简学Python第五章__模块介绍,常用内置模块
Python第五章__模块介绍,常用内置模块
欢迎加入Linux_Python学习群
 群号:478616847
群号:478616847
目录:
模块与导入介绍
包的介绍
time &datetime模块
random
os
sys
shutil
json & pickle
xml处理
configparser
hashlib
subprocess
logging模块
re正则表达式
一、模块与包介绍
模块是某个功能代码的集合,模块是一种组织形式,它将彼此有关系的python代码组织到一个个文件中,模块可以包含可执行代码,
函数和类或者这些东西的组合。一个模块创建之后, 你可以从另一个模块中使用 import 语句导入这个模块来使用。想想看写一个大
的项目的时候是不是有很多代码,那么我们就需要使用模块把这些代码按照功能结构进行划分,放在不同的目录或者是包中。
形象的来说模块就是有一些功能的py文件,我们通过import可以导入这个功能模块,并使用它
模块分为三种:
内置模块
三方开源模块
自定义模块
内置模块:
在安装完成python后,python本身就带有库,这个库叫做python内置库,那么内置模块也被称之为标准库
三方开源模块:
那么python内置的模块,有很多不能满足我们的需求,那么就会有很多人去自己写模块,并且把它开源出来,就是三方模块、
那么这些三方模块,会有一些统一下载的地方,三方模块下载地址 这个地址是pip的网站,里面现在收录了99886个三方模块
这么多的三方模块得益于开源精神,所以我们也是可以在这个网站上上传自己的模块供大家使用。
自定义模块:
自定义模块就是你自己写的代码组成的功能,这些功能称之为一个模块
导入模块
模块是有了,但是要在自己的代码中使用模块,是需要导入的,导入的方式有以下这么几种
import module
from module import xx
from module import xx as rename
from module import * import sys
print(sys.path) from sys import path
print(path) from sys import path as new_path
print(new_path) from sys import *
print(path)
print(argv)
导入模块
import sys 直接导入sys模块,想要用sys模块的功能需要 sys.path (拿path举例)
from sys import path 导入sys模块中的path功能,使用时直接使用path
from sys import path as new_path 导入sys模块中的path功能,并通过as 给path功能重命名,使用时直接使用新名字即可这个功能主要分防止功能名冲突
from sys import *导入sys模块中的所有功能,使用时直接用功能名即可
导入自定义模块
导入自定义模块其实也非常简单,首先在同级目录下我们有main.py和print_mode.py两个文件,在print_mode python文件中定义一个函数内容如下
#!/usr/bin/env python
# -*- coding: utf-8 -*- def new_print(arg):
print("\033[31m%s\033[0m"%arg)
print_mode
然后我们在main.py文件使用new_print这个函数,下面演示了上面的四种导入方法
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import print_mode
print_mode.new_print("Hello world") from print_mode import new_print
new_print("Hello world") from print_mode import new_print as pr
pr("Hello world") from print_mode import *
new_print("Hello world")
导入使用自定义模块
注意在上面我把同级目录下加粗了,也就说这种方法只能导入同级目录下的自定义模块,下面介绍如何导入不是同级目录下的模块
1、首先我们知道,操作系统有默认的环境变量,比如想要在cmd中使用python就需要在PATH环境变量中加入python的安装目录
那么如果我们想要导入其它目录下自定义模块,也要给python的PATH变量中加入模块所在的目录,我的目录结构如图

要知道的是我们的程序在其它计算机上面使用是安装到不同位置的,所以我们肯定不能再PATH环境变量中添加当前主机的程序位置
所以用os.path.abspath(__file__)得到当前文件绝对路径,然后我们要得到bin目录的上层目录,因为只有这样才能找到mode目录
通过os.path.dirname(os.path.abspath(__file__))得到的是bin目录的绝对路径,也就是现在这句话得到的是 bin目录,我们的
目的是得到test目录所以os.path.dirname(os.path.dirname(os.path.abspath(__file__))),得到test目录的绝对路径了,接下来
把得到的绝对路径通过sys.path.appen加入到python环境变量里面,那么我们就可以导入mode目录下的python_mode模块了
#!/usr/bin/env python
# -*- coding: utf-8 -*- import os,sys print(os.path.abspath(__file__))
print(os.path.dirname(os.path.abspath(__file__)))
print(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) print("原:",sys.path)
base_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(base_dir)
print("新:",sys.path) from mode import print_mode
print_mode.new_print("Hello world")
导入其它目录中的自定义模块main(文件内容)
注意!如果在print_mode文件中有一个print()语句,那么在print_mode文件被第一次导入的时候就会执行这个print语句,这是因为
第一次导入的时候会把print_mode文件内容加载到内存,为了防止你重复导入,python的优化手段会把后续的import语句仅是对已经加
载大内存中的模块对象增加了一次引用,不会重新执行模块内的语句。
第三方模块的安装
安装第三方模块我们可以使用pip和源码进行安装,源码安装只需要做以下的操作
以paramiko模块为例,第三方模块在安装过程中就在Python的PATH环境变量中,因此用法和内置模块一样
# pip install paramiko pip安装方式 # pycrypto,由于 paramiko 模块内部依赖pycrypto,所以先下载安装pycrypto # 下载安装 pycrypto
wget http://files.cnblogs.com/files/wupeiqi/pycrypto-2.6.1.tar.gz
tar -xvf pycrypto-2.6.1.tar.gz
cd pycrypto-2.6.1
python setup.py build
python setup.py install # 进入python环境,导入Crypto检查是否安装成功 # 下载安装 paramiko
wget http://files.cnblogs.com/files/wupeiqi/paramiko-1.10.1.tar.gz
tar -xvf paramiko-1.10.1.tar.gz
cd paramiko-1.10.1
python setup.py build
python setup.py install # 进入python环境,import paramiko检查是否安装成功即可
安装第三方模块
更多运维中常用的第三方模块请参考 Python自动化运维
二、包的介绍
包是一种通过使用" .模块名 "来组织python模块名称空间的方式,其实python中的包 就是一个包含__init__.py文件的目录。模块称之为文件
那么包就是文件的集合,在我们使用目录来存储模块,会造成模块名冲突的问题,那么包就可以有效地避免模块名冲突的问题,在学习包之前
首先创建了一个根目录目录和app,bin,config这三个包,每个包里都有py文件
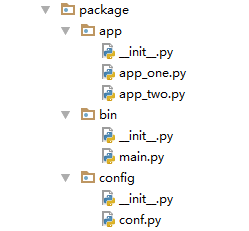
#app_one
def conf_app_one():
print("From app_one") #app_two
def conf_app_two1():
print("From 1 app_two.py") def conf_app_two2():
print("From 2 app_two.py") #conf
def conf_func():
print("From conf.py")
文件内容
导入包
包的导入也分为import,和from...import,import导入语句也是导入同级目录的所以这里不做演示 无论是import形式还是from...import形式,凡是在导入语
句中(而不是在使用时)遇到带点的,都是关于包才有的导入语法,并且from后面的import导入的模块是不能带点的,所以点的左边必须是一个包
错误方法:from aa import bb.c
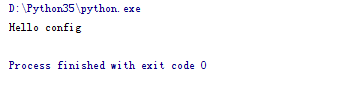
第一次导入包的时候,会执行包中的 __init__.py文件,首先我们可以在config模块中的 __init__.py 写一句 print,然后在main。py中导入 config模块试一下
#!/usr/bin/env python
# -*- coding:utf-8 -*- import os,sys
path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(path) from config import conf
导入模块触发__init__
当我们运行main.py 后就触发了在config模块中的 __init__.py 的print语句
__all__
那么这个__init__.py还能干什么事呢?
