Kubernetes学习之路(二十二)之Pod资源调度
Pod资源调度
API Server在接受客户端提交Pod对象创建请求后,然后是通过调度器(kube-schedule)从集群中选择一个可用的最佳节点来创建并运行Pod。而这一个创建Pod对象,在调度的过程当中有3个阶段:节点预选、节点优选、节点选定,从而筛选出最佳的节点。如图:

- 节点预选:基于一系列的预选规则对每个节点进行检查,将那些不符合条件的节点过滤,从而完成节点的预选
- 节点优选:对预选出的节点进行优先级排序,以便选出最合适运行Pod对象的节点
- 节点选定:从优先级排序结果中挑选出优先级最高的节点运行Pod,当这类节点多于1个时,则进行随机选择
当我们有需求要将某些Pod资源运行在特定的节点上时,我们可以通过组合节点标签,以及Pod标签或标签选择器来匹配特定的预选策略并完成调度,如MatchInterPodAfinity、MatchNodeSelector、PodToleratesNodeTaints等预选策略,这些策略常用于为用户提供自定义Pod亲和性或反亲和性、节点亲和性以及基于污点及容忍度的调度机制。
1、常用的预选策略
预选策略实际上就是节点过滤器,例如节点标签必须能够匹配到Pod资源的标签选择器(MatchNodeSelector实现的规则),以及Pod容器的资源请求量不能大于节点上剩余的可分配资源(PodFitsResource规则)等等。执行预选操作,调度器会逐一根据规则进行筛选,如果预选没能选定一个合适的节点,此时Pod会一直处于Pending状态,直到有一个可用节点完成调度。其常用的预选策略如下:
- CheckNodeCondition:检查是否可以在节点报告磁盘、网络不可用或未准备好的情况下将Pod对象调度其上。
- HostName:如果Pod对象拥有spec.hostname属性,则检查节点名称字符串是否和该属性值匹配。
- PodFitsHostPorts:如果Pod对象定义了ports.hostPort属性,则检查Pod指定的端口是否已经被节点上的其他容器或服务占用。
- MatchNodeSelector:如果Pod对象定义了spec.nodeSelector属性,则检查节点标签是否和该属性匹配。
- NoDiskConflict:检查Pod对象请求的存储卷在该节点上可用。
- PodFitsResources:检查节点上的资源(CPU、内存)可用性是否满足Pod对象的运行需求。
- PodToleratesNodeTaints:如果Pod对象中定义了spec.tolerations属性,则需要检查该属性值是否可以接纳节点定义的污点(taints)。
- PodToleratesNodeNoExecuteTaints:如果Pod对象定义了spec.tolerations属性,检查该属性是否接纳节点的NoExecute类型的污点。
- CheckNodeLabelPresence:仅检查节点上指定的所有标签的存在性,要检查的标签以及其可否存在取决于用户的定义。
- CheckServiceAffinity:根据当前Pod对象所属的Service已有其他Pod对象所运行的节点调度,目前是将相同的Service的Pod对象放在同一个或同一类节点上。
- MaxEBSVolumeCount:检查节点上是否已挂载EBS存储卷数量是否超过了设置的最大值,默认值:39
- MaxGCEPDVolumeCount:检查节点上已挂载的GCE PD存储卷是否超过了设置的最大值,默认值:16
- MaxAzureDiskVolumeCount:检查节点上已挂载的Azure Disk存储卷数量是否超过了设置的最大值,默认值:16
- CheckVolumeBinding:检查节点上已绑定和未绑定的PVC是否满足Pod对象的存储卷需求。
- NoVolumeZoneConflct:在给定了区域限制的前提下,检查在该节点上部署Pod对象是否存在存储卷冲突。
- CheckNodeMemoryPressure:在给定了节点已经上报了存在内存资源压力过大的状态,则需要检查该Pod是否可以调度到该节点上。
- CheckNodePIDPressure:如果给定的节点已经报告了存在PID资源压力过大的状态,则需要检查该Pod是否可以调度到该节点上。
- CheckNodeDiskPressure:如果给定的节点存在磁盘资源压力过大,则检查该Pod对象是否可以调度到该节点上。
- MatchInterPodAffinity:检查给定的节点能否可以满足Pod对象的亲和性和反亲和性条件,用来实现Pod亲和性调度或反亲和性调度。
在上面的这些预选策略里面,CheckNodeLabelPressure和CheckServiceAffinity可以在预选过程中结合用户自定义调度逻辑,这些策略叫做可配置策略。其他不接受参数进行自定义配置的称为静态策略。
