Solr4.8.0源码分析(12)之Lucene的索引文件(5)
Solr4.8.0源码分析(12)之Lucene的索引文件(5)
1. 存储域数据文件(.fdt和.fdx)
Solr4.8.0里面使用的fdt和fdx的格式是lucene4.1的。为了提升压缩比,StoredFieldsFormat以16KB为单位对文档进行压缩,使用的压缩算法是LZ4,由于它更着眼于速度而不是压缩比,所以它能快速压缩以及解压。
1.1 存储域数据文件(.fdt)
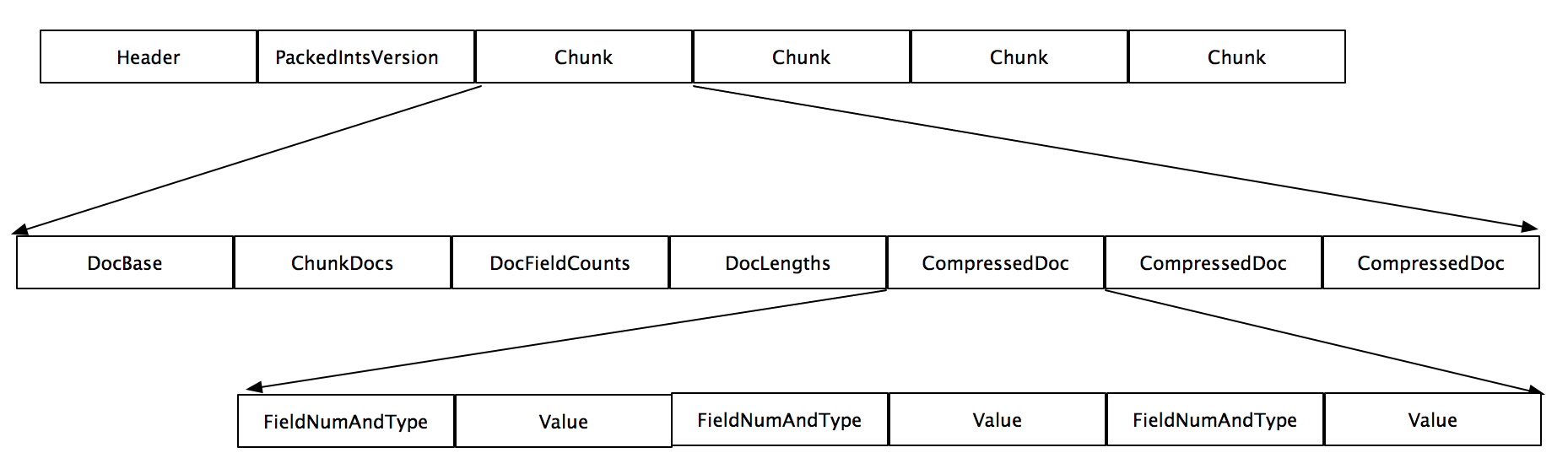
- 真正保存存储域(stored field)信息的是fdt文件,该文件存放了压缩后的文档,按16kb或者更大的模块大小为单位进行压缩。当要写入segment时候,文档会先被存储在内存的buffer里面,当buffer大小大于16kb或者更大时候,这些文档就会被刷入磁盘以LZ4格式压缩存放。
- fdt文件主要由三部分组成,Header信息,PacjedIntsVersion信息,以及多个块chunk。
- fdt是以chunk为单位进行压缩以及解压缩的,一个chunk块内含有一个或者多个document
- chunk内含有第一个document的编号即DocBase,块内document的个数即ChunkDocs,每一个Document的存储的Field的个数即DocFieldCounts,所有在块内的document的长度即DocLengths,以及多个压缩的document。
- CompressedDoc由FieldNumAndType和Value组成。FieldNumAndType是一个Vlong型,它的最低三位表示Type,其他位数表示FieldNum即域号。
- Value对应Type,
- 0: Value is String
- 1: Value is BinaryValue
- 2: Value is Int
- 3: Value is Float
- 4: Value is Long
- 5: Value is Double
- 6, 7: unused
- 如果文档大于16KB,那么chunk只会存在一个文档。因为一个文档的所有域必须全部在同一chunk种
- 如果在chunk块中多个文档较大且使得chunk大于32kb时,那么chunk会被压缩成多个16KB大小的LZ4块。
- 该结构不支持大于(231 - 214) bytes的单个文档
StoredFieldsFormat继承了CompressingStoredFieldsFormat,所以先通过学习CompressingStoredFieldsReader来Solr是怎么解析.fdx和.fdt的
public CompressingStoredFieldsReader(Directory d, SegmentInfo si, String segmentSuffix, FieldInfos fn,
IOContext context, String formatName, CompressionMode compressionMode) throws IOException {
this.compressionMode = compressionMode;
final String segment = si.name;
boolean success = false;
fieldInfos = fn;
numDocs = si.getDocCount();
ChecksumIndexInput indexStream = null;
try {
//打开.fdx名字
final String indexStreamFN = IndexFileNames.segmentFileName(segment, segmentSuffix, FIELDS_INDEX_EXTENSION);
//打开.fdt名字
final String fieldsStreamFN = IndexFileNames.segmentFileName(segment, segmentSuffix, FIELDS_EXTENSION);
// Load the index into memory
//解析.fdx文件
indexStream = d.openChecksumInput(indexStreamFN, context);
//获取header
final String codecNameIdx = formatName + CODEC_SFX_IDX;
version = CodecUtil.checkHeader(indexStream, codecNameIdx, VERSION_START, VERSION_CURRENT);
