hadoop学习笔记——基础知识及安装
1.核心
HDFS 分布式文件系统
主从结构,一个namenoe和多个datanode, 分别对应独立的物理机器
1) NameNode是主服务器,管理文件系统的命名空间和客户端对文件的访问操作。NameNode执行文件系统的命名空间操作,比如打开关闭重命名文件或者目录等,它也负责数据块到具体DataNode的映射
2)集群中的DataNode管理存储的数据。负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据块的创建删除和复制工作。
3)NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode
MapReduce 并行计算框架
主从结构,一个JobTracker和多个TaskTracker
1) MapReduce是由一个单独运行在主节点上的JobTacker和运行在每个集群从节点上的TaskTracker共同组成的。JobTacker负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。总结点监控他们的执行情况,
并且重新执行之前失败的任务;从节点仅负责由主节点指派的任务
2) MapReduce模型原理是利用一个输入的key/value对集合来产生一个输出的key/value队集合,使用Map和Reduce函数来计算
3) MapReduce将大数据分解为成百上千小数据集,每个数据集分别由集群中的一个节点(一般是一台计算机)并行处理生成中间结果,后然这些中间结果又由大量的节点合并,形成最终结果
2. 基础概念
1)hadoop集群三种模式:本地模式(单机模式),伪分布模式,全分布式模式
单机模式:没有守护进程,所有东西运行在jvm上,使用的是本地文件系统, 没有dfs,使用开发过程中运行mapreduce程序,是使用最少的一种模式
伪分布模式:在一台服务器上模拟集群安装环境, 即多个进程运行在一个服务器上;使用与开发和测试环境,所有 守护进程在同一台机子上
全分布式模式:N台主机组成一个Hadoop集群,Hadoop守护进程运行在每一台主机上;分布式模式中,主节点和从节点会分开
2) 网络连接方式
host-only:宿主机(windows)与客户机(虚拟机中的客户机)单独组网,与主机当前的网络是隔离的
bridge:宿主机和客户机网络是连接的,在同一个局域网中,可以相互访问
NAT(network address translation): 虚拟机不占用主机所在局域网ip,通过使用主机的NAT功能访问区域网和互联网,此种方式虚拟机不用设置静态ip,只需要使用DHCP功能自动获取ip即可(绝大多数上网使用此种方式)
3)SSH 使用ssh进行免密码登陆
产生秘钥: ssh-keygen -t rsa
目录:~/.ssh
公钥拷贝:cp id_rsa.pub authorized_keys
3. 伪分布式安装
准备: ----关闭防火墙(内网中,安全性问题较小)
查看状态:service iptables status
关闭: service iptables stop
关闭防火墙的自动启动: chkconfig -list | grep iptables(查看)
chkconfig iptables off(关闭)
----修改ip (修改后 让其生效:server network restart, 然后使用ifconfig查看)
----修改hostname(/etc/sysconfig/network 更改主机名; etc/hosts 将主机名与ip地址绑定; )
----设置ssh自动登录(查看上面章节)
ssh-keygen -t rsa
cp id_rsa.pub authorized_keys
验证 ssh localhost
1. 安装jdk -----配置环境变量(/etc/profile java_home和path)----生效(source /etc/profile)---验证(java -version)
2. 安装hadoop(tar -zxvf hadoop-1.1.2.tar.gz)---重名名(mv hadoop-1.1.2 hadoop)----配置环境变量(hadoop_home和path)----生效(source /etc/profile)
3. 伪分布式集群:
修改hadoop_home/conf下配置文件 hadoop-env.sh core-site.cml hdfs-site.xml mapred-site.xml
1.hadoop-env.sh
