能的值有'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace'以及通过codecs.register_error() 注册的任何值。
name = '晓达'
v = name.encode(encoding='utf-8',errors='strict')
print(v)
a = name.encode(encoding='gbk',errors='strict')
print(a)
运行结果:
b'\xe6\x99\x93\xe8\xbe\xbe'
b'\xcf\xfe\xb4\xef'
8.找到制表符\t,进行替换(长度包含前面的值)
string.expendtabs(tabsize=8)
name = "al\te\tx\nalex\tuu\tkkk"
v = name.expandtabs(20)
print(v)
运行结果:
al e x
alex uu kkk
9.找到指定子序列的索引位置:不存在返回-1
string.find(sub, start=None, end=None)
存在返回索引位置,不存在返回-1
string.index(sub, start=None, end=None)
存在返回索引位置,不存在报错
name = 'alex'
v = name.find('o')
print(v)
a = name.find('e')
print(a)
b = name.index('e')
print(b)
c = name.index('t')
print(c)
运行结果:
-1
2
2
Traceback (most recent call last):
File "E:/s17/day02/test.py", line 10, in <module>
c = name.index('t')
ValueError: substring not found
10.字符串格式化
string.format(*args, **kwargs)
string.format_map(mapping)
根据索引位置
tpl = "我是:{0};年龄:{1};性别:{2}"
v = tpl.format("李杰",19,'都行')
print(v)
根据变量名
tpl = "我是:{name};年龄:{age};性别:{gender}"
v = tpl.format(name='李杰',age=19,gender='随意')
print(v)
根据KV映射关系
tpl = "我是:{name};年龄:{age};性别:{gender}"
v = tpl.format_map({'name':"李杰",'age':19,'gender':'中'})
print(v)
运行结果:
我是:李杰;年龄:19;性别:都行
我是:李杰;年龄:19;性别:随意
我是:李杰;年龄:19;性别:中
11.检测函数
(1)检测字符串是否由字母和数字、汉字组成
string.isalnum()
如果string至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False
name = 'alex8汉子'
v = name.isalnum()
name1 = 'alex8..*汉子'
v1 = name1.isalnum()
print(v1)
运行结果:
True
False
(2)检测字符串是否只由字母组成
string.isalpha()
如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False
name = 'alex'
name1 = 'alex8..*汉子'
v1 = name.isalpha()
print(v1)
v2 = name1.isalpha()
print(v2)
运行结果:
True
False
(3)判断是否是数字
string.isdecimal()
string.isdigit()
string.isnumeric()
num = '②'
v1 = num.isdecimal() # '123' 只能识别阿拉伯数字
v2 = num.isdigit() # '123','②' 可识别特殊数字格式
v3 = num.isnumeric() # '123','二','②' 可识别汉字,及特殊数字格式
print(v1,v2,v3)
运行结果:
False True True
(4)判断字符串是否是合法的标识符,字符串仅包含中文字符合法,实际上这里判断的是变量名是否合法
string.isidentifier()
n = 'name'
v = n.isidentifier()
print(v)
n = '仝晓达'
v = n.isidentifier()
print(v)
n = '9xiaoda'
v = n.isidentifier()
print(v)
运行结果:
True
True
False
(5)是否全部是大写或小写
string.isupper()
string.islower()
name = "ALEX"
v = name.isupper()
print(v)
name1 = "tong"
v1 = name1.islower()
print(v1)
运行结果:
True
True
(6)判断字符串中所有字符是否是可见状态
string.isprintable()
name = "钓鱼要钓刀鱼,\n刀鱼要到岛上钓"
v = name.isprintable()
print(v)
运行结果:
False
(7)字符串中如果至少有一个字符,并且全部为空格时返回为True
string.isspace()
name = 'tong '
v = name.isspace()
print(v)
name1 = ' '
v1 = name1.isspace()
print(v1)
运行结果:
False
True
12.全部变大写
string.upper()
name = 'alex'
v = name.upper()
print(v)
运行结果:
ALEX
13.将序列中的元素以指定的字符连接生成一个新的字符串
string.join(iterable)