这次我们导入 app包下的模块,看看*能不能把app下面的文件全部导入进来
#!/usr/bin/env python
# -*- coding:utf-8 -*- #main文件
import os,sys
path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(path) from app import * app_one.conf_app_one()
app_two.conf_app_two1()
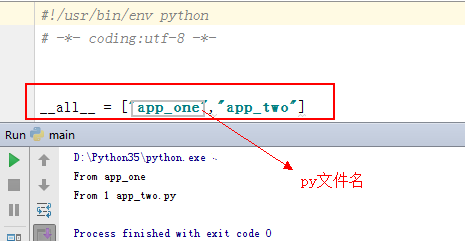
__all__的作用
然而我们一运行发现报错,说app_one没有定义!

这不科学,安装道理说from app import *应该导入 app包下的所有py文件啊!其实在app下的__init__文件中加入__all__ = ["app_one","app_two"],就可以这样调用了。
最后我们来看正常导入的方式
#!/usr/bin/env python
# -*- coding:utf-8 -*- import os,sys
path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(path) from app import app_two
app_two.conf_app_two1() from app import app_two as two
two.conf_app_two2() from app.app_one import *
conf_app_one()
包的导入
pyc文件
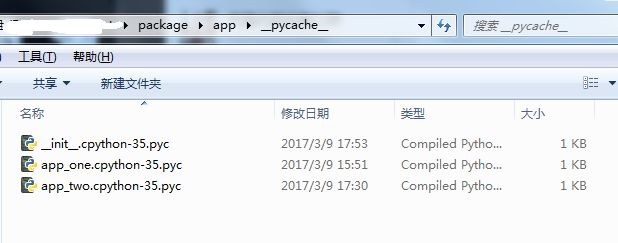
有一天我突然打开包的目录,忽然发现,目录中多出了__pycache__的文件夹,里面有.pyc的文件,在好奇心的驱使下我百度出它的真面目
原来python为了提高模块的加载速度,Python缓存编译的版本,每个模块在__pycache__目录下有着以module.version.pyc的形式命名
的文件,这些文件名包含了python的版本号,模块名,如CPython版本3.5,并且Python会检查源文件的修改时间与编译的版本进行对比,
如果过期就需要重新编译。这是完全自动的过程。不同的版本编译后的pyc文件不同,2.5编译的pyc文件不能到3.5上执行,并且pyc文件是
可以反编译的,因而它的出现仅仅是用来提升模块的加载速度的。
三、time &datetime模块
接下来开始学习常用的内置模块,内置模块就是集成在python中的工具包,我们要学习常用的工具包的用法,这些用法非常简单
在平时的代码中,经常要与实际打交道 与时间处理有关的模块就包括:time,datetime以及calendar这里讲解前两个模块
Time模块
python中通常有这几种形式来表示时间:1、时间戳 2、格式化的时间字符串 3、元祖
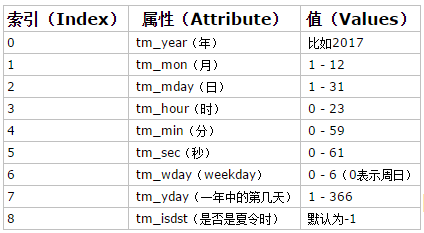
1、time.localtime()会通过time.struct_time的class类转换成特殊时间的格式,括号中可以传入时间戳,如果不传入则用的是当前时间,我们可以通过下标取出对应的值
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=10, tm_hour=15, tm_min=53, tm_sec=53, tm_wday=4, tm_yday=69, tm_isdst=0)
2、time.gmtime()与time.localtime()方法类似,只不过会把当前时间转换成0时区的时间
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=10, tm_hour=16, tm_min=1, tm_sec=16, tm_wday=4, tm_yday=69, tm_isdst=0)
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=10, tm_hour=8, tm_min=1, tm_sec=16, tm_wday=4, tm_yday=69, tm_isdst=0)
3、time.time():返回当前时间的时间戳。
4、time.mktime(t):将一个struct_time转化为时间戳。
5、time.sleep(secs):线程推迟指定的时间运行。单位为秒,可以是小数
6、time.clock():在UNIX系统上,它返回的是“进程时间”,它是用秒表示的浮点数(时间戳)。而在WINDOWS中,第一次调用,返回的是进程运行的实际时间。
而第二次之后的调用是自第一次调用以后到现在的运行时间。
7、time.asctime([t]):把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。如果没有参数,将会将time.localtime()作为参数传入。
8、time.ctime([secs]):把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为None的时候,将会默认time.time()为参数。
它的作用相当于time.asctime(time.localtime(secs))。
输出自定义的日期格式
import time
print(time.strftime("%Y:%m:%d,%H",time.localtime(time.time())))
自定义日志输出格式
可以看到其中双引号的内容就是调用了下面的格式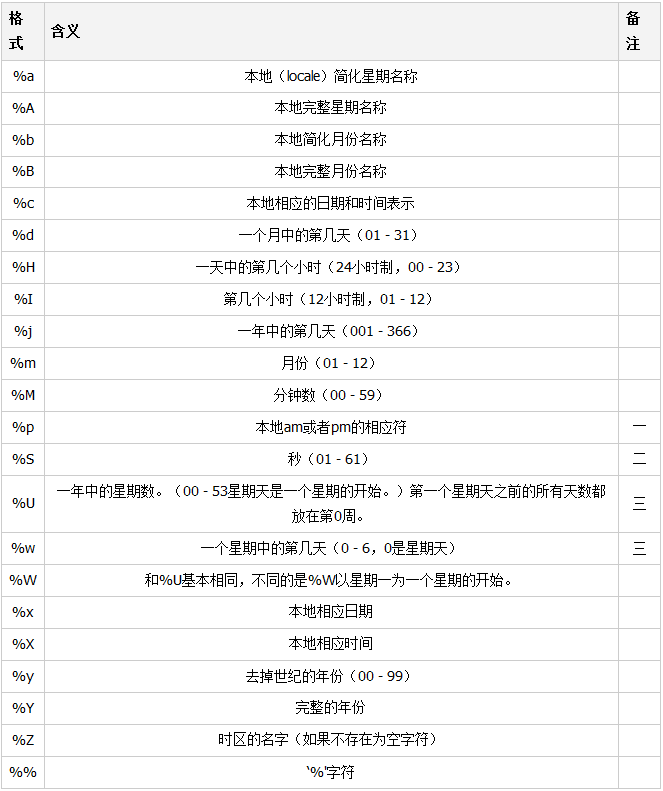
datetime模块
这个模块可以理解为data和time两个部分,主要用于时间的加减,也可以计算时间差
import datetime
import time #返回 当前时间
print(datetime.datetime.now())
# 时间戳直接转成日期格式 2016-08-19
print(datetime.date.fromtimestamp(time.time()) ) #当前时间+3天
print(datetime.datetime.now() + datetime.timedelta(3))
#当前时间-3天
print(datetime.datetime.now() + datetime.timedelta(-3))
#当前时间+3小时
print(datetime.datetime.now() + datetime.timedelta(hours=3))
#当前时间+30分
print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #时间替换
c_time = datetime.datetime.now()
print(c_time.replace(minute=3,hour=2)) #计算时间差,返回天数
datas = "2016-08-19"
def Repayment(past_time):
def conversion(str_data):#把每个元素变成int类型