assert CodecUtil.headerLength(codecNameIdx) == indexStream.getFilePointer();
//开始解析blocks
indexReader = new CompressingStoredFieldsIndexReader(indexStream, si); long maxPointer = -1; if (version >= VERSION_CHECKSUM) {
maxPointer = indexStream.readVLong();
CodecUtil.checkFooter(indexStream);
} else {
CodecUtil.checkEOF(indexStream);
}
indexStream.close();
indexStream = null; // Open the data file and read metadata
//解析.fdt文件
fieldsStream = d.openInput(fieldsStreamFN, context);
if (version >= VERSION_CHECKSUM) {
if (maxPointer + CodecUtil.footerLength() != fieldsStream.length()) {
throw new CorruptIndexException("Invalid fieldsStream maxPointer (file truncated?): maxPointer=" + maxPointer + ", length=" + fieldsStream.length());
}
} else {
maxPointer = fieldsStream.length();
}
this.maxPointer = maxPointer;
final String codecNameDat = formatName + CODEC_SFX_DAT;
final int fieldsVersion = CodecUtil.checkHeader(fieldsStream, codecNameDat, VERSION_START, VERSION_CURRENT);
if (version != fieldsVersion) {
throw new CorruptIndexException("Version mismatch between stored fields index and data: " + version + " != " + fieldsVersion);
}
assert CodecUtil.headerLength(codecNameDat) == fieldsStream.getFilePointer(); if (version >= VERSION_BIG_CHUNKS) {
chunkSize = fieldsStream.readVInt();
} else {
chunkSize = -1;
}
packedIntsVersion = fieldsStream.readVInt();
//开始解析chunks
decompressor = compressionMode.newDecompressor();
this.bytes = new BytesRef(); success = true;
} finally {
if (!success) {
IOUtils.closeWhileHandlingException(this, indexStream);
}
}
}
1.2 存储域索引文件(.fdx)
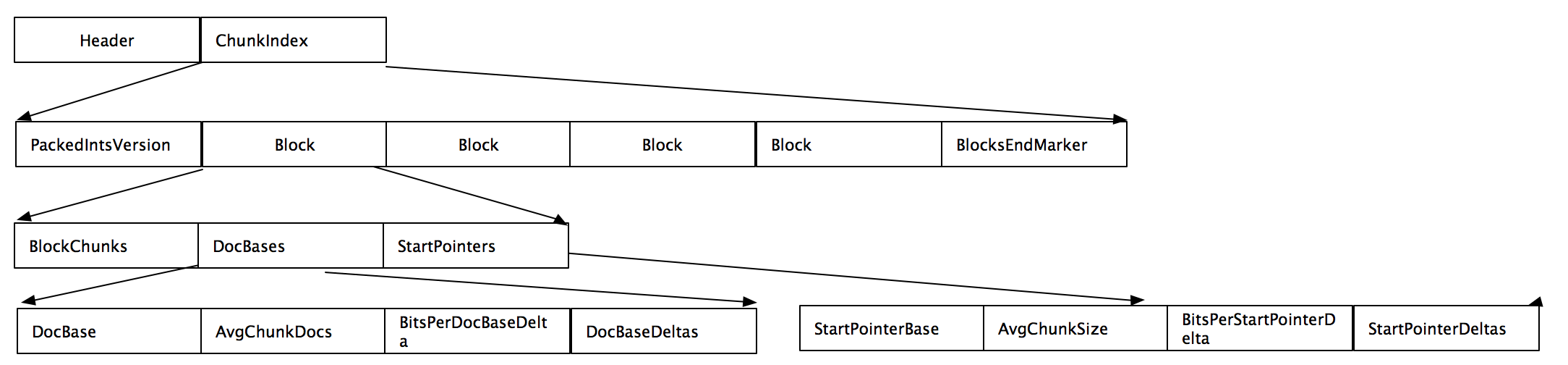
- BlockEndMarker:该值为0,表示后面没有接着Block。因为Block不是以0开始的
- 这里的一个Block包含了多个chunk,chunk对应了.fdt的chunk。所以可以通过.fdx快速的定位到.fdt的chunk。
- Block有三部分组成,BlockChunks表示该block内含有的chunk的数量,DocBases表示了该block的第一个document的ID并可以通过它获取任意一个该block内的chunk的docbase,同理StartPointer表示了该block内所有的chunk在.fdt文件里的位置信息。
- DocBases由DocBase, AvgChunkDocs, BitsPerDocBaseDelta, DocBaseDeltas组成。DocBase是Block内的第一个document ID,AvgChunkDocs是Chunk内document平均个数,BitsPerDocBaseDelta是与AvgChunkDocs的差值,DocBaseDeltas是BlockChunks大小的数组,表示平均的doc base的差值。
