ELK 日志学习
一.Elasticsearch 安装(所有的版本均使用5.5.0 ,且版需要相同 logstash \ kibana \ filebeat )
官网下载地址:https://www.elastic.co/cn/
(下载Linux版),上传到本地虚拟机服务器 ,tar -zxvf 解压,运行
遇到的问题1 : 不允许 root 用户启动
解决:
adduser test
passwd test
chown -R test 文件根目录
遇到的问题2:
max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
max number of threads [1024] for user [lishang] likely too low, increase to at least [2048]
解决:(切记,添加完退出登陆,再登陆,否则不会生效)
vim /etc/security/limits.conf
添加如下内容: * soft nofile * hard nofile * soft nproc * hard nproc
遇到的问题3:
max number of threads [1024] for user [lish] likely too low, increase to at least [2048]
解决:
vim /etc/security/limits.d/-nproc.conf
修改或者添加下:
* soft nproc
遇到的问题4:
max virtual memory areas vm.max_map_count [65530] likely too low, increase to at least [262144]
解决:
vim /etc/sysctl.conf
添加
vm.max_map_count=
退出执行
sysctl -p
遇到的问题5:
再虚拟机中 127.0.0.1:9200 成功 , 外部 :虚拟机 ip:9200 失败
解决:
在conf 文件下添加:
net.host: 虚拟机IP
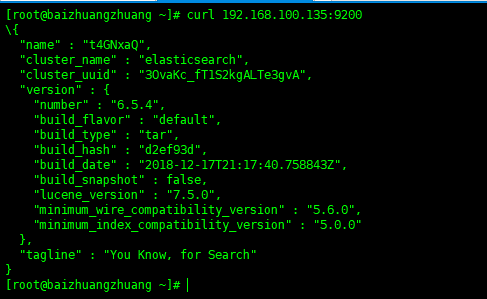
最后:在主机
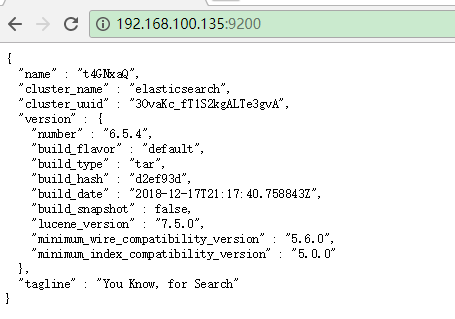
在虚拟机:
二、安装 kibana (数据展示)
在elasticsearch.org 官网有一系列的软件可以下载,下载5.5.0版本的 kibana
解压同elasticsrarch 上
修改配置:/kibana/config/kibana.yml
server.host:"0.0.0.0" elasticsearch.url : "http://localhost:9200"
启动 kibana
./bin/kibana
浏览器访问:服务器ip:5601
三、logstash 安装启动
下载解压同上,配置区别较大
1.在logstash 根目录下建立 logstash.conf 目录,内容包括如下
input {
beats{
port =>
}
}
filter{
}
output {
elasticsearch{
hosts => ["172.18.100.78:9200"]
index => "tomcat_ctmpweb_%{+YYYY.MM.dd}"
}
stdout{
codec =>rubydebug
}
}
~
其中 input 为输入数据端,此处设置数据来源为 filebeat 搜集,稍后配置
输出数据为 elasticsearch
启动 logstash
bin/logstash -f nginx_logs.conf
四、安装启动 filebeat
下载,解压,配置 filebeat.yml
1.配置日志文件读取路径

2.(默认输出到elasticsearch ),注释掉elasticsearch,开放 logstash

3.启动 filebeat
./filebeat -e -c filebeat.yml -d "publish"
五、分析日志
在监听的日志文件中加入new.log ,当有新的日志加入,会及时分析如下
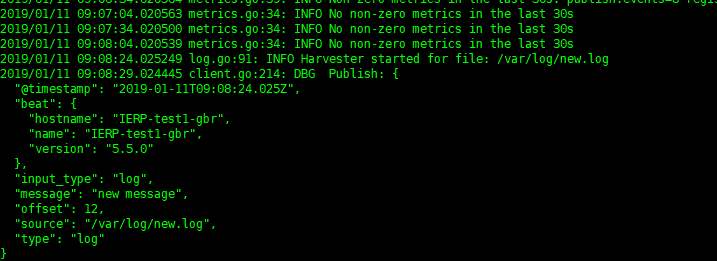
若想要重新开始扫描日志,删掉filebeat 目录下data目录中的数据,则filebeat 会重新扫描