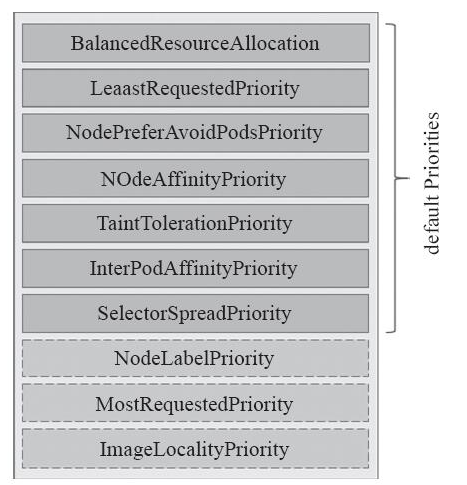
2、优选函数
预选策略筛选出一个节点列表就会进入优选阶段,在这个过程调度器会向每个通过预选的节点传递一系列的优选函数来计算其优先级分值,优先级分值介于0-10之间,其中0表示不适用,10表示最适合托管该Pod对象。
另外,调度器还支持给每个优选函数指定一个简单的值,表示权重,进行节点优先级分值计算时,它首先将每个优选函数的计算得分乘以权重,然后再将所有优选函数的得分相加,从而得出节点的最终优先级分值。权重可以让管理员定义优选函数倾向性的能力,其计算优先级的得分公式如下:
finalScoreNode = (weight1 * priorityFunc1) + (weight2 * priorityFunc2) + ......
下图是关于优选函数的列表图:
3、节点亲和调度
节点亲和性是用来确定Pod对象调度到哪一个节点的规则,这些规则基于节点上的自定义标签和Pod对象上指定的标签选择器进行定义。
定义节点亲和性规则有2种:硬亲和性(require)和软亲和性(preferred)
- 硬亲和性:实现的是强制性规则,是Pod调度时必须满足的规则,否则Pod对象的状态会一直是Pending
- 软亲和性:实现的是一种柔性调度限制,在Pod调度时可以尽量满足其规则,在无法满足规则时,可以调度到一个不匹配规则的节点之上。
定义节点亲和规则的两个要点:一是节点配置是否合乎需求的标签,而是Pod对象定义合理的标签选择器,这样才能够基于标签选择出期望的目标节点。
需要注意的是preferredDuringSchedulingIgnoredDuringExecution和requiredDuringSchedulingIgnoredDuringExecution名字中后半段字符串IgnoredDuringExecution表示的是,在Pod资源基于节点亲和性规则调度到某个节点之后,如果节点的标签发生了改变,调度器不会讲Pod对象从该节点上移除,因为该规则仅对新建的Pod对象有效。
3.1、节点硬亲和性
下面的配置清单中定义的Pod对象,使用节点硬亲和性和规则定义将当前Pod调度到标签为zone=foo的节点上:
apiVersion: v1
kind: Pod
metadata:
name: with-require-nodeaffinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- {key: zone,operator: In,values: ["foo"]}
containers:
- name: myapp
image: ikubernetes/myapp:v1
#创建Pod对象
[root@k8s-master ~]# kubectl apply -f require-nodeAffinity-pod.yaml
pod/with-require-nodeaffinity created
#由于集群中并没有节点含有节点标签为zone=foo,所以创建的Pod一直处于Pending状态
[root@k8s-master ~]# kubectl get pods with-require-nodeaffinity
NAME READY STATUS RESTARTS AGE
with-require-nodeaffinity 0/1 Pending 0 35s
#查看Pending具体的原因
[root@k8s-master ~]# kubectl describe pods with-require-nodeaffinity
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 3s (x21 over 1m) default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
#给node01节点打上zone=foo的标签,可以看到成功调度到node01节点上
[root@k8s-master ~]# kubectl label node k8s-node01 zone=foo
node/k8s-node01 labeled
[root@k8s-master ~]# kubectl describe pods with-require-nodeaffinity
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 58s (x25 over 2m) default-scheduler 0/3 nodes are available: 3 node(s) didn't match node selector.