返回通过指定字符连接序列中元素后生成的新字符串
name = 'alex'
v = "_".join(name) # 内部循环每个元素
print(v)
name_list = ['海峰','杠娘','李杰','李泉']
v = "搞".join(name_list)
print(v)
运行结果:
a_l_e_x
海峰搞杠娘搞李杰搞李泉
14.对应关系 + 翻译
string.maketrans(*args, **kwargs)
用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。
string.translate(table)
根据参数table给出的表(包含256个字符)转换字符串的字符
m = str.maketrans('aeiou','12345') # 对应关系
print(m)
name = "akpsojfasdufasdlkfj8ausdfakjsdfl;kjer09asdf"
v = name.translate(m) # 翻译
print(v)
运行结果:
{97: 49, 111: 52, 117: 53, 101: 50, 105: 51}
1kps4jf1sd5f1sdlkfj815sdf1kjsdfl;kj2r091sdf
15.分割元素
string.partition(sep)
根据指定字符串来分割原字符串,并将指定字符串添加进原字符串内
string.split(sep=None, maxsplit=-1)
指定分隔符对字符串进行切片,可指定分割次数
content = "李泉SB刘康SB刘一"
v = content.partition('SB') # partition
print(v)
v1 = content.split('SB')
print(v1)
v2 = content.split('SB',1)
print(v2)
运行结果:
('李泉', 'SB', '刘康SB刘一')
['李泉', '刘康', '刘一']
['李泉', '刘康SB刘一']
16.替换字符串
string.replace(old, new, count=None)
content = "李泉SB刘康SB刘浩SB刘一"
v = content.replace('SB','Love')
print(v)
v = content.replace('SB','Love',1)
print(v)
运行结果:
李泉Love刘康Love刘浩Love刘一
李泉Love刘康SB刘浩SB刘一
17.移除空白,\n,\t,自定义去掉指定字符串
string.strip(chars=None)
name = ' alex\t'
v = name.strip() # 空白,\n,\t
print(v)
name1 = ' alex tong eric'
v1 = name1.strip('eric') # 自定义
print(v1)
运行结果:
alex
alex tong
18.大小写转换
string.swapcase()
name = "Alex"
v = name.swapcase()
print(v)
运行结果:
aLEX
19.填充0
string.zfill(width)
name = "alex"
v = name.zfill(20)
print(v)
运行结果:
0000000000000000alex
20.标题格式化
string.title()
string.istitle()
判断是否为标题
返回字符串内所有首字母均变为大写
v = "this is string example....wow!!!"
a = v.title()
print(a)
运行结果:
This Is String Example....Wow!!!
三、整数int
1.当前整数的二进制表示,最少位数
int.bit_length()
age = 4 # 100
print(age.bit_length())
运行结果:
3
2. 获取当前数据的字节表示
int.to_bytes(length, byteorder, *args, **kwargs)
age = 15
v = age.to_bytes(10,byteorder='big')
v1 = age.to_bytes(10,byteorder='little')
print(v)
print(v1)
运行结果:
b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x0f'
b'\x0f\x00\x00\x00\x00\x00\x00\x00\x00\x00'
四、布尔值bool
v = 0
v = ""
v = []
以上均为:False 其他情况为:True
五、列表list
1.追加
user_list = ['李泉','刘一','刘康','豆豆','小龙']
user_list.append('刘铭')
print(user_list)
运行结果:
['李泉', '刘一', '刘康', '豆豆', '小龙', '刘铭']
2. 清空
user_list = ['李泉','刘一','刘康','豆豆','小龙']
user_list.clear()
print(user_list)
运行结果:
[]
3. 拷贝(浅拷贝)
user_list = ['李泉','刘一','刘康','豆豆','小龙']
v = user_list.copy()
print(v)
print(user_list)
运行结果:
['李泉', '刘一', '刘康', '豆豆', '小龙']
['李泉', '刘一', '刘康', '豆豆', '小龙']
4. 计数
user_list = ['李泉','刘一','李泉','刘康','豆豆','小龙']
v = user_list.count('李泉')
print(v)
运行结果:
2
5. 扩展原列表
user_list = ['李泉','刘一','李泉','刘康','豆豆','小龙']
user_list.extend(['郭少龙','郭少霞'])
print(user_list)
运行结果:
['李泉', '刘一', '李泉', '刘康', '豆豆', '小龙', '郭少龙', '郭少霞']
