初学Nutch之简介与安装
1、Nutch简介
Nutch是一个由Java实 现的,开放源代码(open-source)的web搜索引擎。主要用于收集网页数据,然后对其进行分析,建立索引,以提供相应的接口来对其网页数据进行 查询的一套工具。其底层使用了Hadoop来做分布式计算与存储,索引使用了Solr分布式索引框架来做,Solr是一个开源的全文索引框架,从 Nutch 1.3开始,其集成了这个索引架构。
1.1 Nutch的目标
Nutch 致力于让每个人能很容易,同时花费很少就可以配置世界一流的Web搜索引擎。为了完成这一宏伟的目标,Nutch必须能够做到:
- 每个月取几十亿网页
- 为这些网页维护一个索引
- 对索引文件进行每秒上千次的搜索
- 提供高质量的搜索结果
- 以最小的成本运作
1.2 Nutch的优点
- 透明度
Nutch是开放源代码的,因此任何人都可以查看他的排序算法是 如何工作的。商业的搜索引擎排序算法都是保密的,我们无法知道为什么搜索出来的排序结果是如何算出来的。更进一步,一些搜索引擎允许竞价排名,比如百度, 这样的索引结果并不是和站点内容相关的。因此Nutch对学术搜索和政府类站点的搜索来说,是个好选择。因为一个公平的排序结果是非常重要的。
- 扩展性
你是不是不喜欢其他的搜索引擎展现结果的方式呢?那就用 Nutch 写你自己的搜索引擎吧。 Nutch 是非常灵活的,他可以被很好的客户订制并集成到你的应用程序中。使用Nutch 的插件机制,Nutch 可以作为一个搜索不同信息载体的搜索平台。当然,最简单的就是集成Nutch到你的站点,为你的用户提供搜索服务。
- 对搜索引擎的理解
我们并没有google的源代码,因此学习搜索引擎Nutch是个不错的选择。了解一个大型分布式的搜索引擎如何工作是一件让人很受益的事情。 在写Nutch的过程中,从学院派和工业派借鉴了很多知识:比如:Nutch的核心部分目前已经被重新用 Map Reduce 实现了。Map Reduce 是一个分布式的处理模型,最先是从 Google 实验室提出来的。并且 Nutch 也吸引了很多研究者,他们非常乐于尝试新的搜索算法,因为对Nutch 来说,这是非常容易实现扩展的。
1.3 Nutch与Lucene关系
Lucene是一个Java高性能全文索引引擎工具包可以方便的嵌入到各种实际应用中实现全文索引搜索功能。它提供了一系列API,能够对文档进行预处理、过滤、分析、索引和检索排序。在保持高效和简单的特点之外,还保证了开发者可以自由定制和组合各种核心功能。Nutch是一个应用程序,是一个以Lucene为基础实现的搜索引擎应用,Lucene为Nutch 提供了文本搜索和索引的API,Nutch不仅提供搜索,而且还有数据抓取的功能。
简单的说:
- Lucene 不是完整的应用程序,而是一个用于实现全文检索的软件库。
- Nutch 是一个应用程序,可以以 Lucene 为基础实现搜索引擎应用。
一个常见的问题是:我应该使用Lucene还是Nutch?
