stacking过程
图解stacking原理:
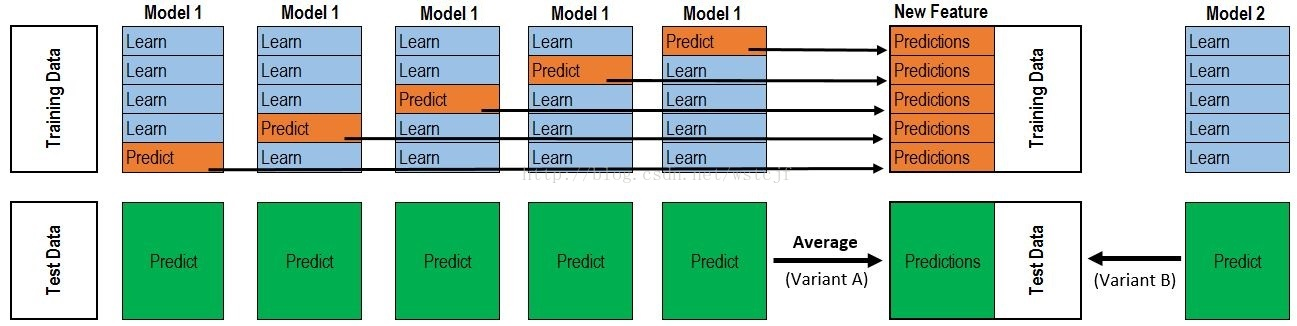
上半部分是用一个基础模型进行5折交叉验证,如:用XGBoost作为基础模型Model1,5折交叉验证就是先拿出四折作为training data,另外一折作为testing data。注意:在stacking中此部分数据会用到整个traing set。如:假设我们整个training set包含10000行数据,testing set包含2500行数据,那么每一次交叉验证其实就是对training set进行划分,在每一次的交叉验证中training data将会是8000行,testing data是2000行。
每一次的交叉验证包含两个过程,1. 基于training data训练模型;2. 基于training data训练生成的模型对testing data进行预测。在整个第一次的交叉验证完成之后我们将会得到关于当前testing data的预测值,这将会是一个一维2000行的数据,记为a1。注意!在这部分操作完成后,我们还要对数据集原来的整个testing set进行预测,这个过程会生成2500个预测值,这部分预测值将会作为下一层模型testing data的一部分,记为b1。因为我们进行的是5折交叉验证,所以以上提及的过程将会进行五次,最终会生成针对testing set数据预测的5列2000行的数据a1,a2,a3,a4,a5,对testing set的预测会是5列2500行数据b1,b2,b3,b4,b5。
在完成对Model1的整个步骤之后,我们可以发现a1,a2,a3,a4,a5其实就是对原来整个training set的预测值,将他们拼凑起来,会形成一个10000行一列的矩阵,记为A1。而对于b1,b2,b3,b4,b5这部分数据,我们将各部分相加取平均值,得到一个2500行一列的矩阵,记为B1。
以上就是stacking中一个模型的完整流程,stacking中同一层通常包含多个模型,假设还有Model2: LR,Model3:RF,Model4: GBDT,Model5:SVM,对于这四个模型,我们可以重复以上的步骤,在整个流程结束之后,我们可以得到新的A2,A3,A4,A5,B2,B3,B4,B5矩阵。
在此之后,我们把A1,A2,A3,A4,A5并列合并得到一个10000行五列的矩阵作为training data,B1,B2,B3,B4,B5并列合并得到一个2500行五列的矩阵作为testing data。让下一层的模型,基于他们进一步训练。
如何实现?
1.写代码自己实现
2.如果嫌麻烦可以调用API
code1:
from vecstack import stacking # 输入数据 # 初始化第一层评估器
models = [LinearRegression(),
Ridge(random_state=0)] # 把 stack特征排成一列
S_train, S_test = stacking(models, X_train, y_train, X_test, regression=True, verbose=2) # 如果觉得效果可以在提升,我们可以使用第一层提取的stack特征输入到模型中
code2:
from vecstack import StackingTransformer
estimators = [('lr', LinearRegression()),
('ridge', Ridge(random_state=0))]
stack = StackingTransformer(estimators, regression=True, verbose=2)
stack = stack.fit(X_train, y_train)
S_train = stack.transform(X_train)
S_test = stack.transform(X_test)
# 使用stack特征作为第二层模型的输入数据
stacking过程的更多相关文章
- 弱分类器的进化--Bagging、Boosting、Stacking
一般来说集成学习可以分为三大类: 用于减少方差的bagging 用于减少偏差的boosting 用于提升预测结果的stacking 一.Bagging(1996) 1.随机森林(1996) RF = ...