data_list = str_data.split("-")
for i in data_list:data_list[data_list.index(i)] = int(i)
return data_list
#得到新老时间的列表
new_time_list = conversion(time.strftime("%Y-%m-%d",time.localtime(time.time())))
past_time_list = conversion(past_time)
n_time = datetime.datetime(new_time_list[0],new_time_list[1],new_time_list[2])
p_time = datetime.datetime(past_time_list[0],past_time_list[1],past_time_list[2])
return ((n_time - p_time).days)
print(Repayment(datas))
datatime
四、random
生成随机数
#!/usr/bin/env python import random #生成一个0到1的随机浮点数
print(random.random()) #用于生成一个指定范围内的随机符点数
print( random.uniform(10, 20))
print( random.uniform(10, 20)) #用于生成一个指定范围内的整数。
print(random.randint(10, 20)) #指定范围内,按指定基数递增的集合中 获取一个随机数。
#例子中也就是只会从 10 12 14 ... 18取得随机数,第三个参数为2的时候也就是取偶数
print(random.randrange(10,20, 2)) #从序列中获取一个随机元素。
data_str = "I love Python"
data_list = [1,2,3,4,5,6]
data_tuple = ("A","B","C","D","E")
print(random.choice(data_str))
print(random.choice(data_list))
print(random.choice(data_tuple)) #用于将一个列表中的元素打乱。
data_list = [1,2,3,4,5,6]
random.shuffle(data_list)
print(data_list) #从指定序列中随机获取指定长度的片断
data_list = [1,2,3,4,5,6]
print(random.sample(data_list,3))
random用法
小例子:生成随机的验证码
#!/usr/bin/env python import random
# 第一版
def code(number):
'''
随机数生成器
'''
number_check = ''
for i in range(0,number):
number_curr = random.randrange(0,5)
if number_curr != i:
number_temp = chr(random.randint(97,122))
else:
number_temp = random.randint(0,9)
number_check += str(number_temp)
return number_check
print(code(5)) # 第二版
import string
source = string.digits + string.ascii_uppercase + string.ascii_lowercase
print("".join(random.sample(source, 4)))
生成随机验证码或者密码
五、os
os模块之前我们接触了与文件相关的发放,os模块还有很多与操作系统交互的函数
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.normpath(path) #规范化路径,转换path的大小写和斜杠
os模块
六、sys
sys模块也是比较常用的模块,比如获取命令执行python是后面的参数
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys功能
七、shutil
shutil是一种高层次的文件操作工具,提供了大量的文件高级操作(可以用print(help(shutil))来查看),比如 拷贝删除,压缩等等
#!/usr/bin/env python import shutil #1、将文件拷贝到另一个文件中
shutil.copyfileobj(open('test','r'), open('test2', 'w')) #2、拷贝文件
shutil.copyfile('test', 'test2.conf') #3、拷贝权限 内容、组、用户均不变(目标文件必须存在)
shutil.copymode('test', 'test2.conf') #4、仅拷贝状态的信息,包括:mode bits, atime, mtime, flags(目标文件必须存在)
shutil.copystat('test', 'test2.conf') #5、拷贝文件和权限
shutil.copy('test', 'test3') #6、拷贝文件和状态信息
shutil.copy2('test', 'test3') #7、递归的去拷贝文件夹
shutil.copytree('testlist', 'test2list', ignore=shutil.ignore_patterns('main.py',))
"""目标目录不能存在,注意对test2list目录父级目录要有可写权限,
ignore的意思是排除,这里表示不拷贝main.py文件,多个可以用逗号隔开,也可以用*.py""" #拷贝软连接
shutil.copytree('f1', 'f2', symlinks=True, ignore=shutil.ignore_patterns('*.pyc'))
#通常的拷贝都把软连接拷贝成硬链接,即对待软连接来说,创建新的文件 #8、递归的去删除文件
shutil.rmtree('test2list') #9、递归的去移动文件,它类似mv命令,其实就是重命名。
shutil.move("testlist", "testlist2")
shutil
压缩shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
- base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
- 如 data_bak =>保存至当前路径
- 如:/tmp/data_bak =>保存至/tmp/
- format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
#!/usr/bin/env python import shutil #打包当前目录下的testlist目录,打包成a_bk.zip
#支持方法"zip", "tar", "bztar" "gztar".