Normal Pulled 4s kubelet, k8s-node01 Container image "ikubernetes/myapp:v1" already present on machine
Normal Created 4s kubelet, k8s-node01 Created container
Normal Started 4s kubelet, k8s-node01 Started container
[root@k8s-master ~]# kubectl get pods with-require-nodeaffinity -o wide
NAME READY STATUS RESTARTS AGE IP NODE
with-require-nodeaffinity 1/1 Running 0 6m 10.244.1.12 k8s-node01
在定义节点亲和性时,requiredDuringSchedulingIgnoredDuringExecution字段的值是一个对象列表,用于定义节点硬亲和性,它可以由一个或多个nodeSelectorTerms定义的对象组成,此时值需要满足其中一个nodeSelectorTerms即可。
而nodeSelectorTerms用来定义节点选择器的条目,它的值也是一个对象列表,由1个或多个matchExpressions对象定义的匹配规则组成,多个规则是逻辑与的关系,这就表示某个节点的标签必须要满足同一个nodeSelectorTerms下所有的matchExpression对象定义的规则才能够成功调度。如下:
#如下配置清单,必须存在满足标签zone=foo和ssd=true的节点才能够调度成功
apiVersion: v1
kind: Pod
metadata:
name: with-require-nodeaffinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- {key: zone, operator: In, values: ["foo"]}
- {key: ssd, operator: Exists, values: []} #增加一个规则
containers:
- name: myapp
image: ikubernetes/myapp:v1
[root@k8s-master ~]# kubectl apply -f require-nodeAffinity-pod.yaml
pod/with-require-nodeaffinity created
[root@k8s-master ~]# kubectl get pods with-require-nodeaffinity
NAME READY STATUS RESTARTS AGE
with-require-nodeaffinity 0/1 Pending 0 16s
[root@k8s-master ~]# kubectl label node k8s-node01 ssd=true
node/k8s-node01 labeled
[root@k8s-master ~]# kubectl get pods with-require-nodeaffinity
NAME READY STATUS RESTARTS AGE
with-require-nodeaffinity 1/1 Running 0 2m
在预选策略中,还可以通过节点资源的可用性去限制能够成功调度,如下配置清单:要求的资源为6核心CPU和20G内存,节点是无法满足该容器的资源需求,因此也会调度失败,Pod资源会处于Pending状态。
apiVersion: v1
kind: Pod
metadata:
name: with-require-nodeaffinity
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
resources:
requests:
cpu: 6
memory: 20Gi
3.2、节点软亲和性
看下面一个配置清单:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy-with-node-affinity
spec:
replicas: 5
selector:
matchLabels:
app: myapp
template:
metadata:
name: myapp-pod
labels:
app: myapp
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 60
preference:
matchExpressions:
- {key: zone, operator: In, values: ["foo"]}
- weight: 30
preference:
matchExpressions:
- {key: ssd, operator: Exists, values: []}
containers:
- name: myapp
image: ikubernetes/myapp:v1
#首先先给node02和master都打上标签,master标签为zone=foo,node02标签为ssd=true,这里node01是没有对应标签的
[root@k8s-master ~]# kubectl label node k8s-node02 ssd=true
node/k8s-node02 labeled
