mysql分页查询优化(索引延迟关联)
对于web后台报表导出是一种常见的功能点,实际对应服务后端即数据库的排序分页查询。如下示例为公司商户积分报表导出其中一个sql ,当大批量的导出请求进入时候,mysql的cpu急剧上升瞬间有拖垮库的风险。
SELECT
*
FROM
coupons.cp_score_log
WHERE
`m_shopid` = 40861
AND `add_time` BETWEEN 1483200000
AND 1544543999
ORDER BY
add_time DESC
LIMIT 118000 ,1000 ;
报表导出功能存在几个问题:
1、时间跨度太大,数据量剧增。(可以结合业务需求,限制一定时间范围,比如只能导出3个月以内数据)
2、DB方面没有限制并发。(需要dba一起参与)
3、sql未考虑LIMIT分页过大,查询性能问题。(索引延迟关联,本文重点 或者 限制分页上限)
运行结果:18.94s (结果受到机器峰值影响,可能低一些,可能更高)
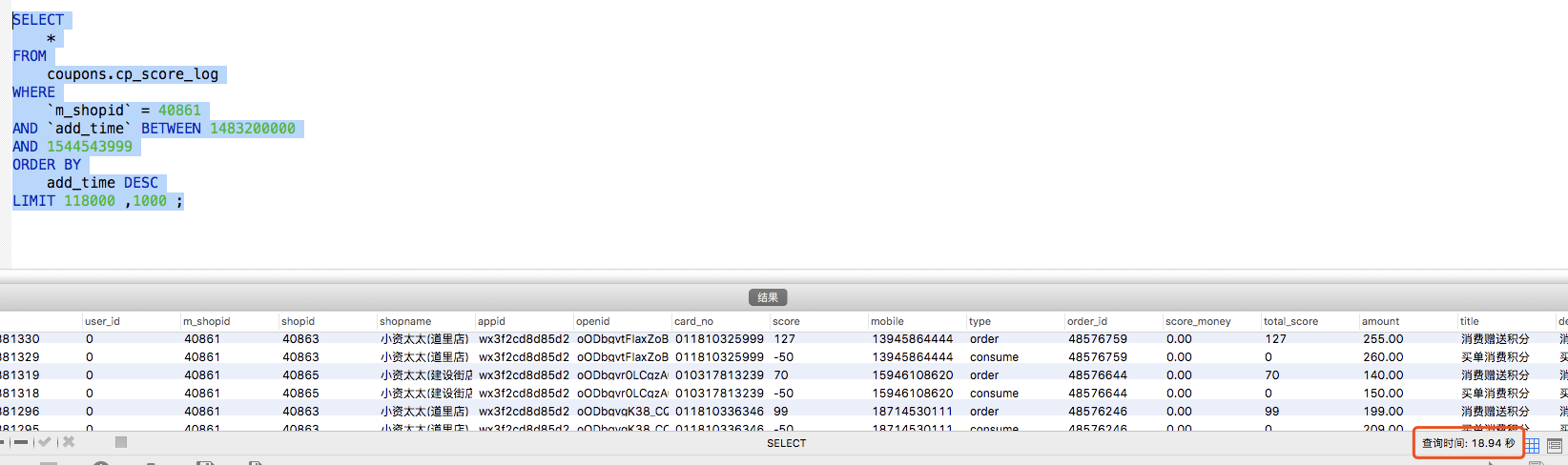
sql执行计划 :
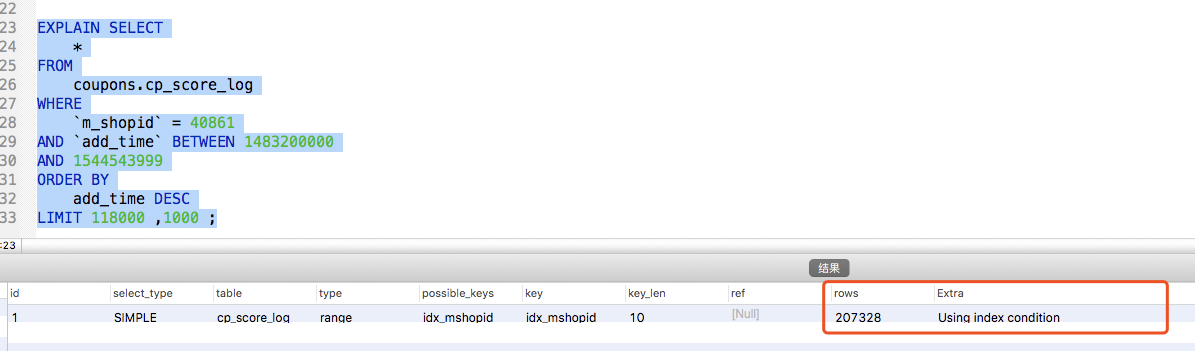
表结构:
CREATE TABLE `cp_score_log` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
......