- 深度学习在CTR预估中的应用
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由鹅厂优文发表于云+社区专栏 一.前言 二.深度学习模型 1. Factorization-machine(FM) FM = LR+ e ...
- 一小部分机器学习算法小结: 优化算法、逻辑回归、支持向量机、决策树、集成算法、Word2Vec等
优化算法 先导知识:泰勒公式 \[ f(x)=\sum_{n=0}^{\infty}\frac{f^{(n)}(x_0)}{n!}(x-x_0)^n \] 一阶泰勒展开: \[ f(x)\approx ...
- c++ primer plus 第6版 部分二 5- 8章
---恢复内容开始--- c++ primer plus 第6版 部分二 5- 章 第五章 计算机除了存储外 还可以对数据进行分析.合并.重组.抽取.修改.推断.合成.以及其他操作 1.for ...
- UVA 103 Stacking Boxes (dp + DAG上的最长路径 + 记忆化搜索)
Stacking Boxes Background Some concepts in Mathematics and Computer Science are simple in one or t ...
- Ensemble Learning: Bootstrap aggregating (Bagging) & Boosting & Stacked generalization (Stacking)
Booststrap aggregating (有些地方译作:引导聚集),也就是通常为大家所熟知的bagging.在维基上被定义为一种提升机器学习算法稳定性和准确性的元算法,常用于统计分类和回归中. ...
- Dream team: Stacking for combining classifiers梦之队:组合分类器
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 集成学习总结 & Stacking方法详解
http://blog.csdn.net/willduan1/article/details/73618677 集成学习主要分为 bagging, boosting 和 stacking方法.本文主要 ...
- 模型融合策略voting、averaging、stacking
原文:https://zhuanlan.zhihu.com/p/25836678 1.voting 对于分类问题,采用多个基础模型,采用投票策略选择投票最多的为最终的分类. 2.averaging 对 ...
随机推荐
- NumPy 从已有的数组创建数组
NumPy 从已有的数组创建数组 本章节我们将学习如何从已有的数组创建数组. numpy.asarray numpy.asarray 类似 numpy.array,但 numpy.asarray 只有 ...
- c# 键值对的方式post提交
DataContractJsonSerializer jsQcData = new DataContractJsonSerializer(typeof(DATA<data>));//DAT ...
- cross-env:跨平台设置和使用环境变量
一 项目结构 二 安装依赖 npm install --save-dev cross-env 三 npm脚本 { "name": "demo", "v ...
- C语言之栈区、堆区
一 局部变量存放在栈区中,函数调用结束后释放内存空间. #include "stdio.h"; #include "stdlib.h"; int *getNum ...
- socket、fsockopen、curl、stream 区别
socket 水泥.沙子,底层的东西fsockopen 水泥预制件,可以用来搭房子curl 毛坯房,自己装修一下就能住了 水泥.沙子不但可以修房子,还能修路.修桥.大型雕塑.socket也是,不但可以 ...
- HDU 1754 I Hate It(线段树区间查询,单点更新)
描述 很多学校流行一种比较的习惯.老师们很喜欢询问,从某某到某某当中,分数最高的是多少. 这让很多学生很反感.不管你喜不喜欢,现在需要你做的是,就是按照老师的要求,写一个程序,模拟老师的询问.当然,老 ...
- 7.27-8.10 Problems
这是之前记录在word里的问题,现在誊到博客里.温故知新.时常回顾问题. 7.27 Bootstrap validator remote 验证出错 用Bootstrap validator插件验证表单 ...
- 通配符的匹配很全面, 但无法找到元素 'tx:annotation-driven' 的声明
启动Tomcat时报错,通配符的匹配很全面, 但无法找到元素 'tx:annotation-driven' 的声明,报错如下 1.从报错可以看到找不到元素 tx:annotation-driven ...
- pthreads v3下一些坑和需要注意的地方
一.子线程无法访问父线程的全局变量,但父线程可以访问子线程的变量 <?php class Task extends Thread { public $data; public function ...
- 关于transform-style:preserve-3d的些许明了
父元素要添加属性transform-style:preserve-3d;和transform:perspective(800px);还有相对定位 首先设置子元素 具有3D属性,然后再设置视角与3D元素 ...