- StartPointers由StartPointerBase(block的第一个指针,它对应DocBase),AvgChunkSize(chunk的平均大小,对应AvgChunkDocs), BitPerStartPointerDelta以及StartPointerDeltas组成
- 第N个chunk的起始docbase可以用如下公式计算:
DocBase + AvgChunkDocs * n + DocBaseDeltas[n] - 第N个chunk的起始point可以用如下公式计算:StartPointerBase + AvgChunkSize * n + StartPointerDeltas[n]
- .fdx文件的解析主要用到了 CompressingStoredFieldsFormat,其中以CompressingStoredFieldsIndexReader为例,查看如何读取.fdx文件:
// It is the responsibility of the caller to close fieldsIndexIn after this constructor
// has been called
CompressingStoredFieldsIndexReader(IndexInput fieldsIndexIn, SegmentInfo si) throws IOException {
maxDoc = si.getDocCount();
int[] docBases = new int[16];
long[] startPointers = new long[16];
int[] avgChunkDocs = new int[16];
long[] avgChunkSizes = new long[16];
PackedInts.Reader[] docBasesDeltas = new PackedInts.Reader[16];
PackedInts.Reader[] startPointersDeltas = new PackedInts.Reader[16];
//读取packedIntsVersion
final int packedIntsVersion = fieldsIndexIn.readVInt(); int blockCount = 0;
//开始遍历并读取所有block
for (;;) {
//numChunks即当做BlockChunks,表示一个Block内Chunks的个数;当Block读取完时候会读取一个为0的值即为BlocksEndMarker,
//表示已读取完所有 block。
final int numChunks = fieldsIndexIn.readVInt();
if (numChunks == 0) {
break;
}
//初始化时候,定义大小为16的数组docBases,startPointers,avgChunkDocs,avgChunkSizes表示16个模块。
//当Block大于16时候,会生成新的大小的数组,并将原数据复制过去。
if (blockCount == docBases.length) {
final int newSize = ArrayUtil.oversize(blockCount + 1, 8);
docBases = Arrays.copyOf(docBases, newSize);
startPointers = Arrays.copyOf(startPointers, newSize);
avgChunkDocs = Arrays.copyOf(avgChunkDocs, newSize);
avgChunkSizes = Arrays.copyOf(avgChunkSizes, newSize);
docBasesDeltas = Arrays.copyOf(docBasesDeltas, newSize);
startPointersDeltas = Arrays.copyOf(startPointersDeltas, newSize);
} // doc bases
//读取block的docBase
docBases[blockCount] = fieldsIndexIn.readVInt();
//读取avgChunkDocs,block中chunk内含有平均的document个数
avgChunkDocs[blockCount] = fieldsIndexIn.readVInt();
//读取bitsPerDocBase,block中与avgChunkDocs的delta的位数,根据这个位数获取docBasesDeltas数组内具体delta