`m_shopid` int(10) DEFAULT '' COMMENT '总店id',
......
`add_time` int(10) DEFAULT '',
`......PRIMARY KEY (`id`),
KEY `idx_cardno` (`card_no`),
KEY `idx_shopid` (`shopid`) USING BTREE,
KEY `idx_orderid` (`order_id`),
KEY `idx_shopid_add_time_score` (`shopid`,`add_time`,`score`),
KEY `idx_mshopid` (`m_shopid`,`add_time`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=24130302 DEFAULT CHARSET=utf8 COMMENT='积分记录表'
表的数据基本在2400万左右未进行拆分,通过查看sql和执行计划发现已经命中索引【idx_mshopid】,但是查询效率仍然很低。抛开其他问题只针对sql来说,核心的问题出在LIMIT。
MySQL中 【LIMIT offset, m】并不是跳过offset然后取m行数据,而是直接取【offset+m】行数据,丢弃前offset行返回m行。因此查询的效率就特别的低,特别当offset特别大的时候。
针对上面提出第3点问题,可以考虑使用后索引延迟关联,即 通过建立中间表覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据。 同时限制最大的分页数量,比如百度最大分页即为79页 。
SELECT
*
FROM
cp_score_log
INNER JOIN (
SELECT
id,
add_time
FROM
coupons.cp_score_log
WHERE
`m_shopid` = 40861
AND `add_time` BETWEEN 1483200000
AND 1544543999
ORDER BY
add_time DESC
LIMIT LIMIT 118000 ,1000
) b ON cp_score_log.id = b.id
ORDER BY
b.add_time DESC;
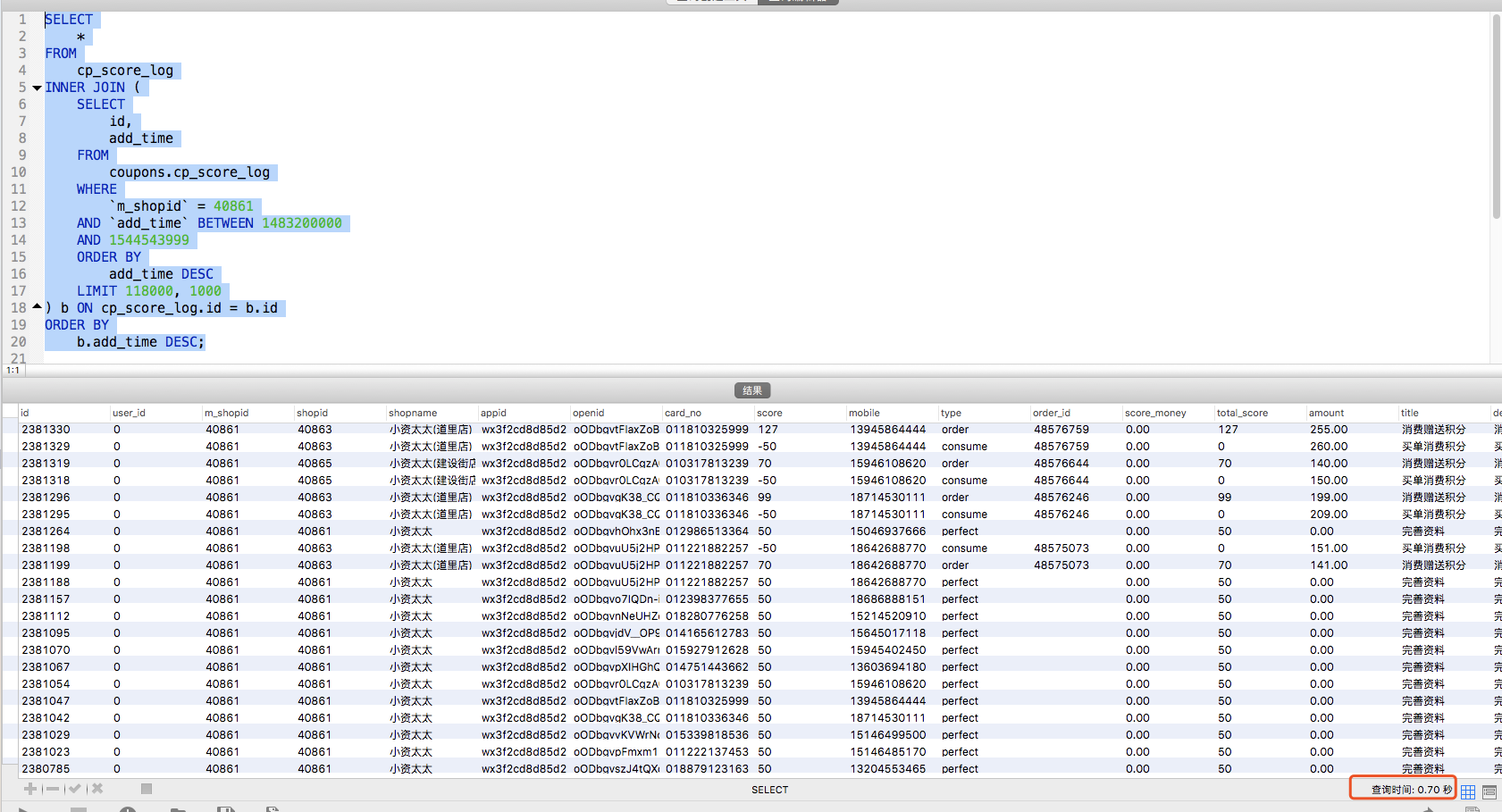
运行结果:0.7s (天差地别)
sql执行计划:
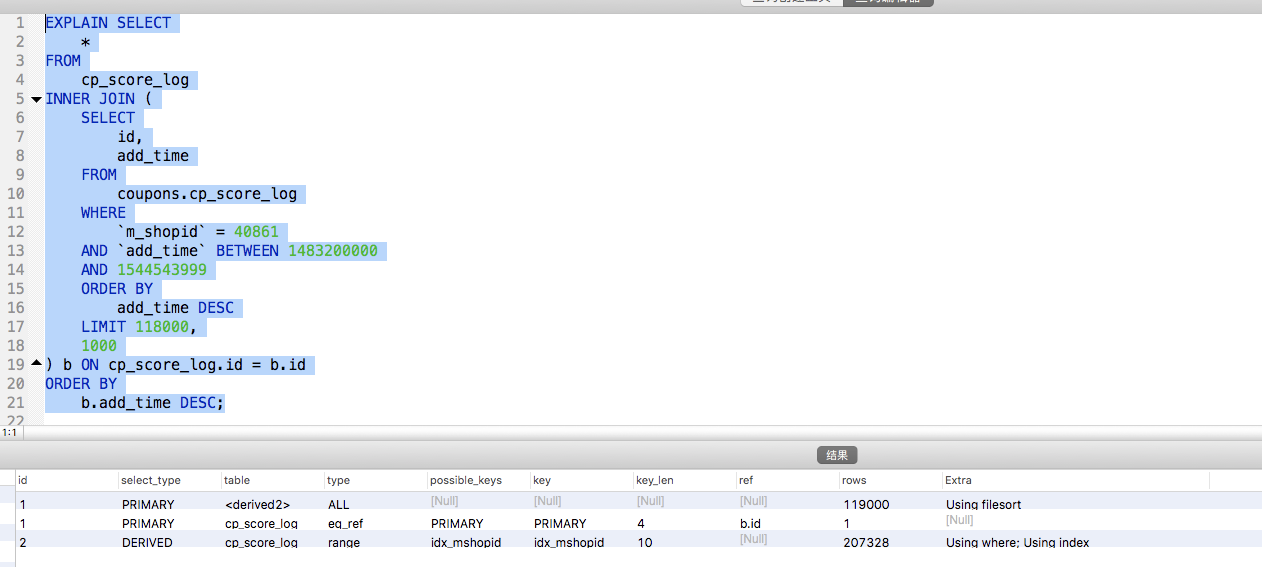
由此可见,使用sql延迟关联sql效率确实提升明显。但是并非能解决所以问题,当表数据过大已经数据库并发提高时,还是会出现查询慢甚至拖垮db当风险。所以因综合考虑,将请求量削峰。
mysql分页查询优化(索引延迟关联)的更多相关文章
- MySQL 分页查询优化——延迟关联优化
目录 1. InnoDB表的索引的几个概念 2. 覆盖索引和回表 3. 分页查询 4. 延迟关联优化 写在前面 下面的介绍均是在选用MySQL数据库和Innodb引擎的基础开展.我们先 ...