export JAVA_HOME=/usr/local/jdk/ 2.core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop:9000</value></property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration> 3.hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value></property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration> 4.mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop:9001</value></property>
</configuration>
4. 启动
hadoop namenode -format(格式化)
start-all.sh
使用jps查看进程
JobTracker、DateNode、TaskTracker、SecondaryNameNode、NameNode
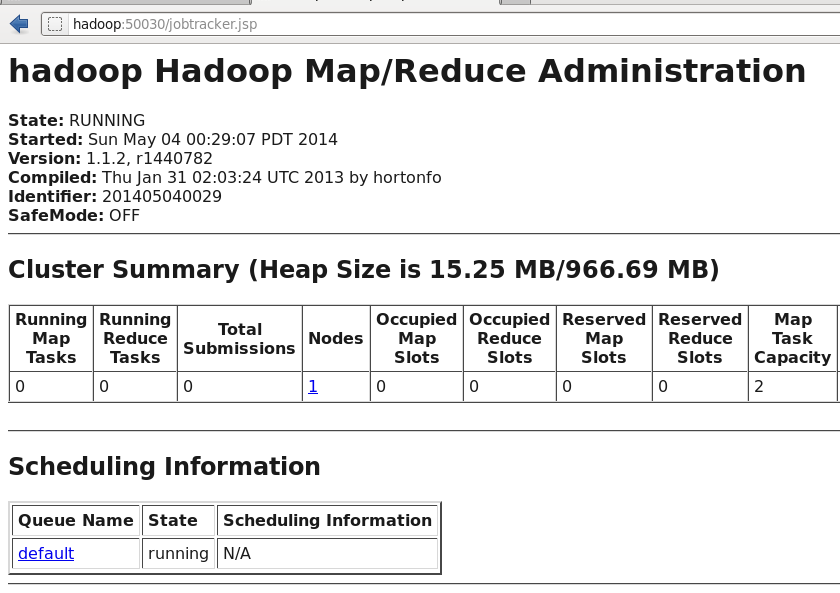
网址栏中输入 hostname:50070 查看namenode信息
输入 hostname:50030 产看mapreduce信息
关闭: stop-all.sh

4. 分布式安装
1.规划集群各节点的功能
两台主机 主机1 hadoop0 namenode ; 主机2 hadoop1 datanode
2. 检查如下配置(同伪分布式安装):1)防火墙是否关闭 2)ip是否设置 3)主机名是否设置 4)/etc/hosts是否配置 5)自己主机的ssh免密码登录是否设置
3. 集群间ssh免密码登录配置
在hadoop0上执行:ssh-copy-id -l ~/.ssh/id_rsa.pub hadoop1 (当本机已经产生rsa authorization时, 通过ssh-copy-id 可以将认证传送到宿端主机)
在hadoop1上执行:ssh-copy-id -l ~/.ssh/id_rsa.pub hadoop0
使用ssh hadoop1验证
4. 配置/etc/hosts文件
例如在hadoop0的/etc/hosts文件中添加: 192.168.1.169 hadoop0
192.168.1.21 hadoop1
5. 其他节点上jdk和hadoop的安装
在hadoop0上执行:
scp -rq /usr/local/jdk hadoop1:/usr/local (-r递归复制整个目录, -q不显示进度条)
scp -rq /usr/local/hadoop hadoop1:/usr/local
scp -rq /etc/profile hadoop1:/etc
scp -rq /etc/hosts hadoop1:/etc
source /etc/profile
6. 配置集群
hadoop0下 修改hadoop_home/conf/slaves(存储datanode和tasktracker节点名称),将localhost改为hadoop1
7. 启动集群
在hadoop0中执行hadoop namenode -format
start-all.sh
(关闭: stop-all.sh)
8. jps查看进程
hadoop0上 NameNode 、SecondarayNameNode、JobTracker进程
hadoop1上 DataNode、TaskTracker
9. 常见启动错误
unknownHostException :设置主机名错误(查看/etc/sysconfig/network)
BindException:ip设置错误(查看/etc/hosts)
Name Node is in safe mode 文件系统在安全模式(分布式文件系统启动时,开始会有 安全模式,出于安全模式时文件系统中的内容不允许修改和删除,直至安全模式结束,安全模式是系统启动时检查各个datanode上数据块的有效性,可以等待一会或者关闭安全模式 hadoop dfsadmin -safemode leave)
hadoop学习笔记——基础知识及安装的更多相关文章
- jQuery学习笔记 - 基础知识扫盲入门篇
jQuery学习笔记 - 基础知识扫盲入门篇 2013-06-16 18:42 by 全新时代, 11 阅读, 0 评论, 收藏, 编辑 1.为什么要使用jQuery? 提供了强大的功能函数解决浏览器 ...
- three.js学习笔记--基础知识
基础知识 从去年开始就在计划中的three.js终于开始了 历史介绍 (摘自ijunfan1994的转载,感谢作者) OpenGL大概许多人都有所耳闻,它是最常用的跨平台图形库. WebGL是基于Op ...