[root@k8s-master ~]# kubectl label node k8s-master zone=foo
node/k8s-master labeled
#进行创建
[root@k8s-master ~]# kubectl apply -f deploy-with-preferred-nodeAffinity.yaml
deployment.apps/myapp-deploy-with-node-affinity2 created
#可以看到5个Pod分别分布在不同的节点上,node01上没有对应的标签也会调度上进行创建Pod,体现软亲和性
[root@k8s-master ~]# kubectl get pods -o wide |grep deploy-with
myapp-deploy-with-node-affinity2-75b8f65f87-2gqjv 1/1 Running 0 11s 10.244.2.4 k8s-node02
myapp-deploy-with-node-affinity2-75b8f65f87-7l2sg 1/1 Running 0 11s 10.244.0.4 k8s-master
myapp-deploy-with-node-affinity2-75b8f65f87-cdrxx 1/1 Running 0 11s 10.244.2.3 k8s-node02
myapp-deploy-with-node-affinity2-75b8f65f87-j77f6 1/1 Running 0 11s 10.244.1.36 k8s-node01
myapp-deploy-with-node-affinity2-75b8f65f87-wt6tq 1/1 Running 0 11s 10.244.0.3 k8s-master
#如果我们给node01打上zone=foo,ssd=true的标签,再去创建时,你会发现所有的Pod都调度在这个节点上。因为节点的软亲和性,会尽力满足Pod中定义的规则,如下:
[root@k8s-master ~]# kubectl label node k8s-node01 zone=foo
[root@k8s-master ~]# kubectl label node k8s-node01 ssd=true
[root@k8s-master ~]# kubectl get pods -o wide |grep deploy-with
myapp-deploy-with-node-affinity2-75b8f65f87-4lwsw 0/1 ContainerCreating 0 3s <none> k8s-node01
myapp-deploy-with-node-affinity2-75b8f65f87-dxbxf 1/1 Running 0 3s 10.244.1.31 k8s-node01
myapp-deploy-with-node-affinity2-75b8f65f87-lnhgm 0/1 ContainerCreating 0 3s <none> k8s-node01
myapp-deploy-with-node-affinity2-75b8f65f87-snxbc 0/1 ContainerCreating 0 3s <none> k8s-node01
myapp-deploy-with-node-affinity2-75b8f65f87-zx8ck 1/1 Running 0 3s 10.244.1.33 k8s-node01
上面的实验结果显示,当2个标签没有都存在一个node节点上时,Pod对象会被分散在集群中的三个节点上进行创建并运行,之所以如此,是因为使用了 节点软亲和性的预选方式,所有的节点都能够通过MatchNodeSelector预选策略的筛选。当我们将2个标签都集合在node01上时,所有Pod对象都会运行在node01之上。
4、Pod资源亲和调度
在出于高效通信的需求,有时需要将一些Pod调度到相近甚至是同一区域位置(比如同一节点、机房、区域)等等,比如业务的前端Pod和后端Pod,此时这些Pod对象之间的关系可以叫做亲和性。
同时出于安全性的考虑,也会把一些Pod之间进行隔离,此时这些Pod对象之间的关系叫做反亲和性(anti-affinity)。
调度器把第一个Pod放到任意位置,然后和该Pod有亲和或反亲和关系的Pod根据该动态完成位置编排,这就是Pod亲和性和反亲和性调度的作用。Pod的亲和性定义也存在硬亲和性和软亲和性的区别,其约束的意义和节点亲和性类似。
Pod的亲和性调度要求各相关的Pod对象运行在同一位置,而反亲和性则要求它们不能运行在同一位置。这里的位置实际上取决于节点的位置拓扑,拓扑的方式不同,Pod是否在同一位置的判定结果也会有所不同。
如果基于各个节点的kubernetes.io/hostname标签作为评判标准,那么会根据节点的hostname去判定是否在同一位置区域。
4.1、Pod硬亲和度
Pod强制约束的亲和性调度也是使用requiredDuringSchedulingIgnoredDuringExecution进行定义的。Pod亲和性是用来描述一个Pod对象和现有的Pod对象运行的位置存在某种依赖关系,所以如果要测试Pod亲和性约束,需要存在一个被依赖的Pod对象,下面创建一个带有app=tomcat的Deployment资源部署一个Pod对象:
[root@k8s-master ~]# kubectl run tomcat -l app=tomcat --image=tomcat:alpine