ELK 日志学习的更多相关文章
- ELK日志分析 学习笔记
(贴一篇之前工作期间整理的elk学习笔记) ELK官网 https://www.elastic.co ELK日志分析系统 学习笔记 概念:ELK = elasticsearch + logstas ...
- 浅谈ELK日志分析平台
作者:珂珂链接:https://zhuanlan.zhihu.com/p/22104361来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 小编的话 “技术干货”系列文章 ...
- ELK日志分析系统-Logstack
ELK日志分析系统 作者:Danbo 2016-*-* 本文是学习笔记,参考ELK Stack中文指南,链接:https://www.gitbook.com/book/chenryn/kibana-g ...
- Docker笔记(十):使用Docker来搭建一套ELK日志分析系统
一段时间没关注ELK(elasticsearch —— 搜索引擎,可用于存储.索引日志, logstash —— 可用于日志传输.转换,kibana —— WebUI,将日志可视化),发现最新版已到7 ...
- ELK 日志平台构建
elastic中文社区 https://elasticsearch.cn/ 完整参考 ELK实时日志分析平台环境部署--完整记录 https://www.cnblogs.com/kevingrace/ ...
- ELK日志分析之安装
ELK日志分析之安装 1.介绍: NRT elasticsearch是一个近似实时的搜索平台,从索引文档到可搜索有些延迟,通常为1秒. 集群 集群就是一个或多个节点存储数据,其中一个节点为主节点,这个 ...
- 【ELK】ELK日志套件安装与使用
ELK日志套件安装与使用 1.ELK介绍 ELK不是一款软件,而是elasticsearch+Logstash+kibana三款开源软件组合而成的日志收集处理套件,堪称神器.其中Logstash负 ...
- springboot 集成 elk 日志收集功能
Lilishop 技术栈 官方公众号 & 开源不易,如有帮助请点Star 介绍 官网:https://pickmall.cn Lilishop 是一款Java开发,基于SpringBoot研发 ...
- ELK 日志分析体系
ELK 日志分析体系 ELK 是指 Elasticsearch.Logstash.Kibana三个开源软件的组合. logstash 负责日志的收集,处 ...
随机推荐
- http 文件传输
http 文件传输 https://www.zhihu.com/question/58118565 转载自:http://www.voidcn.com/article/p-rpdhbjib-m.htm ...
- python大法好——变量、常量、input()、数据类型、字符串、格式化输出、运算符、流程控制语句、进制、字符编码
python基础知识 1.变量 变量:把程序运算的中间结果临时存到内存里,以备后面的代码可以继续调用. 作用:A.存储数据. B.标记数据. 变量的声明规则: A:变量名只能是字母,数字或下划线任意组 ...
- kubernets之endpoints
注:本文整理自网络 endpoint endpoint是k8s集群中的一个资源对象,存储在etcd中,用来记录一个service对应的所有pod的访问地址.service配置selector,endp ...
- JVM虚拟机宕机_java.lang.OutOfMemoryError: unable to create new native thread
原因:当前用户的系统最最大程序数数已达到最大值,使用ulimit -u可以看到是1024 解决办法:在当前用户下使用ulimit -u 65535 然后再执行jsp,一切ok 功能说明:控 ...
- android的体系结构
android 体系结构:采用软件堆层的架构 ,四层1应用程序“: 提供一系列的核心应用程序 2应用程序框架 :提供安卓平台基本的管理功能和组件重用机制activityManager 管理应用程序的生 ...
- SQL Server CLR 使用 C# 自定义存储过程和触发器
资源来源:https://www.cnblogs.com/Brambling/p/8016060.html SQL Server CLR 使用 C# 自定义存储过程和触发器 这一篇博客接着上一篇博 ...
- C++复习:C++的类型转换
C++的类型转换 1 类型转换名称和语法 C风格的强制类型转换(Type Cast)很简单,不管什么类型的转换统统是: TYPE b = (TYPE)a C++风格的类型转换提供了4种类型转换操作符来 ...
- linux 内核假死循环导致的问题
[, comm: -IFileSender Tainted: G B ENX -- ZTE Grantley/S1008 [:[<ffffffff810fb2cb>] [<fffff ...
- linux 再多的running也挡不住锁
再续<linux 3.10 一次softlock排查>,看运行态进程数量之多: crash> mach MACHINE TYPE: x86_64 MEMORY SIZE: GB CP ...
- C++17尝鲜:结构化绑定声明(Structured Binding Declaration)
结构化绑定声明 结构化绑定声明,是指在一次声明中同时引入多个变量,同时绑定初始化表达式的各个子对象的语法形式. 结构化绑定声明使用auto来声明多个变量,所有变量都必须用中括号括起来. cv-auto ...