final int bitsPerDocBase = fieldsIndexIn.readVInt();
if (bitsPerDocBase > 32) {
throw new CorruptIndexException("Corrupted bitsPerDocBase (resource=" + fieldsIndexIn + ")");
}
//获取docBasesDeltas值,docBasesDeltas是一个numChunks大小的数组,存放每一个chunk起始的docbase与avgChunkDocs的差值
docBasesDeltas[blockCount] = PackedInts.getReaderNoHeader(fieldsIndexIn, PackedInts.Format.PACKED, packedIntsVersion, numChunks, bitsPerDocBase); // start pointers
//读取block的startPointers
startPointers[blockCount] = fieldsIndexIn.readVLong();
//读取startPointers,chunk的平均大小
avgChunkSizes[blockCount] = fieldsIndexIn.readVLong();
//读取bitsPerStartPointer,block中与avgChunkSizes的delta的位数,根据这个位数获取startPointersDeltas数组内具体delta
final int bitsPerStartPointer = fieldsIndexIn.readVInt();
if (bitsPerStartPointer > 64) {
throw new CorruptIndexException("Corrupted bitsPerStartPointer (resource=" + fieldsIndexIn + ")");
}
//获取startPointersDeltas值,startPointersDeltas是一个numChunks大小的数组,
//存放每一个chunk起始的startPointer与avgChunkSizes的差值。
startPointersDeltas[blockCount] = PackedInts.getReaderNoHeader(fieldsIndexIn, PackedInts.Format.PACKED, packedIntsVersion, numChunks, bitsPerStartPointer); //下一个block
++blockCount;
}
//将遍历完的数据放入全局变量中
this.docBases = Arrays.copyOf(docBases, blockCount);
this.startPointers = Arrays.copyOf(startPointers, blockCount);
this.avgChunkDocs = Arrays.copyOf(avgChunkDocs, blockCount);
this.avgChunkSizes = Arrays.copyOf(avgChunkSizes, blockCount);
this.docBasesDeltas = Arrays.copyOf(docBasesDeltas, blockCount);
this.startPointersDeltas = Arrays.copyOf(startPointersDeltas, blockCount);
}
Solr4.8.0源码分析(12)之Lucene的索引文件(5)的更多相关文章
- Solr4.8.0源码分析(8)之Lucene的索引文件(1)
Solr4.8.0源码分析(8)之Lucene的索引文件(1) 题记:最近有幸看到觉先大神的Lucene的博客,感觉自己之前学习的以及工作的太为肤浅,所以决定先跟随觉先大神的博客学习下Lucene的原 ...
- Solr4.8.0源码分析(11)之Lucene的索引文件(4)
Solr4.8.0源码分析(11)之Lucene的索引文件(4) 1. .dvd和.dvm文件 .dvm是存放了DocValue域的元数据,比如DocValue偏移量. .dvd则存放了DocValu ...
- Solr4.8.0源码分析(10)之Lucene的索引文件(3)
Solr4.8.0源码分析(10)之Lucene的索引文件(3) 1. .si文件 .si文件存储了段的元数据,主要涉及SegmentInfoFormat.java和Segmentinfo.java这 ...