deployment.apps/tomcat created
[root@k8s-master ~]# kubectl get pods -l app=tomcat -o wide
NAME READY STATUS RESTARTS AGE IP NODE
tomcat-75fd5cc757-w9qdb 1/1 Running 0 5m 10.244.1.37 k8s-node01
从上面我们可以看到新创建的tomcatpod对象被调度在k8s-node01上,再写一个配置清单定义一个Pod对象,通过labelSelector定义的标签选择器挑选对应的Pod对象。
[root@k8s-master ~]# vim required-podAffinity-pod1.yaml
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity-1
spec:
affinity:
podAffninity:
requiredDuringSchedulingIngnoreDuringExecution:
- labelSelector:
matchExpression:
- {key: app , operator: In , values: ["tomcat"]}
topologyKey: kubernetes.io/hostname
containers:
- name: myapp
image: ikubernetes/myapp:v1
kubernetes.io/hostname标签是Kubernetes集群节点的内建标签,它的值为当前节点的主机名,对于各个节点来说都是不同的。所以新建的Pod对象要被部署到和tomcat所在的同一个节点上。
[root@k8s-master ~]# kubectl apply -f required-podAffinity-pod1.yaml
pod/with-pod-affinity-1 created
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
with-pod-affinity-1 1/1 Running 0 31s 10.244.1.38 k8s-node01
tomcat-75fd5cc757-w9qdb 1/1 Running 0 5m 10.244.1.37 k8s-node01
基于单一节点的Pod亲和性相对来说使用的情况会比较少,通常使用的是基于同一地区、区域、机架等拓扑位置约束。比如部署应用程序(myapp)和数据库(db)服务相关的Pod时,这两种Pod应该部署在同一区域上,可以加速通信的速度。
4.2、Pod软亲和度
同理,有硬亲和度即有软亲和度,Pod也支持使用preferredDuringSchedulingIgnoredDuringExecuttion属性进行定义Pod的软亲和性,调度器会尽力满足亲和约束的调度,在满足不了约束条件时,也允许将该Pod调度到其他节点上运行。比如下面这一配置清单:
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-with-preferred-pod-affinity
spec:
replicas: 3
selector:
matchLabels:
app: myapp
template:
metadata:
name: myapp
labels:
app: myapp
spec:
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 80
podAffinityTerm:
labelSelector:
matchExpressions:
- {key: app, operator: In , values: ["cache"]}
topologyKey: zone
- weight: 20
podAffinityTerm:
labelSelector:
matchExpressions:
- {key: app, operator: In, values: ["db"]}
topologyKey: zone
containers:
- name: myapp
image: ikubernetes/mapp:v1
上述的清单配置当中,pod的软亲和调度需要将Pod调度到标签为app=cache并在区域zone当中,或者调度到app=db标签节点上的,但是我们的节点上并没有类似的标签,所以调度器会根据软亲和调度进行随机调度到k8s-node01节点之上。如下:
[root@k8s-master ~]# kubectl apply -f deploy-with-preferred-podAffinity.yaml
deployment.apps/myapp-with-preferred-pod-affinity created
[root@k8s-master ~]# kubectl get pods -o wide |grep myapp-with-preferred-pod-affinity
myapp-with-preferred-pod-affinity-5c44649f58-cwgcd 1/1 Running 0 1m 10.244.1.40 k8s-node01
myapp-with-preferred-pod-affinity-5c44649f58-hdk8q 1/1 Running 0 1m 10.244.1.42 k8s-node01