tar = shutil.make_archive("a_bk","zip",root_dir="./testlist") #把打包结果文件刚在/mnt/目录下
tar2 = shutil.make_archive("/mnt/a_bk","gztar",root_dir="./testlist")
打包
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的
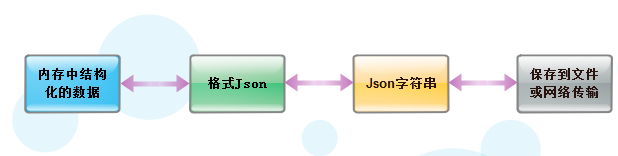
八、json & pickle
在程序运行的过程中,变量都是在变化的,并且当程序结束后变量将消失,那么为了让程序下次运行的时候还可以用上次的变量,就需要对这些变量,字典,列表通过
序列化保存在文件中,下一次读取文件中的内容进行反序列化就可得到上次运行时的变量数据,那么json和pickle是用于数据序列化的模块,有些童鞋会经常听见开发说
,这个Api返回的是一串json,所以json就是不同平台直接传输数据的,因为在java中在html中都支持json格式的数据
Json和Pickle 都提供了四个功能:dumps、dump、loads、load
Json
#!/usr/bin/env python
import json #-----------序列化---------#
dic = {"name":'aaa',"age":22,}
lis = [1,2,3,""] with open("test","w") as file:
file.write(json.dumps(dic))
with open("test2","w") as file:
json.dump(lis,file) #----------反序列化---------#
with open("test","r") as file:
data_dic = json.loads(file.read())
with open("test2","r") as file:
data_lis = json.load(file)
print(type(data_lis),":",data_lis)
print(type(data_dic),":",data_dic)
Json
注!Json不能保存函数和类对象,但是Pickle可以
Pickle,是python独有的,其它语言并不支持,并且保存的数据类时要用bytes方式写入

#!/usr/bin/env python
import pickle #-----------序列化---------#
dic = {"name":'aaa',"age":22,}
def func():
return "Hello" with open("test","wb") as file:
file.write(pickle.dumps(dic))
with open("test2","wb") as file:
pickle.dump(func,file) #----------反序列化---------#
with open("test","rb") as file:
data_dic = pickle.loads(file.read())
with open("test2","rb") as file:
data_func = pickle.load(file)
print(type(data_func),":",data_func)
print(data_func())
print(type(data_dic),":",data_dic)
Pickle
九、xml处理
xml也是实现不同语言或程序之间的数据交互,跟json差不多,它是诞生在json之前,如今很多传统公司和金融行业的系统主要的
接口还是xml
xml数据格式如下
<?xml version='1.0' encoding='utf-8'?>
<userdata>
<name Name="XiaoMing">
<age>22</age>
<gender>Men</gender>
</name>
<name Name="XiaoHong">
<age>19</age>
<gender>Women</gender>
</name>
</userdata>
xml文件
创建上面内容的xml文件
#生成 最外层的<userdata>
new_xml = ET.Element("userdata") #生成<name Name="XiaoMing">
name1 = ET.SubElement(new_xml,"name",attrib={"Name":"XiaoMing"})
#生成<name Name="XiaoMing">中的<age>22</age>
age = ET.SubElement(name1,"age")
age.text = ""
#生成<name Name="XiaoMing">中的<gender>Men</gender>
gender = ET.SubElement(name1,"gender")
gender.text = "Men" #生成<name Name="XiaoHong">
name2 = ET.SubElement(new_xml,"name",attrib={"Name":"XiaoHong"})
#生成<name Name="XiaoHong">中的<age>19</age>
age = ET.SubElement(name2,"age")
age.text = ''
#生成<name Name="XiaoHong">中的<gender>Women</gender>
gender = ET.SubElement(name2,"gender")
gender.text = "Women" et = ET.ElementTree(new_xml) #生成文档对象
et.write("test.xml", encoding="utf-8",xml_declaration=True)#写入
生成xml文件
读取xml文件内容
#获取最外层的<userdata>
tree = ET.parse("test.xml")
root = tree.getroot()
print(root.tag)
print("-----------------遍历xml文档------------------")
#遍历xml文档
for child in root:
print(child.tag,child.attrib)#打印<name Name="XiaoMing">和<name Name="XiaoHong">
for i in child:
print(i.tag,i.text)#分别打印年龄和性别 print("-----------------只遍历age 节点------------------")
#只遍历age 节点
for node in root.iter("age"):
print(node.tag,node.text)
读取xml文件内容
更改删除xml文件内容
import xml.etree.ElementTree as ET
print("--------------------年龄加1------------------")
tree = ET.parse("test.xml")
root = tree.getroot()
for node in root.iter('age'):
node.text = str(int(node.text) + 1)#年龄加一
node.set("updated","yes") #增加属性 updated=“yex”
tree.write("test.xml")#写入
print("----------------删除年龄大于20的-------------")
tree = ET.parse("test.xml")
root = tree.getroot()
for country in root.findall('name'):#循环name标签,[<Element 'name' at 0x009F4180>, <Element 'name' at 0x009F4240>]
rank = int(country.find('age').text)#获取name标签下的年龄
if rank > 20:#判断年龄是否大于20
root.remove(country)#如果大则删除
tree.write('test.xml')#写入
更改删除xml文件内容
十、configparser
这个内置模块呢一般用处用来做配置文件的操作,可以操作以下格式的文件
[www.test.org]
user = test
port = 20012 [www.test2.org]
user = test2
port = 20011
forwardx11 = no
文件内容
语法:读操作
-read(filename) 直接读取文件内容
-sections() 得到所有的section,并以列表的形式返回
-options(section) 得到该section的所有option
-items(section) 得到该section的所有键值对
-get(section,option) 得到section中option的值,返回为string类型
-getint(section,option) 得到section中option的值,返回为int类型
写操作
-add_section(section) 添加一个新的section
-set( section, option, value) 对section中的option进行设置
示例代码
#!/usr/bin/env python import configparser
import time conf = configparser.ConfigParser()