- SQLServer学习笔记<>.基础知识,一些基本命令,单表查询(null top用法,with ties附加属性,over开窗函数),排名函数
Sqlserver基础知识 (1)创建数据库 创建数据库有两种方式,手动创建和编写sql脚本创建,在这里我采用脚本的方式创建一个名称为TSQLFundamentals2008的数据库.脚本如下: ...
- 吴裕雄--天生自然HADOOP学习笔记:使用yum安装更新软件
实验目的 了解yum的原理及配置 学习软件的更新与安装 学习源代码编译安装 实验原理 1.编译安装 前面我们讲到了安装软件的方式,因为linux是开放源码的,我们可以直接获得源码,自己编译安装.例如: ...
- GO Lang学习笔记 - 基础知识
Go lang Learn Note 标签(空格分隔): Go Go安装和Go目录 设置环境变量GOROOT和GOPATH,前者是go的安装目录,后者是开发工作目录.go get包只会将包下载到第一个 ...
- Java Script 学习笔记 -- 基础知识
Java script 概述 java Script 的简介 JavaScript一种直译式脚本语言,是一种动态类型.弱类型.基于原型的语言,内置支持类型.它的解释器被称为JavaScript引擎,为 ...
- [原创] hadoop学习笔记:卸载和安装jdk
一,卸载jdk 1.确定jdk版本 #rpm -qa | grep jak 可能的结果: java-1.7.0-openjdk-1.7.0.75-2.5.4.2.el7_0.x86_64 java- ...
- java虚拟机JVM学习笔记-基础知识
最近使用开发的过程中出现了一个小问题,顺便记录一下原因和方法--java虚拟机 媒介:JVM是每一位从事Java开发工程师必须翻越的一座大山! JVM(Java Virtual Machine)JRE ...
- php学习笔记——基础知识(2)
9.PHP语句 if 语句 - 如果指定条件为真,则执行代码 if...else 语句 - 如果条件为 true,则执行代码:如果条件为 false,则执行另一端代码 if...else if.... ...
随机推荐
- linux shell编程学习笔记(二) --- grep命令
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来.grep全称是Global Regular Expression Print,表示全局正则表达 ...
- Sublime Text 3插件安装方法
安装Sublime Tex 3t插件的方法: 按快捷键Ctrl + ~ 调出console 粘贴以下代码到console并回车: import urllib.request,os; pf = 'Pac ...
- 获取input标签的所有属性
1.用jquery$("input[name='btnAdd']").attr("value") 获取value属性值,其它属性换attr的参数就OK 例1: ...
- webApi实现增删改查操作
1.WebApi是什么 ASP.NET Web API 是一种框架,用于轻松构建可以由多种客户端(包括浏览器和移动设备)访问的 HTTP 服务.ASP.NET Web API 是一种用于在 .NET ...
- 2014年度辛星css教程夏季版第一节
CSS是Cascading Style Sheets的缩写,即层叠样式表,它用于表现HTML的样式,即HTML只是去写该网页有哪些内容,至于如何去表现它们,由CSS去定制. ************* ...
- IE浏览器窗口合并
百度经验:如何在IE上设置多窗口合并为单窗口(可切换)?
- E8.Net工作流平台之中国特色
特色之一领导排名有先后 领导排名是有潜规则的,不论是在企业通讯录中,还是企业员工目录中,不管在流程执行过程中,还是存档数据中,当前领导的排名一定要按潜规则展示,不能随便罗列.E8.Net工作流解决了 ...
- WebService积累
1.缺点,无法传输复杂对象:如无法序列化key/value结构的类型参数以及相关一维集合接口(Hashtable等打上标签[Serializable]即可序列化,不过继承的IDictionary并不可 ...
- input标签文字点击变颜色
<input type="text" class="ser_input"value="从这里搜索(^_^)" onfocus=&quo ...
- [JavaScript] 初中级Javascript程序员必修学习目录
很多人总感觉javascript无法入门,笔者在这里写一下自己的学习过程,以及个人认 为的最佳看书过程,只要各位能按照本人所说步骤走下去,不用很长时间,坚持 个3个月,你的js层级会提高一个档次,无他 ...