最简单的回答是:如果你不需要抓取数据的话,应该使用Lucene。
常见的应用场合是:你有数据源,需要为这些数据提供一个搜索页面。在这种情况下,最好的方式是直接从数据库中取出数据并用Lucene API建立索引。
在你没有本地数据源,或者数据源非常分散的情况下,应该使用Nutch。
2、Nutch安装
我们现在进行的是Nutch的单机版安装以及配置。
2.1准备
JDK版本:jdk-7u15-linux-x64.tar.gz
Nutch版本:apache-nutch-1.2-bin.tar.gz
Tomcat版本:apache-tomcat-7.0.61.tar.gz
2.2 安装CentOS
2.3 安装JDK
2.4 安装Tomcat
将apache-tomcat-7.0.61.tar.gz拷贝到CentOS系统内,解压。

tar -zxvf /home/hadoop/下载/apache-tomcat-7.0.61.tar.gz -C /opt
添加Tomcat环境变量
vim /etc/profile source /etc/profile
# set tomcat environment
export CATALINA_HOME=/opt/apache-tomcat-7.0.61/
export CATALINA_BASE=/opt/apache-tomcat-7.0.61/
export PATH=$PATH:$ CATALINA_HOME/bin

启动tomcat
[root@localhost hadoop]# cd /opt/apache-tomcat-7.0.61/
[root@localhost apache-tomcat-7.0.61]# bin/catalina.sh start
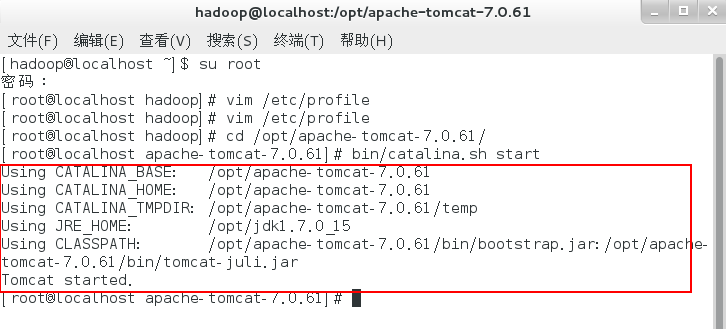
访问地址:http://127.0.0.1:8080
2.5 安装Nutch
将apache-nutch-1.2-bin.tar.gz拷贝到CentOS系统内,解压。
tar -zxvf /home/hadoop/下载/apache-tomcat-7.0.61.tar.gz -C /opt

测试Nutch命令
[root@localhost apache-tomcat-7.0.61]# cd /opt/nutch-1.2/
[root@localhost nutch-1.2]# bin/nutch
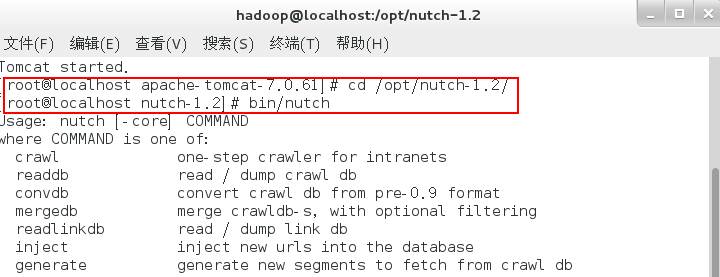
将nutch自带的war文件拷贝到webapps下并解压,修改文件夹名称为ROOT

启动tomcat
[root@localhost nutch-1.2]# cd /opt/apache-tomcat-7.0.61/
[root@localhost apache-tomcat-7.0.61]# bin/catalina.sh start
# bin/catalina.sh stop #关闭tomcat命令
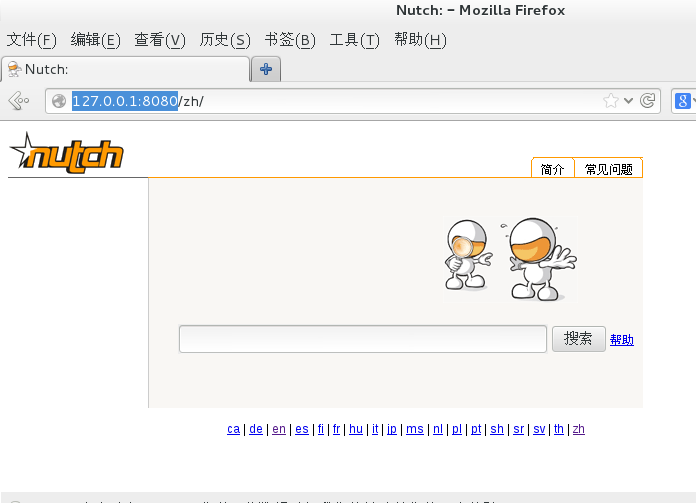
2.6 体验Nutch
增加要抓取的页面
[root@localhost apache-tomcat-7.0.61]# cd /opt/nutch-1.2/
[root@localhost nutch-1.2]# mkdir urls
[root@localhost nutch-1.2]#echo http://news.163.com/>>urls/163
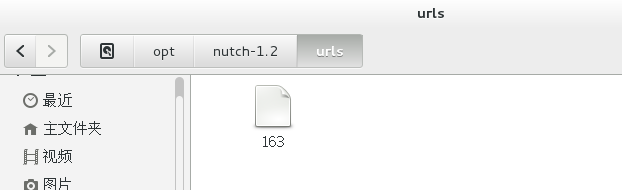
编辑conf/crawl-urlfilter.txt文件,设定要抓取的网址信息。
[root@localhost nutch-1.2]#vim conf/crawl-urlfilter.txt
修改MY.DOMAIN.NAME为:
# accept hosts in MY.DOMAIN.NAME
+^http://([a-z0-9]*\.)*163.com/
编辑conf/nutch-site.xml文件,增加代理的属性,并编辑相应的属性值
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration>
<property>
<name>http.agent.name</name>
<value>hehaiyang</value>
<description>HTTP 'User-Agent' request header. MUST NOT be empty - please set this to a single word uniquely related to your organization. NOTE: You should also check other related properties: http.robots.agents http.agent.description http.agent.url http.agent.email http.agent.version and set their values appropriately.</description>