- Solr4.8.0源码分析(9)之Lucene的索引文件(2)
Solr4.8.0源码分析(9)之Lucene的索引文件(2) 一. Segments_N文件 一个索引对应一个目录,索引文件都存放在目录里面.Solr的索引文件存放在Solr/Home下的core/ ...
- Solr4.8.0源码分析(13)之LuceneCore的索引修复
Solr4.8.0源码分析(13)之LuceneCore的索引修复 题记:今天在公司研究elasticsearch,突然看到一篇博客说elasticsearch具有索引修复功能,顿感好奇,于是点进去看 ...
- Solr4.8.0源码分析(25)之SolrCloud的Split流程
Solr4.8.0源码分析(25)之SolrCloud的Split流程(一) 题记:昨天有位网友问我SolrCloud的split的机制是如何的,这个还真不知道,所以今天抽空去看了Split的原理,大 ...
- Solr4.8.0源码分析(24)之SolrCloud的Recovery策略(五)
Solr4.8.0源码分析(24)之SolrCloud的Recovery策略(五) 题记:关于SolrCloud的Recovery策略已经写了四篇了,这篇应该是系统介绍Recovery策略的最后一篇了 ...
- Solr4.8.0源码分析(23)之SolrCloud的Recovery策略(四)
Solr4.8.0源码分析(23)之SolrCloud的Recovery策略(四) 题记:本来计划的SolrCloud的Recovery策略的文章是3篇的,但是没想到Recovery的内容蛮多的,前面 ...
- Solr4.8.0源码分析(22)之SolrCloud的Recovery策略(三)
Solr4.8.0源码分析(22)之SolrCloud的Recovery策略(三) 本文是SolrCloud的Recovery策略系列的第三篇文章,前面两篇主要介绍了Recovery的总体流程,以及P ...
随机推荐
- Scrapy:Python的爬虫框架
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- JSP基本语法
在tomcat环境搭建一文中为大家详细的介绍了第一个JSP的程序--Hello World,大家都应该顺利的完成了吧,以此为一个开端,希望大家在学习java EE的路上乘风破浪,不断进步.今天,为大家 ...
- Linux(SLES)挂载NTFS移动硬盘实践
问题描写叙述: 因为通过測试环境导出的dmp过大,但要求尽快导入至生产server,请网络室打通防火墙后发现測试网络为100M而生产网络贵为1000M却无法发挥不论什么作用即使通过networklin ...
- J2EE之WebLogic Server
WebLogic是用于开发.集成.部署和管理大型分布式Web应用. 网络应用和数据库应 用的Java应用server. 将Java的动态功能和Java Enterprise标准的安全性引入大型网络应用 ...
- SAP OTR 字段维护 更改SAP的字段翻译
维护系统文本字段:SOTR_EDIT TC:SE63 在SAP用户选择屏幕中,用鼠标选定一个栏位后按F1键,能够看到SAP对其详细解释,通常这样的解释文本分为两部分,一部分为标题, ...
- java中的泛型(转)
什么是泛型? 泛型(Generic type 或者 generics)是对 Java 语言的类型系统的一种扩展,以支持创建可以按类型进行参数化的类.可以把类型参数看作是使用参数化类型时指定的类型的一个 ...
- solr可用于集群的搜索 【转】
一. SOLR搭建企业搜索平台 运行环境: 运行容器:Tomcat6.0.20 Solr版本:apache-solr-1.4.0 分词器:mmseg4j-1.6.2 词库:sogou-dic 准备工 ...
- Mavne + Spring整合CXF
http://blog.csdn.net/xiongyu777888/article/details/23787615(没毛病) http://blog.csdn.net/hbsong75/artic ...
- 基于GBT28181:SIP协议组件开发-----------第四篇SIP注册流程eXosip2实现(一)
原创文章,引用请保证原文完整性,尊重作者劳动,原文地址http://www.cnblogs.com/qq1269122125/p/3945294.html. 上章节讲解了利用自主开发的组件SIP组件l ...
- cocos2d-x 读取 json 文件并用 jsoncpp 做解析
一码胜万言(请看注释) CclUtil.h // // CclUtil.h // PracticeDemo // // Created by kodeyang on 8/1/13. // // #if ...