6. 查找元素索引,没有则报错
user_list = ['李泉','刘一','李泉','刘康','豆豆','小龙']
v = user_list.index('李海')
print(v)
运行结果:
Traceback (most recent call last):
File "E:/s17/day02/test.py", line 4, in <module>
v = user_list.index('李海')
ValueError: '李海' is not in list
7. 删除并且获取元素 - 索引
user_list = ['李泉','刘一','李泉','刘康','豆豆','小龙']
v = user_list.pop(1)
print(v)
print(user_list)
运行结果:
刘一
['李泉', '李泉', '刘康', '豆豆', '小龙']
8. 删除 - 值
user_list = ['李泉','刘一','李泉','刘康','豆豆','小龙']
user_list.remove('刘一')
print(user_list)
运行结果:
['李泉', '李泉', '刘康', '豆豆', '小龙']
9. 翻转
user_list = ['李泉','刘一','李泉','刘康','豆豆','小龙']
user_list.reverse()
print(user_list)
运行结果:
['小龙', '豆豆', '刘康', '李泉', '刘一', '李泉']
10. 排序: 欠参数
nums = [11,22,3,3,9,88]
print(nums)
# 排序,从小到大
nums.sort()
print(nums)
# 从大到小
nums.sort(reverse=True)
print(nums)
运行结果:
[11, 22, 3, 3, 9, 88]
[3, 3, 9, 11, 22, 88]
[88, 22, 11, 9, 3, 3]
六、range和enumrate生成序列方式
1. 请输出1-10
2.7: 立即生成所有数字
range(1,11) # 生成 1,2,3,4,5,6,...10
3.x: 不会立即生成,只有循环迭代时,才一个一个生成
for i in range(1,11):
print(i)
for i in range(1,11,2):
print(i)
for i in range(10,0,-1):
print(i)
2. range: 三个参数
li = ['eric','alex','tony']
range,len,li循环
for i in range(0,len(li)):
ele = li[i]
print(ele)
li = ['eric','alex','tony']
for j in range(0,len(li)):
print(j+1,li[j])
运行结果:
eric
alex
tony
1 eric
2 alex
3 tony
3.enumerate额外生成一列有序的数字
li = ['eric','alex','tony']
for i,ele in enumerate(li,1):
print(i,ele)
v = input('请输入商品序号:')
v = int(v)
item = li[v-1]
print(item)
运行结果:
1 eric
2 alex
3 tony
请输入商品序号:2
alex
七、元组tuple
1.元组定义
user_tuple = ('alex','eric','seven','alex')
元组是不可被修改的列表;不可变类型
2. 获取个数
user_tuple = ('alex','eric','seven','alex')
v = user_tuple.count('alex')
print(v)
运行结果:
2
3.获取值的第一个索引位置
user_tuple = ('alex','eric','seven','alex')
v = user_tuple.index('alex')
print(v)
运行结果:
0
4.额外的元组功能:
user_tuple = ('alex','eric','seven','alex')
for i in user_tuple: # 可以for循环
print(i)
v = user_tuple[0] # 可以被索引
v = user_tuple[0:2] # 可以切片
print(v)
运行结果:
alex
eric
seven
alex
('alex', 'eric')
user_tuple = ('alex','eric','seven',['陈涛','刘浩','赵芬芬'],'alex')
user_tuple[3][1] = '刘一' # 元组不可变,但构成元组的可变元素是可变的
print(user_tuple)
li = ['陈涛','刘浩',('alex','eric','seven'),'赵芬芬']
****** 元组最后,加逗号,否则只有一个元素时将变成字符串 ******
li = ('alex',)
print(li)
运行结果:
('alex', 'eric', 'seven', ['陈涛', '刘一', '赵芬芬'], 'alex')
('alex',)
八、字典dict
1. 清空
dic = {'k1':'v1','k2':'v2'}
dic.clear()
print(dic)
运行结果:
{}
2. 浅拷贝
dic = {'k1':'v1','k2':'v2'}
v = dic.copy()
print(v)
运行结果:
{'k1': 'v1', 'k2': 'v2'}
3. 根据key获取指定的value;不存在则赋予新值,不报错
dic = {'k1':'v1','k2':'v2'}
v = dic.get('k1111',1111)
print(v)
运行结果:
1111
4. 删除并获取对应的value值
dic = {'k1':'v1','k2':'v2'}
v = dic.pop('k1')
print(dic)
print(v)
运行结果:
5. 随机删除键值对,并获取到删除的键值
dic = {'k1':'v1','k2':'v2'}
v = dic.popitem()