</property>
<property>
<name>http.robots.agents</name>
<value>spider,*</value>
<description>The agent strings we'll look for in robots.txt files,
comma-separated, in decreasing order of precedence. You should
put the value of http.agent.name as the first agent name, and keep the
default * at the end of the list. E.g.: BlurflDev,Blurfl,*
</description>
</property>
<property>
<name>http.agent.description</name>
<value></value>
<description>Further description of our bot- this text is used in the User-Agent header. It appears in parenthesis after the agent name.</description>
</property>
<property>
<name>http.agent.url</name>
<value></value>
<description>A URL to advertise in the User-Agent header. This will appear in parenthesis after the agent name. Custom dictates that this should be a URL of a page explaining the purpose and behavior of this crawler.</description>
</property>
<property>
<name>http.agent.email</name>
<value></value>
<description>An email address to advertise in the HTTP 'From' request header and User-Agent header. A good practice is to mangle this address (e.g. 'info at example dot com') to avoid spamming.</description>
</property>
</configuration>
设定搜索目录(是由于默认的segment路径与我们实际的路径不符所造成的)
[root@localhost nutch-1.2]# cd /opt/apache-tomcat-7.0.61/
[root@localhost apache-tomcat-7.0.61]# vim webapps/ROOT/WEB-INF/classes/nutch-site.xml
增加四行代码,修改成为
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration>
<property>
<name>searcher.dir</name>
<value>/opt/nutch-1.2/crawl.demo</value>
</property>
</configuration>
这里的/opt/nutch-1.2/crawl.demo是nutch路径,爬虫到时候的数据就会放在程序新建的crawl.demo下面,即nutch抓取的页面的保存目录。
nutch对中文的支持还不完善,需要修改tomcat文件夹下conf/server.xml文件
[root@localhost apache-tomcat-7.0.61]# vim conf/server.xml
增加两句,修改为
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" URIEncoding="UTF-8" useBodyEncodingForURI="true" />
抓取网页
[root@localhost nutch-1.2]# bin/nutch crawl urls -dir crawl.demo -depth 2 -threads 4 -topN 5 >& crawl.log

抓取过程写入crawl.log中,可以查看如下
搜索发生错误时,查看crawl.log文件是一个不错的办法。
查看结果
非中文搜索结果:
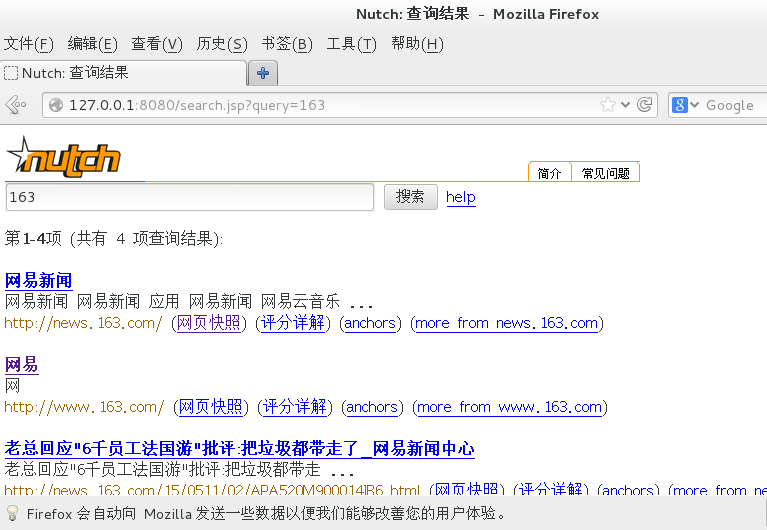
中文搜索结果:

初学Nutch之简介与安装的更多相关文章
- Nutch之简介与安装
初学Nutch之简介与安装 初学Nutch之简介与安装 1.Nutch简介 Nutch是一个由Java实 现的,开放源代码(open-source)的web搜索引擎.主要用于收集网页数据,然后对其 ...