conf.read('conf') print("----------------读----------------")
#得到所有的section,并以列表的形式返回
print(conf.sections())
#得到该section的所有option
print(conf.options('www.test.org'))
#得到该section的所有键值对
print(conf.items('www.test2.org'))
print(conf.get('www.test2.org',"User"))#得到section中option的值,返回为string类型
time.sleep(2) print("----------------改----------------")
conf.set('www.test2.org','port',"")
conf.write(open('conf', "w"))
time.sleep(2) print("----------------判断---------------")
print(conf.has_section('www.test2.org'))
time.sleep(2) print("----------------删----------------")
#删除section中的option
conf.remove_option('www.test.org','port')
#删除section
conf.remove_section('www.test.org')
conf.write(open('conf', "w"))
time.sleep(2) print("----------------写----------------")
#添加section
conf.add_section('www.test3.org')
#添加section中的option
conf.set('www.test3.org','port',"")
conf.write(open('conf', "w"))
configparser操作
十一、hashlib
hashlib在python3中代替了MD5和sha模块,主要提供了SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法,在python3中已经废弃了
md5和sha模块,其中最为常用的MD5算法,我们经常看到下载一个光盘镜像的时候,后面会告诉你一个MD5值,这个就是用来做文件完整性验证的
所以同一种字符串计算出来的MD5值是一样的
特点:1、相同的内容hash运输的结果是相同的2、这种计算是不可逆的3、相同算法,无论校验多长的数据,得到的哈希值长度固定。
以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
#!/usr/bin/env python import hashlib #首先定义一个hashlib的对象
ha = hashlib.md5()#用的md5加密方式,这里还可以用SHA1, SHA224, SHA256, SHA384, SHA512算法
ha.update("Hello".encode("utf-8"))
print(ha.hexdigest())#返回16进制
print(ha.digest())#返回二进制
#结果 8b1a9953c4611296a827abf8c47804d7 b"\x8b\x1a\x99S\xc4a\x12\x96\xa8'\xab\xf8\xc4x\x04\xd7"
hashlib
十二、subprocess
subprocess用于执行本地命令,它是通过管道的形式,连接到他们的输入/输出/错误,并获得他们的返回代码。
示例代码:(官方介绍)
import subprocess
#执行命令,如果命令结果为0,就正常返回,否则抛异常
retcode = subprocess.call(["ls", "-l"]) #接收字符串格式命令,返回元组形式,第1个元素是执行状态,第2个是命令结果
results = subprocess.getstatusoutput('ls /bin/ls')
print(results) #接收字符串格式命令,并返回结果
print(subprocess.getoutput('ls /bin/ls')) #执行命令,并返回结果,注意是返回结果,不是打印,下例结果返回给res
res=subprocess.check_output(['ls','-l'])
print(res) #调用subprocess.run(...)是推荐的常用方法,在大多数情况下能满足需求,
subprocess.run(["ls", "-l", "/dev/null"], stdout=subprocess.PIPE)
subprocess
其实上面的方法都是对Popen的封装subprocess模块中只定义了Popen这个类,我们可以使用Popen来创建进程,并与进程进行复杂的交互。
这个模块将取代 os.system 和 os.spawn*,Popen这个类其中可以跟很多参数。
|
args |
shell命令,可以是字符串或者序列类型(如:list,元组) |
|
bufsize |
指定缓冲: 0:无缓冲 1:行缓冲 其他正值:缓冲区大小 负值:采用默认系统缓冲(一般是全缓冲) |
|
executable |
一般不用吧,args字符串或列表第一项表示程序名 |
|
stdin stdout stderr |
分别表示程序的标准输入、输出、错误句柄 |
|
preexec_fn |
钩子函数, 只在Unix平台下有效,用于指定一个可执行对象(callable object),它将在子进程运行之前被调用 |
|
close_fds |
unix 下执行新进程前是否关闭0/1/2之外的文件 |
|
在windows平台下,如果close_fds被设置为True,则新创建的子进程将不会继承父进程的输入、输出、错误管道。 |
|
|
shell |
为真的话 unix下相当于在命令前面添加了 "/bin/sh” ”-c” window下,相当于添加"cmd.exe /c" |
|
cwd |
设置工作目录 |
|
env |
设置环境变量 |
|
universal_newlines |
不同系统的换行符不同,True -> 则统一使用 \n 为换行符 |
|
startupinfo |
window下传递给CreateProcess的结构体 |
|
creationflags |
只在windows下有效 |
Popen使用方法
但如果你需要进行一些复杂的与系统的交互的话,则需呀Popen,语法如下
import subprocess subprocess.Popen(["ls","test"])
subprocess.Popen("cat test.txt", shell=True)
p = subprocess.Popen("ls test",stdin=subprocess.PIPE,stdout=subprocess.PIPE,shell=True)
p.stdout.read() #需要交互的命令示例
obj = subprocess.Popen(["python"], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
obj.stdin.write('print(1) \n ')
obj.stdin.write('print(2) \n ')
obj.stdin.write('print(3) \n ')
obj.stdin.write('print(4) \n ') out_error_list = obj.communicate(timeout=10)
print(out_error_list)
Popen
subprocess实现sudo 自动输入密码
import subprocess mypass = ''#密码 echo = subprocess.Popen(['echo',mypass],stdout=subprocess.PIPE,)
#命令
sudo = subprocess.Popen(['sudo','-S','iptables','-L'],stdin=echo.stdout,stdout=subprocess.PIPE,) end_of_pipe = sudo.stdout
print("Password ok \n Iptables Chains %s" % end_of_pipe.read())
实现sudo自动输入密码
十三、logging模块
logging模块主要针对日志,在程序中需要日志,好帮助我们进行统计以及问题分析,logging的日志可以分为 debug(), info(), warning(), error() and critical() 5个级别
下面来看一下用法
import logging
logging.warning("user test attempted wrong password more than 3 times")
logging.critical("server is down")
logging.error("File cannot be opened")
简单用法
我们发现有logging模块有info级别有error级别,那么看看这些级别代表的意思

import logging print(logging.NOTSET) #
print(logging.DEBUG) #
print(logging.INFO) #
print(logging.WARNING)#
print(logging.ERROR) #
print(logging.CRITICAL)#