myapp-with-preferred-pod-affinity-5c44649f58-kg7cx 1/1 Running 0 1m 10.244.1.41 k8s-node01
4.3、Pod反亲和度
podAffinity定义了Pod对象的亲和约束,而Pod对象的反亲和调度则是用podAntiAffinty属性进行定义,下面的配置清单中定义了由同一Deployment创建但是彼此基于节点位置互斥的Pod对象:
[root@k8s-master ~]# cat deploy-with-required-podAntiAffinity.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-with-pod-anti-affinity
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
name: myapp
labels:
app: myapp
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- {key: app,operator: In,values: ["myapp"]}
topologyKey: kubernetes.io/hostname
containers:
- name: myapp
image: ikubernetes/myapp:v1
[root@k8s-master ~]# kubectl apply -f deploy-with-required-podAntiAffinity.yaml
deployment.apps/myapp-with-pod-anti-affinity created
[root@k8s-master ~]# kubectl get pods -l app=myapp
NAME READY STATUS RESTARTS AGE
myapp-with-pod-anti-affinity-79c7b6c596-77hrz 1/1 Running 0 8s
myapp-with-pod-anti-affinity-79c7b6c596-fhxmv 0/1 Pending 0 8s
myapp-with-pod-anti-affinity-79c7b6c596-l9ckr 1/1 Running 0 8s
myapp-with-pod-anti-affinity-79c7b6c596-vfv2s 1/1 Running 0 8s
由于在配置清单中定义了强制性反亲和性,所以创建的4个Pod副本必须 运行在不同的节点当中呢,但是集群中只存在3个节点,因此,肯定会有一个Pod对象处于Pending的状态。
5、污点和容忍度
污点(taints)是定义在节点上的一组键值型属性数据,用来让节点拒绝将Pod调度到该节点上,除非该Pod对象具有容纳节点污点的容忍度。而容忍度(tolerations)是定义在Pod对象上的键值型数据,用来配置让Pod对象可以容忍节点的污点。
前面的节点选择器和节点亲和性的调度方式都是通过在Pod对象上添加标签选择器来完成对特定类型节点标签的匹配,实现的是Pod选择节点的方式。而污点和容忍度则是通过对节点添加污点信息来控制Pod对象的调度结果,让节点拥有了控制哪种Pod对象可以调度到该节点上的 一种方式。
Kubernetes使用PodToleratesNodeTaints预选策略和TaintTolerationPriority优选函数来完成这种调度方式。
5.1、定义污点和容忍度
污点的定义是在节点的nodeSpec,而容忍度的定义是在Pod中的podSpec,都属于键值型数据,两种方式都支持一个effect标记,语法格式为key=value: effect,其中key和value的用户和格式和资源注解类似,而effect是用来定义对Pod对象的排斥等级,主要包含以下3种类型:
- NoSchedule:不能容忍此污点的新Pod对象不能调度到该节点上,属于强制约束,节点现存的Pod对象不受影响。
- PreferNoSchedule:NoSchedule属于柔性约束,即不能容忍此污点的Pod对象尽量不要调度到该节点,不过无其他节点可以调度时也可以允许接受调度。
- NoExecute:不能容忍该污点的新Pod对象不能调度该节点上,强制约束,节点现存的Pod对象因为节点污点变动或Pod容忍度的变动导致无法匹配规则,Pod对象就会被从该节点上去除。
在Pod对象上定义容忍度时,其支持2中操作符:Equal和Exists
- Equal:等值比较,表示容忍度和污点必须在key、value、effect三者之上完全匹配。
- Exists:存在性判断,表示二者的key和effect必须完全匹配,而容忍度中的value字段使用空值。
在使用kubeadm部署的集群中,master节点上将会自动添加污点信息,阻止不能容忍该污点的Pod对象调度到该节点上,如下:
[root@k8s-master ~]# kubectl describe node k8s-master
Name: k8s-master
Roles: master
......
Taints: node- role. kubernetes. io/ master: NoSchedule
......
而一些系统级别的应用在创建时,就会添加相应的容忍度来确保被创建时可以调度到master节点上,如flannel插件:
[root@k8s-master ~]# kubectl describe pods kube-flannel-ds-amd64-2p8wm -n kube-system
......