print(dic)
print(v)
运行结果:
{'k2': 'v2'}
v1
dic = {'k1':'v1','k2':'v2'}
k,v = dic.popitem() # ('k2', 'v2')
print(dic)
print(k,v)
运行结果:
{'k2': 'v2'}
k1 v1
dic = {'k1':'v1','k2':'v2'}
v = dic.popitem() # ('k2', 'v2')
print(dic)
print(v[0],v[1])
运行结果:
{'k1': 'v1'}
k2 v2
6. 增加,如果存在则不做操作
dic = {'k1':'v1','k2':'v2'}
dic.setdefault('k3','v3')
print(dic)
dic = {'k1':'v1','k2':'v2'}
dic.setdefault('k1','1111111')
print(dic)
运行结果:
{'k1': 'v1', 'k3': 'v3', 'k2': 'v2'}
{'k1': 'v1', 'k2': 'v2'}
7. 批量增加或修改
dic = {'k1':'v1','k2':'v2'}
dic.update({'k3':'v3','k1':'v24'})
print(dic)
运行结果:
{'k3': 'v3', 'k2': 'v2', 'k1': 'v24'}
dic = dict.fromkeys(['k1','k2','k3'],123)
print(dic)
dic = dict.fromkeys(['k1','k2','k3'],123)
dic['k1'] = 'asdfjasldkf'
print(dic)
运行结果:
{'k2': 123, 'k1': 123, 'k3': 123}
{'k2': 123, 'k1': 'asdfjasldkf', 'k3': 123}
dic = dict.fromkeys(['k1','k2','k3'],[1,])
dic['k1'].append(222)
print(dic)
运行结果:
{'k2': [1, 222], 'k3': [1, 222], 'k1': [1, 222]}
8.额外的字典功能:
- 字典可以嵌套
- 字典key: 必须是不可变类型
dic = {
'k1': 'v1',
'k2': [1,2,3,],
(1,2): 'lllll',
1: 'fffffffff',
111: 'asdf',
}
print(dic)
key:
- 不可变
- True,1
dic = {'k1':'v1'}
del dic['k1']
布尔值:
1 True
0 False
bool(1111)
九、集合set
1.集合的定义
s1 = {"alex",'eric','tony','李泉','李泉11'}
s2 = {"alex",'eric','tony','刘一'}
不可重复的列表;可变类型
2.s1中存在,s2中不存在
s1 = {"alex",'eric','tony','李泉','李泉11'}
s2 = {"alex",'eric','tony','刘一'}
v = s1.difference(s2)
print(v)
运行结果:
{'李泉11', '李泉'}
s1中存在,s2中不存在,然后对s1清空,然后在重新复制
s1 = {"alex",'eric','tony','李泉','李泉11'}
s2 = {"alex",'eric','tony','刘一'}
s1.difference_update(s2)
print(s1)
print(s2)
运行结果:
{'李泉11', '李泉'}
{'tony', 'alex', '刘一', 'eric'}
3.s2中存在,s1中不存在,s1中存在,s2中不存在
s1 = {"alex",'eric','tony','李泉','李泉11'}
s2 = {"alex",'eric','tony','刘一'}
v = s1.symmetric_difference(s2)
print(v)
运行结果:
{'李泉', '刘一', '李泉11'}
4. 交集
s1 = {"alex",'eric','tony','李泉','李泉11'}
s2 = {"alex",'eric','tony','刘一'}
v = s1.intersection(s2)
print(v)
运行结果:
{'eric', 'tony', 'alex'}
5. 并集
s1 = {"alex",'eric','tony','李泉','李泉11'}
s2 = {"alex",'eric','tony','刘一'}
v = s1.union(s2)
print(v)
运行结果:
{'李泉', 'alex', 'tony', 'eric', '李泉11', '刘一'}
6. 移除
s1 = {"alex",'eric','tony','李泉','李泉11'}
s1.discard('alex')
print(s1)
运行结果:
{'李泉', 'eric', 'tony', '李泉11'}
7.更新,值存在则不更新
s1 = {"alex",'eric','tony','李泉','李泉11'}
s1.update({'alex','123123','fff'})
print(s1)
运行结果:
{'eric', 'alex', '123123', '李泉11', '李泉', 'tony', 'fff'}
8.额外的集合功能:
s1 = {"alex",'eric','tony','李泉','李泉11'}
for i in s1: # 可以使用for循环
print(i)
s1 = {"alex",'eric','tony','李泉','李泉11',(11,22,33)}
for i in s1: # 可以嵌套元组,不能嵌套列表
print(i)
Python编程-数据类型方法的更多相关文章
- Python编程-绑定方法、软件开发
一.绑定方法与非绑定方法 1.绑定方法 绑定给谁,谁来调用就自动将它本身当作第一个参数传入 (1)绑定到类的方法:用classmethod装饰器装饰的方法. 为类量身定制 类.boud_method( ...