对应着不同的级别
把日志写入文件
import logging logging.basicConfig(filename='test.log',level=logging.INFO)
logging.debug('debug')
logging.info('info')
logging.warning("warning")
把日志写入文件
我们可以发现debug信息是没有写入日志的level=logging.INFO是定义了最低写入日志的级别,只有比日志是INFO或比INFO级别更高的日志才会被纪录到文件里
上面的日志中少了时间,我们可以定义一些日志格式来实现自己的需求
import logging logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(name)s %(levelname)s %(message)s',
datefmt='[%Y-%m-%d %H:%M:%S]',
filename='test.log',
filemode='a') logging.warning('warning')
自定义日志格式
在自定义日志中,format表示日志格式,用到的就是下面截图中的功能,filename是日志的文件名,filemode是打开日志的格式,默认是w打开所以要是想追加
日志就需要把模式改成a
日志格式

如果想同时把log打印在屏幕和文件日志里,就需要了解一点复杂的知识了
Python 使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
- logger提供了应用程序可以直接使用的接口;
- handler将(logger创建的)日志记录发送到合适的目的输出;
- filter提供了细度设备来决定输出哪条日志记录;
- formatter决定日志记录的最终输出格式。
logger
每个程序在输出信息之前都要获得一个Logger。Logger通常对应了程序的模块名,比如聊天工具的图形界面模块可以这样获得它的Logger:
LOG=logging.getLogger(”chat.gui”)
而核心模块可以这样:
LOG=logging.getLogger(”chat.kernel”) Logger.setLevel(lel):指定最低的日志级别,低于lel的级别将被忽略。debug是最低的内置级别,critical为最高
Logger.addFilter(filt)、Logger.removeFilter(filt):添加或删除指定的filter
Logger.addHandler(hdlr)、Logger.removeHandler(hdlr):增加或删除指定的handler
Logger.debug()、Logger.info()、Logger.warning()、Logger.error()、Logger.critical():可以设置的日志级别 handler handler对象负责发送相关的信息到指定目的地。Python的日志系统有多种Handler可以使用。有些Handler可以把信息输出到控制台,有些Logger可以把信息输出到文件,还有些 Handler可以把信息发送到网络上。如果觉得不够用,还可以编写自己的Handler。可以通过addHandler()方法添加多个多handler
Handler.setLevel(lel):指定被处理的信息级别,低于lel级别的信息将被忽略
Handler.setFormatter():给这个handler选择一个格式
Handler.addFilter(filt)、Handler.removeFilter(filt):新增或删除一个filter对象 每个Logger可以附加多个Handler。接下来我们就来介绍一些常用的Handler:
1) logging.StreamHandler
使用这个Handler可以向类似与sys.stdout或者sys.stderr的任何文件对象(file object)输出信息。它的构造函数是:
StreamHandler([strm])
其中strm参数是一个文件对象。默认是sys.stderr 2) logging.FileHandler
和StreamHandler类似,用于向一个文件输出日志信息。不过FileHandler会帮你打开这个文件。它的构造函数是:
FileHandler(filename[,mode])
filename是文件名,必须指定一个文件名。
mode是文件的打开方式。参见Python内置函数open()的用法。默认是’a',即添加到文件末尾。 3) logging.handlers.RotatingFileHandler
这个Handler类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建 一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。它的构造函数是:
RotatingFileHandler( filename[, mode[, maxBytes[, backupCount]]])
其中filename和mode两个参数和FileHandler一样。
maxBytes用于指定日志文件的最大文件大小。如果maxBytes为0,意味着日志文件可以无限大,这时上面描述的重命名过程就不会发生。
backupCount用于指定保留的备份文件的个数。比如,如果指定为2,当上面描述的重命名过程发生时,原有的chat.log.2并不会被更名,而是被删除。 4) logging.handlers.TimedRotatingFileHandler
这个Handler和RotatingFileHandler类似,不过,它没有通过判断文件大小来决定何时重新创建日志文件,而是间隔一定时间就 自动创建新的日志文件。重命名的过程与RotatingFileHandler类似,不过新的文件不是附加数字,而是当前时间。它的构造函数是:
TimedRotatingFileHandler( filename [,when [,interval [,backupCount]]])
其中filename参数和backupCount参数和RotatingFileHandler具有相同的意义。
interval是时间间隔。
when参数是一个字符串。表示时间间隔的单位,不区分大小写。它有以下取值:
S 秒
M 分
H 小时
D 天
W 每星期(interval==0时代表星期一)
midnight 每天凌晨
介绍
实现的代码
import logging #定义文件日志格式
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(name)s %(levelname)s %(message)s',
datefmt='[%Y-%m-%d %H:%M:%S]',
filename='test.log',
filemode='a') #create logger创建日志记录器
logger = logging.getLogger()
logger.setLevel(logging.DEBUG) # create console handler and set level to debug
#定义输出级别为DEBUG
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG) # create formatter 创建日志输出的格式
formatter = logging.Formatter('%(asctime)s %(name)s - %(levelname)s - %(message)s',
datefmt='[%Y-%m-%d %H:%M:%S]') # add formatter to ch 绑定日志输出格式
ch.setFormatter(formatter) # add ch to logger 绑定到日志记录器
logger.addHandler(ch) #调用日志
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')
实现代码
十四、re正则表达式
正则表达式相信很多人都熟悉了,在python中正则表达式的支持是通过re(regular expression)模块来支持的
下面来熟悉下正则中的几个概念:
1、通配符
通配符是一种特殊语句可以使用它来代替一个或多个真正的字符比如‘ . ’点,他就可以代替任意的字符除了换行符,.python就可以等于xpython、+python等等
2、字符集
既然通配符”. ”可以表示一个任意的字符,那么字符集就可以表示一个字符的范围例如[a-z]就可以表示a-z的任意一个字符,还可以[a-zA-Z0-9]来表示大小写字母
和数字,我们还可以将它来转义[^a]就是除了a的意思
注意的是这里的转意符不是单个\而是双\\
为什么使用两个反斜线?这是为了通过解释器进行转义,需要进行两个级别的转义:1.通过解释器的转义;2.通过 re 模块转义。如果不想使用两个反斜线,可以考
虑使用原始字符串,如:r'python\.org'。
3、选择符
为什么存在选择符呢?主要原因是假如我们想匹配两个字符串如“aaa”,“bbb”,我们就需要使用管道符(|)因此在匹配的时候就可以写成‘aaa|bbb’,当有的时候不
需要匹配这两的时候假如只需要匹配字符串“aaa”或者“bbb”就可以写成“p(aaa|bbb)”
4、表示个数(重复模式)
表示个数顾名思义就是来表示这个字符有多少个的意思主要模式(pattern)有:
(pattern)*:表示这个模式可以重复0次或者多次
(pattern)+:表示允许这个模式出现一次或者多次
(pattern){m,n}:表示允许这个模式重复m到n次