Tolerations: node-role.kubernetes.io/master:NoSchedule
node.kubernetes.io/disk-pressure:NoSchedule
node.kubernetes.io/memory-pressure:NoSchedule
node.kubernetes.io/not-ready:NoExecute
node.kubernetes.io/unreachable:NoExecute
......
5.2、管理节点的污点
使用命令行向节点添加污点
语法:kubectl taint nodes <nodename> <key>=<value>:<effect>......
#定义k8s-node01上的污点
[root@k8s-master ~]# kubectl taint nodes k8s-node01 node-type=production:NoSchedule
node/k8s-node01 tainted
#查看节点污点信息
[root@k8s-master ~]# kubectl get nodes k8s-node01 -o go-template={{.spec.taints}}
[map[effect:NoSchedule key:node-type value:production]]
此时,node01节点上已经存在的Pod对象不受影响,仅对新建Pod对象有影响,需要注意的是,如果是同一个键值数据,但是最后的标识不同,也是属于不同的污点信息,比如再给node01上添加一个污点的标识为:PreferNoSchedule
[root@k8s-master ~]# kubectl taint nodes k8s-node01 node-type=production:PreferNoSchedule
node/k8s-node01 tainted
[root@k8s-master ~]# kubectl get nodes k8s-node01 -o go-template={{.spec.taints}}
[map[value:production effect:PreferNoSchedule key:node-type] map[key:node-type value:production effect:NoSchedule]]
删除污点
语法:kubectl taint nodes <node-name> <key>[: <effect>]-
#删除node01上的node-type标识为NoSchedule的污点
[root@k8s-master ~]# kubectl taint nodes k8s-node01 node-type:NoSchedule-
node/k8s-node01 untainted
#删除指定键名的所有污点
[root@k8s-master ~]# kubectl taint nodes k8s-node01 node-type-
node/k8s-node01 untainted
#补丁方式删除节点上的全部污点信息
[root@k8s-master ~]# kubectl patch nodes k8s-node01 -p '{"spec":{"taints":[]}}'
5.3、Pod对象的容忍度
Pod对象的容忍度可以通过spec.tolerations字段进行添加,同一的也有两种操作符:Equal和Exists方式。Equal等值方式如下:
tolerations:
- key: "key1"
operator: "Equal"
value: "value1"
effect: "Noexecute"
tolerationSeconds: 3600
Exists方式如下:
tolerations:
- key: "key1"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 3600
Kubernetes学习之路(二十二)之Pod资源调度的更多相关文章
- Kubernetes学习之路(十二)之Pod控制器--ReplicaSet、Deployment
一.Pod控制器及其功用 Pod控制器是用于实现管理pod的中间层,确保pod资源符合预期的状态,pod的资源出现故障时,会尝试 进行重启,当根据重启策略无效,则会重新新建pod的资源. pod控制器 ...
- FastAPI 学习之路(十二)接口几个额外信息和额外数据类型
系列文章: FastAPI 学习之路(一)fastapi--高性能web开发框架 FastAPI 学习之路(二) FastAPI 学习之路(三) FastAPI 学习之路(四) FastAPI 学习之 ...
- Kubernetes学习之路(十一)之Pod状态和生命周期管理
一.什么是Pod? Pod是kubernetes中你可以创建和部署的最小也是最简的单位.一个Pod代表着集群中运行的一个进程. Pod中封装着应用的容器(有的情况下是好几个容器),存储.独立的网络IP ...
- Spark学习之路 (十二)SparkCore的调优之资源调优
摘抄自:https://tech.meituan.com/spark-tuning-basic.html 一.概述 在开发完Spark作业之后,就该为作业配置合适的资源了.Spark的资源参数,基本都 ...
- Scala 学习之路(十二)—— 类型参数
一.泛型 Scala支持类型参数化,使得我们能够编写泛型程序. 1.1 泛型类 Java中使用<>符号来包含定义的类型参数,Scala则使用[]. class Pair[T, S](val ...
