DQN(Deep Reiforcement Learning) 发展历程(一)
目录
马尔可夫理论
马尔可夫性质
- P[St+1 | St] = P[St+1 | S1,...,St]
- 给定当前状态 St ,过去的状态可以不用考虑
- 当前状态 St 可以代表过去的所有状态
- 给定当前状态的条件下,未来的状态和过去的状态相互独立。
马尔可夫过程(MP)
- 形式化地描述了强化学习的环境。
- 包括二元组(S,P)
- 根据给定的转移概率矩阵P,从当前状态St转移到下一状态St+1,
- 基于模型的(Model-based):事先给出了转移概率矩阵P
马尔可夫奖励过程(MRP)
- 和马尔可夫过程相比,加入了奖励r,加入了折扣因子gamma,gamma在0~1之间。
- 马尔可夫奖励过程是一个四元组⟨S, P, R, γ⟩
- 需要折扣因子的原因是
- 使未来累积奖励在数学上易于计算
- 由于可能经过某些重复状态,避免累积奖励的计算成死循环
- 用于表示未来的不确定性
- gamma越大表示越看中未来的奖励
值函数(value function)
- 引入了值函数(value function),给每一个状态一个值V,以从当前状态St到评估未来的目标G的累积折扣奖励的大小
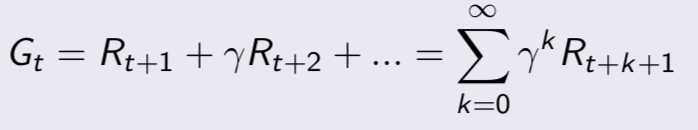
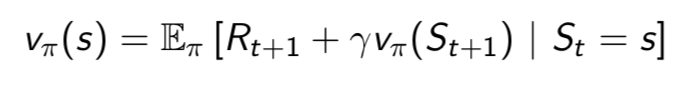
MRP求解
- v = R + γPv (矩阵形式)
- 直接解出上述方程时间复杂度O(n^3), 只适用于一些小规模问题
马尔可夫决策过程(MDP)
- 加入了一个动作因素a,用于每个状态的决策
- MDP是一个五元组⟨S, A, P, R, γ⟩
- 策略policy是从S到A的一个映射
效用函数
- 相比于值函数,加入了一个动作因素

优化的值函数
- 为了求最佳策略,在值函数求解时,选择一个最大的v来更新当前状态对应的v
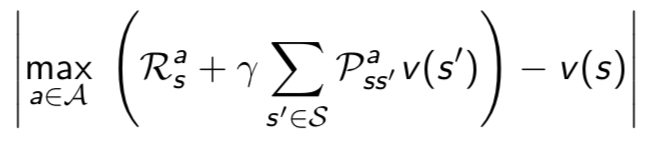
贝尔曼等式
- 和值函数的求解方法相比,不需要从当前状态到目标求解,只需要从当前状态到下一状态即可(根据递推公式)

参考
david siver 课程
https://home.cnblogs.com/u/pinard/
DQN(Deep Reiforcement Learning) 发展历程(一)的更多相关文章
- DQN(Deep Reiforcement Learning) 发展历程(五)
目录 值函数的近似 DQN Nature DQN DDQN Prioritized Replay DQN Dueling DQN 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) ...
- DQN(Deep Reiforcement Learning) 发展历程(三)
目录 不基于模型(Model-free)的预测 蒙特卡罗方法 时序差分方法 多步的时序差分方法 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发展历程(四) DQN发展 ...
- DQN(Deep Reiforcement Learning) 发展历程(四)
目录 不基于模型的控制 选取动作的方法 在策略上的学习(on-policy) 不在策略上的学习(off-policy) 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发 ...
- DQN(Deep Reiforcement Learning) 发展历程(二)
目录 动态规划 使用条件 分类 求解方法 参考 DQN发展历程(一) DQN发展历程(二) DQN发展历程(三) DQN发展历程(四) DQN发展历程(五) 动态规划 动态规划给出了求解强化学习的一种 ...
- [DQN] What is Deep Reinforcement Learning
已经成为DL中专门的一派,高大上的样子 Intro: MIT 6.S191 Lecture 6: Deep Reinforcement Learning Course: CS 294: Deep Re ...
- Deep Reinforcement Learning 基础知识(DQN方面)
Introduction 深度增强学习Deep Reinforcement Learning是将深度学习与增强学习结合起来从而实现从Perception感知到Action动作的端对端学习的一种全新的算 ...
- 论文笔记之:Dueling Network Architectures for Deep Reinforcement Learning
Dueling Network Architectures for Deep Reinforcement Learning ICML 2016 Best Paper 摘要:本文的贡献点主要是在 DQN ...
- Deep Reinforcement Learning: Pong from Pixels
这是一篇迟来很久的关于增强学习(Reinforcement Learning, RL)博文.增强学习最近非常火!你一定有所了解,现在的计算机能不但能够被全自动地训练去玩儿ATARI(译注:一种游戏机) ...
- 论文笔记之:Human-level control through deep reinforcement learning
Human-level control through deep reinforcement learning Nature 2015 Google DeepMind Abstract RL 理论 在 ...
随机推荐
- Thinkphp+ECharts生成柱状图
1.首先进ECharts官网下载echarts.js 点击下载,结合TP5讲解,主要代码在js里面,更多请到ECharts官网 2.引进echarts.js <!DOCTYPE html> ...
- Android工程中javax annotation Nullable找不到的替代方案
我们在某些Android开源库中会遇到下面的引用找不到的问题:import javax.annotation.Nonnull;import javax.annotation.Nullable; 其实A ...
- React Native八大Demo
参考资料:http://www.cnblogs.com/shaoting/p/7148240.html 下一个项目公司也打算使用react native.大致看了下原型设计,写几个小demo先试试水. ...
- 并发容器(四)ConcurrentHashMap 深入解析(JDK1.6)
这篇文章深入分析的是 JDK1.6的 ConcurrentHashMap 的实现原理,但在JDK1.8中又改进了 ConcurrentHashMap 的实现,废弃了 segments.虽然是已经被 ...
- As3截图转换为ByteArray传送给后台node的一种方法
最近将以前用As3+Php做的一个画板拿出来改成了As3+nodejs(expressjs4). Node: 1. 将图片存放的路径设置为静态公开的路径. app.use(express.static ...
- C# 实例化的执行顺序(转)
首先进行细分1.类的成员分为:字段,属性,方法,构造函数2.成员修饰符:静态成员,实例成员不考虑继承的关系执行顺序为:1.静态字段2.静态构造方法3.实例字段4.实例构造方法其中 属性和方法只有在调用 ...
- c#中(&&,||)与(&,|)的区别和应用
对于(&&,||),运算的对象是逻辑值,也就是True/False &&相当与中文的并且,||相当于中文的或者 .(叫做逻辑运算符又叫短路运算符) 运算结果只有下列四种 ...
- 03-01_WebLogic一些概念名词
WebLogic一些概念名词 域(Domain) 管理服务器(Administrative Server) 被管服务器(Managed Server,受管服务器) 集群(Cluster) 机器(Mac ...
- mysql主从不同步问题 Error_code: 1197
首先查看从的状态 mysql> show slave status \G *************************** 1. row *********************** ...
- Tidb数据库报错:Transaction too large
Tidb是一个支持ACID的分布式数据库,当你导入一个非常大的数据集时,这时候产生的事务相当严重,并且Tidb本身对事物的大小也是有一个严格的控制. 有事务大小的限制主要在于 TiKV 的实现用了一致 ...