(pattern){n}:表示重复n次
(pattern){n,} :表示重复n或者更多次,最低重复n次
5、表示开头和结尾
当我们要匹配以什么什么开头或者以什么什么结尾是表示开头我们可以使用‘^a’表示以a开头,’$a‘表示以a结尾
re模块提供的功能:
1 、compile(pattern[, flags]) 根据包含正则表达式的字符串创建模式对象
2 、search(pattern, string[, flags]) 在字符串中寻找模式
3 、match(pattern, string[, flags]) 在字符串的开始处匹配模式
4 、split(pattern, string[, maxsplit=0]) 根据模式的匹配项来分割字符串
5 、findall(pattern, string) 列出字符串中模式的所有匹配项
6 、sub(pat, repl, string[, count=0]) 将字符串中所有pat的匹配项用repl替换
7 、escape(string) 将字符串中所有特殊正则表达式字符转义
语法:
re.match(pattern, string, flags=0)
pattern:匹配的正则表达式
string:要匹配的字符串。
flags:标志位,用于控制正则表达式的匹配模式,如:是否区分大小写,多行匹配等等(例子:print(re.match("^[a]+[d]+","aADdsdaa",flags=re.IGNORECASE)))
I = IGNORECASE = sre_compile.SRE_FLAG_IGNORECASE # ignore case
使匹配对大小写不敏感;字符类和字符串匹配字母时忽略大小写。举个例子,[A-Z]也可以匹配小写字母,Spam 可以匹配 "Spam", "spam", 或 "spAM"。这个小写字母并不考虑当前位置。 L = LOCALE = sre_compile.SRE_FLAG_LOCALE # assume current 8-bit locale
影响 "w, "W, "b, 和 "B,这取决于当前的本地化设置。
locales 是 C 语言库中的一项功能,是用来为需要考虑不同语言的编程提供帮助的。举个例子,如果你正在处理法文文本,你想用 "w+ 来匹配文字,但 "w 只匹配字符类 [A-Za-z];它并不能匹配 "é" 或 "?"。如果你的系统配置适当且本地化设置为法语,那么内部的 C 函数将告诉程序 "é" 也应该被认为是一个字母。当在编译正则表达式时使用 LOCALE 标志会得到用这些 C 函数来处理 "w 後的编译对象;这会更慢,但也会象你希望的那样可以用 "w+ 来匹配法文文本。 U = UNICODE = sre_compile.SRE_FLAG_UNICODE # assume unicode locale
统一成unicode编码 M = MULTILINE = sre_compile.SRE_FLAG_MULTILINE # make anchors look for newline
使用 "^" 只匹配字符串的开始,而 $ 则只匹配字符串的结尾和直接在换行前(如果有的话)的字符串结尾。当本标志指定後, "^" 匹配字符串的开始和字符串中每行的开始。同样的, $ 元字符匹配字符串结尾和字符串中每行的结尾(直接在每个换行之前)。 S = DOTALL = sre_compile.SRE_FLAG_DOTALL # make dot match newline
使 "." 特殊字符完全匹配任何字符,包括换行;没有这个标志, "." 匹配除了换行外的任何字符。 X = VERBOSE = sre_compile.SRE_FLAG_VERBOSE # ignore whitespace and comments
该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。当该标志被指定时,在 RE 字符串中的空白符被忽略,除非该空白符在字符类中或在反斜杠之後;这可以让你更清晰地组织和缩进 RE。它也可以允许你将注释写入 RE,这些注释会被引擎忽略;注释用 "#"号 来标识,不过该符号不能在字符串或反斜杠之後。
匹配的模式
re中的表示模式
|
模式 |
描述 |
|
^ |
匹配字符串的开头 |
|
$ |
匹配字符串的末尾。 |
|
. |
匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。 |
|
[...] |
用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
|
[^...] |
不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。 |
|
re* |
匹配0个或多个的表达式。 |
|
re+ |
匹配1个或多个的表达式。 |
|
re? |
匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
|
re{ n} |
|
|
re{ n,} |
精确匹配n个前面表达式。 |
|
re{ n, m} |
匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 |
|
a| b |
匹配a或b |
|
(re) |
G匹配括号内的表达式,也表示一个组 |
|
(?imx) |
正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域。 |
|
(?-imx) |
正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域。 |
|
(?: re) |
类似 (...), 但是不表示一个组 |
|
(?imx: re) |
在括号中使用i, m, 或 x 可选标志 |
|
(?-imx: re) |
在括号中不使用i, m, 或 x 可选标志 |
|
(?#...) |
注释. |
|
(?= re) |
前向肯定界定符。如果所含正则表达式,以 ... 表示,在当前位置成功匹配时成功,否则失败。但一旦所含表达式已经尝试,匹配引擎根本没有提高;模式的剩余部分还要尝试界定符的右边。 |
|
(?! re) |
前向否定界定符。与肯定界定符相反;当所含表达式不能在字符串当前位置匹配时成功 |
|
(?> re) |
匹配的独立模式,省去回溯。 |
|
\w |
匹配字母数字 |
|
\W |
匹配非字母数字 |
|
\s |
匹配任意空白字符,等价于 [\t\n\r\f]. |
|
\S |
匹配任意非空字符 |
|
\d |
匹配任意数字,等价于 [0-9]. |
|
\D |
匹配任意非数字 |
|
\A |
匹配字符串开始 |
|
\Z |
匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。c |
|
\z |
匹配字符串结束 |
|
\G |
匹配最后匹配完成的位置。 |
|
\b |
匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
|
\B |
匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
|
\n, \t, 等. |
匹配一个换行符。匹配一个制表符。等 |
|
\1...\9 |
匹配第n个分组的子表达式。 |
|
\10 |
匹配第n个分组的子表达式,如果它经匹配。否则指的是八进制字符码的表达式。 |
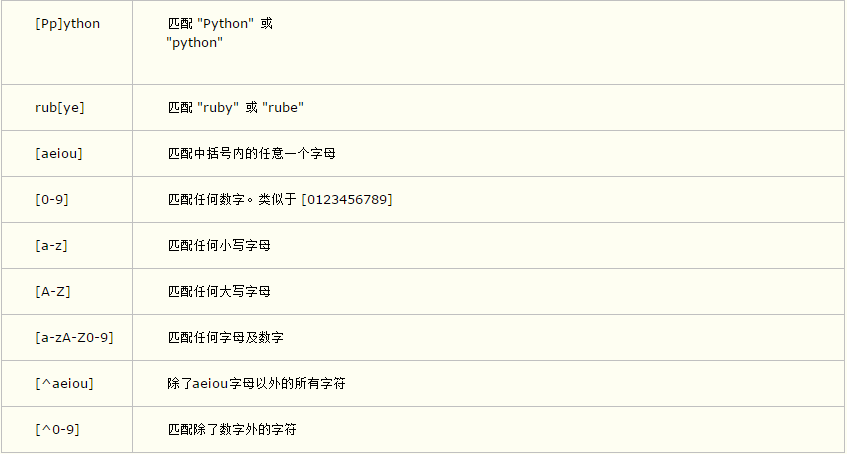
演示代码:
#!/usr/bin/env python import re #re.match从起始位置开始根据模型去字符串中匹配指定内容,匹配单个
#re .match(pattern, string, flags=0)
text = "111apple222pear"
f1 = re.match("\d+",text)
if f1:print(f1.group())
else:print("无")
"""运行一下试试,我们可以发现匹配到了111,所以我们可以确定的是,match匹配的是从起始位置来去匹配,
起始位置匹配到了则正常,否则返回空 “\d+”表示匹配任意数字出现1次或者更多次,如果把+号变成{1,2}
你就发现匹配的结果是11,这是因为{1,2}表示匹配一个或两个""" #re.search这个表示根据模式去匹配字符串中的匹配内容,也只匹配单个
#re.search(pattern, string, flags=0)
text = "aaa111apple222pear"
f1 = re.search("\d+",text)
if f1:print(f1.group())
else:print("无")
#这个例子我们发现,re.search把111匹配出来了所以他就是从整个字符串中匹配出模式符合的字符串,并且只匹配第一个 #group()与groups()的区别
text = "jnj111apple222pear"
f1 = re.search("([0-9]+)([a-z]+)",text)
if f1:
print(f1.group(0),f1.group(1),f1.group(2))
print(f1.groups())
else:print("无")
"""看到结果清晰可见,re模块匹配到后会将值传入子组,group()默认不写参数就返回匹配的整个值,
写入参数就返回参数对应的值,而groups()则返回匹配到的值的元组""" #匹配所有符合条件的值re.finadll(pattern, string, flags=0)
text = "jnj111apple222pear"