- Nutch搜索引擎(第2期)_ Solr简介及安装
1.Solr简介 Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器.同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置.可扩展并对查询性能进行了优化 ...
- Nutch搜索引擎Solr简介及安装
Nutch搜索引擎(第2期)_ Solr简介及安装 1.Solr简介 Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器.同时对其进行了扩展,提供了比Lucene更为丰富的 ...
- Node.js 教程 01 - 简介、安装及配置
系列目录: Node.js 教程 01 - 简介.安装及配置 Node.js 教程 02 - 经典的Hello World Node.js 教程 03 - 创建HTTP服务器 Node.js 教程 0 ...
- Java Gradle入门指南之简介、安装与任务管理
这是一篇Java Gradle入门级的随笔,主要介绍Gradle的安装与基本语法,这些内容是理解和创建build.gradle的基础,关于Gradle各种插件的使用将会在其他随笔中介绍. ...
- 细细品味Storm_Storm简介及安装
Storm是由专业数据分析公司BackType开发的一个分布式实时数据处理软件,可以简单.高效.可靠地处理大量的数据流.Twitter在2011年7月收购该公司,并于2011年9月底正式将Storm项 ...
- VMware vSphere 5.1 简介与安装
虚拟化系列-VMware vSphere 5.1 简介与安装 标签: 虚拟化 esxi5.1 VMware vSphere 5.1 原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 . ...
- Node.js的简介和安装
一.Node.js的简介和安装 a) 什么是Node.js? Node.js是一个开发平台 让JavaScript运行在服务器端的开发平台 ---简单点说就是用JavaScript写服务器 ...
- DNN简介以及安装
开源框架DNN简介以及安装 donetnuke 是一款免费的开源cms框架,目前也有收费版,不过免费版也可以适应大家大部分的需求.我前些阵子是老板让我在20天内,做好一个官网并且发布,并且指定使用dn ...
随机推荐
- XAML 布局StackPanel
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/Fanbin168/article/details/24768459 <Window x:Cla ...
- pycham database查看db.sqlites文件 无内容解决方法
初学django,使用pycharm IDE的时候,通过使用默认的sqlites数据库,执行问makemigration 和migrate操作之后,控制台正常输出类似如下结果,按照道理应该生成了数据表 ...
- Python2.7-copy
copy 模块,python 中的‘=’是使左边的对象成为右边对象的一个引用,对不可变对象(如数字,字符串等)使用‘=’一般不会出现问题,但当对字典,列表等可变对象进行‘=’操作时,要注意修改其中一个 ...
- Java安全通信:HTTPS与SSL
转载地址:http://www.cnblogs.com/devinzhang/archive/2012/02/28/2371631.html Java安全通信:HTTPS与SSL 1. HTTPS概念 ...
- 面试题之O(n)内旋转字符串
样例: 字符串“abcd1234"左移3位结果为”234abcd1“ K:左移位数 L:字符串长度 方案1:暴力 O(K * L) 可以每次将数组中的元素左移一位,循环K次. abcd123 ...
- PRML2-概率分布
本博文来自<PRML第二章> 在第一章中说了对于模式识别问题来说,核心角色就是概率论.本章的目的一方面是为了介绍概率分布,另一方面也是为了对后面遇到的那些复杂问题先打下基础.本章关于分布上 ...
- rownum与row_number() OVER (PARTITION BY COL1 ORDER BY COL2)
1)rownum 为查询结果排序.使用rownum进行排序的时候是先对结果集加入伪列rownum然后再进行排序 select rownum n, a.* from ps_user a order by ...
- PuTTY+Xming实现X11的ssh转发
1 需求分析 有些Linux程序还是不能完全离开窗口环境,或者说离开后操作不方便.其中Oracle就是这样一个程序,其工具程序大多数能够在纯命令行静默执行,如 OCI,DBCA,NetCA等,但是工作 ...
- [Usaco2012 Dec]First! BZOJ3012
分析: 其实我们可以很容易的想到,如果一个串是另一个串的子串,那么必定长的那个串不可能是字典序最小的串.其次,如果一个串为了使他成为字典序最小的串儿出现了矛盾的情况,那么也不可能是字典序最小的串.那么 ...
- solr服务器搭建与Tomact整合及使用
一:solr服务器的搭建 1:搭建全新的为solr专用的solr服务器: 在自己电脑上搭建两台Tomact服务器,一台仍为应用服务器,一台作为solr服务器,应用服务器按照正常Tomact服务器搭建即 ...