- Spark学习之路(十二)—— Spark SQL JOIN操作
一. 数据准备 本文主要介绍Spark SQL的多表连接,需要预先准备测试数据.分别创建员工和部门的Datafame,并注册为临时视图,代码如下: val spark = SparkSession.b ...
- Salesforce学习之路(十二)Aura组件表达式
1. 表达式语法 在上篇文章组件属性示例中,新建了一个属性whom, 引用该属性时使用了表达式:{!v.whom},负责该属性的动态输出. 语法:{!expression} 上述示例中,我们的属性名称 ...
- 学习之路三十二:VS调试的简单技巧
这段时间园子里讲了一些关于VS的快捷键以及一些配置技巧,挺好的,大家一起学习,一起进步. 这段时间重点看了一下关于VS调试技巧方面的书,在此记录一下学习的内容吧,主要还是一些比较浅显的知识. 1. 调 ...
- Android破解学习之路(十二)—— GP录像汉化过程及添加布局
前言 最近闲着发慌,想起了很久之前就想汉化的一款录像APP,APP大小不到1MB,但是好用,本期就给大家带来汉化的基本步骤以及如何在APP中添加我们汉化的信息 汉化思路 查找关键字 关键字挺好找的,由 ...
- Python小白学习之路(十二)—【前向引用】【风湿理论】
前向引用 风湿理论(函数即变量) 理论总是很抽象,我个人理解: 代码从上到下执行,一旦遇到定义的函数体,内存便为其开辟空间,并用该函数的名字作为一个标识但是该函数体内具体是什么内容,这个时候并不着急去 ...
随机推荐
- Java标识符
相关内容: JAVA标识符: 定义 组成规则 常见的命名规则 包 类和接口 方法.变量 常量 首发时间:2017-06-22 20:40 修改时间: 2018-03-16 14:01 :修改了标题,修 ...
- SQLSERVER中的元数据锁
SQLSERVER中的元数据锁 网上对于元数据锁的资料真的非常少 元数据锁一般会出现在DDL语句里 下面列出数据库引擎可以锁定的资源 资源 说明 RID 用于锁定堆(heap)中的某一行 KEY 用于 ...
- leveldb源码分析--SSTable之逻辑结构
SSTable是leveldb 的核心模块,这也是其称为leveldb的原因,leveldb正是通过将数据分为不同level的数据分为对应的不同的数据文件存储到磁盘之中的.为了理解其机制,我们首先看看 ...
- c#List数组移除元素
; i >= ; i--) //移除已经订阅的患者 { if (AllPatientsEntities[i].姓名 == item.患者姓名) AllPatientsEntities.Remov ...
- Oracle EBS OPM complete step
--complete_step --created by jenrry DECLARE x_return_status VARCHAR2 (1); l_exception_material_tbl g ...
- windows7环境下使用pip安装MySQLdb for python3.7
1.首先,需要确定你已经安装了pip.在Python2.7的安装包中,easy_install.py和pip都是默认安装的.可以在Python的安装目录先确认,如果\Python37\Scripts里 ...
- MariaDB数据表操作实例
1. MariaDB 数据库操作实例 MariaDB>create database class; //创建class数据库 MariaDB>use class; MariaDB>c ...
- RHEL7.3安装mysql5.7
RHEL7.3 install mysql5.7 CentOS7默认安装MariaDB而不是MySQL,而且yum服务器上也移除了MySQL相关的软件包.因为MariaDB和MySQL可能会冲突,需先 ...
- css常见效果
1.ul li横排 /* ul li以横排显示 */ /* 所有class为menu的div中的ul样式 */ div.menu ul { list-style:none; /* 去掉ul前面的符号 ...
- 团队作业7——第二次项目冲刺(Beta版本)day3
项目成员: 曾海明(组长):201421122036 于波(组员):201421122058 蓝朝浩(组员):201421122048 王珏 (组员):201421122057 叶赐红(组员):20 ...