sparkSessiontest
记事本内容:
打印结构:
方法1:
object SparkSessionTest { case class Person(name:String,age:Int) def main(args: Array[String]): Unit = { val sparkSession=SparkSession.builder().appName("SparkSessionTest")
.master("local[*]")
.getOrCreate()
val sparkContext=sparkSession.sparkContext
val rdd=sparkContext.textFile("D:\\temp\\person.txt")
val rowRdd=rdd.map(_.split(" ")).map(row=>Person(row(0),row(1).toInt)) import sparkSession.implicits._
rowRdd.toDF sparkSession.stop()
} }
方法2:
val sparkContext=sparkSession.sparkContext
val rdd=sparkContext.textFile("D:\\temp\\person.txt")
val schemaFiled="name,age"
val schemaString=schemaFiled.split(",")
val schema =StructType(
List(
StructField(schemaString(0),StringType,nullable = true),
StructField(schemaString(1),IntegerType,nullable = true)
)
)
val rowRdd= rdd.map(_.split("")).map(p=>Row(p(0),p(1).toInt))
val df=sparkSession.createDataFrame(rowRdd,schema)
df.show()
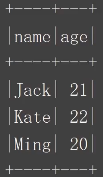
结果展示:
parquet的优势
支持列存储+嵌套数据格式+适配多个计算框架
节省表扫描时间和反序列的时间
压缩技术稳定出色,节省存储空间
Spark操作 Parquet文件比操作CSV等普通文件的速度更快
加载数据:sparkSession.read.parquet(“/nginx/20200110.parquet”)
写入数据:df.write.mode(SaveMode.Overwrite).parquet(“/path/to”)
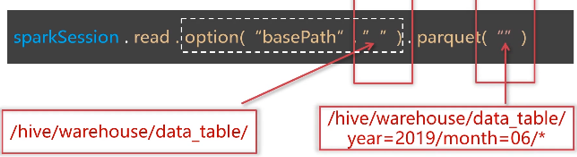
分区文件
加载批量数据:
Df.show()//只显示前20条数据
Df.show(3)//只显示前3条数据
df.show( false)//每列可以显示多于20个字符
dt show(3, false)
Df.select (“字段1”,”字段2”).show()
Df.select(col(“”) as(“别名1”),col(“字段2”)+1).show()
df.first()//获取第一行数据,返回RoW
df.head( 3)//获取前3行数据,返回 Array Row]
df.take (3)//获取前3行数据,返回 Array[Row]
df.takeaslist(3//获取前3行数据,返回List[Row]
df.limit(3).show()//返回新的 Data Frame,不是 Action操作
Df.where(“age>21”).show()
Df.filter(“age>21”).show()
Df.where(col(“age”)>21).show()
Ds.where($”age”>21).show()
Df.where(“age=21”).show
Df.where(col(“age”)===21).show
Df.where(col(“age”)=!=21).show
Val ageFilter_1 =col(“age”)>21
Val agefilter_2=col(“age”)<25
Val ageFilter_3=agefilter_1.or(ageFilter_2)
Df.where(col(“name”)===”jack”).where(ageFilter_3)
Val ageFilter_1 =col(“age”)>21
Val ageFilter_2=col(“age”)<25
Val ageFilter_3 =ageFilter_1.ll(ageFilter_2)
Df.where(col(“name”)===”jack”)
.where(ageFitler_3)
.show
//按照身份统计人数
Df.groupBy(col(“province”))
.count
.show
按照城市,手机运营商分组统计人数并按人数排序
//方法1
Df.groupby(col(“city”),col(“”op_phone“”))
.count
.withColumnRenamed(“count”,”num”)
.orderBy(col(“num”).desc)
.show
//方法2
Ds.groupBy($”city”,$”op_phone”)
.count
.withColumnRenamed(“count”,”num”)
.sort($”num”.desc)
.show
按年统计注册用户最高的积分,以及平均积分
Df.groupBy(year(col(“add_time”)))
.agg(max(col(“total_mark”).as(“max_mark”)),
Avg(col(“total_mark”).as(“avg_mark”))
)
.show






sparkSessiontest的更多相关文章
- RDD&Dataset&DataFrame
Dataset创建 object DatasetCreation { def main(args: Array[String]): Unit = { val spark = SparkSession ...
随机推荐
- 推荐几个来自 MOOCs的 Data Science
数据科学是一个大领域,如果你想成为一个优秀的数据专家,自学是必要的技能. MOOCs是数据科学的主要来源.有许多网站提供了 MOOCs,比如Coursera.Coursera和Udacity都还不错. ...
- 微信小程序开发-小程序之间的跳转
前几天开发微信小程序,其中有个需要联动宣传的业务,就是正在开发的小程序跳转到别的小程序去, 然后去看了下大家的做法与看法,总结下这小程序跳转之间应该注意到的几个问题 首先是跳转的方法, https:/ ...
- python制作一键启动脚本
我们的系统环境或许没有Python环境,又想使用脚本,这就要使该脚本能脱离Python环境独立运行,比如说将该脚本打包成exe可执行文件等.那么怎么做呢?你可能想到py2exe和pyinstaller ...
- Java中Comparable和Comparator的区别
前言 最近复习遇到了这个问题,在此进行一个详细的记录,分享给大家. 两个接口的区别 包区别 Comparable接口是在java.lang下. Comparator接口是在java.util下. 使用 ...
- Java基础语法(4)-流程控制
title: Java基础语法(4)-流程控制 blog: CSDN data: Java学习路线及视频 1.程序流程控制 流程控制语句是用来控制程序中各语句执行顺序的语句,可以把语句组合成能完成一定 ...
- CentOS7 部署 Hadoop 3.2.1 (伪分布式)
CentOS: Linux localhost.localdomain 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20 16:44:24 UTC 2018 x86_64 ...
- 从本地方法栈看到jni调用
我们都知道java虚拟机所管理的内存区域包括方法区,堆,虚拟机栈,本地方法栈,程序计数器. 在<深入理解java虚拟机>中,周志明老师对虚拟机栈进行了讲解,但是对本地方法栈却一笔带过.今天 ...
- Mysql性能优化:为什么你的count(*)这么慢?
导读 在开发中一定会用到统计一张表的行数,比如一个交易系统,老板会让你每天生成一个报表,这些统计信息少不了 sql 中的count函数. 但是随着记录越来越多,查询的速度会越来越慢,为什么会这样呢?M ...
- iOS sign in with Apple 苹果ID登录
http://www.cocoachina.com/articles/109104?filter=ios https://juejin.im/post/5deefc5e518825126416611d ...
- macro
Hello, 宏定义魔法世界 宏只是在预处理器里进行文本替换,没有类型,不做任何类型检查,编译器可以对相同的字符串进行优化.只保存一份到 .rodata 段.甚至有相同后缀的字符串也可以优化,你可以用 ...