- Python基础数据类型方法补充
str 补充的方法: capitalize():首字母大写,其余变小写 s = 'liBAI' s1 = s.capitalize() print(s1) # Libai swapcase():大小写 ...
- Python编程从入门到实践笔记——变量和简单数据类型
Python编程从入门到实践笔记——变量和简单数据类型 #coding=gbk #变量 message_1 = 'aAa fff' message_2 = 'hart' message_3 = &qu ...
- Python编程笔记二进制、字符编码、数据类型
Python编程笔记二进制.字符编码.数据类型 一.二进制 bin() 在python中可以用bin()内置函数获取一个十进制的数的二进制 计算机容量单位 8bit = 1 bytes 字节,最小的存 ...
- Python编程-常用模块及方法
常用模块介绍 一.time模块 在Python中,通常有这几种方式来表示时间: 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量.我们运行 ...
- Python 编程入门(1):基本数据类型
以下所有例子都基于最新版本的 Python,为了便于消化,每一篇都尽量短小精悍,希望你能尽力去掌握 Python 编程的「概念」,可以的话去动手试一下这些例子(就算目前还没完全搞懂),加深理解. 程序 ...
- 第2章 Python编程基础知识 第2.1节 简单的Python数据类型、变量赋值及输入输出
第三节 简单的Python数据类型.变量赋值及输入输出 Python是一门解释性语言,它的执行依赖于Python提供的执行环境,前面一章介绍了Python环境安装.WINDOWS系列Python编辑和 ...
- python常用数据类型内置方法介绍
熟练掌握python常用数据类型内置方法是每个初学者必须具备的内功. 下面介绍了python常用的集中数据类型及其方法,点开源代码,其中对主要方法都进行了中文注释. 一.整型 a = 100 a.xx ...
- python——获取数据类型:type()、isinstance()的使用方法:
python——获取数据类型 在python中,可使用type()和isinstance()内置函数获取数据类型 如: (1)type()的使用方法: >>> a = '230' ...
随机推荐
- 进出口流程 & 报关单据
出口流程 一. 委托人 1. 需找货运代理公司 2. 向代理公司询问价格 一般为 ALL IN 价格( 空运费+燃油费+战险费 ) 总费用 = ALL IN 价格 * ( 货物公斤数 ) ALL IN ...
- [搬家]新域名 akagi201.org
现在感觉自己做了好多年的垃圾信息制造者 以后只在网络上发布有用的东西, 垃圾或者对别人没用的东西就放到自己的硬盘上把 http://akagi201.org
- JavaScript 测试和捕捉
try 语句允许我们定义在执行时进行错误测试的代码块. catch 语句允许我们定义当 try 代码块发生错误时,所执行的代码块. JavaScript 语句 try 和 catch 是成对出现的.
- Eclipse 关闭项目
Eclipse 关闭项目 为什么要关闭项目? Eclipse 工作空间包含了多个项目.一个项目可以是关闭或开启状态. 项目打开过多影响有: 消耗内存 占用编译时间:在删除项目.class 文件(Cle ...
- linux 分卷压缩命令
linux 分卷压缩命令 1.使用tar分卷压缩 格式 tar cvzf - filedir | split -d -b 50m - filename 样例: tar cvzf - ./picture ...
- Unity3D学习笔记——NGUI之Localization system
Localization system(国际化系统) 实现的就是用户选择不同的语言,切换我们游戏文字的显示. 一:创建一个CVS文件.可以用Google Docs, Excel等软件工具. 我这里用的 ...
- phpstorm将多个int数字拼接成字符串
场景:将程序输出的多个int数字拼成以','分隔的字符串 数据为 8680 24399 37619 45425 49635 139334 386918 429498 461616 523384 561 ...
- hibernate 标签inverse cascade
inverse设立不当会导致性能低下,其实是说inverse设立不当,会产生多余重复的SQL语句甚至致使JDBC exception的throw.这是我们在建立实体类关系时必须需要关注的地方.一般来说 ...
- python 数学操作符
优先级从高到低 print("2 ** 3 = %d" % 2 ** 3) 2 ** 3 = 8print("7 % 2 = {}".format(7 % 2) ...
- java中使用MD5进行加密
java中使用MD5进行加密 在各种应用系统的开发中,经常需要存储用户信息,很多地方都要存储用户密码,而将用户密码直接存储在服务器上显然是不安全的,本文简要介绍工作中常用的 MD5加密算法,希 ...