- MySQL性能优化之延迟关联
[背景] 某业务数据库load 报警异常,cpu usr 达到30-40 ,居高不下.使用工具查看数据库正在执行的sql ,排在前面的大部分是: SELECT id, cu_id, name, in ...
- MySQL 分页查询优化
有时在处理偏移量非常大的分页时候查询时,例如LIMIT 1000,10这样的查询,这时MySQL需要查询1010条记录然后只返回最后10条,前面1000条记录都被抛弃,这样的代价非常高.要优化这种查询 ...
- 复盘MySQL分页查询优化方案
一.前言 MySQL分页查询作为Java面试的一道高频面试题,这里有必要实践一下,毕竟实践出真知. 很多同学在做测试时苦于没有海量数据,官方其实是有一套测试库的. 二.模拟数据 这里模拟数据分2种情况 ...
- MySQL大数据分页的优化思路和索引延迟关联
之前上次在部门的分享会上,听了关于MySQL大数据的分页,即怎样使用limit offset,N来进行大数据的分页,现在做一个记录: 首先我们知道,limit offset,N的时候,MySQL的查询 ...
- 4种MySQL分页查询优化的方法,你知道几个?
前言 当需要从数据库查询的表有上万条记录的时候,一次性查询所有结果会变得很慢,特别是随着数据量的增加特别明显,这时需要使用分页查询.对于数据库分页查询,也有很多种方法和优化的点.下面简单说一下我知道的 ...
- mysql分页查询优化
由于MySql的分页机制:并不是跳过 offset 行,而是取 offset + N 行,然后返回放弃前 offset 行,返回N 行, 所以当 offset 特别大的时候,效率就非常的低下,要么控制 ...
- mysql通过“延迟关联”进行limit分页查询优化的一个实例
最近在生产上遇见一个分页查询特别慢的问题,数据量大概有200万的样子,翻到最后一页性能很低,差不多得有4秒的样子才能出来整个页面,需要进行查询优化. 第一步,找到执行慢的sql,如下: SELECT ...
- mysql优化----大数据下的分页,延迟关联,索引与排序的关系,重复索引与冗余索引,索引碎片与维护
理想的索引,高效的索引建立考虑: :查询频繁度(哪几个字段经常查询就加上索引) :区分度要高 :索引长度要小 : 索引尽量能覆盖常用查询字段(如果把所有的列都加上索引,那么索引就会变得很大) : 索引 ...
随机推荐
- CSS3设置内容超过一定长度后自动折行
在用编辑器保存的数据到数据库的时候经常是在我们的内容前后加一个P标签,但是出来之后是一行,有时候会超过边框的宽度,所以研究了如何折行,如下代码: <!DOCTYPE html> <h ...
- Mini Twitter
Implement a simple twitter. Support the following method: postTweet(user_id, tweet_text). Post a twe ...
- find查找时排除目录及文件
查找根目录下大于500M的文件,排除/proc目录 find / ! -path "/proc/*" -type f -size +500M | sort -rh|xargs ls ...
- shell expect的简单用法【转】
用expect实现自动登录的脚本,网上有很多,可是都没有一个明白的说明,初学者一般都是照抄.收藏.可是为什么要这么写却不知其然.本文用一个最短的例子说明脚本的原理. 脚本代码如下: ######## ...
- xunsearch 迅搜初探
2014年1月2日 19:34:12 [root@localhost bin]# ./php /usr/local/lamp/xunsearch/sdk/php/util/Quest.php demo ...
- 2017-2018-2 20155225《网络对抗技术》实验一 PC平台逆向破解
2017-2018-2 20155225<网络对抗技术>实验一 PC平台逆向破解 1.直接修改程序机器指令,改变程序执行流程 理清思路: 我们的目标文件是一个linux可执行文件,格式为E ...
- Mybatis输入映射和输出映射
本节内容: 输入参数映射 输出映射 resultMap Mapper.xml映射文件中定义了操作数据库的sql,每个sql是一个statement,映射文件是mybatis的核心. 一.环境准备 复制 ...
- PHP 利用redis 做统计缓存mysql的压力
<?php header("Content-Type:text/html;charset=utf-8"); include 'lib/mysql.class.php'; $m ...
- oracle用户名小写时,利用sqlplus连接
[oracle@upright92 ~]$ sqlplus / as sysdba SQL*Plus: Release 11.2.0.4.0 Production on Tue May 22 10:3 ...
- HTML5 标签语法变化和使用概念
1.H5与H4的区别 概念的变化: H5更注重内容与结构,不再只专注于表现. 声明与标签: 新的声明背简化: <!DOCTYPE html> <meta charset=utf-8& ...