f1 = re.findall("([0-9]+)",text)
if f1:print(f1)
else:print("无")
"""执行上面的例子,得到的结果是个列表,列表中包含着所有符合条件的值([0-9]+)也可以写成(\d+)""" #用于替换匹配条件的字符串re.sub(pattern, repl, string, count=0, flags=0)
text = "jnj111apple222pear"
f1 = re.sub("([a-z]+)",'A',text)
if f1:print(f1)
else:print("无")
#输出的结果是所有的字母全变成大写的A了类似于str.repalce #re.split(pattern, string, maxsplit=0, flags=0)
content = "a1*b2c3*d4e5"
new_content = re.split('[\*]', content,2)
print (new_content)
#表示以*号作为分割符保持在列表中类似于str.split #将匹配规则赋予对象,这样做的好处是可以提升匹配的速度compile(pattern, flags=0)
import re
content = "a1b*2c3*d4e5"
aaa = re.compile('[\*]')
new_content = re.split(aaa, content)
print (new_content) #将字符串中所有特殊正则表达式字符转义escape(string)
import re
content = "a1b*2c3*d4e5"
ccc = re.escape(content)
print(ccc)
re演示代码
小练习
1、匹配出其中的年龄字段,字符串是:"name: aaa , age:22 , user:1112"
import re
str_in = 'name: aaa , age:22 , user:11121'
new_str_in = re.findall("[age]+\:\d{1,3}",str_in)
#表示age出现最低一次加上:号加上任意数字出现1到3次
print(new_str_in)
练习1
2、匹配出字符串中的所有网址,字符串是:"The url is www.aaa.com wwa.ccc.dsa www.cdsa.c"
import re
str_in = "The url is www.aaa.com wwa.ccc.dsa www.cdsa.c"
new_str_in = re.findall("www\.\S*\..{2,3}",str_in)
#以www加.加任意非空字符加任意字符出现次数为2到3次
print(new_str_in)
练习2
3、算出括号中的值并进行替换,字符串是:"The name is xiaoyan The money I have (5+5),6-1'
import re
str_in = 'The name is xiaoyan The money I have (5+5),6-1'
new_str_in = re.findall("\(*\d+[\+]+\d+\)*",str_in)#匹配出括号中的内容
value = new_str_in[0].strip('(,)')#取出括号
n1, n2 = value.split('+')#以+作为分割付
new_value = str(int(n1)+int(n2))#进行计算
aaa = str_in.replace(new_str_in[0],new_value)#进行替换
print(aaa)
练习3
官网网站提供的内置模块文档,点击这里
作者:北京小远
出处:http://www.cnblogs.com/bj-xy/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
简学Python第五章__模块介绍,常用内置模块的更多相关文章
- Python第五章__模块介绍,常用内置模块
Python第五章__模块介绍,常用内置模块 欢迎加入Linux_Python学习群 群号:478616847 目录: 模块与导入介绍 包的介绍 time &datetime模块 rando ...
- 简学Python第四章__装饰器、迭代器、列表生成式
Python第四章__装饰器.迭代器 欢迎加入Linux_Python学习群 群号:478616847 目录: 列表生成式 生成器 迭代器 单层装饰器(无参) 多层装饰器(有参) 冒泡算法 代码开发 ...
- 简学Python第三章__函数式编程、递归、内置函数
#cnblogs_post_body h2 { background: linear-gradient(to bottom, #18c0ff 0%,#0c7eff 100%); color: #fff ...
- 简学Python第六章__class面向对象编程与异常处理
Python第六章__class面向对象编程与异常处理 欢迎加入Linux_Python学习群 群号:478616847 目录: 面向对象的程序设计 类和对象 封装 继承与派生 多态与多态性 特性p ...
- 简学Python第七章__class面向对象高级用法与反射
Python第七章__class面向对象高级用法与反射 欢迎加入Linux_Python学习群 群号:478616847 目录: Python中关于oop的常用术语 类的特殊方法 元类 反射 一.P ...
- 简学Python第二章__巧学数据结构文件操作
#cnblogs_post_body h2 { background: linear-gradient(to bottom, #18c0ff 0%,#0c7eff 100%); color: #fff ...
- Python编程中 re正则表达式模块 介绍与使用教程
Python编程中 re正则表达式模块 介绍与使用教程 一.前言: 这篇文章是因为昨天写了一篇 shell script 的文章,在文章中俺大量调用多媒体素材与网址引用.这样就会有一个问题就是:随着俺 ...
- 简学Python第一章__进入PY的世界
#cnblogs_post_body h2 { background: linear-gradient(to bottom, #18c0ff 0%,#0c7eff 100%); color: #fff ...
- C语言老司机学Python (五)
今天看的是标准库概览. 操作系统接口: 用os模块实现. 针对文件和目录管理,还有个shutil模块可以用. 例句: import os os.getcwd() # 返回当前的工作目录 os.chdi ...
随机推荐
- conda 和 pip 安装,更新,删除
安装: pip install xxx conda install xxx 更新: pip install --upgrade xxx conda update xxx 删除: pip uninst ...
- 《从零开始学Swift》学习笔记(Day 7)——Swift 2.0中的print函数几种重载形式
原创文章,欢迎转载.转载请注明:关东升的博客 Swift 2.0中的print函数有4种重载形式: l print(_:).输出变量或常量到控制台,并且换行. l print(_:_:).输出 ...
- EasyDSS流媒体服务器软件(支持RTMP/HLS/HTTP-FLV/视频点播/视频直播)-正式环境安装部署攻略
EasyDSS流媒体服务器软件,提供一站式的转码.点播.直播.时移回放服务,极大地简化了开发和集成的工作. 其中,点播功能主要包含:上传.转码.分发.直播功能,主要包含:直播.录像, 直播支持RTMP ...
- EasyNVR互联网监控直播分发出RTMP、HLS、HTTP-FLV视频流说明介绍
背景需求 需求比视频流协议更重要,你想要什么,什么可以满足你的需求,这个很大程度上是需求在前,选择使用什么视频流是比较靠后的. 目前Easy系列互联网直播服务将全线支持HLS.RTMP.HTP-FLV ...
- echarts+thinkphp 学习写的第一个程序
一.前台 建个名为map.html,代码如下. <!doctype html><html lang="en"><head> <meta c ...
- hive表信息查询:查看表结构、表操作等
转自网友的,主要是自己备份下 有时候不记得! 问题导读:1.如何查看hive表结构?2.如何查看表结构信息?3.如何查看分区信息?4.哪个命令可以模糊搜索表 1.hive模糊搜索表 show tabl ...
- Django基础流程
软件环境: Pycharm 2018.1 Python 3.6 Django 2.0.3 1.新建项目 直接使用Pycharm的菜单来创建项目,命名为mysite. mysite mysite __i ...
- py 与 pyc 文件
本文要说明的问题 pyc 文件是什么 pyc 文件的作用 py 与 pyc 文件冲突 pyc 文件是什么 当 py 文件加载后,py 文件被二进制编码成 pyc 文件.py 文件的修改时间被记录到 p ...
- 通过配置rinetd来实现ECS跳转访问非外网连接的mongodb
跳转的原理通用,不单单针对mongo,其他需求应用也可以使用这种方式 生成环境中的mongodb迁移到了阿里云上的mongodb,由于机制的问题,mongodb不能直接被外网访问,故此采用的办法为 ...
- 基于Cpython的 GIL(Global Interpreter Lock)
一 介绍 定义: In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native t ...